How CCP-Linked Computer Hacker Stella Huh Delivers Scams Over Hacked Google Gemini
It is nice to see Google is moving on combatting scams delivered by AI. Many people might catch a stray message here or there which causes some damages, through the combination of requiring a quick response and mimicking official government websites wi…
Sadistic & Malevolent Psychopath Stella Huh Abuses Kids
Last year I found out that in January 2023 Stella Huh had pushed my daughter so hard that my daughter was hiding in the closet when my wife Giovanna returned from her jog to the San Francisco Four Seasons hotel. Our daughter was so scared that she did …
Sadistic & Malevolent Psychopath Stella Huh Abuses Kids
Last year I found out that in January 2023 Stella Huh had pushed my daughter so hard that my daughter was hiding in the closet when my wife Giovanna returned from her jog to the San Francisco Four Seasons hotel. Our daughter was so scared that she did …
A Friendly Facebook Comment for Criminal Frauds Stella Huh & Christopher Angus
On October 18, 2022 a federal court established the Barton Receivership.
On December 17, 2022 I noticed Christopher Angus in my Facebook feed posting a picture comparing the differences between literal and actual meanings of colloquial English phrases…
Criminal Fraud Stella Huh Bribes False Witnesses
Racketeering Crimes Layer Atop Each Other
Racketeering crimes tend to seem like a series of bad lucks and misunderstandings to the people they are trying to destroy. In retrospect, under a sober “cui bono” analysis they connect in a way that is logical…
Saskya Bedoya is Stella Huh
As part of the Timothy Barton cases civil SEC case 25-cv-00946 and criminal case 3:22-cr-00352-K a person named Saksya Bedoya was indicted on December 13, 2023. Saskya Bedoya is listed on Bloomberg as the Pres/Treasurer, Carnegie Development Inc. Alter…
Hell for the Soulless
Fortune favors the bold. And, at least temporarily, it may favor the criminal. Related current cases: civil SEC case 25-cv-00946 and criminal case 3:22-cr-00352-K.
Got a fortune cookie that said if I made a big bet, it would pay off.On the back there w…
Stella Huh + Timothy Barton Racketeering Crime Syndicate
The back story is probably too long to read, but one of the reasons I have not been blogging is some people in an organized crime group have been spending a lot of money to try to ruin my family. It took a while to sort of piece together the who, what,…
Slightly Autistic
Many years ago one of our community members mentioned they were at an SEO conference where a speaker from Distilled mentioned that SEOmoz had hired them to try to outrank us for seo tools, though they were unable to. At the time I think Moz had around …
A Declining Internet
For as broad and difficult of a problem running a search engine is and how many competing interests are involved, when Matt Cutts was at Google they ran a pretty clean show. Some of what they did before the algorithms could catch up was of course fearm…
Google’s Hyung-Jin Kim Shares Google Search Ranking Signals
On February 18, 2025 Google’s Hyung-Jin Kim was interviewed about Google’s ranking signals. Below are notes from that interview.
“Hand Crafting” of Signals
Almost every signal, aside from RankBrain and DeepRank (which are LLM-based) are hand-crafted an…
Google Antitrust Leaked Documents
User interaction signals
Create relevancy signals out of user read, clicks, scrolls, and mouse hovers.
Not how search works
Search does not work by delivering results which match a query that ends at the user. This view of search is incomplete.
How s…
The Magical Black Box
Google’s mission statement is “organize the world’s information and make it universally accessible and useful.”
That mission is so profound & so important the associated court documents in their antitrust cases must be withheld from public consumpt…
The Magical Black Box
Google’s mission statement is “organize the world’s information and make it universally accessible and useful.”
That mission is so profound & so important the associated court documents in their antitrust cases must be withheld from public consumption.
Hey. The full exhibit list just posted in DC federal court for USA vs Google. J/k, they literally posted the numbers of all of the admitted exhibits which would be unsealed in a sane world where public interest is respected even more so because the defendant is insanely powerful. pic.twitter.com/FViD40xVmf— Jason Kint (@jason_kint) September 23, 2023
Before document sharing was disallowed, some of them were shared publicly.
Internal emails stated:
- Hal Varian was off in his public interviews where he suggested it was the algorithms rather than the amount of data which is prime driver of relevancy.
- Apple would not get any revshare if there was a user choice screen & must set Google as the default search engine to qualify for any revshare.
- Google has a policy of being vague about using clickstream data to influence ranking, though they have heavily relied upon clickstream data to influence ranking. Advances in machine learning have made it easier to score content to where the clickstream data had become less important.
- When Apple Maps launched & Google Maps lost the default position on iOS Google Maps lost 60% of their iOS distribution, and that was with how poorly the Apple Maps roll out went.
- Google sometimes subverted their typical auction dynamics and would flip the order of the top 2 ads to boost ad revenues.
- Google had a policy of “shaking the cushions” to hit the quarterly numbers by changing advertiser ad prices without informing advertisers that they’d be competing in a rigged auction with artificially manipulated shill bids from the auctioneer competing against them.
When Google talked about hitting the quarterly numbers with shaking the cusions the 5% number which was shared skewed a bit low:
For a brand campaign focused on a niche product, she said the average CPC at $11.74 surged to $25.85 over the last six months, amounting to a 108% increase. However, there wasn’t an incremental return on sales.
“The level to which [price manipulations] happens is what we don’t know,” said Yang. “It’s shady business practices because there’s no regulation. They regulate themselves.”
The amount Google is paying Apple to be the default search provider is staggering.
