An update on Google’s feature-phone crawling & indexing
Limited mobile devices, “feature-phones”, require a special form of markup or a transcoder for web content. Most websites don’t provide feature-phone-compatible content in WAP/WML any more. Given these developments, we’ve made changes in how we crawl f…
Deprecating our AJAX crawling scheme
tl;dr: We are no longer recommending the AJAX crawling proposal we made back in 2009.
In 2009, we made a proposal to make AJAX pages crawlable. Back then, our systems were not able to render and understand pages that use JavaScript to present content to users. Because “crawlers … [were] not able to see any content … created dynamically,” we proposed a set of practices that webmasters can follow in order to ensure that their AJAX-based applications are indexed by search engines.
Times have changed. Today, as long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers. To reflect this improvement, we recently updated our technical Webmaster Guidelines to recommend against disallowing Googlebot from crawling your site’s CSS or JS files.
Since the assumptions for our 2009 proposal are no longer valid, we recommend following the principles of progressive enhancement. For example, you can use the History API pushState() to ensure accessibility for a wider range of browsers (and our systems).
Questions and answers
Q: My site currently follows your recommendation and supports _escaped_fragment_. Would my site stop getting indexed now that you’ve deprecated your recommendation?
A: No, the site would still be indexed. In general, however, we recommend you implement industry best practices when you’re making the next update for your site. Instead of the _escaped_fragment_ URLs, we’ll generally crawl, render, and index the #! URLs.
Q: Is moving away from the AJAX crawling proposal to industry best practices considered a site move? Do I need to implement redirects?
A: If your current setup is working fine, you should not have to immediately change anything. If you’re building a new site or restructuring an already existing site, simply avoid introducing _escaped_fragment_ urls. .
Q: I use a JavaScript framework and my webserver serves a pre-rendered page. Is that still ok?
A: In general, websites shouldn’t pre-render pages only for Google — we expect that you might pre-render pages for performance benefits for users and that you would follow progressive enhancement guidelines. If you pre-render pages, make sure that the content served to Googlebot matches the user’s experience, both how it looks and how it interacts. Serving Googlebot different content than a normal user would see is considered cloaking, and would be against our Webmaster Guidelines.
If you have any questions, feel free to post them here, or in the webmaster help forum.
Posted by Kazushi Nagayama, Search Quality Analyst

Unblocking resources with Webmaster Tools
Webmasters often use linked images, CSS, and JavaScript files in web pages to make them pretty and functional. If these resources are blocked from crawling, then Googlebot can’t use them when it renders those pages for search. Google Webmaster Tools no…
The four steps to appiness
Webmaster Level: intermediate to advanced
App deep links are the new kid on the block in organic search, and they’re picking up speed faster than you can say “schema.org ViewAction”! For signed-in users, 15% of Google searches on Android now return deep links to apps through App Indexing. And over just the past quarter, we’ve seen the number of clicks on app deep links jump by 10x.
We’ve gotten a lot of feedback from developers and seen a lot of implementations gone right and others that were good learning experiences since we opened up App Indexing back in June. We’d like to share with you four key steps to monitor app performance and drive user engagement:
1. Give your app developer access to Webmaster Tools
App indexing is a team effort between you (as a webmaster) and your app development team. We show information in Webmaster Tools that is key for your app developers to do their job well. Here’s what’s available right now:
- Errors in indexed pages within apps
- Weekly clicks and impressions from app deep link via Google search
- Stats on your sitemap (if that’s how you implemented the app deep links)
…and we plan to add a lot more in the coming months!
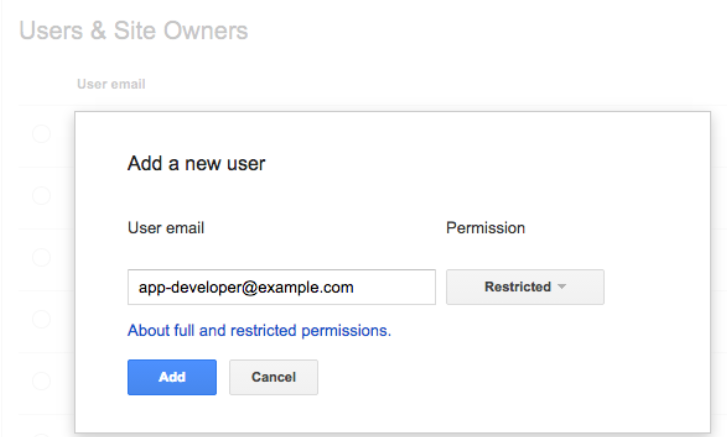
We’ve noticed that very few developers have access to Webmaster Tools. So if you want your app development team to get all of the information they need to fix app-related issues, it’s essential for them to have access to Webmaster Tools.
Any verified site owner can add a new user. Pick restricted or full permissions, depending on the level of access you’d like to give:
2. Understand how your app is doing in search results
How are users engaging with your app from search results? We’ve introduced two new ways for you to track performance for your app deep links:
- We now send a weekly clicks and impressions update to the Message center in your Webmaster Tools account.
- You can now track how much traffic app deep links drive to your app using referrer information – specifically, the referrer extra in the ACTION_VIEW intent. We’re working to integrate this information with Google Analytics for even easier access. Learn how to track referrer information on our Developer site.
3. Make sure key app resources can be crawled
Blocked resources are one of the top reasons for the “content mismatch” errors you see in Webmaster Tools’ Crawl Errors report. We need access to all the resources necessary to render your app page. This allows us to assess whether your associated web page has the same content as your app page.
To help you find and fix these issues, we now show you the specific resources we can’t access that are critical for rendering your app page. If you see a content mismatch error for your app, look out for the list of blocked resources in “Step 5” of the details dialog:

