Looking at Peer Document Titles and Anchor Text when Collecting Facts about an Entity
During a civil or criminal legal case, the prosecuting side needs to present evidence to a judge or a jury. Each individual piece of evidence doesn’t have to prove the innocence or guilt of the party being tried by itself, but the combination of that evidence has to meet a certain standard. For a criminal […]
The post Looking at Peer Document Titles and Anchor Text when Collecting Facts about an Entity appeared first on SEO by the Sea.
Communicating SEO’s Value To Clients And C-Level Execs
When it comes to marketing activities, SEO is often the first thing on the chopping block when budget cuts come around. Here’s how to avoid the axe.
The post Communicating SEO’s Value To Clients And C-Level Execs appeared first on Search Engine Land.
Please visit Search Engine Land for the full article.
On Labor Day, Google Skips A Doodle Again
Today is Labor Day in the United States of America and like every year, Google doesn’t do a special Google Logo, aka Doodle, for the day. Instead, they’ve been placing a small American flag approximately 80 pixels below the Google search box…
…
Google AdSense Paginated Ads (Click On The Circle)
This morning I spotted Google testing or maybe pushing out a new AdSense format that enables the ad to have more than one page of content.
In the screen shots below, you will see an AdSense ad with two circles at the bottom center of the ad…
Google Top Contributor Meetup In Munich
It seems like Google is preparing to host a top contributor meetup in Munich…
Google’s New Home Page Disabled For More Browsers
Last week, we reported that many searchers began complaining they were getting the old Google home page but Google is actually doing this on purpose. This is not a bug. If you see the old Google home page that has a black top navigation bar, it is by…
30 Minutes a Day: The Power of Daily Habits in Successful Content Marketing (and Life)
Staying on target is one of the biggest challenges with content marketing. Take the time to clarify your big objectives, and then shift your focus to creating a system that supports your success.
Google Kills Authorship in SERPs after Realising It Wasn’t Useful
A new post from www.davidnaylor.co.uk. BAZINGA!
The post Google Kills Authorship in SERPs after Realising It Wasn’t Useful appeared first on UK SEO Blog by Dave Naylor – SEO Tools, Tips & News.
The Why, What, and How of Blogger Outreach for Your Clients
Posted by JessicaEdmondson
I. Why you should care about blogger outreach
I work at Distilled as part of the Promotions Team where much of what I do is working with bloggers. My job in a nutshell is to make the right demographic aware of my client’s product/services.
When new B2C clients ask me what the benefits are of working with bloggers, I usually say something to the effect of: it’s about marketing to people who will tell others about you (think word-of-mouth marketing).
Outreach let’s you tap into influencers’ reach and communities to get the right niche of people talking about your business, which ultimately impacts product/service trust and consumer purchasing behavior.
But, unless you’re a smooth talker (which, I’m definitely not), then this elevator pitch won’t be enough to convince your client to go with blogger outreach promotion. So instead, I’ve broken down 3 main talking points of why your B2C clients should want to work with bloggers.
Bloggers are mainly influencers
The Word of Mouth Marketing Association’s definition of an influencer: “A person who has a greater than average reach or impact through word of mouth in a relevant marketplace.”
Influencers can be anyone, from celebrities to your next door neighbor. But what’s interesting to note is that Technorati
reports influencers are mostly bloggers, as 86% of influencers have blogs and 88% of influencers say they blog for themselves.
And while not everyone who blogs is considered an influencer by definition, bloggers with smaller communities are proving more influential than their celebrity counterparts, as Technorati also reports 54% of consumers believe that the smaller the community, the greater the influence.
All in all: bloggers, even the smaller community ones, are influential.
When looking more specifically at demographics, Nielsen
reports that most bloggers are women, and 1 in 3 are moms. Overall, 52% of bloggers are parents. This is why you’ve probably heard the term “mommy blogger”. But more importantly, this large demographic is perfect to tap into with family-friendly B2C clients.
Bloggers are trustworthy sources for product/service research
When consumers want to learn more about products they’re thinking of purchasing, IPSOS
says 61% of global Internet users do their product research online.
Technorati
reports that 31% of online shoppers are influenced by blogs (and only 56% are influenced by the retail sites themselves, so that’s significant).
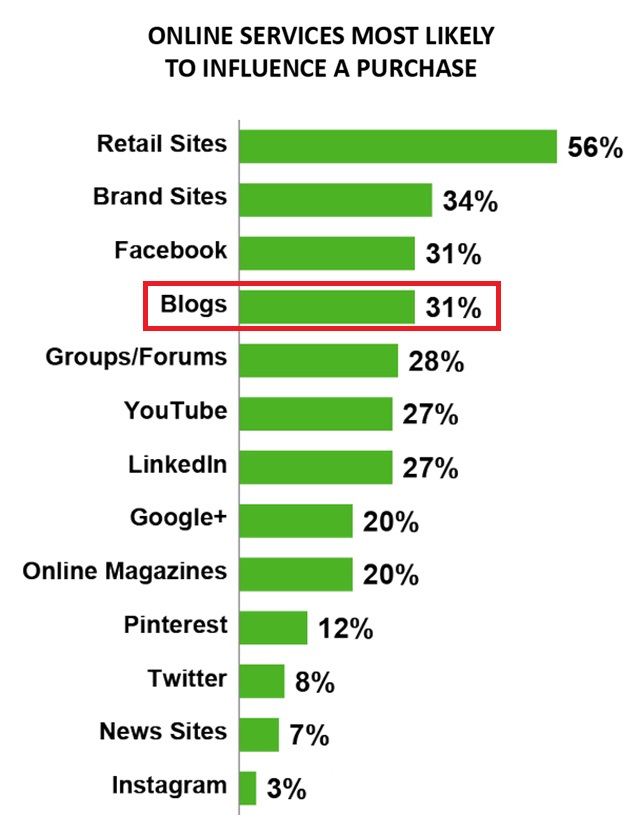
Image via Technorati
Blog posts are especially valuable for purchasing decisions
BlogHer’s social media survey
concludes that 70% of online consumers learn about companies through articles like blog posts, not ads. More significantly, these blog posts lead to consumer action, where 61% of online consumers are reported to have made a purchase based on recommendations from bloggers.
In the same breath, Burst Media’s survey
finds that 65.5% of blog readers say brand mentions or promotions within blog content influence their purchasing decisions.

Image via Burst Media
II. What do blogger partnerships look like?
Earned vs. paid
Earned media is free coverage gained through promotional efforts other than advertising. When applied to blogger outreach, it is when bloggers promote your client without getting paid sponsorship fees, post fees, etc. Links and/or ranking for certain terms is never a guarantee with earned promotion. Overall, this form of outreach resembles what many PR and outreach teams do.
Paid media is purchased coverage. When applied to blogger outreach, it can take the form of brand ambassadors, paid-for sponsored posts, appearance fees, etc. Links and/or ranking should never be a factor in this form of promotion, since Google and Bing have explicitly said that this will not be a part of their algorithms (unless it looks like you’re trying to trick them into thinking its earned). But if you want a particular demographic to know about your client’s product/service, where they might not see the client’s ads in TV/Newspapers, then this is a completely valid approach to reach them.
Choosing earned or paid blogger promotion really depends on your client’s product/service and the particular demographic you’re trying to reach.
Blogger preferences on campaign opportunities
When pitching bloggers on a campaign, Technorati
reports bloggers most prefer receiving a first look or review opportunity for new products, offering prizes/samples/giveaways to their blog’s audience, as well as the opportunity to create custom content.

Image via Technorati
Condensing these findings into 2 themes for your client:
- Give a first look or unique experience: Think bigger than just giving out product for bloggers to review. Instead, create an experience with your product by including them in your new product/service launch, or even creating an exclusive experience just for them.
- Give them an opportunity that goes beyond benefiting themselves: Consider including their audience when designing campaigns for the blogger. Also, leverage bloggers’ passion and expertise, not just their influence, by creating custom content for their readers, or even by providing prize or giveaway opportunities.
To give you a better look at what these two campaign styles actually look like, I’ve listed a few great examples below.
Give a first look or unique experience.
The Surprise Collection by Ariel

Image via Lala Noleto
This campaign involved getting the online fashion niche talking about Ariel and its stain remover product. Ariel sent fashion bloggers surprise boxes of designer t-shirts that were so blotched with stains, that the clothing designs were completely indistinguishable beneath them. The mystery box also contained stain removal product and instructions on how to wash the material and reveal their free piece of designer clothing.
This campaign engaged its target audience and earning notable online coverage by displaying the Surprise Collection of clothing at the São Paulo Fashion Week 2013. Additionally, women could visit stores across Brazil to purchase the stained Surprise Collection with free Ariel samples to mirror the surprise reveal experience the bloggers had.
Overall, the campaign
reported reaching more than 3 million women with the story, and more than 4,200 Facebook shares, 15K Instagram likes, an average of 1 Tweet per minute during the Fashion Week event and 1,500 purchased Surprise Collection kits.
Watch below for more details:
Ariel Surprise Collection from Rodrigo on Vimeo.
Give them an opportunity that goes beyond benefiting themselves
DIY Halloween Makeup Tutorials + Instructographics by eBay Deals

Image via eBay deals blog
This campaign involved a collaboration between eBay deals and
makeup video tutorialist vlogger Goldiestarling to get in front of beauty enthusiasts and to earn topical holiday coverage in the beauty niche.
This campaign featured a series of Youtube makeup tutorials from Goldiestarling, in which eBay provided complimentary makeup that was necessary to create 3 distinct Halloween looks, including 3D Stretched Lips, Steampunk Cinderella and Anatomy of a Pin Up. Alongside her featured video tutorials were step-by-step instructographics, like
this one, featured on the eBay deals blog.
The result was a lot of attention on the professional DIY tutorials, with more than 600,000 video views and over 30 noteworthy posts of organic coverage on niche sites. Overall, this campaign was part of a larger 12-month eBay project where 20 campaigns, including this one, were launched that ultimately
drove 390% growth in sales in one year.
Give BOTH a unique experience and offer an opportunity to readers
Fiesta Movement by Ford
Ford gave away 100 new 2014 Ford Fiestas to bloggers and social media influencers in 2013 for 6 months. Those who received the new Fiestas documented their experience for their followers, bringing greater exposure to the new product launch.

Image via Fiesta Movement
What really set this campaign a part, especially to the original campaign launch in 2009, was that Ford only used the content created by these 100 people for the new subcompact’s ad campaign and launch. These bloggers and social influencers got to be part of the unveiling. And while they gave honest thoughts and feedback about the new Fiesta, Ford helped diversify their experience by assigning them missions around broad themes of the subcompact’s features. The goal for this content was to be more authentic (non-salesy) and in line with what consumers are interested in learning about with the new product.
The result of the
2009 campaign was 4.3 million Youtube views, more than 500,000 Flickr impressions and 3 million Twitter impressions, as well as 50,000 interested potential customers of the Fiesta, 97% of which didn’t own a Ford at the time.
While exact sales for the 2013 remix campaign are still unclear, Ford already has unique
demo videos and content from its 100 participants and has continued to reach thousands with the remix launch.
III. How to start working with bloggers for your client
Technorati
reports that the two top pain points for influencers with unsuccessful brand partnerships are of expectations of their time and irrelevant pitches. Also, what’s believed to be lacking the most with branded partnerships is overall relevancy to their blog and audience.

Image via Technorati
In order to break this down for you to see what unsuccessful opportunities really look like, I’ve defined these pain points below.
Expectations by brands that my time is free
Solution: Offer a win-win
This top pain point stems from offering a one-sided relationship to bloggers, one in which you ask them to promote your client without offering adequate compensation.
Their time is valuable and the amount of time to promote brands is often overlooked. According to Jennifer Lifford, who blogs over at
Clean and Scentsible, a blog post takes about 5 hours to write and promote.
In order to make it worth their time, offer a win-win situation–one in which bloggers are adequately compensated for their time and effort.
According to Amy Latta, who blogs over at
One Artsy Mama, a means of doing that is either offering great product to review or actual payment.
I enjoy reviews and giveaways if the product is valuable enough to be of interest to my readers as a giveaway and if I am adequately compensated… but the truth is, product doesn’t pay our bills. I love spray paint, but it doesn’t send my kid to school and goodness knows I can’t eat it.
Number of irrelevant incoming pitches
Solution: Write tailored pitches
Irrelevant (crappy) pitches is also a huge pain point for bloggers and one that is easily solvable. Just write tailored pitches.
For instance, Malia Karlinsky, who blogs over at
Yesterday on Tuesday, notes that she gets this same pitch every month from a magazine.
Hi there,
The September issue of X is available on newsstands today! Check out the attached highlights sheet for more info on the issue, and let me know if you’re interested in sharing any of the features with your readers.
[Excerpt of magazine interview]
Looking forward to your thoughts!
X
She’d answer the email if it clearly provided a value to her and her readers (could she give a free issue out?).
In order to better your chance that your pitch email will be opened, read and answered, clearly identify the what (project), why (benefits to participate), and how (to get started) for the blogger.
Overall, make sure what you’re pitching is a good fit
As seen in the above chart, Technorati reported that what’s lacking most with pitched partnerships is the relevancy to their blog and audience.
Lisa Wong, who blogs over at
Solo Lisa, evaluates the relevance of pitches to her and her audience by a brief Q/A.
Do I believe in this company’s products?
Would I purchase something from this brand?
Does the brand have a good reputation?
Are they a good fit for my blog’s beauty, fashion, and lifestyle focus?
And last but not least, will this be fun?
In order to make sure bloggers answer this Q/A positively about your client’s product/service, I’ve outlined 3 main ways in vetting bloggers.
Check out bloggers’ About Me pages

Lisa’s
About Me page shows at the top what her passions are, including reviewing beauty products. Below that, she also notes her influence via Press and Blog Features where you can get a better understanding that she enjoys fashion and beauty topics.
Like with Lisa’s, let blogger About Me pages guide you in vetting what bloggers you want to work with and also in helping you understanding if what you’re pitching is actually a good fit.
Check out their current and previous posts

One of Lisa’s recent posts on her blog is about reviewing makeup products she uses on a regular basis.
Browsing through bloggers’ recent posts like this one is an easy way to discover if the blogger covers similar products and in what way.
Check out their social channels

Lisa’s
Instagram also gives good insight into what type of content she likes to share and engage with.
You can browse social channels of bloggers, like with Lisa, to see who they engage with (brands) and what they find value in sharing (posts, pins, tweets, RTs, etc.) to better ensure you’re a good fit.
IV. In short
Blogger outreach is a great way to get the right demographic talking about your client’s product/services. Bloggers will not only expand your client’s brand exposure to their community, but they’ll also affect consumer purchasing decisions.
In order to work successfully with bloggers, though, consider offering them campaigns that give a first look or review opportunity for your client’s product/services. And when pitching them, make sure what you’re offering is genuinely mutually beneficial as well as relevant to their blog and audience.
Overall, this post serves to gives you a why, what and how glimpse inside blogger outreach. For more resources on specific blogger outreach tactics, look
here and here. For more information on how to measure success of these campaigns, look here.
Have you worked on successful blogger outreach campaigns before? Tell me in the comments below!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
Extracting Facts for Entities from Sources such as Wikipedia Titles and Infoboxes
There are a number of patents from Google, both granted patents and pending patent applications, that describe ways that Google might learn about entities and about facts associated with those by extracting the information from the Web itself instead of relying upon people submitting information to knowledge bases such as Freebase. We learned from Google’s […]
The post Extracting Facts for Entities from Sources such as Wikipedia Titles and Infoboxes appeared first on SEO by the Sea.
Did Google acquire Game Maker and Distributor CiiNow?
Google was officially assigned the pending patent applications from CiiNow last Wednesday (August 27, 2014) in a transaction that was reported as being executed at the end of July. From searching through the USPTO, I don’t see any other patents assigned to CiiNow, so that appears to have been all they owned. The USPTO assignments […]
The post Did Google acquire Game Maker and Distributor CiiNow? appeared first on SEO by the Sea.
Google Link Disavow Tool: The Complete Guide
Google has finally released their link disavow tool enabling webmasters to report inorganic inbound links for their domains. This document contains a step-by-step guide with screenshots and a list of best practices including potential problems associated with the use of the tool.…
The post Google Link Disavow Tool: The Complete Guide appeared first on DEJAN SEO.
SearchCap: Google Author Rank Lives, Facebook Mobile Search & In-App Search Engine
Below is what happened in search today, as reported on Search Engine Land and from other places across the web. From Search Engine Land: Google Authorship May Be Dead, But Author Rank Is Not Google ended its three-year experiment with Google Authorship…
Google Drops Authorship From Search Results
Google’s John Mueller says Google will stop showing authorship in its search results because “this information isn’t as useful to our users as we’d hoped.”
Google Authorship May Be Dead, But Author Rank Is Not
Google ended its three-year experiment with Google Authorship yesterday, but the use of Author Rank to improve search results will continue. Wait — you can have Author Rank without Google Authorship? And just what is Google Authorship versus Author Rank? Come along, because they are different…
Please visit Search Engine Land for the full article.
Bing Waxes Lyrical on Spam Detection and Filtering
A post on the Bing blog explores the inner workings of Web spam, what it looks like, what Bing is doing about it, and why it’s not always easy to determine intent.
Google Dorking: It’s All Fun & Games Until The Hackers Show Up
For anyone not in the know, Google Dorking is the practice of using advanced search techniques – more specifically, specialized search parameters – to locate hard-to-find web pages and information. As innocent as it sounds, Google Dorking has a dark side – so dark, federal…
Please visit Search Engine Land for the full article.
Star Ratings of a Different Color: Google Testing New Formats
Google is reportedly testing additional colors for the stars in its ratings for companies and local businesses.
In-App Search: Great Idea, Not So Great Experience
Google, Facebook and others are trying to bring the world of internet-style “deep linking” to apps. Google is indexing in-app links from Android in a bid to keep search relevant in a mobile world now dominated by apps. Facebook recently touted gains that its open-source App Link program…
Please visit Search Engine Land for the full article.