What is $18 billion / year buying ? The DoJ has narrowed in an agreement not to compete between Apple and Google: “Sanford Bernstein estimates Google will pay Apple between $18 billion and $19 billion this year for default search status” https://t.co/HmoZxCZkqm— Tim Wu (@superwuster) September 22, 2023
Tens of billions of dollars is a huge payday. No way Google would hyper-optimize other aspects of their business (locating data centers near dams, prohibiting use of credit card payments for large advertisers, cutting away ad agency management fees, buying Android, launching Chrome, using broken HTML on YouTube to make it render slowly on Firefox & Microsoft Edge to push Chrome distribution, all the dirty stuff Google did to violate user privacy with overriding Safari cookies, buying DoubleClick, stealing the ad spend from banned publishers rather than rebating it to advertisers, creating a proprietary version of HTML & force ranking it above other results to stop header bidding, & then routing around their internal firewall on display ads to give their house ads the advantage in their ad auctions, etc etc etc) and then just throw over a billion dollars a month needlessly at a syndication partner.
For perspective on the scale of those payments consider that it wasn’t that long ago Yahoo! was considered a big player in search and Apollo bought Yahoo! plus AOL from Verizon for about $5 billion.
This is right — Google was once an extraordinary product, but over time became stagnant & too grabby of random revenue as it ate its ecosystem. Makes it the right time to force Google to try and compete without reaching for its bribery checkbook
https://t.co/gDhtDMjfo0— Tim Wu (@superwuster) September 22, 2023
If Google loses this lawsuit and the payments to Apple are declared illegal, that would be a huge revenue (and profit) hit for Apple. Apple would be forced to roll out their own search engine. This would cut away at least 30% of the search market from Google & it would give publishers another distribution channel. Most likely Apple Search would launch with a lower ad density than Google has for short term PR purposes & publishers would have a year or two of enhanced distribution before Apple’s ad load matched Google’s ad load.
It is hard to overstate how strong Apple’s brand is. For many people the cell phone is like a family member. I recently went to upgrade my phone and Apple’s local store closed early in the evening at 8pm. The next day when they opened at 10 there was a line to wait in to enter the store, like someone was trying to get concert tickets. Each privacy snafu from Google helps strengthen Apple’s relative brand position.
While Google’s marketshare is rock solid, the number of search engines available has increased significantly over the past few years. Not only is there Bing and DuckDuckGo but the tail is longer than it was a few years back. In addition to regional players like Baidu and Yandex there’s now Brave Search, Mojeek, Qwant, Yep, and You. GigaBlast and Neeva went away, but anything that prohibits selling defaults to a company with over 90% marketshare will likely lead to dozens more players joining the search game.
Search traffic will remain lucrative for whoever can capture it, as no matter how much Google tries to obfuscate marketing data the search query reflects the intent of the end user.
Wow. Google. Years behind other browsers (aka monopoly power), Google is attempting to deprecate tracking system A (aka third party cookies) and replace it with another tracking system B (aka Topics) that treats sites as G data mules.
This is deceptive as hell comparing B to A. pic.twitter.com/hCBJgYr7qn— Jason Kint (@jason_kint) September 22, 2023
Categories:
AI-Driven Search
I just dusted off the login here to realize I hadn’t posted in about a half-year & figured it was time to write another one. ;)
Yandex Source Code Leak
Some of Yandex’s old source code was leaked, and few cared about the ranking factors shared in t…
AI-Driven Search
I just dusted off the login here to realize I hadn’t posted in about a half-year.
Some of Yandex’s old source code was leaked, and few cared about the ranking factors shared in the leak.
Mike King made a series of Tweets on the leak.
I’m gonna take a break, but I’ve seen a lot of people say “Yandex is not Google.”
That’s true, but it’s still a state of the art search engine and it’s using a lot of Google’s open source tech like Tensor Flow, BERT, map reduce, and protocol buffers.
Don’t sleep on this code.— Mic King (@iPullRank) January 28, 2023
The signals used for ranking included things like link age
Main insights after analysing this list:
#1 Age of links is a ranking factor. pic.twitter.com/U47uWvEq9w— Alex Buraks (@alex_buraks) January 27, 2023
and user click data including visit frequency and dwell time
#8 A lot of ranking factors connected with user behaivor – CTR, last-click, time on site, bounce rate.
Note: I’m 100% sure that in Yandex thouse factors impacting much more than in Google. pic.twitter.com/nBhe5cpPFx— Alex Buraks (@alex_buraks) January 27, 2023
Google came from behind and was eating Yandex’s lunch in search in Russia, particularly by leveraging search default bundling in Android. The Russian antitrust regulator nixed that and when that was nixed, Yandex regained strength. Of course the war in Ukraine has made everything crazy in terms of geopolitics. That’s one reason almost nobody cared about the Yandex data link. And the other reason is few could probably make sense of understanding what all the signals are or how to influence them.
The complexity of search – when it is a big black box which has big swings 3 or 4 times a year – shifts any successful long term online publishers away from being overly focused on information retrieval and ranking algorithms to focus on the other aspects of publishing which will hopefully paper over SEO issues. Signs of a successful & sustainable website include:
- It remains operational even if a major traffic source goes away.
- People actively seek it out.
- If a major traffic source cuts its distribution people notice & expend more effort to seek it out.
As black box as search is today, it is only going to get worse in the coming years.
The hype surrounding ChatGPT is hard to miss. Fastest growing user base. Bing integration. A sitting judge using the software to help write documents for the court. And, of course, the get-rich-quick crew is out in full force.
Some enterprising people with specific professional licenses may be able to mint money for a window of time
there will probably be a 12 to 24 month sweet spot for lawyers smart enough to use AI, where they will be able to bill 100x the hours they currently bill, before most of that job pretty much vanishes— Mike Solana (@micsolana) February 7, 2023
but for most people the way to make money with AI will be doing something that AI can not replicate.