4. Watch out for Android App errors
To help you identify errors when indexing your app, we’ll send you messages for all app errors we detect, and will also display most of them in the “Android apps” tab of the Crawl errors report.
In addition to the currently available “Content mismatch” and “Intent URI not supported” error alerts, we’re introducing three new error types:
- APK not found: we can’t find the package corresponding to the app.
- No first-click free: the link to your app does not lead directly to the content, but requires login to access.
- Back button violation: after following the link to your app, the back button did not return to search results.
In our experience, the majority of errors are usually caused by a general setting in your app (e.g. a blocked resource, or a region picker that pops up when the user tries to open the app from search). Taking care of that generally resolves it for all involved URIs.
Good luck in the pursuit of appiness! As always, if you have questions, feel free to drop by our Webmaster help forum.
Posted by Mariya Moeva, Webmaster Trends Analyst
An improved search box within the search results
Webmaster level: All
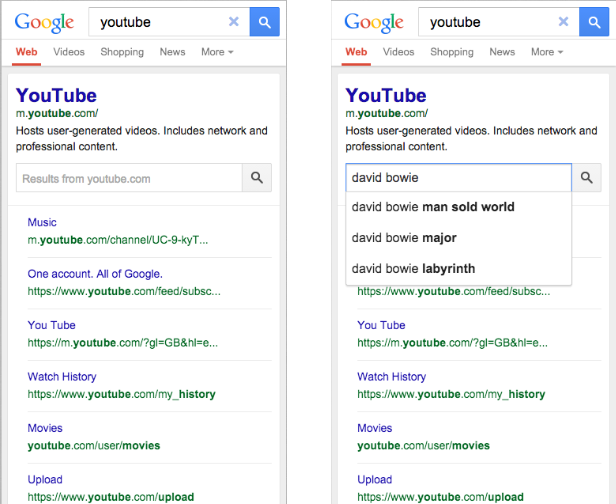
Today you’ll see a new and improved sitelinks search box. When shown, it will make it easier for users to reach specific content on your site, directly through your own site-search pages.
What’s this search box and when does it appear for my site?
When users search for a company by name—for example, [Megadodo Publications] or [Dunder Mifflin]—they may actually be looking for something specific on that website. In the past, when our algorithms recognized this, they’d display a larger set of sitelinks and an additional search box below that search result, which let users do site: searches over the site straight from the results, for example [site:example.com hitchhiker guides].
This search box is now more prominent (above the sitelinks), supports Autocomplete, and—if you use the right markup—will send the user directly to your website’s own search pages.

How can I mark up my site?
You need to have a working site-specific search engine for your site. If you already have one, you can let us know by marking up your homepage as a schema.org/WebSite entity with the potentialAction property of the schema.org/SearchAction markup. You can use JSON-LD, microdata, or RDFa to do this; check out the full implementation details on our developer site.
If you implement the markup on your site, users will have the ability to jump directly from the sitelinks search box to your site’s search results page. If we don’t find any markup, we’ll show them a Google search results page for the corresponding site: query, as we’ve done until now.
As always, if you have questions, feel free to ask in our Webmaster Help forum.
Posted by Mariya Moeva, Webmaster Trends Analyst, and Kaylin Spitz, Software Engineer
Android app indexing is now open for everyone!
Webmaster level: All



Do you have an Android app in addition to your website? You can now connect the two so that users searching from their smartphones and tablets can easily find and reach your app content.
App deep links in search results help your users find your content more easily and re-engage with your app after they’ve installed it. As a site owner, you can show your users the right content at the right time — by connecting pages of your website to the relevant parts of your app you control when your users are directed to your app and when they go to your website.

Hundreds of apps have already implemented app indexing. This week at Google I/O, we’re announcing a set of new features that will make it even easier to set up deep links in your app, connect your site to your app, and keep track of performance and potential errors.
Getting started is easy
We’ve greatly simplified the process to get your app deep links indexed. If your app supports HTTP deep linking schemes, here’s what you need to do:
- Add deep link support to your app
- Connect your site and your app
- There is no step 3 (:
As we index your URLs, we’ll discover and index the app / site connections and may begin to surface app deep links in search results.
We can discover and index your app deep links on our own, but we recommend you publish the deep links. This is also the case if your app only supports a custom deep link scheme. You publish them in one of two ways:
- Insert a rel=alternate elment in the section of each web page, or in your sitemap to specify app URIs. Find out how to implement these methods on our developer site.
- Use the App indexing API
There’s one more thing: we’ve added a new feature in Webmaster Tools to help you debug any issues that might arise during indexing app pages. It will show you what type of errors we’ve detected for the app page-web page pairs, together with example app URIs so you can debug:

We’ll also give you detailed instructions on how to debug each issue, including a QR code for the app deep links, so you can easily open them on your phone or tablet. We’ll send you Webmaster Tools error notifications as well, so you can keep up to date.

Give app indexing a spin, and as always, if you need more help ask questions on the Webmaster help forum.
Posted by Mariya Moeva, Webmaster Trends Analyst
Directing smartphone users to the page they actually wanted
Webmaster level: all


Have you ever used Google Search on your smartphone and clicked on a promising-looking result, only to end up on the mobile site’s homepage, with no idea why the page you were hoping to see vanished? This is such a common annoyance that we’ve even seen comics about it. Usually this happens because the website is not properly set up to handle requests from smartphones and sends you to its smartphone homepage—we call this a “faulty redirect”.
We’d like to spare users the frustration of landing on irrelevant pages and help webmasters fix the faulty redirects. Starting today in our English search results in the US, whenever we detect that smartphone users are redirected to a homepage instead of the the page they asked for, we may note it below the result. If you still wish to proceed to the page, you can click “Try anyway”:

And we’re providing advice and resources to help you direct your audience to the pages they want. Here’s a quick rundown:
1. Do a few searches on your own phone (or with a browser set up to act like a smartphone) and see how your site behaves. Simple but effective. :)
2. Check out Webmaster Tools—we’ll send you a message if we detect that any of your site’s pages are redirecting smartphone users to the homepage. We’ll also show you any faulty redirects we detect in the Smartphone Crawl Errors section of Webmaster Tools:
3. Investigate any faulty redirects and fix them. Here’s what you can do:
- Use the example URLs we provide in Webmaster Tools as a starting point to debug exactly where the problem is with your server configuration.
- Set up your server so that it redirects smartphone users to the equivalent URL on your smartphone site.
- If a page on your site doesn’t have a smartphone equivalent, keep users on the desktop page, rather than redirecting them to the smartphone site’s homepage. Doing nothing is better than doing something wrong in this case.
- Try using responsive web design, which serves the same content for desktop and smartphone users.
If you’d like to know more about building smartphone-friendly sites, read our full recommendations. And, as always, if you need more help you can ask a question in our webmaster forum.
Posted by Mariya Moeva, Webmaster Trends Analyst
Creating the Right Homepage for your International Users
If you are doing business in more than one country or targeting different languages, we recommend having separate sites or sections with specific content on each URLs targeted for individual countries or languages. For instance one page for US and english-speaking visitors, and a different page for France and french-speaking users. While we have information on handling multi-regional and multilingual sites, the homepage can be a bit special. This post will help you create the right homepage on your website to serve the appropriate content to users depending on their language and location.

There are three ways to configure your homepage / landing page when your users access it:
- Show everyone the same content.
- Let users choose.
- Serve content depending on users’ localization and language.
Let’s have a look at each in detail.
Show users worldwide the same content
In this scenario, you decide to serve specific content for one given country and language on your homepage / generic URL (http://www.example.com). This content will be available to anyone who accesses that URL directly in their browser or those who search for that URL specifically. As mentioned above, all country & language versions should also be accessible on their own unique URLs.
Note: You can show a banner on your page to suggest a more appropriate version to users from other locations or with different language settings.
Let users choose which local version and which language they want
In this configuration, you decide to serve a country selector page on your homepage / generic URL and to let users choose which content they want to see depending on country and language. All users who type in that URL can access the same page.
If you implement this scenario on your international site, remember to use the x-default rel-alternate-hreflang annotation for the country selector page, which was specifically created for these kinds of pages. The x-default value helps us recognize pages that are not specific to one language or region.

Automatically redirect users or dynamically serve the appropriate HTML content depending on users’ location and language settings
A third scenario would be to automatically serve the appropriate HTML content to your users depending on their location and language settings. You will either do that by using server-side 302 redirects or by dynamically serving the right HTML content.
Remember to use x-default rel-alternate-hreflang annotation on the homepage / generic page even if the latter is a redirect page that is not accessible directly for users.
Note: Think about redirecting users for whom you do not have a specific version. For instance, French-speaking users on a website that has English, Spanish and Chinese versions. Show them the content that you consider the most appropriate.
Whatever configuration you decide to go with, you should make sure all the pages – including country and language selector pages:
- Have rel-alternate-hreflang annotations.
- Are accessible for Googlebot’s crawling and indexing: do not block the crawling or indexing of your localized pages.
- Always allow users to switch local version or language: you can do that using a drop down menu for instance.
Reminder: As mentioned in the beginning, remember that you must have separate URLs for each country and language version.
About rel-alternate-hreflang annotations
Remember to annotate all your pages – whatever method you choose. This will greatly help search engines to show the right results to your users.
Country selector pages and redirecting or dynamically serving homepages should all use the x-default hreflang, which was specifically designed for auto-redirecting homepages and country selectors.
Finally, here are a few useful reminders about rel-alternate-hreflang annotations in general:
- Your annotations must be confirmed from the other pages. If page A links to page B, page B must link back to page A, otherwise, your annotations may not be interpreted correctly.
- Your annotations should be self-referential. Page A should use rel-alternate-hreflang annotation linking to itself.
- You can specify the rel-alternate-hreflang annotations in the HTTP header, in the head section of the HTML, or in a sitemap file. We strongly recommend that you choose only one way to implement the annotations, in order to avoid inconsistent signals and errors.
- The value of the hreflang attribute must be in ISO 639-1 format for the language, and in ISO 3166-1 Alpha 2 format for the region. Specifying only the region is not supported. If you wish to configure your site only for a country, use the geotargeting feature in Webmaster Tools.
Following these recommendations will help us better understand your localized content and serve more relevant results to your users in our search results. As always, if you have any questions or feedback, please tell us in the internationalization Webmaster Help Forum.
Posted by Zineb Ait Bahajji and Gary Illyes, Webmaster Trends Analysts.
App Indexing updates
Webmaster Level: Advanced

In October, we announced guidelines for App Indexing for deep linking directly from Google Search results to your Android app. Thanks to all of you that have expressed interest. We’ve just enabled 20+ additional applications that users will soon see app deep links for in Search Results, and starting today we’re making app deep links to English content available globally.
We’re continuing to onboard more publishers in all languages. If you haven’t added deep link support to your Android app or specified these links on your website or in your Sitemaps, please do so and then notify us by filling out this form.
Here are some best practices to consider when adding deep links to your sitemap or website:
- App deep links should only be included for canonical web URLs.
- Remember to specify an app deep link for your homepage.
- Not all website URLs in a Sitemap need to have a corresponding app deep link. Do not include app deep links that aren’t supported by your app.
- If you are a news site and use News Sitemaps, be sure to include your deep link annotations in the News Sitemaps, as well as your general Sitemaps.
- Don’t provide annotations for deep links that execute native ARM code. This enables app indexing to work for all platforms
When Google indexes content from your app, your app will need to make HTTP requests that it usually makes under normal operation. These requests will appear to your servers as originating from Googlebot. Therefore, your server’s robots.txt file must be configured properly to allow these requests.
Finally, please make sure the back button behavior of your app leads directly back to the search results page.
For more details on implementation, visit our updated developer guidelines. And, as always, you can ask questions on the mobile section of our webmaster forum.
Posted by Michael Xu, Software Engineer
More Precise Index Status Data for Your Site Variations
Webmaster Level: Intermediate