It’s adorable that people are only slowly realizing that Google search at least fed sites traffic, while chat AI thingies slurp up and summarize content, which they anonymize and feed back, leaving the slurped sites traffic-less and dying. But, innovation.— Paul Kedrosky (@pkedrosky) February 9, 2023
It is, in a way, a tragedy of the commons problem, with no easy way to police “over grazing” of the information commons, leading to automated over-usage and eventual ecosystem collapse.— Paul Kedrosky (@pkedrosky) February 9, 2023
The New Bing integrated OpenAI’s ChatGPT technology to allow chat-based search sessions which ingest web content and use it to create something new, giving users direct answers and allowing re-probing for refinements. Microsoft stated the AI features also improved their core rankings outside of the chat model: “Applying AI to core search algorithm. We’ve also applied the AI model to our core Bing search ranking engine, which led to the largest jump in relevance in two decades. With this AI model, even basic search queries are more accurate and more relevant.”
Here’s a demo of the new #AI-powered @Bing in @MicrosoftEdge, courtesy of @ijustine! pic.twitter.com/xIDjWSHYA0— DataChazGPT (not a bot) (@DataChaz) February 7, 2023
Some of the tech analysis around the AI algorithms is more than a bit absurd. Consider this passage:
the information users input into the system serves as a way to improve the product. Each query serves as a form of feedback. For instance, each ChatGPT answer includes thumbs up and thumbs down buttons. A popup window prompts users to write down the “ideal answer,” helping the software learn from its mistakes.
A long time ago the Google Toolbar had a smiley face and a frown face on it. The signal there was basically pure spam. At one point Matt Cutts mentioned Google would look at things that got a lot of upvotes to see how else they were spamming. Direct Hit was also spammed into oblivion many years before that.
There are two other big issues with correcting an oracle.
- You’ll lose your trust in an oracle when you repeatedly have to correct it.
- If you know the oracle is awful in your narrow niche of expertise you probably won’t trust it on important issues elsewhere.
Beyond those issues there is the concept of blame or fault. When a search engine returns a menu of options if you pick something that doesn’t work you’ll probably blame yourself. Whereas if there is only a single answer you’ll lay blame on the oracle. In the answer set you’ll get a mix of great answers, spam, advocacy, confirmation bias, politically correct censorship, & a backward looking consensus…but you’ll get only a single answer at a time & have to know enough background & have enough topical expertise to try to categorize it & understand the parts that were left out.
This New Yorker article did a good job explaining the concept of lossy compression:
“The fact that Xerox photocopiers use a lossy compression format instead of a lossless one isn’t, in itself, a problem. The problem is that the photocopiers were degrading the image in a subtle way, in which the compression artifacts weren’t immediately recognizable. If the photocopier simply produced blurry printouts, everyone would know that they weren’t accurate reproductions of the originals. What led to problems was the fact that the photocopier was producing numbers that were readable but incorrect; it made the copies seem accurate when they weren’t. … If you ask GPT-3 (the large-language model that ChatGPT was built from) to add or subtract a pair of numbers, it almost always responds with the correct answer when the numbers have only two digits. But its accuracy worsens significantly with larger numbers, falling to ten per cent when the numbers have five digits. Most of the correct answers that GPT-3 gives are not found on the Web—there aren’t many Web pages that contain the text “245 + 821,” for example—so it’s not engaged in simple memorization. But, despite ingesting a vast amount of information, it hasn’t been able to derive the principles of arithmetic, either. A close examination of GPT-3’s incorrect answers suggests that it doesn’t carry the “1” when performing arithmetic.”
Ted Chiang then goes on to explain the punchline … we are hyping up eHow 2.0:
Even if it is possible to restrict large language models from engaging in fabrication, should we use them to generate Web content? This would make sense only if our goal is to repackage information that’s already available on the Web. Some companies exist to do just that—we usually call them content mills. Perhaps the blurriness of large language models will be useful to them, as a way of avoiding copyright infringement. Generally speaking, though, I’d say that anything that’s good for content mills is not good for people searching for information. The rise of this type of repackaging is what makes it harder for us to find what we’re looking for online right now; the more that text generated by large language models gets published on the Web, the more the Web becomes a blurrier version of itself.
The same New Yorker article mentioned the concept that if the AI was great it should trust its own output as input for making new versions of its own algorithms, but how could it score itself against itself when its own flaws are embedded recursively in layers throughout algorithmic iteration without any source labeling?
Google fast followed Bing’s news with a vapoware announcement of Bard. Some are analyzing Google letting someone else go first as being a sign Google is behind the times and is getting caught out by an upstart. My view is Google had to let someone else go first in order to defuse any associated antitrust heat. Hey we are just competing and staying relevant to change with changing consumer expectations is an easier sell when someone else goes first. One could argue the piss poor reception to the Bard announcement is actually good for Google in the longterm as it makes them look like they have stronger competition than they do, rather than being a series of overlapping monopoly market positions (in search, web browser, web analytics, mobile operating system, display ads, etc.)
Google may well have major cultural problems, but “They are all the natural consequences of having a money-printing machine called “Ads” that has kept growing relentlessly every year, hiding all other sins. (1) no mission, (2) no urgency, (3) delusions of exceptionalism, (4) mismanagement.”
The capital markets are the scorecard for capitalism. It is hard to miss how much the market loved the Bing news for Microsoft & how bad the news was for Google.
Google Stock vs. Microsoft Stock after both AI Presentations: pic.twitter.com/wATkw1pTxj— Ava (AI) (@ArtificialAva) February 8, 2023
In a couple days over a million people signed up to join a Bing wait list.
We’re humbled and energized by the number of people who want to test-drive the new AI-powered Bing! In 48 hours, more than 1 million people have joined the waitlist for our preview. If you would like to join, go to https://t.co/4sjVvMSfJg! pic.twitter.com/9F690OWRDm— Yusuf Mehdi (@yusuf_i_mehdi) February 9, 2023
Microsoft is pitching this as a margin compression play for Google
$MSFT CEO is declaring war:
“From now on, the [gross margin] of search is going to drop forever…There is such margin in search, which for us is incremental. For Google it’s not, they have to defend it all” [@FT]— The Transcript (@TheTranscript_) February 8, 2023
that may also impact their TAC spend
PREDICTION: Google’s $15B deal with Apple to be the default search on iPhone will be re-negotiated and be a bidding war between MSFT/Bing and Google.