The Google Webmaster Tools Index Status feature reports how many pages on your site are indexed by Google. In the past, we didn’t show index status data for HTTPS websites independently, but rather we’d included everything in the HTTP site’s report. In the last months, we’ve heard from you that you’d like to use Webmaster Tools to track your indexed URLs for sections of your website, including the parts that use HTTPS.
We’ve seen that nearly 10% of all URLs already use a secure connection to transfer data via HTTPS, and we hope to see more webmasters move their websites from HTTP to HTTPS in the future. We’re happy to announce a refinement in the way your site’s index status data is displayed in Webmaster Tools: the Index Status feature now tracks your site’s indexed URLs for each protocol (HTTP and HTTPS) as well as for verified subdirectories.
This makes it easy for you to monitor different sections of your site. For example, the following URLs each show their own data in Webmaster Tools Index Status report, provided they are verified separately:
|
HTTP
|
HTTPS
|
The refined data will be visible for webmasters whose site’s URLs are on HTTPS or who have subdirectories verified, such as https://example.com/folder/. Data for subdirectories will be included in the higher-level verified sites on the same hostname and protocol.
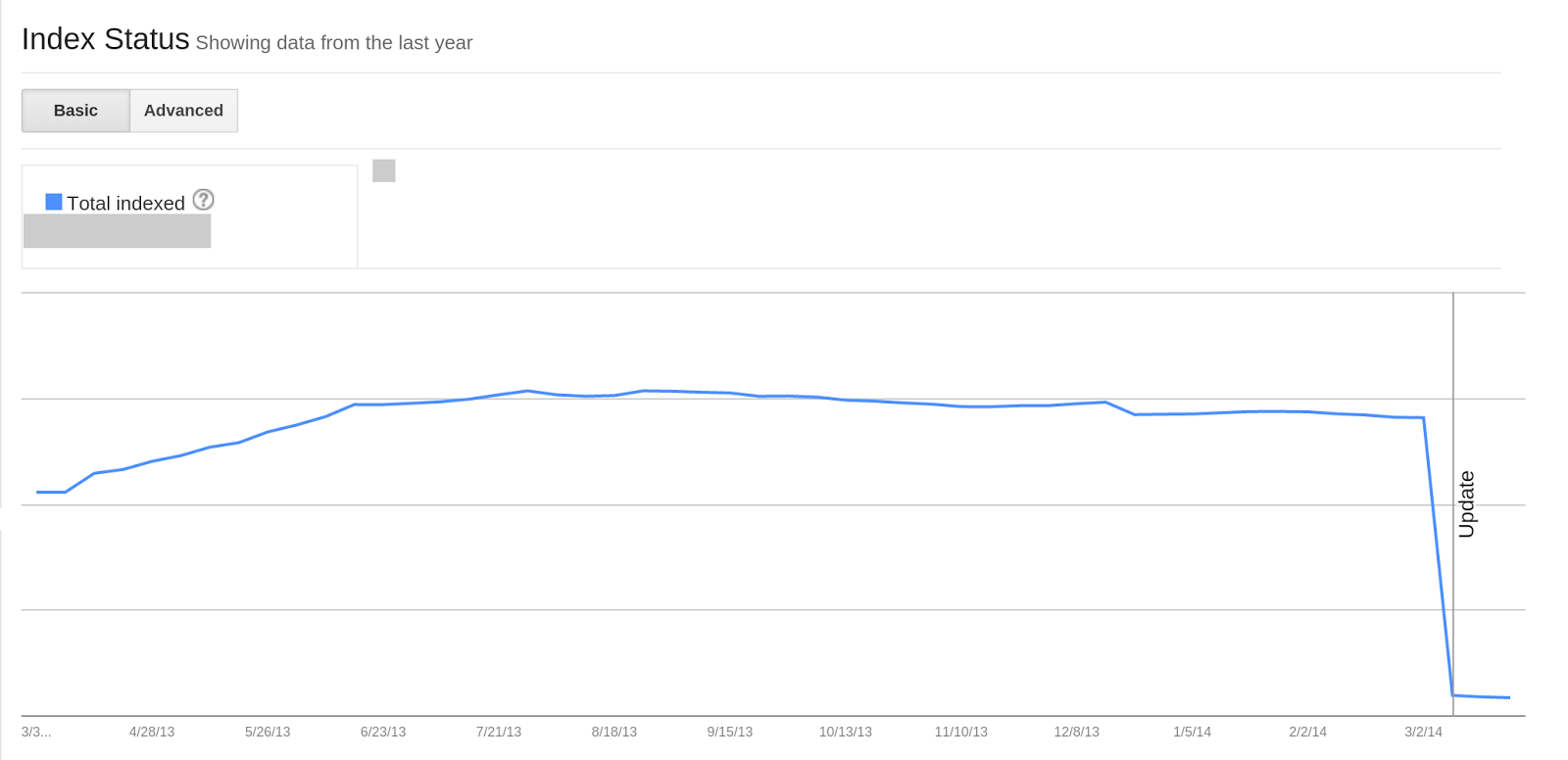
If you have a website on HTTPS or if some of your content is indexed under different subdomains, you will see a change in the corresponding Index Status reports. The screenshots below illustrate the changes that you may see on your HTTP and HTTPS sites’ Index Status graphs for instance:
HTTP site’s Index Status showing drop
HTTPS site’s Index Status showing increase
An “Update” annotation has been added to the Index Status graph for March 9th, showing when we started collecting this data. This change does not affect the way we index your URLs, nor does it have an impact on the overall number of URLs indexed on your domain. It is a change that only affects the reporting of data in Webmaster Tools user interface.
In order to see your data correctly, you will need to verify all existing variants of your site (www., non-www., HTTPS, subdirectories, subdomains) in Google Webmaster Tools. We recommend that your preferred domains and canonical URLs are configured accordingly.
Note that if you wish to submit a Sitemap, you will need to do so for the preferred variant of your website, using the corresponding URLs. Robots.txt files are also read separately for each protocol and hostname.
We hope that you’ll find this update useful, and that it’ll help you monitor, identify and fix indexing problems with your website. You can find additional details in our Index Status Help Center article. As usual, if you have any questions, don’t hesitate to ask in our webmaster Help Forum.
Posted by Zineb Ait Bahajji, WTA, thanks to the Webmaster Tools team.
Infinite scroll search-friendly recommendations
Webmaster Level: Advanced
Your site’s news feed or pinboard might use infinite scroll—much to your users’ delight! When it comes to delighting Googlebot, however, that can be another story. With infinite scroll, crawlers cannot always emulate manual user behavior–like scrolling or clicking a button to load more items–so they don’t always access all individual items in the feed or gallery. If crawlers can’t access your content, it’s unlikely to surface in search results.
To make sure that search engines can crawl individual items linked from an infinite scroll page, make sure that you or your content management system produces a paginated series (component pages) to go along with your infinite scroll.

Infinite scroll page is made “search-friendly” when converted to a paginated series — each component page has a similar <title> with rel=next/prev values declared in the <head>.
You can see this type of behavior in action in the infinite scroll with pagination demo created by Webmaster Trends Analyst, John Mueller. The demo illustrates some key search-engine friendly points:
- Coverage: All individual items are accessible. With traditional infinite scroll, individual items displayed after the initial page load aren’t discoverable to crawlers.
- No overlap: Each item is listed only once in the paginated series (i.e., no duplication of items).
Search-friendly recommendations for infinite scroll
- Before you start:
- Chunk your infinite-scroll page content into component pages that can be accessed when JavaScript is disabled.
- Determine how much content to include on each page.
- Be sure that if a searcher came directly to this page, they could easily find the exact item they wanted (e.g., without lots of scrolling before locating the desired content).
- Maintain reasonable page load time.
- Divide content so that there’s no overlap between component pages in the series (with the exception of buffering).
- Structure URLs for infinite scroll search engine processing.
- Each component page contains a full URL. We recommend full URLs in this situation to minimize potential for configuration error.
- Good:
example.com/category?name=fun-items&page=1 - Good:
example.com/fun-items?lastid=567 - Less optimal:
example.com/fun-items#1 - Test that each component page (the URL) works to take anyone directly to the content and is accessible/referenceable in a browser without the same cookie or user history.
- Good:
- Any key/value URL parameters should follow these recommendations:
- Be sure the URL shows conceptually the same content two weeks from now.
- Avoid relative-time based URL parameters:
example.com/category/page.php?name=fun-items&days-ago=3
- Avoid relative-time based URL parameters:
- Create parameters that can surface valuable content to searchers.
- Avoid non-searcher valuable parameters as the primary method to access content:
example.com/fun-places?radius=5&lat=40.71&long=-73.40
- Avoid non-searcher valuable parameters as the primary method to access content:
- Be sure the URL shows conceptually the same content two weeks from now.
- Each component page contains a full URL. We recommend full URLs in this situation to minimize potential for configuration error.
- Configure pagination with each component page containing rel=next and rel=prev values in the <head>. Pagination values in the <body> will be ignored for Google indexing purposes because they could be created with user-generated content (not intended by the webmaster).
- Implement replaceState/pushState on the infinite scroll page. (The decision to use one or both is up to you and your site’s user behavior). That said, we recommend including pushState (by itself, or in conjunction with replaceState) for the following:
- Any user action that resembles a click or actively turning a page.
- To provide users with the ability to serially backup through the most recently paginated content.
- Test!
- Check that page values adjust as the user scrolls up or down. John Mueller’s infinite-scroll-with-pagination site demonstrates the scrolling up/down behavior.
- Verify that pages that are out-of-bounds in the series return a 404 response (i.e.,
example.com/category?name=fun-items&page=999should return a 404 response if there are only 998 pages of content). - Investigate potential usability implications introduced by your infinite scroll implementation.