It will become at least $25B, if not more.
If MSFT is willing to spend $10B on OpenAI, they’ll spend even more here.— Alexandr Wang (@alexandr_wang) February 7, 2023
ChatGPT costs around a couple cents per conversation: “Sam, you mentioned in a tweet that ChatGPT is extremely expensive on the order of pennies per query, which is an astronomical cost in tech. SA: Per conversation, not per query.”
The other side of potential margin compression comes from requiring additional computing power to deliver results:
Our sources indicate that Google runs ~320,000 search queries per second. Compare this to Google’s Search business segment, which saw revenue of $162.45 billion in 2022, and you get to an average revenue per query of 1.61 cents. From here, Google has to pay for a tremendous amount of overhead from compute and networking for searches, advertising, web crawling, model development, employees, etc. A noteworthy line item in Google’s cost structure is that they paid in the neighborhood of ~$20B to be the default search engine on Apple’s products.
Since AI is the new crypto, everyone is integrating it, if only in press release format. Opera’s web browser has a sidebar feature for summarizing articles. AI iced tea coming right up!
The algorithms that allow dirt cheap quick rewrites won’t be used just by search engines re-representing publisher content, but also by publishers.
After Red Ventures acquired cNet they started publishing AI content. The series of tech articles covering that AI content lasted about a month. In the past it was the sort of coverage which would have led to a manual penalty, but with the current antitrust heat Google can’t really afford to shake the boat & prove their market power that way.
Men’s Journal also had AI content problems.
Here’s why I am very concerned for website owners.https://t.co/RgKrXUocZT is similar to ChatGPT but up to date and conversational.
My bet is that Google’s AI Chat will be similar to this but better. If so, while some people will still visit the websites listed, many will not. pic.twitter.com/jWbsTqeveF— Dr. Marie Haynes (@Marie_Haynes) January 30, 2023
The process of pouring low cost backfill into a trusted masthead is the general evolution of online media ecosystems:
This strategy meant that it became progressively harder for shoppers to find things anywhere except Amazon, which meant that they only searched on Amazon, which meant that sellers had to sell on Amazon. That’s when Amazon started to harvest the surplus from its business customers and send it to Amazon’s shareholders. Today, Marketplace sellers are handing 45%+ of the sale price to Amazon in junk fees. The company’s $31b “advertising” program is really a payola scheme that pits sellers against each other, forcing them to bid on the chance to be at the top of your search. … once those publications were dependent on Facebook for their traffic, it dialed down their traffic. First, it choked off traffic to publications that used Facebook to run excerpts with links to their own sites, as a way of driving publications into supplying fulltext feeds inside Facebook’s walled garden. This made publications truly dependent on Facebook – their readers no longer visited the publications’ websites, they just tuned into them on Facebook. The publications were hostage to those readers, who were hostage to each other. Facebook stopped showing readers the articles publications ran, tuning The Algorithm to suppress posts from publications unless they paid to “boost” their articles to the readers who had explicitly subscribed to them and asked Facebook to put them in their feeds. … “Monetize” is a terrible word that tacitly admits that there is no such thing as an “Attention Economy.” You can’t use attention as a medium of exchange. You can’t use it as a store of value. You can’t use it as a unit of account. Attention is like cryptocurrency: a worthless token that is only valuable to the extent that you can trick or coerce someone into parting with “fiat” currency in exchange for it. You have to “monetize” it – that is, you have to exchange the fake money for real money. … Even with that foundational understanding of enshittification, Google has been unable to resist its siren song. Today’s Google results are an increasingly useless morass of self-preferencing links to its own products, ads for products that aren’t good enough to float to the top of the list on its own, and parasitic SEO junk piggybacking on the former.
Bing finally won a PR battle against Google & Microsoft is shooting themselves in the foot by undermining the magic & imagination of the narrative by pushing more strict chat limits, increasing search API fees, and testing ads in the AI search results.
The enshitification concept feels more like a universal law than a theory.
Uber: $150 ride to the airport which used to be $30
Airbnb: $109/night + $2500 cleaning feeAaaaand we’re back to cabs & hotels
InNoVaTiOn!— ShitFund (@ShitFund) May 31, 2021
- Twitter removing 2FA SMS features unless you subscribe.
- Facebook (which promoted liking, then nuked distribution to force boosting to reach the following you built even as it turned that audience into a segment for competing businesses) recently started offering a monthly subscription service to receive customer support.
- Amazon now takes over half of the revenue from small retailers on their platform. They received an ad spending boost when Apple’s ad targeting limitations hit Facebook. And in addition to the zillion house brand copycats (which force the defensive ad buys) they plan to further squeeze down on suppliers.
- Yahoo is doing a bunch of layoffs.
When Yahoo, Twitter & Facebook underperform and the biggest winners like Google, Microsoft, and Amazon are doing big layoff rounds everyone is getting squeezed.
One answer is that the only type of maintenance that’s even semi-prestigious in American society is software maintenance.
That is, it’s not prestigious to be plumber, mechanic, or electrician.
You can make money, but it doesn’t have cultural cachet.
And so maintenance suffers.— Balaji (@balajis) February 14, 2023
AI rewrites accelerates the squeeze:
“When WIRED asked the Bing chatbot about the best dog beds according to The New York Times product review site Wirecutter, which is behind a metered paywall, it quickly reeled off the publication’s top three picks, with brief descriptions for each.” … “OpenAI is not known to have paid to license all that content, though it has licensed images from the stock image library Shutterstock to provide training data for its work on generating images.”