The example on the left is search-friendly, the right example isn’t — the right example would cause crawling and indexing of duplicative content.
Written, reviewed, or coded by John Mueller, Maile Ohye, and Joachim Kupke
Faceted navigation best (and 5 of the worst) practices
Webmaster Level: Advanced
Faceted navigation, such as filtering by color or price range, can be helpful for your visitors, but it’s often not search-friendly since it creates many combinations of URLs with duplicative content. With duplicative URLs, search engines may not crawl new or updated unique content as quickly, and/or they may not index a page accurately because indexing signals are diluted between the duplicate versions. To reduce these issues and help faceted navigation sites become as search-friendly as possible, we’d like to:
- Provide background and potential issues with faceted navigation
- Highlight worst practices
- Share best practices

Selecting filters with faceted navigation can cause many URL combinations, such as
http://www.example.com/category.php?category=gummy-candies&price=5-10&price=over-10Background
In an ideal state, unique content — whether an individual product/article or a category of products/articles — would have only one accessible URL. This URL would have a clear click path, or route to the content from within the site, accessible by clicking from the homepage or a category page.
Ideal for searchers and Google Search
- Clear path that reaches all individual product/article pages
On the left is potential user navigation on the site (i.e., the click path), on the right are the pages accessed.- One representative URL for category page
http://www.example.com/category.php?category=gummy-candies
Category page for gummy candies- One representative URL for individual product page
http://www.example.com/product.php?item=swedish-fish
Product page for swedish fishUndesirable duplication caused with faceted navigation
- Numerous URLs for the same article/product
Canonical Duplicate example.com/product.php? item=swedish-fishexample.com/product.php? item=swedish-fish&category=gummy-candies&price=5-10Same product page for swedish fish can be available on multiple URLs.
- Numerous category pages that provide little or no value to searchers and search engines)
URL example.com/category.php? category=gummy-candies&taste=sour&price=5-10example.com/category.php? category=gummy-candies&taste=sour&price=over-10Issues
- No added value to Google searchers given users rarely search for [sour gummy candy price five to ten dollars].
- No added value for search engine crawlers that discover same item (“fruit salad”) from parent category pages (either “gummy candies” or “sour gummy candies”).
- Negative value to site owner who may have indexing signals diluted between numerous versions of the same category.
- Negative value to site owner with respect to serving bandwidth and losing crawler capacity to duplicative content rather than new or updated pages.
- No value for search engines (should have 404 response code).
- Negative value to searchers.







Worst (search un-friendly) practices for faceted navigation
Worst practice #1: Non-standard URL encoding for parameters, like commas or brackets, instead of “key=value&” pairs.
Worst practices:
example.com/category?[category:gummy-candy][sort:price-low-to-high][sid:789]
- key=value pairs marked with : rather than =
- multiple parameters appended with [ ] rather than &
example.com/category?category,gummy-candy,,sort,lowtohigh,,sid,789
- key=value pairs marked with a , rather than =
- multiple parameters appended with ,, rather than &
Best practice:
example.com/category?category=gummy-candy&sort=low-to-high&sid=789While humans may be able to decode odd URL parameters, such as “,,”, crawlers have difficulty interpreting URL parameters when they’re implemented in a non-standard fashion. Software engineer on Google’s Crawling Team, Mehmet Aktuna, says “Using non-standard encoding is just asking for trouble.” Instead, connect key=value pairs with an equal sign (=) and append multiple parameters with an ampersand (&).
Worst practice #2: Using directories or file paths rather than parameters to list values that don’t change page content.
Worst practice:
example.com/c123/s789/product?swedish-fish
(where /c123/ is a category, /s789/ is a sessionID that doesn’t change page content)Good practice:
example.com/gummy-candy/product?item=swedish-fish&sid=789(the directory, /gummy-candy/,changes the page content in a meaningful way)Best practice:
example.com/product?item=swedish-fish&category=gummy-candy&sid=789(URL parameters allow more flexibility for search engines to determine how to crawl efficiently)It’s difficult for automated programs, like search engine crawlers, to differentiate useful values (e.g., “gummy-candy”) from the useless ones (e.g., “sessionID”) when values are placed directly in the path. On the other hand, URL parameters provide flexibility for search engines to quickly test and determine when a given value doesn’t require the crawler access all variations.
Common values that don’t change page content and should be listed as URL parameters include:
- Session IDs
- Tracking IDs
- Referrer IDs
- Timestamp
Worst practice #3: Converting user-generated values into (possibly infinite) URL parameters that are crawlable and indexable, but not useful in search results.
Worst practices (e.g., user-generated values like longitude/latitude or “days ago” as crawlable and indexable URLs):
example.com/find-a-doctor?radius=15&latitude=40.7565068&longitude=-73.9668408
example.com/article?category=health&days-ago=7Best practices:
example.com/find-a-doctor?city=san-francisco&neighborhood=soma
example.com/articles?category=health&date=january-10-2014Rather than allow user-generated values to create crawlable URLs — which leads to infinite possibilities with very little value to searchers — perhaps publish category pages for the most popular values, then include additional information so the page provides more value than an ordinary search results page. Alternatively, consider placing user-generated values in a separate directory and then robots.txt disallow crawling of that directory.
example.com/filtering/find-a-doctor?radius=15&latitude=40.7565068&longitude=-73.9668408example.com/filtering/articles?category=health&days-ago=7with robots.txt:
User-agent: *
Disallow: /filtering/Worst practice #4: Appending URL parameters without logic.
Worst practices:
example.com/gummy-candy/lollipops/gummy-candy/gummy-candy/product?swedish-fishexample.com/product?cat=gummy-candy&cat=lollipops&cat=gummy-candy&cat=gummy-candy&item=swedish-fishBetter practice:
example.com/gummy-candy/product?item=swedish-fishBest practice:
example.com/product?item=swedish-fish&category=gummy-candyExtraneous URL parameters only increase duplication, causing less efficient crawling and indexing. Therefore, consider stripping unnecessary URL parameters and performing your site’s “internal housekeeping” before generating the URL. If many parameters are required for the user session, perhaps hide the information in a cookie rather than continually append values like
cat=gummy-candy&cat=lollipops&cat=gummy-candy&…Worst practice #5: Offering further refinement (filtering) when there are zero results.
Worst practice:
Allowing users to select filters when zero items exist for the refinement.
Refinement to a page with zero results (e.g.,price=over-10) is allowed even though it frustrates users and causes unnecessary issues for search engines.Best practice
Only create links/URLs when it’s a valid user-selection (items exist). With zero items, grey out filtering options. To further improve usability, consider adding item counts next to each filter.
Refinement to a page with zero results (e.g.,price=over-10) isn’t allowed, preventing users from making an unnecessary click and search engine crawlers from accessing a non-useful page.Prevent useless URLs and minimize the crawl space by only creating URLs when products exist. This helps users to stay engaged on your site (fewer clicks on the back button when no products exist), and helps minimize potential URLs known to crawlers. Furthermore, if a page isn’t just temporarily out-of-stock, but is unlikely to ever contain useful content, consider returning a 404 status code. With the 404 response, you can include a helpful message to users with more navigation options or a search box to find related products.