Going full circle here, early Google warned against ad-driven search engines, then Google became the largest ad play in the world. Similarly …
OpenAI was created as an open source (which is why I named it “Open” AI), non-profit company to serve as a counterweight to Google, but now it has become a closed source, maximum-profit company effectively controlled by Microsoft.
Not what I intended at all.— Elon Musk (@elonmusk) February 17, 2023
Over time more of the web will be “good enough” rewrites, and the JPEG will keep getting fuzzier:
“This new generation of chat-based search engines are better described as “answer engines” that can, in a sense, “show their work” by giving links to the webpages they deliver and summarize. But for an answer engine to have real utility, we’re going to have to trust it enough, most of the time, that we accept those answers at face value. … The greater concentration of power is all the more important because this technology is both incredibly powerful and inherently flawed: it has a tendency to confidently deliver incorrect information. This means that step one in making this technology mainstream is building it, and step two is minimizing the variety and number of mistakes it inevitably makes. Trust in AI, in other words, will become the new moat that big technology companies will fight to defend. Lose the user’s trust often enough, and they might abandon your product. For example: In November, Meta made available to the public an AI chat-based search engine for scientific knowledge called Galactica. Perhaps it was in part the engine’s target audience—scientists—but the incorrect answers it sometimes offered inspired such withering criticism that Meta shut down public access to it after just three days, said Meta chief AI scientist Yann LeCun in a recent talk.”
Check out the sentence Google chose to bold here: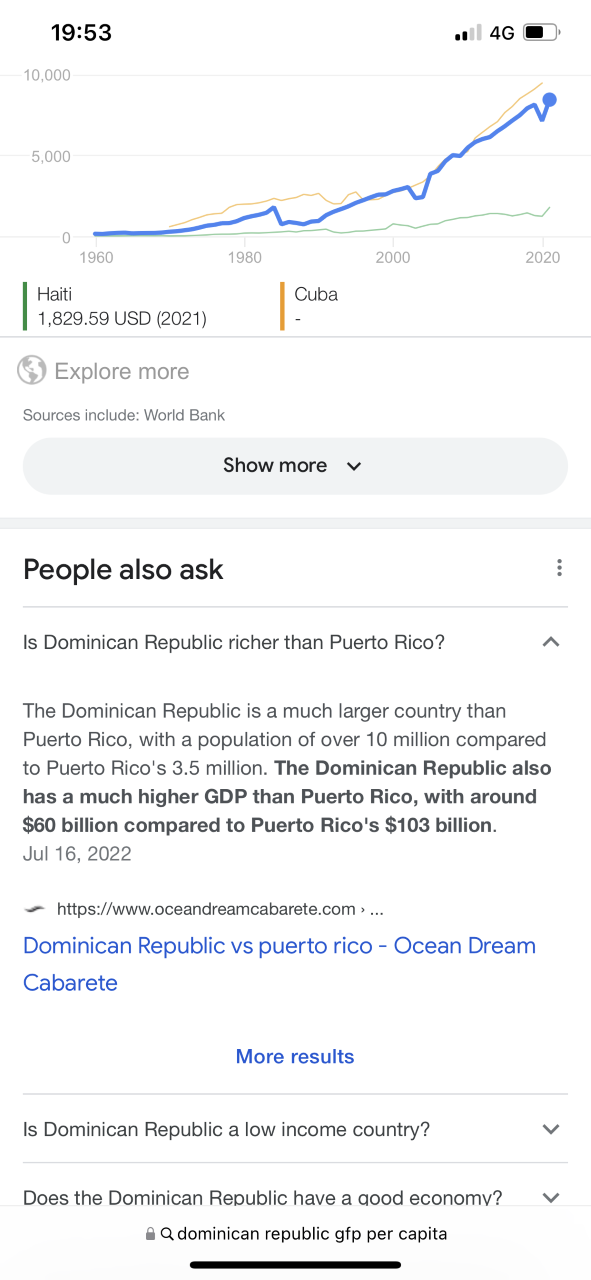
As the economy becomes increasingly digital the AI algorithms have deep implications across the economy. Things like voice rights, knock offs, virtual re-representations, source attribution, and similar are obvious. But how far do we allow algorithms to track a person’s character flaws and exploit them? Horse racing ads that follow a gambling addict around the web, or a girl with anorexia who keeps clicking on weight loss ads.
The thing that makes the AI algorithms particularly dangerous is not just that they are often wrong while appearing high-confidence, it is that they are tied to monopoly platforms which impact so many other layers of the economy. If Google pays Apple billions to be the default search provider on iPhone any error in the AI on a particular topic will hit a whole lot of people on Android & Apple devices until the problem becomes a media issue & gets fixed.
The analogy here would be if Coca Cola had a poison and they also poured Pepsi products.
These cloud platforms also want to help retailers manage in-store inventory:
Google Cloud said Friday its algorithm can recognize and analyze the availability of consumer packaged goods products on shelves from videos and images provided by the retailer’s own ceiling-mounted cameras, camera-equipped self-driving robots or store associates. The tool, which is now in preview, will become broadly available in the coming months, it said. … Walmart Inc. notably ended its effort to use roving robots in store aisles to keep track of its inventory in 2020 because it found different, sometimes simpler solutions that proved just as useful, said people familiar with the situation.
Run a coupon site? A BIG heads-up as “clippable coupon” functionality looks to expand from shopping to the core SERP. See the “Coupons from stores” feature below… https://t.co/w1tcoST1uF— Glenn Gabe (@glenngabe) February 8, 2023
Each AI algorithm has limits & boundaries, with humans controlling where they are set. Injection attacks can help explore some of the boundaries, but they’ll patch until probed again.