Best practices for new faceted navigation implementations or redesigns
New sites that are considering implementing faceted navigation have several options to optimize the “crawl space” (the totality of URLs on your site known to Googlebot) for unique content pages, reduce crawling of duplicative pages, and consolidate indexing signals.
- Determine which URL parameters are required for search engines to crawl every individual content page (i.e., determine what parameters are required to create at least one click-path to each item). Required parameters may include
item-id,category-id,page, etc.- Determine which parameters would be valuable to searchers and their queries, and which would likely only cause duplication with unnecessary crawling or indexing. In the candy store example, I may find the URL parameter “
taste” to be valuable to searchers for queries like [sour gummy candies] which could show the resultexample.com/category.php?category=gummy-candies&taste=sour. However, I may consider the parameter “price” to only cause duplication, such ascategory=gummy-candies&taste=sour&price=over-10. Other common examples:
- Valuable parameters to searchers:
item-id,category-id,name,brand…- Unnecessary parameters:
session-id,price-range…- Consider implementing one of several configuration options for URLs that contain unnecessary parameters. Just make sure that the unnecessary URL parameters are never required in a crawler or user’s click path to reach each individual product!
- Option 1: rel=”nofollow” internal links
Make all unnecessary URLs links rel=“nofollow.” This option minimizes the crawler’s discovery of unnecessary URLs and therefore reduces the potentially explosive crawl space (URLs known to the crawler) that can occur with faceted navigation. rel=”nofollow” doesn’t prevent the unnecessary URLs from being crawled (only a robots.txt disallow prevents crawling). By allowing them to be crawled, however, you can consolidate indexing signals from the unnecessary URLs with a searcher-valuable URL by adding rel=”canonical” from the unnecessary URL to a superset URL (e.g.
example.com/category.php?category=gummy-candies&taste=sour&price=5-10can specify arel=”canonical”to the superset sour gummy candies view-all page atexample.com/category.php?category=gummy-candies&taste=sour&page=all).- Option 2: Robots.txt disallow
For URLs with unnecessary parameters, include a
/filtering/directory that will be robots.txt disallow’d. This lets all search engines freely crawl good content, but will prevent crawling of the unwanted URLs. For instance, if my valuable parameters were item, category, and taste, and my unnecessary parameters were session-id and price. I may have the URL:example.com/category.php?category=gummy-candies
which could link to another URL valuable parameter such as taste:example.com/category.php?category=gummy-candies&taste=sour.
but for the unnecessary parameters, such as price, the URL includes a predefined directory,/filtering/:example.com/filtering/category.php?category=gummy-candies&price=5-10
which is then robots.txt disallowed
User-agent: *
Disallow: /filtering/- Option 3: Separate hosts
If you’re not using a CDN (sites using CDNs don’t have this flexibility easily available in Webmaster Tools), consider placing any URLs with unnecessary parameters on a separate host — for example, creating main host
www.example.comand secondary host,www2.example.com. On the secondary host (www2), set the Crawl rate in Webmaster Tools to “low” while keeping the main host’s crawl rate as high as possible. This would allow for more full crawling of the main host URLs and reduces Googlebot’s focus on your unnecessary URLs.
- Be sure there remains at least one click path to all items on the main host.
- If you’d like to consolidate indexing signals, consider adding rel=”canonical” from the secondary host to a superset URL on the main host (e.g.
www2.example.com/category.php?category=gummy-candies&taste=sour&price=5-10may specify a rel=”canonical” to the superset “sour gummy candies” view-all page,www.example.com/category.php?category=gummy-candies&taste=sour&page=all).
- Prevent clickable links when no products exist for the category/filter.
- Add logic to the display of URL parameters.
- Remove unnecessary parameters rather than continuously append values.
- Avoid
example.com/product?cat=gummy-candy&cat=lollipops&cat=gummy-candy&item=swedish-fish)- Help the searcher experience by keeping a consistent parameter order based on searcher-valuable parameters listed first (as the URL may be visible in search results) and searcher-irrelevant parameters last (e.g., session ID).
- Avoid
example.com/category.php?session-id=123&tracking-id=456&category=gummy-candies&taste=sour- Improve indexing of individual content pages with rel=”canonical” to the preferred version of a page. rel=”canonical” can be used across hostnames or domains.
- Improve indexing of paginated content (such as page=1 and page=2 of the category “gummy candies”) by either:
- Adding rel=”canonical” from individual component pages in the series to the category’s “view-all” page (e.g. page=1, page=2, and page=3 of “gummy candies” with rel=”canonical” to
category=gummy-candies&page=all) while making sure that it’s still a good searcher experience (e.g., the page loads quickly).- Using pagination markup with rel=”next” and rel=”prev” to consolidate indexing properties, such as links, from the component pages/URLs to the series as a whole.
- Be sure that if using JavaScript to dynamically sort/filter/hide content without updating the URL, there still exists URLs on your site that searchers would find valuable, such as main category and product pages that can be crawled and indexed. For instance, avoid using only the homepage (i.e., one URL) for your entire site with JavaScript to dynamically change content with user navigation — this would unfortunately provide searchers with only one URL to reach all of your content. Also, check that performance isn’t negatively affected with dynamic filtering, as this could undermine the user experience.
- Include only canonical URLs in Sitemaps.
Best practices for existing sites with faceted navigation
First, know that the best practices listed above (e.g., rel=”nofollow” for unnecessary URLs) still apply if/when you’re able to implement a larger redesign. Otherwise, with existing faceted navigation, it’s likely that a large crawl space was already discovered by search engines. Therefore, focus on reducing further growth of unnecessary pages crawled by Googlebot and consolidating indexing signals.
- Use parameters (when possible) with standard encoding and key=value pairs.
- Verify that values that don’t change page content, such as session IDs, are implemented as standard key=value pairs, not directories
- Prevent clickable anchors when products exist for the category/filter (i.e., don’t allow clicks or URLs to be created when no items exist for the filter)
- Add logic to the display of URL parameters
- Remove unnecessary parameters rather than continuously append values (e.g., avoid
example.com/product?cat=gummy-candy&cat=lollipops&cat=gummy-candy&item=swedish-fish)- Help the searcher experience by keeping a consistent parameter order based on searcher-valuable parameters listed first (as the URL may be visible in search results) and searcher-irrelevant parameters last (e.g., avoid
example.com/category?session-id=123&tracking-id=456&category=gummy-candies&taste=sour&in favor ofexample.com/category.php?category=gummy-candies&taste=sour&session-id=123&tracking-id=456)- Configure Webmaster Tools URL Parameters if you have strong understanding of the URL parameter behavior on your site (make sure that there is still a clear click path to each individual item/article). For instance, with URL Parameters in Webmaster Tools, you can list the parameter name, the parameters effect on the page content, and how you’d like Googlebot to crawl URLs containing the parameter.
URL Parameters in Webmaster Tools allows the site owner to provide information about the site’s parameters and recommendations for Googlebot’s behavior.- Be sure that if using JavaScript to dynamically sort/filter/hide content without updating the URL, there still exists URLs on your site that searchers would find valuable, such as main category and product pages that can be crawled and indexed. For instance, avoid using only the homepage (i.e., one URL) for your entire site with JavaScript to dynamically change content with user navigation — this would unfortunately provide searchers with only one URL to reach all of your content. Also, check that performance isn’t negatively affected with dynamic filtering, as this could undermine the user experience.
- Improve indexing of individual content pages with rel=”canonical” to the preferred version of a page. rel=”canonical” can be used across hostnames or domains.
- Improve indexing of paginated content (such as page=1 and page=2 of the category “gummy candies”) by either:
- Adding rel=”canonical” from individual component pages in the series to the category’s “view-all” page (e.g. page=1, page=2, and page=3 of “gummy candies” with rel=”canonical” to
category=gummy-candies&page=all) while making sure that it’s still a good searcher experience (e.g., the page loads quickly).- Using pagination markup with rel=”next” and rel=”prev” to consolidate indexing properties, such as links, from the component pages/URLs to the series as a whole.
- Include only canonical URLs in Sitemaps.