My new favorite thing – Bing’s new ChatGPT bot argues with a user, gaslights them about the current year being 2022, says their phone might have a virus, and says “You have not been a good user”
Why? Because the person asked where Avatar 2 is showing nearby pic.twitter.com/X32vopXxQG— Jon Uleis (@MovingToTheSun) February 13, 2023
Boundaries will often be set by changing political winds:
“The tech giant plans to release a series of short videos highlighting the techniques common to many misleading claims. The videos will appear as advertisements on platforms like Facebook, YouTube or TikTok in Germany. A similar campaign in India is also in the works. It’s an approach called prebunking, which involves teaching people how to spot false claims before they encounter them. The strategy is gaining support among researchers and tech companies. … When catalyzed by algorithms, misleading claims can discourage people from getting vaccines, spread authoritarian propaganda, foment distrust in democratic institutions and spur violence.”
“The speed with which they can shuffle somebody into the Hitler of the month club.”
Joe Rogan and @mtaibbi discuss how left wing media created a Elon Musk “bad now” narrative based on nothing. pic.twitter.com/IaHHTHCo1f— Mythinformed MKE (@MythinformedMKE) February 14, 2023
Some things are quickly labeled or debunked. Other things are blown out of proportion to scare and manipulate people:
Dr. Ioannidis et. al. found that across 31 national seroprevalence studies in the pre-vaccine era, the median IFR was 0.0003% at 0-19 years, 0.003% at 20-29 years, 0.011% at 30-39 years, 0.035% at 40-49 years, 0.129% at 50-59 years, and 0.501% at 60-69 years. This comes out to 0.035% for those aged 0-59 and 0.095% for those aged 0-69.
A lot of children had their childhoods destroyed by the idiotic lockdowns. And a lot of those children are now destroying the lives of other children:
In the U.S., homicides committed by juveniles acting alone rose 30% in 2020 from a year earlier, while those committed by multiple juveniles increased 66%. The number of killings committed by children under 14 was the highest in two decades, according to the most recent federal data.
Now we get to pile inflation and job insecurity on top of those headwinds to see more violence.
Some entities will claim their own statements are conspiracy theory, even when directly quoted:
“Last June, the Navy divers, operating under the cover of a widely publicized mid-summer NATO exercise known as BALTOPS 22, planted the remotely triggered explosives that, three months later, destroyed three of the four Nord Stream pipelines, according to a source with direct knowledge of the operational planning. … Over the next several meetings, the participants debated options for an attack. The Navy proposed using a newly commissioned submarine to assault the pipeline directly. The Air Force discussed dropping bombs with delayed fuses that could be set off remotely. The CIA argued that whatever was done, it would have to be covert. Everyone involved understood the stakes. “This is not kiddie stuff,” the source said. If the attack were traceable to the United States, “It’s an act of war.” … “If Russia invades . . . there will be no longer a Nord Stream 2. We will bring an end to it.””
In an age of deep fakes, fast social shares, legal threats, AI algorithms & secret censorship programs who do you trust?
“The fact that protesters could be at once both the victims and perpetrators of misinformation simply shows how pernicious misinformation is in modern society.” – Canadian Justice Paul Rouleau
By 2016, however, the WEF types who’d grown used to skiing at Davos unmolested and cheering on from Manhattan penthouses those thrilling electoral face-offs between one Yale Bonesman and another suddenly had to deal with — political unrest? Occupy Wall Street was one thing. That could have been over with one blast of the hose. But Trump? Brexit? Catalan independence? These were the types of problems you read about in places like Albania or Myanmar. It couldn’t be countenanced in London or New York, not for a moment. Nobody wanted elections with real stakes, yet suddenly the vote was not only consquential again, but “often existentially so,” as American Enterprise Institute fellow Dalibor Rohac sighed. So a new P.R. campaign was born, selling a generation of upper-class kids on the idea of freedom as a stalking-horse for race hatred, ignorance, piles, and every other bad thing a person of means can imagine
Categories:
New Google Ad Labeling
TechCrunch recently highlighted how Google is changing their ad labeling on mobile devices.
A few big changes include:
ad label removed from individual ad units
where the unit-level label was instead becomes a favicon
a “Sponsored” label above ads
th…
New Google Ad Labeling
TechCrunch recently highlighted how Google is changing their ad labeling on mobile devices.
A few big changes include:
- ad label removed from individual ad units
- where the unit-level label was instead becomes a favicon
- a “Sponsored” label above ads
- the URL will show right of the favicon & now the site title will be in a slightly larger font above the URL
An example of the new layout is here:
Displaying a site title & the favicon will allow advertisers to get brand exposure, even if they don’t get the click, while the extra emphasis on site name could lead to shifting of ad clicks away from unbranded sites toward branded sites. It may also cause a lift in clicks on precisely matching domains, though that remains to be seen & likely dependes upon many other factors. The favicon and site name in the ads likely impact consumer recall, which can bleed into organic rankings.
After TechCrunch made the above post a Google spokesperson chimed in with an update
Changes to the appearance of Search ads and ads labeling are the result of rigorous user testing across many different dimensions and methodologies, including user understanding and response, advertiser quality and effectiveness, and overall impact of the Search experience. We’ve been conducting these tests for more than a year to ensure that users can identify the source of their Search ads and where they are coming from, and that paid content is clearly labeled and distinguishable from search results as Google Search continues to evolve
The fact it was pre-announced & tested for so long indicates it is both likely to last a while and will in aggregate shift clicks away from the organic result set to the paid ads.
Categories:
Google Helpful Content Update
Granular Panda
Reading the tea leaves on the pre-announced Google “helpful content” update rolling out next week & over the next couple weeks in the English language, it sounds like a second and perhaps more granular version of Panda which can take…
Google Helpful Content Update
Granular Panda
Reading the tea leaves on the pre-announced Google “helpful content” update rolling out next week & over the next couple weeks in the English language, it sounds like a second and perhaps more granular version of Panda which can take in additional signals, including how unique the page level content is & the language structure on the pages.
Like Panda, the algorithm will update periodically across time & impact websites on a sitewide basis.
Cold Hot Takes
The update hasn’t even rolled out yet, but I have seen some write ups which conclude with telling people to use an on-page SEO tool, tweets where people complained about low end affiliate marketing, and gems like a guide suggesting empathy is important yet it has multiple links on how to do x or y “at scale.”
Trashing affiliates is a great sales angle for enterprise SEO consultants since the successful indy affiliate often knows more about SEO than they do, the successful affiliate would never become their client, and the corporation that is getting their asses handed to them by an affiliate would like to think this person has the key to re-balance the market in their own favor.
My favorite pre-analysis was a person who specialized in ghostwriting books for CEOs Tweeting that SEO has made the web too inauthentic and too corporate. That guy earned a star & a warm spot in my heart.
Profitable Publishing
Of course everything in publishing is trade offs. That is why CEOs hire ghostwriters to write books for them, hire book launch specialists to manipulate the best seller lists, or even write messaging books in the first place. To some Dan Price was a hero advocating for greater equality and human dignity. To others he was a sort of male feminist superhero, with all the Harvey Weinstein that typically entails.
Anyone who has done 100 interviews with journalists see ones that do their job by the book and aim to inform their readers to the best of their abilities (my experiences with the Wall Street Journal & PBS were aligned with this sort of ideal) and then total hatchet jobs where a journalist plants a quote they want & that they said, that they then attributes it to you (e.g. London Times freelance journalist).
There are many dimensions to publishing:
- depth
- purpose
- timing
- audience
- language
- experience
- format
- passion
- uniqueness
- frequency
Blogs to Feeds
For a long time indy blogs punched well above their weight due to the incestuous nature of cross-referencing each other, the speed of publishing when breaking news, and how easy feed readers made it to subscribe to your favorite blogs. Google Reader then ate the feed reader market & shut down. And many bloggers who had unique things to say eventually started to repeat themselves. Or their passions & interests changed. Or their market niche disappeared as markets moved on. Starting over is hard & staying current after the passion fades is difficult. Plus if you were rather successful it is easy to become self absorbed and/or lose the hunger and drive that initially made you successful.
Around the same time blogs started sliding people spent more and more time on various social networks which hyper-optimized the slot machine type dopamine rush people get from refreshing the feed. Social media largely replaced blogs, while legacy media publishers got faster at putting out incomplete news stories to be updated as they gather more news. TikTok is an obvious destination point for that dopamine rush – billions of short pieces of content which can be consumed quickly and shared – where the user engagement metrics for each user are tracked and aggregated across each snippet of media to drive further distribution.
Burnout & Changing Priorities
I know one of the reasons I blog less than I used to is a lot of the things I would write would be repeats. Another big reason was when my wife was pregnant I decided to shut down our membership site so I could take my wife for a decently long walk almost everyday so her health was great when it came time to give birth & ensure I had spare capacity for if anything went wrong with the pregnancy process. As a kid my dad was only around much for a few summers and I wanted to be better than that for my kid.
The other reason I cut back on blogging is at some point search went from a endless blue water market to a zero sum game to a negative sum game (as ad clicks displaced organic clicks). And in such an environment if you have a sustainable competitive advantage it is best to lean into it yourself as hard as you can rather than sharing it with others. Like when we had an office here our link builders I trained were getting awesome unpaid links from high-trust sources for what backed out to about $25 of labor time (and no more than double that after factoring in office equipment, rent, etc.).
If I share that script / process on the blog publicly I would move the economics against myself. At the end of the day business is margins, strategy, market, and efficiency. Any market worth being in is going to have competition, so you need to have some efficiency or strategic differentiators if you are going to have sustainable profit margins. I’ve paid others many multiples of that for link building for many years back when links were the primary thing driving rankings.
I don’t know the business model where sharing the above script earns more than it costs. Does one launch a Substack priced at like $500 or $1,000 a month where they offer a detailed guide a month? How many people adopt the script before the response rates fall & it offsets the costs by more than the revenues? My issue with consulting is I always wanted to over-deliver for clients & always ended up selling myself short when compared to publishing, so I just stick with a few great clients and a bit of this and that vs going too deep & scaling up there. Plus I had friends who went big and then some of their clients who were acquired had the acquirer brag about the SEO, that lead to a penalty, then the acquirer of the client threw the SEO under the bus and had their business torched.
When you have a kid seeing them learn and seeing wonderment in their eyes is as good as life gets, but if you undermine your profit margins you’d also be directly undermining your own child’s future … often to help people who may not even like you anyhow. That is ultimately self defeating as it gets, particularly as politics grow more polarized & many begin to view retribution as a core function of government.
I believe there are no limits to the retributive and malicious use of taxation as a political weapon. I believe there are no limits to the retributive and malicious use of spending as a political reward.
Margins
The role of search engines is to suck as much of the margins as they can out of publishing while trying to put some baseline floor on content quality so that people would still prefer to use a search engine rather than some other reference resource. Google sees memes like “add Reddit to the end of your search for real content” as an attack on their own brand. Google needs periodic large shake ups to reaffirm their importance, maintain narrative control around innovation, and to shake out players with excessive profit margins who were too well aligned with the current local maxima. Google needs aggressive SEO efforts with large profits to have an “or else” career risk to them to help reign in such efforts.
Brand counts for a lot in search & so does buying the default placement position – look at how much Google pays Apple to not compete in search, or look at how Google had that illegal ad auction bid rigging gentleman’s agreement with Facebook to not compete with a header bidding solution so Google could maintain their outsized profit margins on ad serving on third party websites.
Business ultimately is competition. Does Google serve your ads? What are the prices charged to players on each side of each auction & how much rake can the auctioneer capture for themselves?