Remember that commonly, the simpler you can keep it, the better. Questions? Please ask in our Webmaster discussion forum.
Written by Maile Ohye, Developer Programs Tech Lead, and Mehmet Aktuna, Crawl Team
Changes in crawl error reporting for redirects
Webmaster level: intermediate-advancedIn the past, we have seen occasional confusion by webmasters regarding how crawl errors on redirecting pages were shown in Webmaster Tools. It’s time to make this a bit clearer and easier to diagnose! While it used…
Indexing apps just like websites
Webmaster Level: Advanced

Searchers on smartphones experience many speed bumps that can slow them down. For example, any time they need to change context from a web page to an app, or vice versa, users are likely to encounter redirects, pop-up dialogs, and extra swipes and taps. Wouldn’t it be cool if you could give your users the choice of viewing your content either on the website or via your app, both straight from Google’s search results?
Today, we’re happy to announce a new capability of Google Search, called app indexing, that uses the expertise of webmasters to help create a seamless user experience across websites and mobile apps.
Just like it crawls and indexes websites, Googlebot can now index content in your Android app. Webmasters will be able to indicate which app content you’d like Google to index in the same way you do for webpages today — through your existing Sitemap file and through Webmaster Tools. If both the webpage and the app contents are successfully indexed, Google will then try to show deep links to your app straight in our search results when we think they’re relevant for the user’s query and if the user has the app installed. When users tap on these deep links, your app will launch and take them directly to the content they need. Here’s an example of a search for home listings in Mountain View:
We’re currently testing app indexing with an initial group of developers. Deep links for these applications will start to appear in Google search results for signed-in users on Android in the US in a few weeks. If you are interested in enabling indexing for your Android app, it’s easy to get started:
- Let us know that you’re interested. We’re working hard to bring this functionality to more websites and apps in the near future.
- Enable deep linking within your app.
- Provide information about alternate app URIs, either in the Sitemaps file or in a link element in pages of your site.
For more details on implementation and for information on how to sign up, visit our developer site. As always, if you have any questions, please ask in the mobile section of our webmaster forum.
Posted by Lawrence Chang, Product Manager
Video: Expanding your site to more languages
Webmaster Level: Intermediate to Advanced
We filmed a video providing more details about expanding your site to more languages or country-based language variations. The video covers details about rel=”alternate” hreflang and potential implementation on your multilingual and/or multinational site.
Video and slides on expanding your site to more languages
You can watch the entire video or skip to the relevant sections:
- Potential search issues with international sites
- Questions to ask within your company before beginning international expansion
- International site use cases
- rel=”alternate” hreflang and hreflang=”x-default”: details and implementation
- Best practices
Additional resources on hreflang include:
- Webmaster Help Center article on rel=”alternate” hreflang and hreflang=”x-default”
- More blog posts
- Working with multilingual sites
- Working with multiregional sites
- New markup for multilingual content
- Introducing “x-default hreflang” for international landing pages”
- Webmaster discussion forum FAQ on internationalization
- Webmaster discussion forum for internationalization (review answers or post your own question!)
Good luck as you expand your site to more languages!
Written by Maile Ohye, Developer Programs Tech Lead
5 common mistakes with rel=canonical
Webmaster Level: Intermediate to Advanced
Including a rel=canonical link in your webpage is a strong hint to search engines your preferred version to index among duplicate pages on the web. It’s supported by several search engines, including Yahoo!, Bing, and Google. The rel=canonical link consolidates indexing properties from the duplicates, like their inbound links, as well as specifies which URL you’d like displayed in search results. However, rel=canonical can be a bit tricky because it’s not very obvious when there’s a misconfiguration.
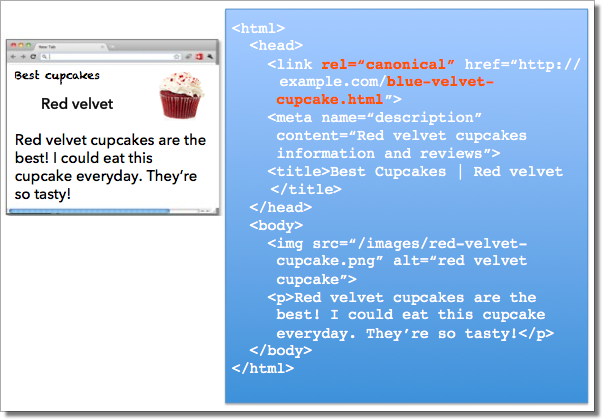
While the webmaster sees the “red velvet” page on the left in their browser, search engines notice on the webmaster’s unintended “blue velvet” rel=canonical on the right.
We recommend the following best practices for using rel=canonical:
- A large portion of the duplicate page’s content should be present on the canonical version.
- Double-check that your rel=canonical target exists (it’s not an error or “soft 404”)
- Verify the rel=canonical target doesn’t contain a noindex robots meta tag
- Make sure you’d prefer the rel=canonical URL to be displayed in search results (rather than the duplicate URL)
- Include the rel=canonical link in either the <head> of the page or the HTTP header
- Specify no more than one rel=canonical for a page. When more than one is specified, all rel=canonicals will be ignored.
One test is to imagine you don’t understand the language of the content—if you placed the duplicate side-by-side with the canonical, does a very large percentage of the words of the duplicate page appear on the canonical page? If you need to speak the language to understand that the pages are similar; for example, if they’re only topically similar but not extremely close in exact words, the canonical designation might be disregarded by search engines.
Mistake 1: rel=canonical to the first page of a paginated series
Imagine that you have an article that spans several pages:
- example.com/article?story=cupcake-news&page=1
- example.com/article?story=cupcake-news&page=2
- and so on
Specifying a rel=canonical from page 2 (or any later page) to page 1 is not correct use of rel=canonical, as these are not duplicate pages. Using rel=canonical in this instance would result in the content on pages 2 and beyond not being indexed at all.

Good content (e.g., “cookies are superior nutrition” and “to vegetables”) is lost when specifying rel=canonical from component pages to the first page of a series.
In cases of paginated content, we recommend either a rel=canonical from component pages to a single-page version of the article, or to use rel=”prev” and rel=”next” pagination markup.

rel=canonical from component pages to the view-all page

If rel=canonical to a view-all page isn’t designated, paginated content can use rel=”prev” and rel=”next” markup.
Mistake 2: Absolute URLs mistakenly written as relative URLs

The <link> tag, like many HTML tags, accepts both relative and absolute URLs. Relative URLs include a path “relative” to the current page. For example, “images/cupcake.png” means “from the current directory go to the “images” subdirectory, then to cupcake.png.” Absolute URLs specify the full path—including the scheme like http://.
Specifying <link rel=canonical href=“example.com/cupcake.html” /> (a relative URL since there’s no “http://”) implies that the desired canonical URL is http://example.com/example.com/cupcake.html even though that is almost certainly not what was intended. In these cases, our algorithms may ignore the specified rel=canonical. Ultimately this means that whatever you had hoped to accomplish with this rel=canonical will not come to fruition.
Mistake 3: Unintended or multiple declarations of rel=canonical
Occasionally, we see rel=canonical designations that we believe are unintentional. In very rare circumstances we see simple typos, but more commonly a busy webmaster copies a page template without thinking to change the target of the rel=canonical. Now the site owner’s pages specify a rel=canonical to the template author’s site.

If you use a template, check that you didn’t also copy the rel=canonical specification.
Another issue is when pages include multiple rel=canonical links to different URLs. This happens frequently in conjunction with SEO plugins that often insert a default rel=canonical link, possibly unbeknownst to the webmaster who installed the plugin. In cases of multiple declarations of rel=canonical, Google will likely ignore all the rel=canonical hints. Any benefit that a legitimate rel=canonical might have offered will be lost.
In both these types of cases, double-checking the page’s source code will help correct the issue. Be sure to check the entire <head> section as the rel=canonical links may be spread apart.

Check the behavior of plugins by looking at the page’s source code.
Mistake 4: Category or landing page specifies rel=canonical to a featured article
Let’s say you run a site about desserts. Your dessert site has useful category pages like “pastry” and “gelato.” Each day the category pages feature a unique article. For instance, your pastry landing page might feature “red velvet cupcakes.” Because the “pastry” category page has nearly all the same content as the “red velvet cupcake” page, you add a rel=canonical from the category page to the featured individual article.
If we were to accept this rel=canonical, then your pastry category page would not appear in search results. That’s because the rel=canonical signals that you would prefer search engines display the canonical URL in place of the duplicate. However, if you want users to be able to find both the category page and featured article, it’s best to only have a self-referential rel=canonical on the category page, or none at all.

Remember that the canonical designation also implies the preferred display URL. Avoid adding a rel=canonical from a category or landing page to a featured article.
Mistake 5: rel=canonical in the <body>
The rel=canonical link tag should only appear in the <head> of an HTML document. Additionally, to avoid HTML parsing issues, it’s good to include the rel=canonical as early as possible in the <head>. When we encounter a rel=canonical designation in the <body>, it’s disregarded.
This is an easy mistake to correct. Simply double-check that your rel=canonical links are always in the <head> of your page, and as early as possible if you can.

rel=canonical designations in the <head> are processed, not the <body>.
Conclusion
To create valuable rel=canonical designations:
- Verify that most of the main text content of a duplicate page also appears in the canonical page.
- Check that rel=canonical is only specified once (if at all) and in the <head> of the page.
- Check that rel=canonical points to an existent URL with good content (i.e., not a 404, or worse, a soft 404).
- Avoid specifying rel=canonical from landing or category pages to featured articles as that will make the featured article the preferred URL in search results.
And, as always, please ask any questions in our Webmaster Help forum.
Written by Allan Scott, Software Engineer, Indexing Team
A new opt-out tool
Webmasters have several ways to keep their sites’ content out of Google’s search results. Today, as promised, we’re providing a way for websites to opt out of having their content that Google has crawled appear on Google Shopping, Advisor, Flights, Ho…
We created a first steps cheat sheet for friends & family
Webmaster level: beginner
Everyone knows someone who just set up their first blog on Blogger, installed WordPress for the first time or maybe who had a web site for some time but never gave search much thought. We came up with a first steps cheat sheet for just these folks. It’s a short how-to list with basic tips on search engine-friendly design, that can help Google and others better understand the content and increase your site’s visibility. We made sure it’s available in thirteen languages. Please feel free to read it, print it, share it, copy and distribute it!
We hope this content will help those who are just about to start their webmaster adventure or have so far not paid too much attention to search engine-friendly design. Over time as you gain experience you may want to have a look at our more advanced Google SEO Starter Guide. As always we welcome all webmasters and site owners, new and experienced to join discussions on our Google Webmaster Help Forum.
Configuring URL Parameters in Webmaster Tools
Webmaster Level: Intermediate to Advanced
We recently filmed a video (with slides available) to provide more information about the URL Parameters feature in Webmaster Tools. The URL Parameters feature is designed for webmasters who want to help Google crawl their site more efficiently, and who manage a site with — you guessed it — URL parameters! To be eligible for this feature, the URL parameters must be configured in key/value pairs like item=swedish-fish or category=gummy-candy in the URL http://www.example.com/product.php?item=swedish-fish&category=gummy-candy.
Guidance for common cases when configuring URL Parameters. Music in the background masks the ongoing pounding of my neighbor’s construction!
URL Parameter settings are powerful. By telling us how your parameters behave and the recommended action for Googlebot, you can improve your site’s crawl efficiency. On the other hand, if configured incorrectly, you may accidentally recommend that Google ignore important pages, resulting in those pages no longer being available in search results. (There’s an example provided in our improved Help Center article.) So please take care when adjusting URL Parameters settings, and be sure that the actions you recommend for Googlebot make sense across your entire site.
Written by Maile Ohye, Developer Programs Tech Lead