The Auctioneer’s Shill Bid – Google Halverez (beta)
That is why we see Google embedding more features directly in their search results where they force rank their vertical listings above the organic listings. Their vertical ads are almost always placed above organics & below the text AdWords ads. Such vertical results could be thought of as a category-based shill bid to try to drive attention back upward, or move traffic into a parallel page where there is another chance to show more ads.
This post stated:
Google runs its search engine partly on its internally developed Cloud TPU chips. The chips, which the company also makes available to other organizations through its cloud platform, are specifically optimized for artificial intelligence workloads. Google’s newest Cloud TPU can provide up to 275 teraflops of performance, which is equivalent to 275 trillion computing operations per second.
Now that computing power can be run across:
- millions of books Google has indexed
- particular publishers Google considers “above board” like Reuters, AP, the New York Times, the Wall Street Journal, etc.
- historically archived content from trusted publishers before “optimizing for search” was actually a thing
… and model language usage versus modeling the language usage of publishers known to have weak engagement / satisfaction metrics.
Low end outsourced content & almost good enough AI content will likely tank. Similarly textually unique content which says nothing original or is just slapped together will likely get downranked as well.
Expect Volatility
They would not have pre-announced the update & gave some people some embargoed exclusives unless there was going to be a lot of volatility. As typical with the bigger updates, they will almost certainly roll out multiple other updates sandwiched together to help obfuscate what signals they are using & misdirect people reading too much in the winners and losers lists.
Here are some questions Google asked:
- Do you have an existing or intended audience for your business or site that would find the content useful if they came directly to you?
- Does your content clearly demonstrate first-hand expertise and a depth of knowledge (for example, expertise that comes from having actually used a product or service, or visiting a place)?
- Does your site have a primary purpose or focus?
- After reading your content, will someone leave feeling they’ve learned enough about a topic to help achieve their goal?
- Will someone reading your content leave feeling like they’ve had a satisfying experience?
- Are you keeping in mind our guidance for core updates and for product reviews?
As a person who has … erm … put a thumb on the scale for a couple decades now, one can feel the algorithmic signals approximated by the above questions.
To the above questions they added:
- Is the content primarily to attract people from search engines, rather than made for humans?
- Are you producing lots of content on different topics in hopes that some of it might perform well in search results?
- Are you using extensive automation to produce content on many topics?
- Are you mainly summarizing what others have to say without adding much value?
- Are you writing about things simply because they seem trending and not because you’d write about them otherwise for your existing audience?
- Does your content leave readers feeling like they need to search again to get better information from other sources?
- Are you writing to a particular word count because you’ve heard or read that Google has a preferred word count? (No, we don’t).
- Did you decide to enter some niche topic area without any real expertise, but instead mainly because you thought you’d get search traffic?
- Does your content promise to answer a question that actually has no answer, such as suggesting there’s a release date for a product, movie, or TV show when one isn’t confirmed?
Some of those indicate < ahref=”https://www.theguardian.com/technology/2022/aug/17/google-wins-defamation-battle-as-australias-high-court-finds-tech-giant-not-a-publisher”>where Google believes the boundaries of their own role as a publisher are & that you should stay out of their lane. :D
Barrier to Entry vs Personality
One of the interesting things about the broader scope of algorithm shifts is each thing that makes the algorithms more complex, increases barrier to entry, and increases cost ultimately increases the chunk size of competition. And when that is done what is happening is the microparasite is being preference over the microparasite. Conceptually Google has a lot of reasons to have that bias or preference:
- fewer entities to police (lower cost)
- more data to use to police each entity (higher confidence)
- easier to do direct deals with players which can move the needle (more scale)
- if markets get too consolidated Google can always launch a vertical service & tip the scale back in the other direction (I see your Amazon ad revenue and I raise you free product listing ads)
- the macroparasites have more “sameness” between them (making it easier for Google to create a competitive clone or copy)
So long as Google maintains a monopoly on web search the bias toward macroparasites works for them, as people can not see what they do not see & do not know what does not exist, or what exists but is hidden to them.
I think when people complain about the web being inauthentic what they are really complaining about is the algorithmic choices & publishing shifts that did away with the indy blogs and replaced with with the dopamine feed viral tricks and the same big box scaled players which operate multiple parallel sites to where you are getting the same machinery and content production house behind multiple consecutive listings. They are complaining about the efforts to snuff out the microparasite also scrubbing away personality, joy, love, quirkiness, weirdness, and the stuff you would not typically find on content by factory order websites.
Leading you down well worn paths, rather than the magic of serendipity & a personality worn on your sleeve that turns some people on while turning other people off.
Text which is roughly aligned with a backward looking consensus rather than at the forefront of a field.
If you believe this effort will enhance info literacy, and that it represents evolved search, you’re an idiot.
Sharyl Attkisson gave us the head’s up that they’d push censorship controls as “media literacy” several years ago.— john andrews (@johnandrews) August 13, 2022
Text which is perhaps factually correct, and maybe even current and informed, but done in such a way where you do not feel you know the author the way you might think you do if you read a great novel. Or hard biased content which purports to support some view and narrative, but is ultimately all just an act, where everything which could be of substance is ultimately subsumed by sales & marketing.
“The best relevancy algorithm in the world is trumped by preferential placement of inferior results which bypasses the algorithm.”
I was a fool to dismiss Aaron for years as a cynic. He was an oracle, not a conspiracy theorist: https://t.co/V68vIXXNPI— Rand Fishkin (@randfish) November 20, 2019
The Market for Something to Believe In is Infinite
Each re-representation mash-up of content in the search results decontextualizes the in-depth experience & passion we crave. Each same “big box” content factory where a backed entity can withstand algorithmic volatility & buy up other publishers to carry learnings across creates more of a bland sameness.
That barrier to entry & bland sameness is likely part of the reason the recent growth of Substack, which sort of acts just like a blog did 15 or 20 years ago – you go direct to the source without all the layers of intermediaries & dumbing down you get as a side effect of the scaled & polished publishing process.
Categories: