Internet Wayback Machine Adds Historical TextDiff
The Wayback Machine has a cool new feature for looking at the historical changes of a web page.
The color scale shows how much a page has changed since it was last cached & you can select between any two documents to see how a page has changed ove…
Dofollow, Nofollow, Sponsored, UGC
A Change to Nofollow
Last month Google announced they were going to change how they treated nofollow, moving it from a directive toward a hint. As part of that they also announced the release of parallel attributes rel=”sponsored” for sponsored links & rel=”ugc” for user generated content in areas like forums & blog comments.
Why not completely ignore such links, as had been the case with nofollow? Links contain valuable information that can help us improve search, such as how the words within links describe content they point at. Looking at all the links we encounter can also help us better understand unnatural linking patterns. By shifting to a hint model, we no longer lose this important information, while still allowing site owners to indicate that some links shouldn’t be given the weight of a first-party endorsement.
In many emerging markets the mobile web is effectively the entire web. Few people create HTML links on the mobile web outside of on social networks where links are typically nofollow by default. This reduces the potential signal available to either tracking what people do directly and/or shifting how the nofollow attribute is treated.
Google shifting how nofollow is treated is a blanket admission that Penguin & other elements of “the war on links” were perhaps a bit too effective and have started to take valuable signals away from Google.
Google has suggested the shift in how nofollow is treated will not lead to any additional blog comment spam. When they announced nofollow they suggested it would lower blog comment spam. Blog comment spam remains a growth market long after the gravity of the web has shifted away from blogs onto social networks.
Changing how nofollow is treated only makes any sort of external link analysis that much harder. Those who specialize in link audits (yuck!) have historically ignored nofollow links, but now that is one more set of things to look through. And the good news for professional link auditors is that increases the effective cost they can charge clients for the service.
Some nefarious types will notice when competitors get penalized & then fire up Xrummer to help promote the penalized site, ensuring that the link auditor bankrupts the competing business even faster than Google.
Links, Engagement, or Something Else…
When Google was launched they didn’t own Chrome or Android. They were not yet pervasively spying on billions of people:
If, like most people, you thought Google stopped tracking your location once you turned off Location History in your account settings, you were wrong. According to an AP investigation published Monday, even if you disable Location History, the search giant still tracks you every time you open Google Maps, get certain automatic weather updates, or search for things in your browser.
Thus Google had to rely on external signals as their primary ranking factor:
The reason that PageRank is interesting is that there are many cases where simple citation counting does not correspond to our common sense notion of importance. For example, if a web page has a link on the Yahoo home page, it may be just one link but it is a very important one. This page should be ranked higher than many pages with more links but from obscure places. PageRank is an attempt to see how good an approximation to “importance” can be obtained just from the link structure. … The denition of PageRank above has another intuitive basis in random walks on graphs. The simplied version corresponds to the standing probability distribution of a random walk on the graph of the Web. Intuitively, this can be thought of as modeling the behavior of a “random surfer”.
Google’s reliance on links turned links into a commodity, which led to all sorts of fearmongering, manual penalties, nofollow and the Penguin update.
As Google collected more usage data those who overly focused on links often ended up scoring an own goal, creating sites which would not rank.
Google no longer invests heavily in fearmongering because it is no longer needed. Search is so complex most people can’t figure it out.
Many SEOs have reduced their link building efforts as Google dialed up weighting on user engagement metrics, though it appears the tide may now be heading in the other direction. Some sites which had decent engagement metrics but little in the way of link building slid on the update late last month.
As much as Google desires relevancy in the short term, they also prefer a system complex enough to external onlookers that reverse engineering feels impossible. If they discourage investment in SEO they increase AdWords growth while gaining greater control over algorithmic relevancy.
Google will soon collect even more usage data by routing Chrome users through their DNS service: “Google isn’t actually forcing Chrome users to only use Google’s DNS service, and so it is not centralizing the data. Google is instead configuring Chrome to use DoH connections by default if a user’s DNS service supports it.”
If traffic is routed through Google that is akin to them hosting the page in terms of being able to track many aspects of user behavior. It is akin to AMP or YouTube in terms of being able to track users and normalize relative engagement metrics.
Once Google is hosting the end-to-end user experience they can create a near infinite number of ranking signals given their advancement in computing power: “We developed a new 54-qubit processor, named “Sycamore”, that is comprised of fast, high-fidelity quantum logic gates, in order to perform the benchmark testing. Our machine performed the target computation in 200 seconds, and from measurements in our experiment we determined that it would take the world’s fastest supercomputer 10,000 years to produce a similar output.”
Relying on “one simple trick to…” sorts of approaches are frequently going to come up empty.
EMDs Kicked Once Again
I was one of the early promoters of exact match domains when the broader industry did not believe in them. I was also quick to mention when I felt the algorithms had moved in the other direction.
Google’s mobile layout, which they are now testing on desktop computers as well, replaces green domain names with gray words which are easy to miss. And the favicon icons sort of make the organic results look like ads. Any boost a domain name like CreditCards.ext might have garnered in the past due to matching the keyword has certainly gone away with this new layout that further depreciates the impact of exact-match domain names.
At one point in time CreditCards.com was viewed as a consumer destination. It is now viewed … below the fold.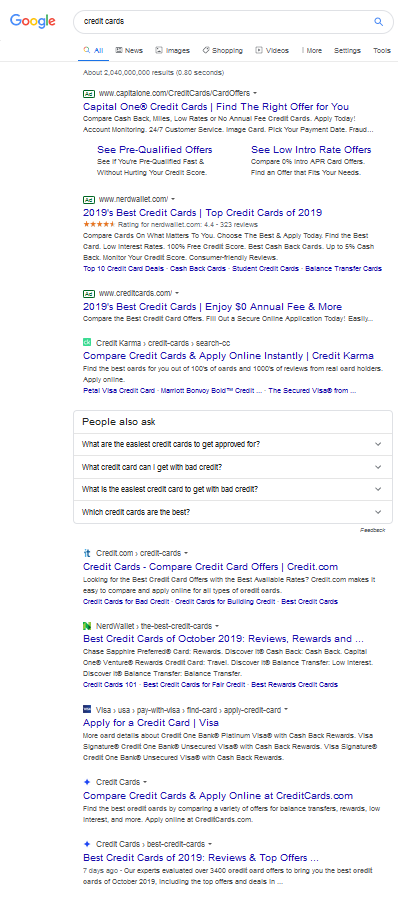
If you have a memorable brand-oriented domain name the favicon can help offset the above impact somewhat, but matching keywords is becoming a much more precarious approach to sustaining rankings as the weight on brand awareness, user engagement & authority increase relative to the weight on anchor text.
Categories:
Dofollow, Nofollow, Sponsored, UGC
A Change to Nofollow
Last month Google announced they were going to change how they treated nofollow, moving it from a directive toward a hint. As part of that they also announced the release of parallel attributes rel=”sponsored” for sponsored links & rel=”ugc” for user generated content in areas like forums & blog comments.
Why not completely ignore such links, as had been the case with nofollow? Links contain valuable information that can help us improve search, such as how the words within links describe content they point at. Looking at all the links we encounter can also help us better understand unnatural linking patterns. By shifting to a hint model, we no longer lose this important information, while still allowing site owners to indicate that some links shouldn’t be given the weight of a first-party endorsement.
In many emerging markets the mobile web is effectively the entire web. Few people create HTML links on the mobile web outside of on social networks where links are typically nofollow by default. This reduces the potential signal available to either tracking what people do directly and/or shifting how the nofollow attribute is treated.
Google shifting how nofollow is treated is a blanket admission that Penguin & other elements of “the war on links” were perhaps a bit too effective and have started to take valuable signals away from Google.
Google has suggested the shift in how nofollow is treated will not lead to any additional blog comment spam. When they announced nofollow they suggested it would lower blog comment spam. Blog comment spam remains a growth market long after the gravity of the web has shifted away from blogs onto social networks.
Changing how nofollow is treated only makes any sort of external link analysis that much harder. Those who specialize in link audits (yuck!) have historically ignored nofollow links, but now that is one more set of things to look through. And the good news for professional link auditors is that increases the effective cost they can charge clients for the service.
Some nefarious types will notice when competitors get penalized & then fire up Xrummer to help promote the penalized site, ensuring that the link auditor bankrupts the competing business even faster than Google.
Links, Engagement, or Something Else…
When Google was launched they didn’t own Chrome or Android. They were not yet pervasively spying on billions of people:
If, like most people, you thought Google stopped tracking your location once you turned off Location History in your account settings, you were wrong. According to an AP investigation published Monday, even if you disable Location History, the search giant still tracks you every time you open Google Maps, get certain automatic weather updates, or search for things in your browser.
Thus Google had to rely on external signals as their primary ranking factor:
The reason that PageRank is interesting is that there are many cases where simple citation counting does not correspond to our common sense notion of importance. For example, if a web page has a link on the Yahoo home page, it may be just one link but it is a very important one. This page should be ranked higher than many pages with more links but from obscure places. PageRank is an attempt to see how good an approximation to “importance” can be obtained just from the link structure. … The denition of PageRank above has another intuitive basis in random walks on graphs. The simplied version corresponds to the standing probability distribution of a random walk on the graph of the Web. Intuitively, this can be thought of as modeling the behavior of a “random surfer”.
Google’s reliance on links turned links into a commodity, which led to all sorts of fearmongering, manual penalties, nofollow and the Penguin update.
As Google collected more usage data those who overly focused on links often ended up scoring an own goal, creating sites which would not rank.
Google no longer invests heavily in fearmongering because it is no longer needed. Search is so complex most people can’t figure it out.
Many SEOs have reduced their link building efforts as Google dialed up weighting on user engagement metrics, though it appears the tide may now be heading in the other direction. Some sites which had decent engagement metrics but little in the way of link building slid on the update late last month.
As much as Google desires relevancy in the short term, they also prefer a system complex enough to external onlookers that reverse engineering feels impossible. If they discourage investment in SEO they increase AdWords growth while gaining greater control over algorithmic relevancy.
Google will soon collect even more usage data by routing Chrome users through their DNS service: “Google isn’t actually forcing Chrome users to only use Google’s DNS service, and so it is not centralizing the data. Google is instead configuring Chrome to use DoH connections by default if a user’s DNS service supports it.”
If traffic is routed through Google that is akin to them hosting the page in terms of being able to track many aspects of user behavior. It is akin to AMP or YouTube in terms of being able to track users and normalize relative engagement metrics.
Once Google is hosting the end-to-end user experience they can create a near infinite number of ranking signals given their advancement in computing power: “We developed a new 54-qubit processor, named “Sycamore”, that is comprised of fast, high-fidelity quantum logic gates, in order to perform the benchmark testing. Our machine performed the target computation in 200 seconds, and from measurements in our experiment we determined that it would take the world’s fastest supercomputer 10,000 years to produce a similar output.”
Relying on “one simple trick to…” sorts of approaches are frequently going to come up empty.
EMDs Kicked Once Again
I was one of the early promoters of exact match domains when the broader industry did not believe in them. I was also quick to mention when I felt the algorithms had moved in the other direction.
Google’s mobile layout, which they are now testing on desktop computers as well, replaces green domain names with gray words which are easy to miss. And the favicon icons sort of make the organic results look like ads. Any boost a domain name like CreditCards.ext might have garnered in the past due to matching the keyword has certainly gone away with this new layout that further depreciates the impact of exact-match domain names.
At one point in time CreditCards.com was viewed as a consumer destination. It is now viewed … below the fold.
If you have a memorable brand-oriented domain name the favicon can help offset the above impact somewhat, but matching keywords is becoming a much more precarious approach to sustaining rankings as the weight on brand awareness, user engagement & authority increase relative to the weight on anchor text.
Categories:
New Keyword Tool
Our keyword tool is updated periodically. We recently updated it once more.
For comparison sake, the old keyword tool looked like this
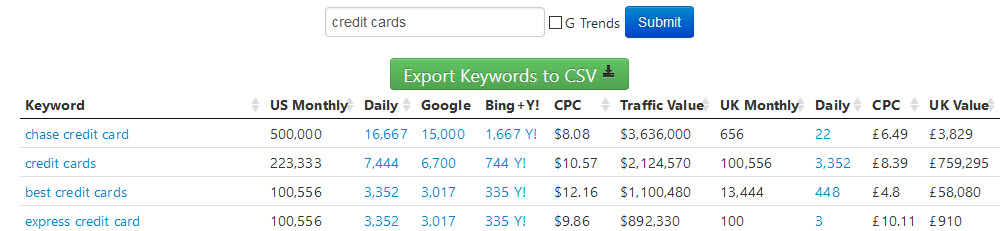
Whereas the new keyword tool looks like this

The upsides of the new keyword tool are:
- fresher data from this year
- more granular data on ad bids vs click prices
- lists ad clickthrough rate
- more granular estimates of Google AdWords advertiser ad bids
- more emphasis on commercial oriented keywords
With the new columns of [ad spend] and [traffic value] here is how we estimate those.
- paid search ad spend: search ad clicks * CPC
- organic search traffic value: ad impressions * 0.5 * (100% – ad CTR) * CPC
The first of those two is rather self explanatory. The second is a bit more complex. It starts with the assumption that about half of all searches do not get any clicks, then it subtracts the paid clicks from the total remaining pool of clicks & multiplies that by the cost per click.
The new data also has some drawbacks:
- Rather than listing search counts specifically it lists relative ranges like low, very high, etc.
- Since it tends to tilt more toward keywords with ad impressions, it may not have coverage for some longer tail informational keywords.
For any keyword where there is insufficient coverage we re-query the old keyword database for data & merge it across. You will know if data came from the new database if the first column says something like low or high & the data came from the older database if there are specific search counts in the first column
For a limited time we are still allowing access to both keyword tools, though we anticipate removing access to the old keyword tool in the future once we have collected plenty of feedback on the new keyword tool. Please feel free to leave your feedback in the below comments.
One of the cool features of the new keyword tools worth highlighting further is the difference between estimated bid prices & estimated click prices. In the following screenshot you can see how Amazon is estimated as having a much higher bid price than actual click price, largely because due to low keyword relevancy entities other than the official brand being arbitraged by Google require much higher bids to appear on competing popular trademark terms.

Historically, this difference between bid price & click price was a big source of noise on lists of the most valuable keywords.
Recently some advertisers have started complaining about the “Google shakedown” from how many brand-driven searches are simply leaving the .com part off of a web address in Chrome & then being forced to pay Google for their own pre-existing brand equity.
When Google puts 4 paid ads ahead of the first organic result for your own brand name, you’re forced to pay up if you want to be found. It’s a shakedown. It’s ransom. But at least we can have fun with it. Search for Basecamp and you may see this attached ad. pic.twitter.com/c0oYaBuahL
— Jason Fried (@jasonfried) September 3, 2019
Categories:
New Keyword Tool
Our keyword tool is updated periodically. We recently updated it once more.
For comparison sake, the old keyword tool looked like this
Whereas the new keyword tool looks like this
The upsides of the new keyword tool are:
- fresher data from this year
- more granular data on ad bids vs click prices
- lists ad clickthrough rate
- more granular estimates of Google AdWords advertiser ad bids
- more emphasis on commercial oriented keywords
With the new columns of [ad spend] and [traffic value] here is how we estimate those.
- paid search ad spend: search ad clicks * CPC
- organic search traffic value: ad impressions * 0.5 * (100% – ad CTR) * CPC
The first of those two is rather self explanatory. The second is a bit more complex. It starts with the assumption that about half of all searches do not get any clicks, then it subtracts the paid clicks from the total remaining pool of clicks & multiplies that by the cost per click.
The new data also has some drawbacks:
- Rather than listing search counts specifically it lists relative ranges like low, very high, etc.
- Since it tends to tilt more toward keywords with ad impressions, it may not have coverage for some longer tail informational keywords.
For any keyword where there is insufficient coverage we re-query the old keyword database for data & merge it across. You will know if data came from the new database if the first column says something like low or high & the data came from the older database if there are specific search counts in the first column
For a limited time we are still allowing access to both keyword tools, though we anticipate removing access to the old keyword tool in the future once we have collected plenty of feedback on the new keyword tool. Please feel free to leave your feedback in the below comments.
One of the cool features of the new keyword tools worth highlighting further is the difference between estimated bid prices & estimated click prices. In the following screenshot you can see how Amazon is estimated as having a much higher bid price than actual click price, largely because due to low keyword relevancy entities other than the official brand being arbitraged by Google require much higher bids to appear on competing popular trademark terms.
Historically, this difference between bid price & click price was a big source of noise on lists of the most valuable keywords.
Recently some advertisers have started complaining about the “Google shakedown” from how many brand-driven searches are simply leaving the .com part off of a web address in Chrome & then being forced to pay Google for their own pre-existing brand equity.
When Google puts 4 paid ads ahead of the first organic result for your own brand name, you’re forced to pay up if you want to be found. It’s a shakedown. It’s ransom. But at least we can have fun with it. Search for Basecamp and you may see this attached ad. pic.twitter.com/c0oYaBuahL
— Jason Fried (@jasonfried) September 3, 2019
Categories:
AMP’d Up for Recaptcha
Beyond search Google controls the leading distributed ad network, the leading mobile OS, the leading web browser, the leading email client, the leading web analytics platform, the leading free video hosting site.
They win a lot.
And they take winnings from one market & leverage them into manipulating adjacent markets.
Embrace. Extend. Extinguish.
Imagine taking a universal open standard that has zero problems with it and then stripping it down to it’s most basic components and then prepending each element with your own acronym. Then spend years building and recreating what has existed for decades. That is @amphtml— Jon Henshaw (@henshaw) April 4, 2019
AMP is an utterly unnecessary invention designed to further shift power to Google while disenfranchising publishers. From the very start it had many issues with basic things like supporting JavaScript, double counting unique users (no reason to fix broken stats if they drive adoption!), not supporting third party ad networks, not showing publisher domain names, and just generally being a useless layer of sunk cost technical overhead that provides literally no real value.
Over time they have corrected some of these catastrophic deficiencies, but if it provided real value, they wouldn’t have needed to force adoption with preferential placement in their search results. They force the bundling because AMP sucks.
Absurdity knows no bounds. Googlers suggest: “AMP isn’t another “channel” or “format” that’s somehow not the web. It’s not a SEO thing. It’s not a replacement for HTML. It’s a web component framework that can power your whole site. … We, the AMP team, want AMP to become a natural choice for modern web development of content websites, and for you to choose AMP as framework because it genuinely makes you more productive.”
Meanwhile some newspapers have about a dozen employees who work on re-formatting content for AMP:
The AMP development team now keeps track of whether AMP traffic drops suddenly, which might indicate pages are invalid, and it can react quickly.
All this adds expense, though. There are setup, development and maintenance costs associated with AMP, mostly in the form of time. After implementing AMP, the Guardian realized the project needed dedicated staff, so it created an 11-person team that works on AMP and other aspects of the site, drawing mostly from existing staff.
Feeeeeel the productivity!
Some content types (particularly user generated content) can be unpredictable & circuitous. For many years forums websites would use keywords embedded in the search referral to highlight relevant parts of the page. Keyword (not provided) largely destroyed that & then it became a competitive feature for AMP: “If the Featured Snippet links to an AMP article, Google will sometimes automatically scroll users to that section and highlight the answer in orange.”
That would perhaps be a single area where AMP was more efficient than the alternative. But it is only so because Google destroyed the alternative by stripping keyword referrers from search queries.
The power dynamics of AMP are ugly:
“I see them as part of the effort to normalise the use of the AMP Carousel, which is an anti-competitive land-grab for the web by an organisation that seems to have an insatiable appetite for consuming the web, probably ultimately to it’s own detriment. … This enables Google to continue to exist after the destination site (eg the New York Times) has been navigated to. Essentially it flips the parent-child relationship to be the other way around. … As soon as a publisher blesses a piece of content by packaging it (they have to opt in to this, but see coercion below), they totally lose control of its distribution. … I’m not that smart, so it’s surely possible to figure out other ways of making a preload possible without cutting off the content creator from the people consuming their content. … The web is open and decentralised. We spend a lot of time valuing the first of these concepts, but almost none trying to defend the second. Google knows, perhaps better than anyone, how being in control of the user is the most monetisable position, and having the deepest pockets and the most powerful platform to do so, they have very successfully inserted themselves into my relationship with millions of other websites. … In AMP, the support for paywalls is based on a recommendation that the premium content be included in the source of the page regardless of the user’s authorisation state. … These policies demonstrate contempt for others’ right to freely operate their businesses.
After enough publishers adopted AMP Google was able to turn their mobile app’s homepage into an interactive news feed below the search box. And inside that news feed Google gets to distribute MOAR ads while 0% of the revenue from those ads find its way to the publishers whose content is used to make up the feed.
Appropriate appropriation. :D
Each additional layer of technical cruft is another cost center. Things that sound appealing at first blush may not be:
The way you verify your identity to Let’s Encrypt is the same as with other certificate authorities: you don’t really. You place a file somewhere on your website, and they access that file over plain HTTP to verify that you own the website. The one attack that signed certificates are meant to prevent is a man-in-the-middle attack. But if someone is able to perform a man-in-the-middle attack against your website, then he can intercept the certificate verification, too. In other words, Let’s Encrypt certificates don’t stop the one thing they’re supposed to stop. And, as always with the certificate authorities, a thousand murderous theocracies, advertising companies, and international spy organizations are allowed to impersonate you by design.
Anything that is easy to implement & widely marketed often has costs added to it in the future as the entity moves to monetize the service.
This is a private equity firm buying up multiple hosting control panels & then adjusting prices.
This is Google Maps drastically changing their API terms.
This is Facebook charging you for likes to build an audience, giving your competitors access to those likes as an addressable audience to advertise against, and then charging you once more to boost the reach of your posts.
This is Grubhub creating shadow websites on your behalf and charging you for every transaction created by the gravity of your brand.
Shivane believes GrubHub purchased her restaurant’s web domain to prevent her from building her own online presence. She also believes the company may have had a special interest in owning her name because she processes a high volume of orders. … it appears GrubHub has set up several generic, templated pages that look like real restaurant websites but in fact link only to GrubHub. These pages also display phone numbers that GrubHub controls. The calls are forwarded to the restaurant, but the platform records each one and charges the restaurant a commission fee for every order
Settling for the easiest option drives a lack of differentiation, embeds additional risk & once the dominant player has enough marketshare they’ll change the terms on you.
Small gains in short term margins for massive increases in fragility.
“Closed platforms increase the chunk size of competition & increase the cost of market entry, so people who have good ideas, it is a lot more expensive for their productivity to be monetized. They also don’t like standardization … it looks like rent seeking behaviors on top of friction” – Gabe Newell
The other big issue is platforms that run out of growth space in their core market may break integrations with adjacent service providers as each want to grow by eating the other’s market.
Those who look at SaaS business models through the eyes of a seasoned investor will better understand how markets are likely to change:
“I’d argue that many of today’s anointed tech “disruptors” are doing little in the way of true disruption. … When investors used to get excited about a SAAS company, they typically would be describing a hosted multi-tenant subscription-billed piece of software that was replacing a ‘legacy’ on-premise perpetual license solution in the same target market (i.e. ERP, HCM, CRM, etc.). Today, the terms SAAS and Cloud essentially describe the business models of every single public software company.
Most platform companies are initially required to operate at low margins in order to buy growth of their category & own their category. Then when they are valued on that, they quickly need to jump across to adjacent markets to grow into the valuation:
Twilio has no choice but to climb up the application stack. This is a company whose ‘disruption’ is essentially great API documentation and gangbuster SEO spend built on top of a highly commoditized telephony aggregation API. They have won by marketing to DevOps engineers. With all the hype around them, you’d think Twilio invented the telephony API, when in reality what they did was turn it into a product company. Nobody had thought of doing this let alone that this could turn into a $17 billion company because simply put the economics don’t work. And to be clear they still don’t. But Twilio’s genius CEO clearly gets this. If the market is going to value robocalls, emergency sms notifications, on-call pages, and carrier fee passed through related revenue growth in the same way it does ‘subscription’ revenue from Atlassian or ServiceNow, then take advantage of it while it lasts.
Large platforms offering temporary subsidies to ensure they dominate their categories & companies like SoftBank spraying capital across the markets is causing massive shifts in valuations:
I also think if you look closely at what is celebrated today as innovation you often find models built on hidden subsidies. … I’d argue the very distributed nature of microservices architecture and API-first product companies means addressable market sizes and unit economics assumptions should be even more carefully scrutinized. … How hard would it be to create an Alibaba today if someone like SoftBank was raining money into such a greenfield space? Excess capital would lead to destruction and likely subpar returns. If capital was the solution, the 1.5 trillion that went into telcos in late ’90s wouldn’t have led to a massive bust. Would a Netflix be what it is today if a SoftBank was pouring billions into streaming content startups right as the experiment was starting? Obviously not. Scarcity of capital is another often underappreciated part of the disruption equation. Knowing resources are finite leads to more robust models. … This convergence is starting to manifest itself in performance. Disney is up 30% over the last 12 months while Netflix is basically flat. This may not feel like a bubble sign to most investors, but from my standpoint, it’s a clear evidence of the fact that we are approaching a something has got to give moment for the way certain businesses are valued.”
Circling back to Google’s AMP, it has a cousin called Recaptcha.
Recaptcha is another AMP-like trojan horse:
According to tech statistics website Built With, more than 650,000 websites are already using reCaptcha v3; overall, there are at least 4.5 million websites use reCaptcha, including 25% of the top 10,000 sites. Google is also now testing an enterprise version of reCaptcha v3, where Google creates a customized reCaptcha for enterprises that are looking for more granular data about users’ risk levels to protect their site algorithms from malicious users and bots. … According to two security researchers who’ve studied reCaptcha, one of the ways that Google determines whether you’re a malicious user or not is whether you already have a Google cookie installed on your browser. … To make this risk-score system work accurately, website administrators are supposed to embed reCaptcha v3 code on all of the pages of their website, not just on forms or log-in pages.
About a month ago when logging into Bing Ads I saw recaptcha on the login page & couldn’t believe they’d give Google control at that access point. I think they got rid of that, but lots of companies are perhaps shooting themselves in the foot through a combination of over-reliance on Google infrastructure AND sloppy implementation
Today when making a purchase on Fiverr, after converting, I got some of this action
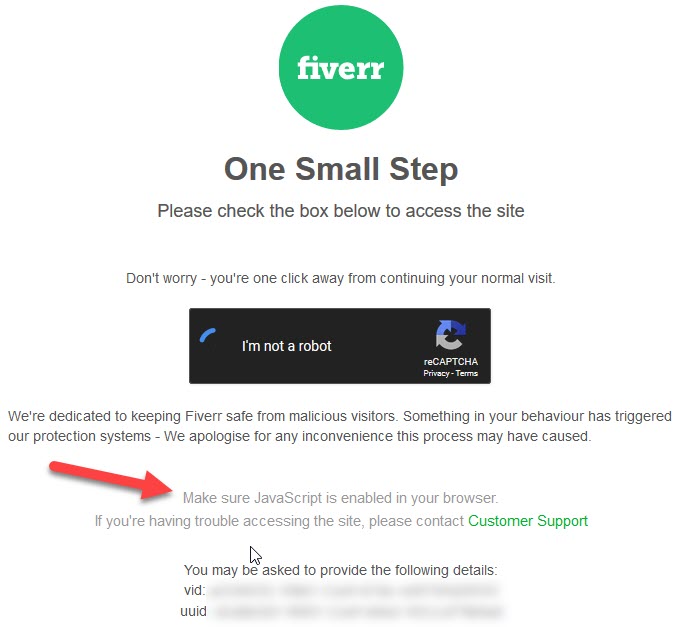
Hmm. Maybe I will enable JavaScript and try again.
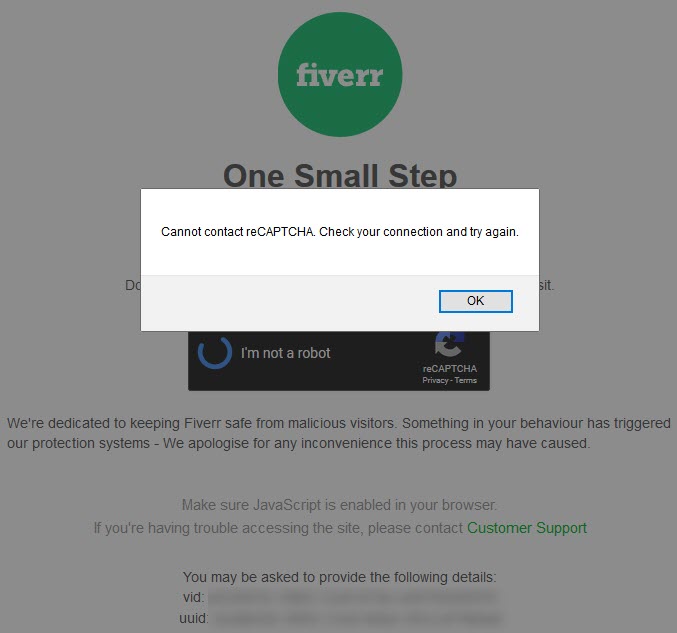
Oooops.

That is called snatching defeat from the jaws of victory.
My account is many years old. My payment type on record has been used for years. I have ordered from the particular seller about a dozen times over the years. And suddenly because my web browser had JavaScript turned off I was deemed a security risk of some sort for making an utterly ordinary transaction I have already completed about a dozen times.
On AMP JavaScript was the devil. And on desktop not JavaScript was the devil.
Pro tip: Ecommerce websites that see substandard conversion rates from using Recaptcha can boost their overall ecommerce revenue by buying more Google AdWords ads.
—
As more of the infrastructure stack is driven by AI software there is going to be a very real opportunity for many people to become deplatformed across the web on an utterly arbitrary basis. That tech companies like Facebook also want to create digital currencies on top of the leverage they already have only makes the proposition that much scarier.
If the tech platforms host copies of our sites, process the transactions & even create their own currencies, how will we know what level of value they are adding versus what they are extracting?
Who measures the measurer?
And when the economics turn negative, what will we do if we are hooked into an ecosystem we can’t spend additional capital to get out of when things head south?
Categories:
AMP’d Up for Recaptcha
Beyond search Google controls the leading distributed ad network, the leading mobile OS, the leading web browser, the leading email client, the leading web analytics platform, the leading free video hosting site.
They win a lot.
And they take winnings from one market & leverage them into manipulating adjacent markets.
Embrace. Extend. Extinguish.
Imagine taking a universal open standard that has zero problems with it and then stripping it down to it’s most basic components and then prepending each element with your own acronym. Then spend years building and recreating what has existed for decades. That is @amphtml— Jon Henshaw (@henshaw) April 4, 2019
AMP is an utterly unnecessary invention designed to further shift power to Google while disenfranchising publishers. From the very start it had many issues with basic things like supporting JavaScript, double counting unique users (no reason to fix broken stats if they drive adoption!), not supporting third party ad networks, not showing publisher domain names, and just generally being a useless layer of sunk cost technical overhead that provides literally no real value.
Over time they have corrected some of these catastrophic deficiencies, but if it provided real value, they wouldn’t have needed to force adoption with preferential placement in their search results. They force the bundling because AMP sucks.
Absurdity knows no bounds. Googlers suggest: “AMP isn’t another “channel” or “format” that’s somehow not the web. It’s not a SEO thing. It’s not a replacement for HTML. It’s a web component framework that can power your whole site. … We, the AMP team, want AMP to become a natural choice for modern web development of content websites, and for you to choose AMP as framework because it genuinely makes you more productive.”
Meanwhile some newspapers have about a dozen employees who work on re-formatting content for AMP:
The AMP development team now keeps track of whether AMP traffic drops suddenly, which might indicate pages are invalid, and it can react quickly.
All this adds expense, though. There are setup, development and maintenance costs associated with AMP, mostly in the form of time. After implementing AMP, the Guardian realized the project needed dedicated staff, so it created an 11-person team that works on AMP and other aspects of the site, drawing mostly from existing staff.
Feeeeeel the productivity!
Some content types (particularly user generated content) can be unpredictable & circuitous. For many years forums websites would use keywords embedded in the search referral to highlight relevant parts of the page. Keyword (not provided) largely destroyed that & then it became a competitive feature for AMP: “If the Featured Snippet links to an AMP article, Google will sometimes automatically scroll users to that section and highlight the answer in orange.”
That would perhaps be a single area where AMP was more efficient than the alternative. But it is only so because Google destroyed the alternative by stripping keyword referrers from search queries.
The power dynamics of AMP are ugly:
“I see them as part of the effort to normalise the use of the AMP Carousel, which is an anti-competitive land-grab for the web by an organisation that seems to have an insatiable appetite for consuming the web, probably ultimately to it’s own detriment. … This enables Google to continue to exist after the destination site (eg the New York Times) has been navigated to. Essentially it flips the parent-child relationship to be the other way around. … As soon as a publisher blesses a piece of content by packaging it (they have to opt in to this, but see coercion below), they totally lose control of its distribution. … I’m not that smart, so it’s surely possible to figure out other ways of making a preload possible without cutting off the content creator from the people consuming their content. … The web is open and decentralised. We spend a lot of time valuing the first of these concepts, but almost none trying to defend the second. Google knows, perhaps better than anyone, how being in control of the user is the most monetisable position, and having the deepest pockets and the most powerful platform to do so, they have very successfully inserted themselves into my relationship with millions of other websites. … In AMP, the support for paywalls is based on a recommendation that the premium content be included in the source of the page regardless of the user’s authorisation state. … These policies demonstrate contempt for others’ right to freely operate their businesses.
After enough publishers adopted AMP Google was able to turn their mobile app’s homepage into an interactive news feed below the search box. And inside that news feed Google gets to distribute MOAR ads while 0% of the revenue from those ads find its way to the publishers whose content is used to make up the feed.
Appropriate appropriation. :D
Thank you for your content!!!
Well this issue (bug?) is going to cause a sh*t storm… Google @AMPhtml not allowing people to click through to full site? You can’t see but am clicking the link in top right iOS Chrome 74.0.3729.155 pic.twitter.com/dMt5QSW9fu— Scotch.io (@scotch_io) June 11, 2019
The mainstream media is waking up to AMP being a trap, but their neck is already in it:
European and American tech, media and publishing companies, including some that originally embraced AMP, are complaining that the Google-backed technology, which loads article pages in the blink of an eye on smartphones, is cementing the search giant’s dominance on the mobile web.
Each additional layer of technical cruft is another cost center. Things that sound appealing at first blush may not be:
The way you verify your identity to Let’s Encrypt is the same as with other certificate authorities: you don’t really. You place a file somewhere on your website, and they access that file over plain HTTP to verify that you own the website. The one attack that signed certificates are meant to prevent is a man-in-the-middle attack. But if someone is able to perform a man-in-the-middle attack against your website, then he can intercept the certificate verification, too. In other words, Let’s Encrypt certificates don’t stop the one thing they’re supposed to stop. And, as always with the certificate authorities, a thousand murderous theocracies, advertising companies, and international spy organizations are allowed to impersonate you by design.
Anything that is easy to implement & widely marketed often has costs added to it in the future as the entity moves to monetize the service.
This is a private equity firm buying up multiple hosting control panels & then adjusting prices.
This is Google Maps drastically changing their API terms.
This is Facebook charging you for likes to build an audience, giving your competitors access to those likes as an addressable audience to advertise against, and then charging you once more to boost the reach of your posts.
This is Grubhub creating shadow websites on your behalf and charging you for every transaction created by the gravity of your brand.
Shivane believes GrubHub purchased her restaurant’s web domain to prevent her from building her own online presence. She also believes the company may have had a special interest in owning her name because she processes a high volume of orders. … it appears GrubHub has set up several generic, templated pages that look like real restaurant websites but in fact link only to GrubHub. These pages also display phone numbers that GrubHub controls. The calls are forwarded to the restaurant, but the platform records each one and charges the restaurant a commission fee for every order
Settling for the easiest option drives a lack of differentiation, embeds additional risk & once the dominant player has enough marketshare they’ll change the terms on you.
Small gains in short term margins for massive increases in fragility.
“Closed platforms increase the chunk size of competition & increase the cost of market entry, so people who have good ideas, it is a lot more expensive for their productivity to be monetized. They also don’t like standardization … it looks like rent seeking behaviors on top of friction” – Gabe Newell
The other big issue is platforms that run out of growth space in their core market may break integrations with adjacent service providers as each want to grow by eating the other’s market.
Those who look at SaaS business models through the eyes of a seasoned investor will better understand how markets are likely to change:
“I’d argue that many of today’s anointed tech “disruptors” are doing little in the way of true disruption. … When investors used to get excited about a SAAS company, they typically would be describing a hosted multi-tenant subscription-billed piece of software that was replacing a ‘legacy’ on-premise perpetual license solution in the same target market (i.e. ERP, HCM, CRM, etc.). Today, the terms SAAS and Cloud essentially describe the business models of every single public software company.
Most platform companies are initially required to operate at low margins in order to buy growth of their category & own their category. Then when they are valued on that, they quickly need to jump across to adjacent markets to grow into the valuation:
Twilio has no choice but to climb up the application stack. This is a company whose ‘disruption’ is essentially great API documentation and gangbuster SEO spend built on top of a highly commoditized telephony aggregation API. They have won by marketing to DevOps engineers. With all the hype around them, you’d think Twilio invented the telephony API, when in reality what they did was turn it into a product company. Nobody had thought of doing this let alone that this could turn into a $17 billion company because simply put the economics don’t work. And to be clear they still don’t. But Twilio’s genius CEO clearly gets this. If the market is going to value robocalls, emergency sms notifications, on-call pages, and carrier fee passed through related revenue growth in the same way it does ‘subscription’ revenue from Atlassian or ServiceNow, then take advantage of it while it lasts.
Large platforms offering temporary subsidies to ensure they dominate their categories & companies like SoftBank spraying capital across the markets is causing massive shifts in valuations:
I also think if you look closely at what is celebrated today as innovation you often find models built on hidden subsidies. … I’d argue the very distributed nature of microservices architecture and API-first product companies means addressable market sizes and unit economics assumptions should be even more carefully scrutinized. … How hard would it be to create an Alibaba today if someone like SoftBank was raining money into such a greenfield space? Excess capital would lead to destruction and likely subpar returns. If capital was the solution, the 1.5 trillion that went into telcos in late ’90s wouldn’t have led to a massive bust. Would a Netflix be what it is today if a SoftBank was pouring billions into streaming content startups right as the experiment was starting? Obviously not. Scarcity of capital is another often underappreciated part of the disruption equation. Knowing resources are finite leads to more robust models. … This convergence is starting to manifest itself in performance. Disney is up 30% over the last 12 months while Netflix is basically flat. This may not feel like a bubble sign to most investors, but from my standpoint, it’s a clear evidence of the fact that we are approaching a something has got to give moment for the way certain businesses are valued.”
Circling back to Google’s AMP, it has a cousin called Recaptcha.
Recaptcha is another AMP-like trojan horse:
According to tech statistics website Built With, more than 650,000 websites are already using reCaptcha v3; overall, there are at least 4.5 million websites use reCaptcha, including 25% of the top 10,000 sites. Google is also now testing an enterprise version of reCaptcha v3, where Google creates a customized reCaptcha for enterprises that are looking for more granular data about users’ risk levels to protect their site algorithms from malicious users and bots. … According to two security researchers who’ve studied reCaptcha, one of the ways that Google determines whether you’re a malicious user or not is whether you already have a Google cookie installed on your browser. … To make this risk-score system work accurately, website administrators are supposed to embed reCaptcha v3 code on all of the pages of their website, not just on forms or log-in pages.
About a month ago when logging into Bing Ads I saw recaptcha on the login page & couldn’t believe they’d give Google control at that access point. I think they got rid of that, but lots of companies are perhaps shooting themselves in the foot through a combination of over-reliance on Google infrastructure AND sloppy implementation
Today when making a purchase on Fiverr, after converting, I got some of this action
Hmm. Maybe I will enable JavaScript and try again.
Oooops.
That is called snatching defeat from the jaws of victory.
My account is many years old. My payment type on record has been used for years. I have ordered from the particular seller about a dozen times over the years. And suddenly because my web browser had JavaScript turned off I was deemed a security risk of some sort for making an utterly ordinary transaction I have already completed about a dozen times.
On AMP JavaScript was the devil. And on desktop not JavaScript was the devil.
Pro tip: Ecommerce websites that see substandard conversion rates from using Recaptcha can boost their overall ecommerce revenue by buying more Google AdWords ads.
—
As more of the infrastructure stack is driven by AI software there is going to be a very real opportunity for many people to become deplatformed across the web on an utterly arbitrary basis. That tech companies like Facebook also want to create digital currencies on top of the leverage they already have only makes the proposition that much scarier.
If the tech platforms host copies of our sites, process the transactions & even create their own currencies, how will we know what level of value they are adding versus what they are extracting?
Who measures the measurer?
And when the economics turn negative, what will we do if we are hooked into an ecosystem we can’t spend additional capital to get out of when things head south?
Categories:
The Fractured Web
Anyone can argue about the intent of a particular action & the outcome that is derived by it. But when the outcome is known, at some point the intent is inferred if the outcome is derived from a source of power & the outcome doesn’t change.
Or, put another way, if a powerful entity (government, corporation, other organization) disliked an outcome which appeared to benefit them in the short term at great lasting cost to others, they could spend resources to adjust the system.
If they don’t spend those resources (or, rather, spend them on lobbying rather than improving the ecosystem) then there is no desired change. The outcome is as desired. Change is unwanted.
Engagement is a toxic metric.Products which optimize for it become worse. People who optimize for it become less happy.It also seems to generate runaway feedback loops where most engagable people have a) worst individual experiences and then b) end up driving the product bus.— Patrick McKenzie (@patio11) April 9, 2019
News is a stock vs flow market where the flow of recent events drives most of the traffic to articles. News that is more than a couple days old is no longer news. A news site which stops publishing news stops becoming a habit & quickly loses relevancy. Algorithmically an abandoned archive of old news articles doesn’t look much different than eHow, in spite of having a much higher cost structure.
According to SEMrush’s traffic rank, ampproject.org gets more monthly visits than Yahoo.com.
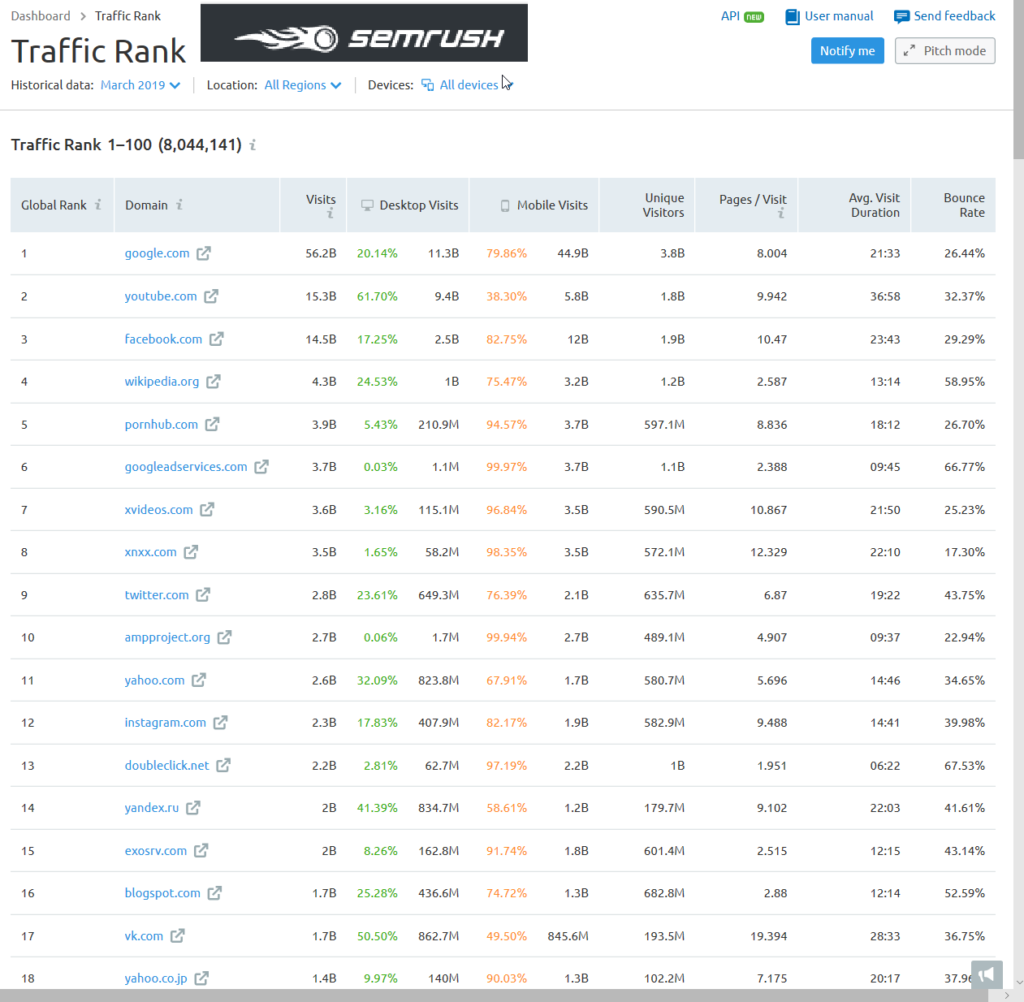
That actually understates the prevalence of AMP because AMP is generally designed for mobile AND not all AMP-formatted content is displayed on ampproject.org.
Part of how AMP was able to get widespread adoption was because in the news vertical the organic search result set was displaced by an AMP block. If you were a news site either you were so differentiated that readers would scroll past the AMP block in the search results to look for you specifically, or you adopted AMP, or you were doomed.
Some news organizations like The Guardian have a team of about a dozen people reformatting their content to the duplicative & proprietary AMP format. That’s wasteful, but necessary “In theory, adoption of AMP is voluntary. In reality, publishers that don’t want to see their search traffic evaporate have little choice. New data from publisher analytics firm Chartbeat shows just how much leverage Google has over publishers thanks to its dominant search engine.”
It seems more than a bit backward that low margin publishers are doing duplicative work to distance themselves from their own readers while improving the profit margins of monopolies. But it is what it is. And that no doubt drew the ire of many publishers across the EU.
And now there are AMP Stories to eat up even more visual real estate.
If you spent a bunch of money to create a highly differentiated piece of content, why would you prefer that high spend flaghship content appear on a third party website rather than your own?
Google & Facebook have done such a fantastic job of eating the entire pie that some are celebrating Amazon as a prospective savior to the publishing industry. That view – IMHO – is rather suspect.
Where any of the tech monopolies dominate they cram down on partners. The New York Times acquired The Wirecutter in Q4 of 2016. In Q1 of 2017 Amazon adjusted their affiliate fee schedule.
Amazon generally treats consumers well, but they have been much harder on business partners with tough pricing negotiations, counterfeit protections, forced ad buying to have a high enough product rank to be able to rank organically, ad displacement of their organic search results below the fold (even for branded search queries), learning suppliers & cutting out the partners, private label products patterned after top sellers, in some cases running pop over ads for the private label products on product level pages where brands already spent money to drive traffic to the page, etc.
They’ve made things tougher for their partners in a way that mirrors the impact Facebook & Google have had on online publishers:
“Boyce’s experience on Amazon largely echoed what happens in the offline world: competitors entered the market, pushing down prices and making it harder to make a profit. So Boyce adapted. He stopped selling basketball hoops and developed his own line of foosball tables, air hockey tables, bocce ball sets and exercise equipment. The best way to make a decent profit on Amazon was to sell something no one else had and create your own brand. … Amazon also started selling bocce ball sets that cost $15 less than Boyce’s. He says his products are higher quality, but Amazon gives prominent page space to its generic version and wins the cost-conscious shopper.”
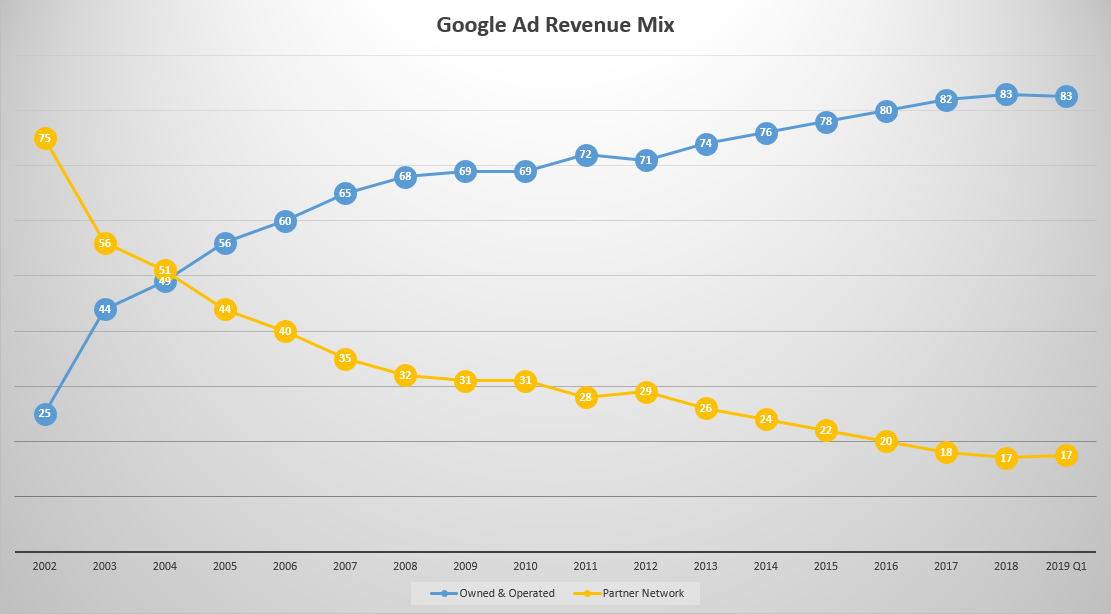
Google claims they have no idea how content publishers are with the trade off between themselves & the search engine, but every quarter Alphabet publish the share of ad spend occurring on owned & operated sites versus the share spent across the broader publisher network. And in almost every quarter for over a decade straight that ratio has grown worse for publishers.
When Google tells industry about how much $ it funnels to rest of ecosystem, just show them this chart. It’s good to be the “revenue regulator” (note: G went public in 2004). pic.twitter.com/HCbCNgbzKc— Jason Kint (@jason_kint) February 5, 2019
The aggregate numbers for news publishers are worse than shown above as Google is ramping up ads in video games quite hard. They’ve partnered with Unity & promptly took away the ability to block ads from appearing in video games using googleadsenseformobileapps.com exclusion (hello flat thumb misclicks, my name is budget & I am gone!)
They will also track video game player behavior & alter game play to maximize revenues based on machine learning tied to surveillance of the user’s account: “We’re bringing a new approach to monetization that combines ads and in-app purchases in one automated solution. Available today, new smart segmentation features in Google AdMob use machine learning to segment your players based on their likelihood to spend on in-app purchases. Ad units with smart segmentation will show ads only to users who are predicted not to spend on in-app purchases. Players who are predicted to spend will see no ads, and can simply continue playing.”
And how does the growth of ampproject.org square against the following wisdom?
If you do use a CDN, I’d recommend using a domain name of your own (eg, https://t.co/fWMc6CFPZ0), so you can move to other CDNs if you feel the need to over time, without having to do any redirects.— John (@JohnMu) April 15, 2019
Literally only yesterday did Google begin supporting instant loading of self-hosted AMP pages.
China has a different set of tech leaders than the United States. Baidu, Alibaba, Tencent (BAT) instead of Facebook, Amazon, Apple, Netflix, Google (FANG). China tech companies may have won their domestic markets in part based on superior technology or better knowledge of the local culture, though those same companies have largely went nowhere fast in most foreign markets. A big part of winning was governmental assistance in putting a foot on the scales.
Part of the US-China trade war is about who controls the virtual “seas” upon which value flows:
it can easily be argued that the last 60 years were above all the era of the container-ship (with container-ships getting ever bigger). But will the coming decades still be the age of the container-ship? Possibly not, for the simple reason that things that have value increasingly no longer travel by ship, but instead by fiberoptic cables! … you could almost argue that ZTE and Huawei have been the “East India Company” of the current imperial cycle. Unsurprisingly, it is these very companies, charged with laying out the “new roads” along which “tomorrow’s value” will flow, that find themselves at the center of the US backlash. … if the symbol of British domination was the steamship, and the symbol of American strength was the Boeing 747, it seems increasingly clear that the question of the future will be whether tomorrow’s telecom switches and routers are produced by Huawei or Cisco. … US attempts to take down Huawei and ZTE can be seen as the existing empire’s attempt to prevent the ascent of a new imperial power. With this in mind, I could go a step further and suggest that perhaps the Huawei crisis is this century’s version of Suez crisis. No wonder markets have been falling ever since the arrest of the Huawei CFO. In time, the Suez Crisis was brought to a halt by US threats to destroy the value of sterling. Could we now witness the same for the US dollar?
China maintains Huawei is an employee-owned company. But that proposition is suspect. Broadly stealing technology is vital to the growth of the Chinese economy & they have no incentive to stop unless their leading companies pay a direct cost. Meanwhile, China is investigating Ericsson over licensing technology.
India has taken notice of the success of Chinese tech companies & thus began to promote “national champion” company policies. That, in turn, has also meant some of the Chinese-styled laws requiring localized data, antitrust inquiries, foreign ownership restrictions, requirements for platforms to not sell their own goods, promoting limits on data encryption, etc.
The secretary of India’s Telecommunications Department, Aruna Sundararajan, last week told a gathering of Indian startups in a closed-door meeting in the tech hub of Bangalore that the government will introduce a “national champion” policy “very soon” to encourage the rise of Indian companies, according to a person familiar with the matter. She said Indian policy makers had noted the success of China’s internet giants, Alibaba Group Holding Ltd. and Tencent Holdings Ltd. … Tensions began rising last year, when New Delhi decided to create a clearer set of rules for e-commerce and convened a group of local players to solicit suggestions. Amazon and Flipkart, even though they make up more than half the market, weren’t invited, according to people familiar with the matter.
Amazon vowed to invest $5 billion in India & they have done some remarkable work on logistics there. Walmart acquired Flipkart for $16 billion.
Other emerging markets also have many local ecommerce leaders like Jumia, MercadoLibre, OLX, Gumtree, Takealot, Konga, Kilimall, BidOrBuy, Tokopedia, Bukalapak, Shoppee, Lazada. If you live in the US you may have never heard of *any* of those companies. And if you live in an emerging market you may have never interacted with Amazon or eBay.
It makes sense that ecommerce leadership would be more localized since it requires moving things in the physical economy, dealing with local currencies, managing inventory, shipping goods, etc. whereas information flows are just bits floating on a fiber optic cable.
If the Internet is primarily seen as a communications platform it is easy for people in some emerging markets to think Facebook is the Internet. Free communication with friends and family members is a compelling offer & as the cost of data drops web usage increases.
At the same time, the web is incredibly deflationary. Every free form of entertainment which consumes time is time that is not spent consuming something else.
Add the technological disruption to the wealth polarization that happened in the wake of the great recession, then combine that with algorithms that promote extremist views & it is clearly causing increasing conflict.
If you are a parent and you think you child has no shot at a brighter future than your own life it is easy to be full of rage.
Empathy can radicalize otherwise normal people by giving them a more polarized view of the world:
Starting around 2000, the line starts to slide. More students say it’s not their problem to help people in trouble, not their job to see the world from someone else’s perspective. By 2009, on all the standard measures, Konrath found, young people on average measure 40 percent less empathetic than my own generation … The new rule for empathy seems to be: reserve it, not for your “enemies,” but for the people you believe are hurt, or you have decided need it the most. Empathy, but just for your own team. And empathizing with the other team? That’s practically a taboo.
A complete lack of empathy could allow a psychopath to commit extreme crimes while feeling no guilt, shame or remorse. Extreme empathy can have the same sort of outcome:
“Sometimes we commit atrocities not out of a failure of empathy but rather as a direct consequence of successful, even overly successful, empathy. … They emphasized that students would learn both sides, and the atrocities committed by one side or the other were always put into context. Students learned this curriculum, but follow-up studies showed that this new generation was more polarized than the one before. … [Empathy] can be good when it leads to good action, but it can have downsides. For example, if you want the victims to say ‘thank you.’ You may even want to keep the people you help in that position of inferior victim because it can sustain your feeling of being a hero.” – Fritz Breithaupt
News feeds will be read. Villages will be razed. Lynch mobs will become commonplace.
Many people will end up murdered by algorithmically generated empathy.
As technology increases absentee ownership & financial leverage, a society led by morally agnostic algorithms is not going to become more egalitarian.
The more I think about and discuss it, the more I think WhatsApp is simultaneously the future of Facebook, and the most potentially dangerous digital tool yet created. We haven’t even begun to see the real impact yet of ubiquitous, unfettered and un-moderatable human telepathy.— Antonio García Martínez (@antoniogm) April 15, 2019
When politicians throw fuel on the fire it only gets worse:
It’s particularly odd that the government is demanding “accountability and responsibility” from a phone app when some ruling party politicians are busy spreading divisive fake news. How can the government ask WhatsApp to control mobs when those convicted of lynching Muslims have been greeted, garlanded and fed sweets by some of the most progressive and cosmopolitan members of Modi’s council of ministers?
Mark Zuckerburg won’t get caught downstream from platform blowback as he spends $20 million a year on his security.
The web is a mirror. Engagement-based algorithms reinforcing our perceptions & identities.
And every important story has at least 2 sides!
The Rohingya asylum seekers are victims of their own violent Jihadist leadership that formed a militia to kill Buddhists and Hindus. Hindus are being massacred, where’s the outrage for them!? https://t.co/P3m6w4B1Po— Imam Tawhidi (@Imamofpeace) May 23, 2018
Some may “learn” vaccines don’t work. Others may learn the vaccines their own children took did not work, as it failed to protect them from the antivax content spread by Facebook & Google, absorbed by people spreading measles & Medieval diseases.
Passion drives engagement, which drives algorithmic distribution: “There’s an asymmetry of passion at work. Which is to say, there’s very little counter-content to surface because it simply doesn’t occur to regular people (or, in this case, actual medical experts) that there’s a need to produce counter-content.”
As the costs of “free” become harder to hide, social media companies which currently sell emerging markets as their next big growth area will end up having embedded regulatory compliance costs which will end up exceeding any sort of prospective revenue they could hope to generate.
The Pinterest S1 shows almost all their growth is in emerging markets, yet almost all their revenue is inside the United States.
As governments around the world see the real-world cost of the foreign tech companies & view some of them as piggy banks, eventually the likes of Facebook or Google will pull out of a variety of markets they no longer feel worth serving. It will be like Google did in mainland China with search after discovering pervasive hacking of activist Gmail accounts.
Just tried signing into Gmail from a new device. Unless I provide a phone number, there is no way to sign in and no one to call about it. Oh, and why do they say they need my phone? If you guessed “for my protection,” you would be correct. Talk about Big Brother…— Simon Mikhailovich (@S_Mikhailovich) April 16, 2019
Lower friction & lower cost information markets will face more junk fees, hurdles & even some legitimate regulations. Information markets will start to behave more like physical goods markets.
The tech companies presume they will be able to use satellites, drones & balloons to beam in Internet while avoiding messy local issues tied to real world infrastructure, but when a local wealthy player is betting against them they’ll probably end up losing those markets: “One of the biggest cheerleaders for the new rules was Reliance Jio, a fast-growing mobile phone company controlled by Mukesh Ambani, India’s richest industrialist. Mr. Ambani, an ally of Mr. Modi, has made no secret of his plans to turn Reliance Jio into an all-purpose information service that offers streaming video and music, messaging, money transfer, online shopping, and home broadband services.”
Publishers do not have “their mojo back” because the tech companies have been so good to them, but rather because the tech companies have been so aggressive that they’ve earned so much blowback which will in turn lead publishers to opting out of future deals, which will eventually lead more people back to the trusted brands of yesterday.
Publishers feeling guilty about taking advertorial money from the tech companies to spread their propaganda will offset its publication with opinion pieces pointing in the other direction: “This is a lobbying campaign in which buying the good opinion of news brands is clearly important. If it was about reaching a target audience, there are plenty of metrics to suggest his words would reach further – at no cost – on Facebook. Similarly, Google is upping its presence in a less obvious manner via assorted media initiatives on both sides of the Atlantic. Its more direct approach to funding journalism seems to have the desired effect of making all media organisations (and indeed many academic institutions) touched by its money slightly less questioning and critical of its motives.”
When Facebook goes down direct visits to leading news brand sites go up.
When Google penalizes a no-name me-too site almost nobody realizes it is missing. But if a big publisher opts out of the ecosystem people will notice.
The reliance on the tech platforms is largely a mirage. If enough key players were to opt out at the same time people would quickly reorient their information consumption habits.
If the platforms can change their focus overnight then why can’t publishers band together & choose to dump them?
CEO Jack Dorsey said Twitter is looking to change the focus from following specific individuals to topics of interest, acknowledging that what’s incentivized today on the platform is at odds with the goal of healthy dialoguehttps://t.co/31FYslbePA— Axios (@axios) April 16, 2019
In Europe there is GDPR, which aimed to protect user privacy, but ultimately acted as a tax on innovation by local startups while being a subsidy to the big online ad networks. They also have Article 11 & Article 13, which passed in spite of Google’s best efforts on the scaremongering anti-SERP tests, lobbying & propaganda fronts: “Google has sparked criticism by encouraging news publishers participating in its Digital News Initiative to lobby against proposed changes to EU copyright law at a time when the beleaguered sector is increasingly turning to the search giant for help.”
Remember the Eric Schmidt comment about how brands are how you sort out (the non-YouTube portion of) the cesspool? As it turns out, he was allegedly wrong as Google claims they have been fighting for the little guy the whole time:
Article 11 could change that principle and require online services to strike commercial deals with publishers to show hyperlinks and short snippets of news. This means that search engines, news aggregators, apps, and platforms would have to put commercial licences in place, and make decisions about which content to include on the basis of those licensing agreements and which to leave out. Effectively, companies like Google will be put in the position of picking winners and losers. … Why are large influential companies constraining how new and small publishers operate? … The proposed rules will undoubtedly hurt diversity of voices, with large publishers setting business models for the whole industry. This will not benefit all equally. … We believe the information we show should be based on quality, not on payment.
Facebook claims there is a local news problem: “Facebook Inc. has been looking to boost its local-news offerings since a 2017 survey showed most of its users were clamoring for more. It has run into a problem: There simply isn’t enough local news in vast swaths of the country. … more than one in five newspapers have closed in the past decade and a half, leaving half the counties in the nation with just one newspaper, and 200 counties with no newspaper at all.”
Google is so for the little guy that for their local news experiments they’ve partnered with a private equity backed newspaper roll up firm & another newspaper chain which did overpriced acquisitions & is trying to act like a PE firm (trying to not get eaten by the PE firm).
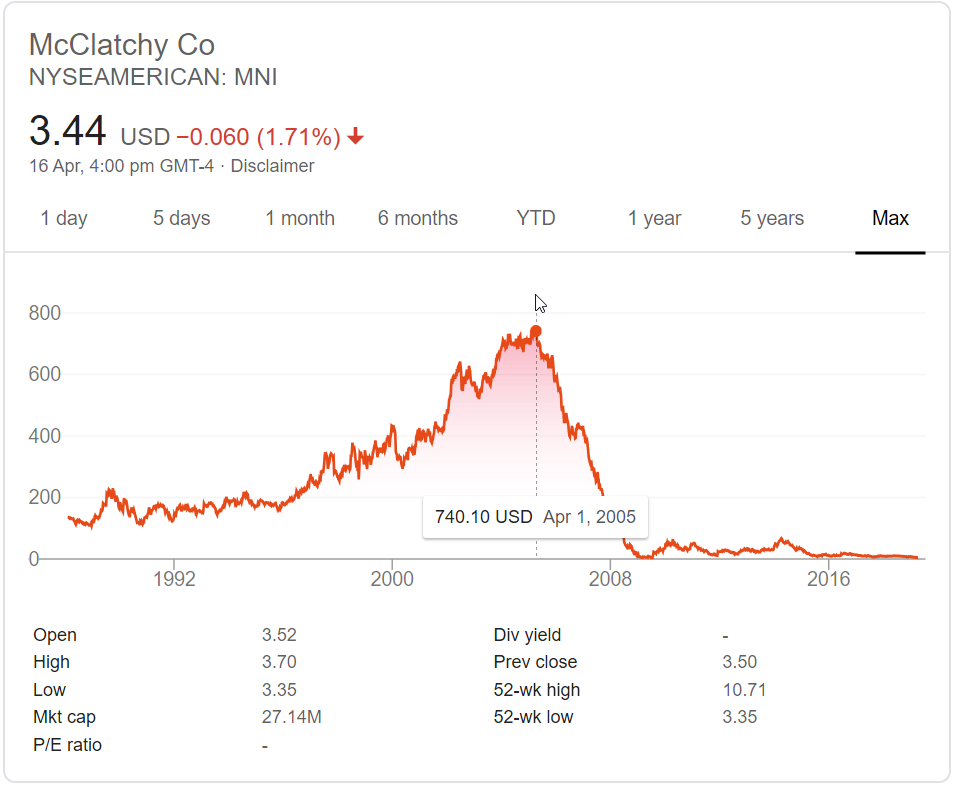
Does the above stock chart look in any way healthy?
Does it give off the scent of a firm that understood the impact of digital & rode it to new heights?
If you want good market-based outcomes, why not partner with journalists directly versus operating through PE chop shops?
If Patch is profitable & Google were a neutral ranking system based on quality, couldn’t Google partner with journalists directly?
Throwing a few dollars at a PE firm in some nebulous partnership sure beats the sort of regulations coming out of the EU. And the EU’s regulations (and prior link tax attempts) are in addition to the three multi billion Euro fines the European Union has levied against Alphabet for shopping search, Android & AdSense.
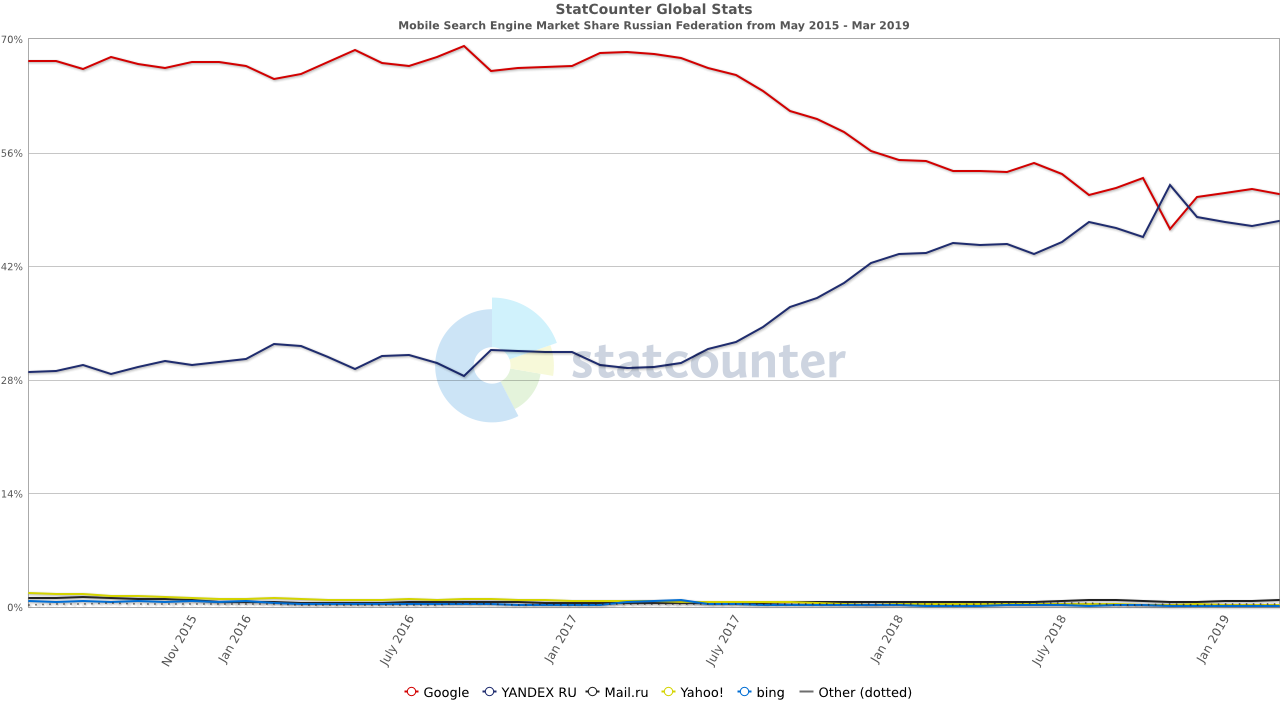
Google was also fined in Russia over Android bundling. The fine was tiny, but after consumers gained a search engine choice screen (much like Google pushed for in Europe on Microsoft years ago) Yandex’s share of mobile search grew quickly.
The UK recently published a white paper on online harms. In some ways it is a regulation just like the tech companies might offer to participants in their ecosystems:
Companies will have to fulfil their new legal duties or face the consequences and “will still need to be compliant with the overarching duty of care even where a specific code does not exist, for example assessing and responding to the risk associated with emerging harms or technology”.
If web publishers should monitor inbound links to look for anything suspicious then the big platforms sure as hell have the resources & profit margins to monitor behavior on their own websites.
Australia passed the Sharing of Abhorrent Violent Material bill which requires platforms to expeditiously remove violent videos & notify the Australian police about them.
There are other layers of fracturing going on in the web as well.
Programmatic advertising shifted revenue from publishers to adtech companies & the largest ad sellers. Ad blockers further lower the ad revenues of many publishers. If you routinely use an ad blocker, try surfing the web for a while without one & you will notice layover welcome AdSense ads on sites as you browse the web – the very type of ad they were allegedly against when promoting AMP.
There has been much more press in the past week about ad blocking as Google’s influence is being questioned as it rolls out ad blocking as a feature built into Google’s dominant Chrome web browser. https://t.co/LQmvJu9MYB— Jason Kint (@jason_kint) February 19, 2018
Tracking protection in browsers & ad blocking features built directly into browsers leave publishers more uncertain. And who even knows who visited an AMP page hosted on a third party server, particularly when things like GDPR are mixed in? Those who lack first party data may end up having to make large acquisitions to stay relevant.
Voice search & personal assistants are now ad channels.
Google Assistant Now Showing Sponsored Link Ads for Some Travel Related Queries “Similar results are delivered through both Google Home and Google Home Hub without the sponsored links.” https://t.co/jSVKKI2AYT via @bretkinsella pic.twitter.com/0sjAswy14M— Glenn Gabe (@glenngabe) April 15, 2019
App stores are removing VPNs in China, removing Tiktok in India, and keeping female tracking apps in Saudi Arabia. App stores are centralized chokepoints for governments. Every centralized service is at risk of censorship. Web browsers from key state-connected players can also censor messages spread by developers on platforms like GitHub.
Microsoft’s newest Edge web browser is based on Chromium, the source of Google Chrome. While Mozilla Firefox gets most of their revenue from a search deal with Google, Google has still went out of its way to use its services to both promote Chrome with pop overs AND break in competing web browsers:
“All of this is stuff you’re allowed to do to compete, of course. But we were still a search partner, so we’d say ‘hey what gives?’ And every time, they’d say, ‘oops. That was accidental. We’ll fix it in the next push in 2 weeks.’ Over and over. Oops. Another accident. We’ll fix it soon. We want the same things. We’re on the same team. There were dozens of oopses. Hundreds maybe?” – former Firefox VP Jonathan Nightingale
This is how it spreads. Google normalizes “web apps” that are really just Chrome apps. Then others follow. We’ve been here before, y’all. Remember IE? Browser hegemony is not a happy place. https://t.co/b29EvIty1H— DHH (@dhh) April 1, 2019
In fact, it’s alarming how much of Microsoft’s cut-off-the-air-supply playbook on browser dominance that Google is emulating. From browser-specific apps to embrace-n-extend AMP “standards”. It’s sad, but sadder still is when others follow suit.— DHH (@dhh) April 1, 2019
YouTube page load is 5x slower in Firefox and Edge than in Chrome because YouTube’s Polymer redesign relies on the deprecated Shadow DOM v0 API only implemented in Chrome. You can restore YouTube’s faster pre-Polymer design with this Firefox extension: https://t.co/F5uEn3iMLR— Chris Peterson (@cpeterso) July 24, 2018
As phone sales fall & app downloads stall a hardware company like Apple is pushing hard into services while quietly raking in utterly fantastic ad revenues from search & ads in their app store.
Part of the reason people are downloading fewer apps is so many apps require registration as soon as they are opened, or only let a user engage with them for seconds before pushing aggressive upsells. And then many apps which were formerly one-off purchases are becoming subscription plays. As traffic acquisition costs have jumped, many apps must engage in sleight of hand behaviors (free but not really, we are collecting data totally unrelated to the purpose of our app & oops we sold your data, etc.) in order to get the numbers to back out. This in turn causes app stores to slow down app reviews.
Apple acquired the news subscription service Texture & turned it into Apple News Plus. Not only is Apple keeping half the subscription revenues, but soon the service will only work for people using Apple devices, leaving nearly 100,000 other subscribers out in the cold: “if you’re part of the 30% who used Texture to get your favorite magazines digitally on Android or Windows devices, you will soon be out of luck. Only Apple iOS devices will be able to access the 300 magazines available from publishers. At the time of the sale in March 2018 to Apple, Texture had about 240,000 subscribers.”
Apple is also going to spend over a half-billion Dollars exclusively licensing independently developed games:
Several people involved in the project’s development say Apple is spending several million dollars each on most of the more than 100 games that have been selected to launch on Arcade, with its total budget likely to exceed $500m. The games service is expected to launch later this year. … Apple is offering developers an extra incentive if they agree for their game to only be available on Arcade, withholding their release on Google’s Play app store for Android smartphones or other subscription gaming bundles such as Microsoft’s Xbox game pass.
Verizon wants to launch a video game streaming service. It will probably be almost as successful as their Go90 OTT service was. Microsoft is pushing to make Xbox games work on Android devices. Amazon is developing a game streaming service to compliment Twitch.
The hosts on Twitch, some of whom sign up exclusively with the platform in order to gain access to its moneymaking tools, are rewarded for their ability to make a connection with viewers as much as they are for their gaming prowess. Viewers who pay $4.99 a month for a basic subscription — the money is split evenly between the streamers and Twitch — are looking for immediacy and intimacy. While some hosts at YouTube Gaming offer a similar experience, they have struggled to build audiences as large, and as dedicated, as those on Twitch. … While YouTube has made millionaires out of the creators of popular videos through its advertising program, Twitch’s hosts make money primarily from subscribers and one-off donations or tips. YouTube Gaming has made it possible for viewers to support hosts this way, but paying audiences haven’t materialized at the scale they have on Twitch.
Google, having a bit of Twitch envy, is also launching a video game streaming service which will be deeply integrated into YouTube: “With Stadia, YouTube watchers can press “Play now” at the end of a video, and be brought into the game within 5 seconds. The service provides “instant access” via button or link, just like any other piece of content on the web.”
Google will also launch their own game studio making exclusive games for their platform.
When consoles don’t use discs or cartridges so they can sell a subscription access to their software library it is hard to be a game retailer! GameStop’s stock has been performing like an ICO. And these sorts of announcements from the tech companies have been hitting stock prices for companies like Nintendo & Sony: “There is no doubt this service makes life even more difficult for established platforms,” Amir Anvarzadeh, a market strategist at Asymmetric Advisors Pte, said in a note to clients. “Google will help further fragment the gaming market which is already coming under pressure by big games which have adopted the mobile gaming business model of giving the titles away for free in hope of generating in-game content sales.”
The big tech companies which promoted everything in adjacent markets being free are now erecting paywalls for themselves, balkanizing the web by paying for exclusives to drive their bundled subscriptions.
How many paid movie streaming services will the web have by the end of next year? 20? 50? Does anybody know?
Disney alone with operate Disney+, ESPN+ as well as Hulu.
And then the tech companies are not only licensing exclusives to drive their subscription-based services, but we’re going to see more exclusionary policies like YouTube not working on Amazon Echo, Netflix dumping support for Apple’s Airplay, or Amazon refusing to sell devices like Chromecast or Apple TV.
The good news in a fractured web is a broader publishing industry that contains many micro markets will have many opportunities embedded in it. A Facebook pivot away from games toward news, or a pivot away from news toward video won’t kill third party publishers who have a more diverse traffic profile and more direct revenues. And a regional law blocking porn or gambling websites might lead to an increase in demand for VPNs or free to play points-based games with paid upgrades. Even the rise of metered paywalls will lead to people using more web browsers & more VPNs. Each fracture (good or bad) will create more market edges & ultimately more opportunities. Chinese enforcement of their gambling laws created a real estate boom in Manila.
So long as there are 4 or 5 game stores, 4 or 5 movie streaming sites, etc. … they have to compete on merit or use money to try to buy exclusives. Either way is better than the old monopoly strategy of take it or leave it ultimatums.
The publisher wins because there is a competitive bid. There won’t be an arbitrary 30% tax on everything. So long as there is competition from the open web there will be means to bypass the junk fees & the most successful companies that do so might create their own stores with a lower rate: “Mr. Schachter estimates that Apple and Google could see a hit of about 14% to pretax earnings if they reduced their own app commissions to match Epic’s take.”
As the big media companies & big tech companies race to create subscription products they’ll spend many billions on exclusives. And they will be training consumers that there’s nothing wrong with paying for content. This will eventually lead to hundreds of thousands or even millions of successful niche publications which have incentives better aligned than all the issues the ad supported web has faced.
Categories:
The Fractured Web
Anyone can argue about the intent of a particular action & the outcome that is derived by it. But when the outcome is known, at some point the intent is inferred if the outcome is derived from a source of power & the outcome doesn’t change.
Or, put another way, if a powerful entity (government, corporation, other organization) disliked an outcome which appeared to benefit them in the short term at great lasting cost to others, they could spend resources to adjust the system.
If they don’t spend those resources (or, rather, spend them on lobbying rather than improving the ecosystem) then there is no desired change. The outcome is as desired. Change is unwanted.
Engagement is a toxic metric.
Products which optimize for it become worse. People who optimize for it become less happy.
It also seems to generate runaway feedback loops where most engagable people have a) worst individual experiences and then b) end up driving the product bus.— Patrick McKenzie (@patio11) April 9, 2019
News is a stock vs flow market where the flow of recent events drives most of the traffic to articles. News that is more than a couple days old is no longer news. A news site which stops publishing news stops becoming a habit & quickly loses relevancy. Algorithmically an abandoned archive of old news articles doesn’t look much different than eHow, in spite of having a much higher cost structure.
According to SEMrush’s traffic rank, ampproject.org gets more monthly visits than Yahoo.com.
That actually understates the prevalence of AMP because AMP is generally designed for mobile AND not all AMP-formatted content is displayed on ampproject.org.
Part of how AMP was able to get widespread adoption was because in the news vertical the organic search result set was displaced by an AMP block. If you were a news site either you were so differentiated that readers would scroll past the AMP block in the search results to look for you specifically, or you adopted AMP, or you were doomed.
Some news organizations like The Guardian have a team of about a dozen people reformatting their content to the duplicative & proprietary AMP format. That’s wasteful, but necessary “In theory, adoption of AMP is voluntary. In reality, publishers that don’t want to see their search traffic evaporate have little choice. New data from publisher analytics firm Chartbeat shows just how much leverage Google has over publishers thanks to its dominant search engine.”
It seems more than a bit backward that low margin publishers are doing duplicative work to distance themselves from their own readers while improving the profit margins of monopolies. But it is what it is. And that no doubt drew the ire of many publishers across the EU.
And now there are AMP Stories to eat up even more visual real estate.
If you spent a bunch of money to create a highly differentiated piece of content, why would you prefer that high spend flagship content appear on a third party website rather than your own?
Google & Facebook have done such a fantastic job of eating the entire pie that some are celebrating Amazon as a prospective savior to the publishing industry. That view – IMHO – is rather suspect.
Where any of the tech monopolies dominate they cram down on partners. The New York Times acquired The Wirecutter in Q4 of 2016. In Q1 of 2017 Amazon adjusted their affiliate fee schedule.
Amazon generally treats consumers well, but they have been much harder on business partners with tough pricing negotiations, counterfeit protections, forced ad buying to have a high enough product rank to be able to rank organically, ad displacement of their organic search results below the fold (even for branded search queries), learning suppliers & cutting out the partners, private label products patterned after top sellers, in some cases running pop over ads for the private label products on product level pages where brands already spent money to drive traffic to the page, etc.
They’ve made things tougher for their partners in a way that mirrors the impact Facebook & Google have had on online publishers:
“Boyce’s experience on Amazon largely echoed what happens in the offline world: competitors entered the market, pushing down prices and making it harder to make a profit. So Boyce adapted. He stopped selling basketball hoops and developed his own line of foosball tables, air hockey tables, bocce ball sets and exercise equipment. The best way to make a decent profit on Amazon was to sell something no one else had and create your own brand. … Amazon also started selling bocce ball sets that cost $15 less than Boyce’s. He says his products are higher quality, but Amazon gives prominent page space to its generic version and wins the cost-conscious shopper.”
Google claims they have no idea how content publishers are with the trade off between themselves & the search engine, but every quarter Alphabet publish the share of ad spend occurring on owned & operated sites versus the share spent across the broader publisher network. And in almost every quarter for over a decade straight that ratio has grown worse for publishers.
When Google tells industry about how much $ it funnels to rest of ecosystem, just show them this chart. It’s good to be the “revenue regulator” (note: G went public in 2004). pic.twitter.com/HCbCNgbzKc— Jason Kint (@jason_kint) February 5, 2019
The aggregate numbers for news publishers are worse than shown above as Google is ramping up ads in video games quite hard. They’ve partnered with Unity & promptly took away the ability to block ads from appearing in video games using googleadsenseformobileapps.com exclusion (hello flat thumb misclicks, my name is budget & I am gone!)
They will also track video game player behavior & alter game play to maximize revenues based on machine learning tied to surveillance of the user’s account: “We’re bringing a new approach to monetization that combines ads and in-app purchases in one automated solution. Available today, new smart segmentation features in Google AdMob use machine learning to segment your players based on their likelihood to spend on in-app purchases. Ad units with smart segmentation will show ads only to users who are predicted not to spend on in-app purchases. Players who are predicted to spend will see no ads, and can simply continue playing.”
And how does the growth of ampproject.org square against the following wisdom?
If you do use a CDN, I’d recommend using a domain name of your own (eg, https://t.co/fWMc6CFPZ0), so you can move to other CDNs if you feel the need to over time, without having to do any redirects.— John (@JohnMu) April 15, 2019
Literally only yesterday did Google begin supporting instant loading of self-hosted AMP pages.
China has a different set of tech leaders than the United States. Baidu, Alibaba, Tencent (BAT) instead of Facebook, Amazon, Apple, Netflix, Google (FANG). China tech companies may have won their domestic markets in part based on superior technology or better knowledge of the local culture, though those same companies have largely went nowhere fast in most foreign markets. A big part of winning was governmental assistance in putting a foot on the scales.
Part of the US-China trade war is about who controls the virtual “seas” upon which value flows:
it can easily be argued that the last 60 years were above all the era of the container-ship (with container-ships getting ever bigger). But will the coming decades still be the age of the container-ship? Possibly not, for the simple reason that things that have value increasingly no longer travel by ship, but instead by fiberoptic cables! … you could almost argue that ZTE and Huawei have been the “East India Company” of the current imperial cycle. Unsurprisingly, it is these very companies, charged with laying out the “new roads” along which “tomorrow’s value” will flow, that find themselves at the center of the US backlash. … if the symbol of British domination was the steamship, and the symbol of American strength was the Boeing 747, it seems increasingly clear that the question of the future will be whether tomorrow’s telecom switches and routers are produced by Huawei or Cisco. … US attempts to take down Huawei and ZTE can be seen as the existing empire’s attempt to prevent the ascent of a new imperial power. With this in mind, I could go a step further and suggest that perhaps the Huawei crisis is this century’s version of Suez crisis. No wonder markets have been falling ever since the arrest of the Huawei CFO. In time, the Suez Crisis was brought to a halt by US threats to destroy the value of sterling. Could we now witness the same for the US dollar?
China maintains Huawei is an employee-owned company. But that proposition is suspect. Broadly stealing technology is vital to the growth of the Chinese economy & they have no incentive to stop unless their leading companies pay a direct cost. Meanwhile, China is investigating Ericsson over licensing technology.
Amazon will soon discontinue selling physical retail products in China: “Amazon shoppers in China will no longer be able to buy goods from third-party merchants in the country, but they still will be able to order from the United States, Britain, Germany and Japan via the firm’s global store. Amazon expects to close fulfillment centers and wind down support for domestic-selling merchants in China in the next 90 days.”
India has taken notice of the success of Chinese tech companies & thus began to promote “national champion” company policies. That, in turn, has also meant some of the Chinese-styled laws requiring localized data, antitrust inquiries, foreign ownership restrictions, requirements for platforms to not sell their own goods, promoting limits on data encryption, etc.
The secretary of India’s Telecommunications Department, Aruna Sundararajan, last week told a gathering of Indian startups in a closed-door meeting in the tech hub of Bangalore that the government will introduce a “national champion” policy “very soon” to encourage the rise of Indian companies, according to a person familiar with the matter. She said Indian policy makers had noted the success of China’s internet giants, Alibaba Group Holding Ltd. and Tencent Holdings Ltd. … Tensions began rising last year, when New Delhi decided to create a clearer set of rules for e-commerce and convened a group of local players to solicit suggestions. Amazon and Flipkart, even though they make up more than half the market, weren’t invited, according to people familiar with the matter.
Amazon vowed to invest $5 billion in India & they have done some remarkable work on logistics there. Walmart acquired Flipkart for $16 billion.
Other emerging markets also have many local ecommerce leaders like Jumia, MercadoLibre, OLX, Gumtree, Takealot, Konga, Kilimall, BidOrBuy, Tokopedia, Bukalapak, Shoppee, Lazada. If you live in the US you may have never heard of *any* of those companies. And if you live in an emerging market you may have never interacted with Amazon or eBay.
It makes sense that ecommerce leadership would be more localized since it requires moving things in the physical economy, dealing with local currencies, managing inventory, shipping goods, etc. whereas information flows are just bits floating on a fiber optic cable.
If the Internet is primarily seen as a communications platform it is easy for people in some emerging markets to think Facebook is the Internet. Free communication with friends and family members is a compelling offer & as the cost of data drops web usage increases.
At the same time, the web is incredibly deflationary. Every free form of entertainment which consumes time is time that is not spent consuming something else.
Add the technological disruption to the wealth polarization that happened in the wake of the great recession, then combine that with algorithms that promote extremist views & it is clearly causing increasing conflict.
If you are a parent and you think you child has no shot at a brighter future than your own life it is easy to be full of rage.
Empathy can radicalize otherwise normal people by giving them a more polarized view of the world:
Starting around 2000, the line starts to slide. More students say it’s not their problem to help people in trouble, not their job to see the world from someone else’s perspective. By 2009, on all the standard measures, Konrath found, young people on average measure 40 percent less empathetic than my own generation … The new rule for empathy seems to be: reserve it, not for your “enemies,” but for the people you believe are hurt, or you have decided need it the most. Empathy, but just for your own team. And empathizing with the other team? That’s practically a taboo.
A complete lack of empathy could allow a psychopath to commit extreme crimes while feeling no guilt, shame or remorse. Extreme empathy can have the same sort of outcome:
“Sometimes we commit atrocities not out of a failure of empathy but rather as a direct consequence of successful, even overly successful, empathy. … They emphasized that students would learn both sides, and the atrocities committed by one side or the other were always put into context. Students learned this curriculum, but follow-up studies showed that this new generation was more polarized than the one before. … [Empathy] can be good when it leads to good action, but it can have downsides. For example, if you want the victims to say ‘thank you.’ You may even want to keep the people you help in that position of inferior victim because it can sustain your feeling of being a hero.” – Fritz Breithaupt
News feeds will be read. Villages will be razed. Lynch mobs will become commonplace.
Many people will end up murdered by algorithmically generated empathy.
As technology increases absentee ownership & financial leverage, a society led by morally agnostic algorithms is not going to become more egalitarian.
The more I think about and discuss it, the more I think WhatsApp is simultaneously the future of Facebook, and the most potentially dangerous digital tool yet created. We haven’t even begun to see the real impact yet of ubiquitous, unfettered and un-moderatable human telepathy.— Antonio García Martínez (@antoniogm) April 15, 2019
When politicians throw fuel on the fire it only gets worse:
It’s particularly odd that the government is demanding “accountability and responsibility” from a phone app when some ruling party politicians are busy spreading divisive fake news. How can the government ask WhatsApp to control mobs when those convicted of lynching Muslims have been greeted, garlanded and fed sweets by some of the most progressive and cosmopolitan members of Modi’s council of ministers?
Mark Zuckerburg won’t get caught downstream from platform blowback as he spends $20 million a year on his security.
The web is a mirror. Engagement-based algorithms reinforcing our perceptions & identities.
And every important story has at least 2 sides!
The Rohingya asylum seekers are victims of their own violent Jihadist leadership that formed a militia to kill Buddhists and Hindus. Hindus are being massacred, where’s the outrage for them!? https://t.co/P3m6w4B1Po— Imam Tawhidi (@Imamofpeace) May 23, 2018
Some may “learn” vaccines don’t work. Others may learn the vaccines their own children took did not work, as it failed to protect them from the antivax content spread by Facebook & Google, absorbed by people spreading measles & Medieval diseases.
Passion drives engagement, which drives algorithmic distribution: “There’s an asymmetry of passion at work. Which is to say, there’s very little counter-content to surface because it simply doesn’t occur to regular people (or, in this case, actual medical experts) that there’s a need to produce counter-content.”
As the costs of “free” become harder to hide, social media companies which currently sell emerging markets as their next big growth area will end up having embedded regulatory compliance costs which will end up exceeding any sort of prospective revenue they could hope to generate.
The Pinterest S1 shows almost all their growth is in emerging markets, yet almost all their revenue is inside the United States.
As governments around the world see the real-world cost of the foreign tech companies & view some of them as piggy banks, eventually the likes of Facebook or Google will pull out of a variety of markets they no longer feel worth serving. It will be like Google did in mainland China with search after discovering pervasive hacking of activist Gmail accounts.
Just tried signing into Gmail from a new device. Unless I provide a phone number, there is no way to sign in and no one to call about it. Oh, and why do they say they need my phone? If you guessed “for my protection,” you would be correct. Talk about Big Brother…— Simon Mikhailovich (@S_Mikhailovich) April 16, 2019
Lower friction & lower cost information markets will face more junk fees, hurdles & even some legitimate regulations. Information markets will start to behave more like physical goods markets.
The tech companies presume they will be able to use satellites, drones & balloons to beam in Internet while avoiding messy local issues tied to real world infrastructure, but when a local wealthy player is betting against them they’ll probably end up losing those markets: “One of the biggest cheerleaders for the new rules was Reliance Jio, a fast-growing mobile phone company controlled by Mukesh Ambani, India’s richest industrialist. Mr. Ambani, an ally of Mr. Modi, has made no secret of his plans to turn Reliance Jio into an all-purpose information service that offers streaming video and music, messaging, money transfer, online shopping, and home broadband services.”
Publishers do not have “their mojo back” because the tech companies have been so good to them, but rather because the tech companies have been so aggressive that they’ve earned so much blowback which will in turn lead publishers to opting out of future deals, which will eventually lead more people back to the trusted brands of yesterday.
Publishers feeling guilty about taking advertorial money from the tech companies to spread their propaganda will offset its publication with opinion pieces pointing in the other direction: “This is a lobbying campaign in which buying the good opinion of news brands is clearly important. If it was about reaching a target audience, there are plenty of metrics to suggest his words would reach further – at no cost – on Facebook. Similarly, Google is upping its presence in a less obvious manner via assorted media initiatives on both sides of the Atlantic. Its more direct approach to funding journalism seems to have the desired effect of making all media organisations (and indeed many academic institutions) touched by its money slightly less questioning and critical of its motives.”
When Facebook goes down direct visits to leading news brand sites go up.
When Google penalizes a no-name me-too site almost nobody realizes it is missing. But if a big publisher opts out of the ecosystem people will notice.
The reliance on the tech platforms is largely a mirage. If enough key players were to opt out at the same time people would quickly reorient their information consumption habits.
If the platforms can change their focus overnight then why can’t publishers band together & choose to dump them?
CEO Jack Dorsey said Twitter is looking to change the focus from following specific individuals to topics of interest, acknowledging that what’s incentivized today on the platform is at odds with the goal of healthy dialoguehttps://t.co/31FYslbePA— Axios (@axios) April 16, 2019
In Europe there is GDPR, which aimed to protect user privacy, but ultimately acted as a tax on innovation by local startups while being a subsidy to the big online ad networks. They also have Article 11 & Article 13, which passed in spite of Google’s best efforts on the scaremongering anti-SERP tests, lobbying & propaganda fronts: “Google has sparked criticism by encouraging news publishers participating in its Digital News Initiative to lobby against proposed changes to EU copyright law at a time when the beleaguered sector is increasingly turning to the search giant for help.”
Remember the Eric Schmidt comment about how brands are how you sort out (the non-YouTube portion of) the cesspool? As it turns out, he was allegedly wrong as Google claims they have been fighting for the little guy the whole time:
Article 11 could change that principle and require online services to strike commercial deals with publishers to show hyperlinks and short snippets of news. This means that search engines, news aggregators, apps, and platforms would have to put commercial licences in place, and make decisions about which content to include on the basis of those licensing agreements and which to leave out. Effectively, companies like Google will be put in the position of picking winners and losers. … Why are large influential companies constraining how new and small publishers operate? … The proposed rules will undoubtedly hurt diversity of voices, with large publishers setting business models for the whole industry. This will not benefit all equally. … We believe the information we show should be based on quality, not on payment.
Facebook claims there is a local news problem: “Facebook Inc. has been looking to boost its local-news offerings since a 2017 survey showed most of its users were clamoring for more. It has run into a problem: There simply isn’t enough local news in vast swaths of the country. … more than one in five newspapers have closed in the past decade and a half, leaving half the counties in the nation with just one newspaper, and 200 counties with no newspaper at all.”
Google is so for the little guy that for their local news experiments they’ve partnered with a private equity backed newspaper roll up firm & another newspaper chain which did overpriced acquisitions & is trying to act like a PE firm (trying to not get eaten by the PE firm).
Does the above stock chart look in any way healthy?
Does it give off the scent of a firm that understood the impact of digital & rode it to new heights?
If you want good market-based outcomes, why not partner with journalists directly versus operating through PE chop shops?
If Patch is profitable & Google were a neutral ranking system based on quality, couldn’t Google partner with journalists directly?
Throwing a few dollars at a PE firm in some nebulous partnership sure beats the sort of regulations coming out of the EU. And the EU’s regulations (and prior link tax attempts) are in addition to the three multi billion Euro fines the European Union has levied against Alphabet for shopping search, Android & AdSense.
Google was also fined in Russia over Android bundling. The fine was tiny, but after consumers gained a search engine choice screen (much like Google pushed for in Europe on Microsoft years ago) Yandex’s share of mobile search grew quickly.
The UK recently published a white paper on online harms. In some ways it is a regulation just like the tech companies might offer to participants in their ecosystems:
Companies will have to fulfil their new legal duties or face the consequences and “will still need to be compliant with the overarching duty of care even where a specific code does not exist, for example assessing and responding to the risk associated with emerging harms or technology”.
If web publishers should monitor inbound links to look for anything suspicious then the big platforms sure as hell have the resources & profit margins to monitor behavior on their own websites.
Australia passed the Sharing of Abhorrent Violent Material bill which requires platforms to expeditiously remove violent videos & notify the Australian police about them.
There are other layers of fracturing going on in the web as well.
Programmatic advertising shifted revenue from publishers to adtech companies & the largest ad sellers. Ad blockers further lower the ad revenues of many publishers. If you routinely use an ad blocker, try surfing the web for a while without one & you will notice layover welcome AdSense ads on sites as you browse the web – the very type of ad they were allegedly against when promoting AMP.
There has been much more press in the past week about ad blocking as Google’s influence is being questioned as it rolls out ad blocking as a feature built into Google’s dominant Chrome web browser. https://t.co/LQmvJu9MYB— Jason Kint (@jason_kint) February 19, 2018
Tracking protection in browsers & ad blocking features built directly into browsers leave publishers more uncertain. And who even knows who visited an AMP page hosted on a third party server, particularly when things like GDPR are mixed in? Those who lack first party data may end up having to make large acquisitions to stay relevant.
Voice search & personal assistants are now ad channels.
Google Assistant Now Showing Sponsored Link Ads for Some Travel Related Queries
“Similar results are delivered through both Google Home and Google Home Hub without the sponsored links.” https://t.co/jSVKKI2AYT via @bretkinsella pic.twitter.com/0sjAswy14M— Glenn Gabe (@glenngabe) April 15, 2019
App stores are removing VPNs in China, removing Tiktok in India, and keeping female tracking apps in Saudi Arabia. App stores are centralized chokepoints for governments. Every centralized service is at risk of censorship. Web browsers from key state-connected players can also censor messages spread by developers on platforms like GitHub.
Microsoft’s newest Edge web browser is based on Chromium, the source of Google Chrome. While Mozilla Firefox gets most of their revenue from a search deal with Google, Google has still went out of its way to use its services to both promote Chrome with pop overs AND break in competing web browsers:
“All of this is stuff you’re allowed to do to compete, of course. But we were still a search partner, so we’d say ‘hey what gives?’ And every time, they’d say, ‘oops. That was accidental. We’ll fix it in the next push in 2 weeks.’ Over and over. Oops. Another accident. We’ll fix it soon. We want the same things. We’re on the same team. There were dozens of oopses. Hundreds maybe?” – former Firefox VP Jonathan Nightingale
This is how it spreads. Google normalizes “web apps” that are really just Chrome apps. Then others follow. We’ve been here before, y’all. Remember IE? Browser hegemony is not a happy place. https://t.co/b29EvIty1H— DHH (@dhh) April 1, 2019
In fact, it’s alarming how much of Microsoft’s cut-off-the-air-supply playbook on browser dominance that Google is emulating. From browser-specific apps to embrace-n-extend AMP “standards”. It’s sad, but sadder still is when others follow suit.— DHH (@dhh) April 1, 2019
YouTube page load is 5x slower in Firefox and Edge than in Chrome because YouTube’s Polymer redesign relies on the deprecated Shadow DOM v0 API only implemented in Chrome. You can restore YouTube’s faster pre-Polymer design with this Firefox extension: https://t.co/F5uEn3iMLR— Chris Peterson (@cpeterso) July 24, 2018
As phone sales fall & app downloads stall a hardware company like Apple is pushing hard into services while quietly raking in utterly fantastic ad revenues from search & ads in their app store.
Part of the reason people are downloading fewer apps is so many apps require registration as soon as they are opened, or only let a user engage with them for seconds before pushing aggressive upsells. And then many apps which were formerly one-off purchases are becoming subscription plays. As traffic acquisition costs have jumped, many apps must engage in sleight of hand behaviors (free but not really, we are collecting data totally unrelated to the purpose of our app & oops we sold your data, etc.) in order to get the numbers to back out. This in turn causes app stores to slow down app reviews.
Apple acquired the news subscription service Texture & turned it into Apple News Plus. Not only is Apple keeping half the subscription revenues, but soon the service will only work for people using Apple devices, leaving nearly 100,000 other subscribers out in the cold: “if you’re part of the 30% who used Texture to get your favorite magazines digitally on Android or Windows devices, you will soon be out of luck. Only Apple iOS devices will be able to access the 300 magazines available from publishers. At the time of the sale in March 2018 to Apple, Texture had about 240,000 subscribers.”
Apple is also going to spend over a half-billion Dollars exclusively licensing independently developed games:
Several people involved in the project’s development say Apple is spending several million dollars each on most of the more than 100 games that have been selected to launch on Arcade, with its total budget likely to exceed $500m. The games service is expected to launch later this year. … Apple is offering developers an extra incentive if they agree for their game to only be available on Arcade, withholding their release on Google’s Play app store for Android smartphones or other subscription gaming bundles such as Microsoft’s Xbox game pass.
Verizon wants to launch a video game streaming service. It will probably be almost as successful as their Go90 OTT service was. Microsoft is pushing to make Xbox games work on Android devices. Amazon is developing a game streaming service to compliment Twitch.
The hosts on Twitch, some of whom sign up exclusively with the platform in order to gain access to its moneymaking tools, are rewarded for their ability to make a connection with viewers as much as they are for their gaming prowess. Viewers who pay $4.99 a month for a basic subscription — the money is split evenly between the streamers and Twitch — are looking for immediacy and intimacy. While some hosts at YouTube Gaming offer a similar experience, they have struggled to build audiences as large, and as dedicated, as those on Twitch. … While YouTube has made millionaires out of the creators of popular videos through its advertising program, Twitch’s hosts make money primarily from subscribers and one-off donations or tips. YouTube Gaming has made it possible for viewers to support hosts this way, but paying audiences haven’t materialized at the scale they have on Twitch.
Google, having a bit of Twitch envy, is also launching a video game streaming service which will be deeply integrated into YouTube: “With Stadia, YouTube watchers can press “Play now” at the end of a video, and be brought into the game within 5 seconds. The service provides “instant access” via button or link, just like any other piece of content on the web.”
Google will also launch their own game studio making exclusive games for their platform.
When consoles don’t use discs or cartridges so they can sell a subscription access to their software library it is hard to be a game retailer! GameStop’s stock has been performing like an ICO. And these sorts of announcements from the tech companies have been hitting stock prices for companies like Nintendo & Sony: “There is no doubt this service makes life even more difficult for established platforms,” Amir Anvarzadeh, a market strategist at Asymmetric Advisors Pte, said in a note to clients. “Google will help further fragment the gaming market which is already coming under pressure by big games which have adopted the mobile gaming business model of giving the titles away for free in hope of generating in-game content sales.”
The big tech companies which promoted everything in adjacent markets being free are now erecting paywalls for themselves, balkanizing the web by paying for exclusives to drive their bundled subscriptions.
How many paid movie streaming services will the web have by the end of next year? 20? 50? Does anybody know?
Disney alone with operate Disney+, ESPN+ as well as Hulu.
And then the tech companies are not only licensing exclusives to drive their subscription-based services, but we’re going to see more exclusionary policies like YouTube not working on Amazon Echo, Netflix dumping support for Apple’s Airplay, or Amazon refusing to sell devices like Chromecast or Apple TV.
The good news in a fractured web is a broader publishing industry that contains many micro markets will have many opportunities embedded in it. A Facebook pivot away from games toward news, or a pivot away from news toward video won’t kill third party publishers who have a more diverse traffic profile and more direct revenues. And a regional law blocking porn or gambling websites might lead to an increase in demand for VPNs or free to play points-based games with paid upgrades. Even the rise of metered paywalls will lead to people using more web browsers & more VPNs. Each fracture (good or bad) will create more market edges & ultimately more opportunities. Chinese enforcement of their gambling laws created a real estate boom in Manila.
So long as there are 4 or 5 game stores, 4 or 5 movie streaming sites, etc. … they have to compete on merit or use money to try to buy exclusives. Either way is better than the old monopoly strategy of take it or leave it ultimatums.
The publisher wins because there is a competitive bid. There won’t be an arbitrary 30% tax on everything. So long as there is competition from the open web there will be means to bypass the junk fees & the most successful companies that do so might create their own stores with a lower rate: “Mr. Schachter estimates that Apple and Google could see a hit of about 14% to pretax earnings if they reduced their own app commissions to match Epic’s take.”
As the big media companies & big tech companies race to create subscription products they’ll spend many billions on exclusives. And they will be training consumers that there’s nothing wrong with paying for content. This will eventually lead to hundreds of thousands or even millions of successful niche publications which have incentives better aligned than all the issues the ad supported web has faced.
Added: Facebook pushing privacy & groups is both an attempt to thwart regulation risk while also making their services more relevant to a web that fractures away from a monolithic thing into more niche communities.
One way of looking at Facebook in this moment is as an unstoppable behemoth that bends reality to its will, no matter the consequences. (This is how many journalists tend to see it.) Another way of looking at the company is from the perspective of its fundamental weakness — as a slave to ever-shifting consumer behavior. (This is how employees are more likely to look at it.) … Zuckerberg’s vision for a new Facebook is perhaps best represented by a coming redesign of the flagship app and desktop site that will emphasize events and groups, at the expense of the News Feed. Collectively, the design changes will push people toward smaller group conversations and real-world meetups — and away from public posts.
Categories:
Keyword Not Provided, But it Just Clicks
When SEO Was Easy
When I got started on the web over 15 years ago I created an overly broad & shallow website that had little chance of making money because it was utterly undifferentiated and crappy. In spite of my best (worst?) efforts while being a complete newbie, sometimes I would go to the mailbox and see a check for a couple hundred or a couple thousand dollars come in. My old roommate & I went to Coachella & when the trip was over I returned to a bunch of mail to catch up on & realized I had made way more while not working than what I spent on that trip.
What was the secret to a total newbie making decent income by accident?
Horrible spelling.
Back then search engines were not as sophisticated with their spelling correction features & I was one of 3 or 4 people in the search index that misspelled the name of an online casino the same way many searchers did.
The high minded excuse for why I did not scale that would be claiming I knew it was a temporary trick that was somehow beneath me. The more accurate reason would be thinking in part it was a lucky fluke rather than thinking in systems. If I were clever at the time I would have created the misspeller’s guide to online gambling, though I think I was just so excited to make anything from the web that I perhaps lacked the ambition & foresight to scale things back then.
In the decade that followed I had a number of other lucky breaks like that. One time one of the original internet bubble companies that managed to stay around put up a sitewide footer link targeting the concept that one of my sites made decent money from. This was just before the great recession, before Panda existed. The concept they targeted had 3 or 4 ways to describe it. 2 of them were very profitable & if they targeted either of the most profitable versions with that page the targeting would have sort of carried over to both. They would have outranked me if they targeted the correct version, but they didn’t so their mistargeting was a huge win for me.
Search Gets Complex
Search today is much more complex. In the years since those easy-n-cheesy wins, Google has rolled out many updates which aim to feature sought after destination sites while diminishing the sites which rely one “one simple trick” to rank.
Arguably the quality of the search results has improved significantly as search has become more powerful, more feature rich & has layered in more relevancy signals.
Many quality small web publishers have went away due to some combination of increased competition, algorithmic shifts & uncertainty, and reduced monetization as more ad spend was redirected toward Google & Facebook. But the impact as felt by any given publisher is not the impact as felt by the ecosystem as a whole. Many terrible websites have also went away, while some formerly obscure though higher-quality sites rose to prominence.
There was the Vince update in 2009, which boosted the rankings of many branded websites.
Then in 2011 there was Panda as an extension of Vince, which tanked the rankings of many sites that published hundreds of thousands or millions of thin content pages while boosting the rankings of trusted branded destinations.
Then there was Penguin, which was a penalty that hit many websites which had heavily manipulated or otherwise aggressive appearing link profiles. Google felt there was a lot of noise in the link graph, which was their justification for the Penguin.
There were updates which lowered the rankings of many exact match domains. And then increased ad load in the search results along with the other above ranking shifts further lowered the ability to rank keyword-driven domain names. If your domain is generically descriptive then there is a limit to how differentiated & memorable you can make it if you are targeting the core market the keywords are aligned with.
There is a reason eBay is more popular than auction.com, Google is more popular than search.com, Yahoo is more popular than portal.com & Amazon is more popular than a store.com or a shop.com. When that winner take most impact of many online markets is coupled with the move away from using classic relevancy signals the economics shift to where is makes a lot more sense to carry the heavy overhead of establishing a strong brand.
Branded and navigational search queries could be used in the relevancy algorithm stack to confirm the quality of a site & verify (or dispute) the veracity of other signals.
Historically relevant algo shortcuts become less appealing as they become less relevant to the current ecosystem & even less aligned with the future trends of the market. Add in negative incentives for pushing on a string (penalties on top of wasting the capital outlay) and a more holistic approach certainly makes sense.
Modeling Web Users & Modeling Language
PageRank was an attempt to model the random surfer.
When Google is pervasively monitoring most users across the web they can shift to directly measuring their behaviors instead of using indirect signals.
Years ago Bill Slawski wrote about the long click in which he opened by quoting Steven Levy’s In the Plex: How Google Thinks, Works, and Shapes our Lives
“On the most basic level, Google could see how satisfied users were. To paraphrase Tolstoy, happy users were all the same. The best sign of their happiness was the “Long Click” — This occurred when someone went to a search result, ideally the top one, and did not return. That meant Google has successfully fulfilled the query.”
Of course, there’s a patent for that. In Modifying search result ranking based on implicit user feedback they state:
user reactions to particular search results or search result lists may be gauged, so that results on which users often click will receive a higher ranking. The general assumption under such an approach is that searching users are often the best judges of relevance, so that if they select a particular search result, it is likely to be relevant, or at least more relevant than the presented alternatives.
If you are a known brand you are more likely to get clicked on than a random unknown entity in the same market.
And if you are something people are specifically seeking out, they are likely to stay on your website for an extended period of time.
One aspect of the subject matter described in this specification can be embodied in a computer-implemented method that includes determining a measure of relevance for a document result within a context of a search query for which the document result is returned, the determining being based on a first number in relation to a second number, the first number corresponding to longer views of the document result, and the second number corresponding to at least shorter views of the document result; and outputting the measure of relevance to a ranking engine for ranking of search results, including the document result, for a new search corresponding to the search query. The first number can include a number of the longer views of the document result, the second number can include a total number of views of the document result, and the determining can include dividing the number of longer views by the total number of views.
Attempts to manipulate such data may not work.
safeguards against spammers (users who generate fraudulent clicks in an attempt to boost certain search results) can be taken to help ensure that the user selection data is meaningful, even when very little data is available for a given (rare) query. These safeguards can include employing a user model that describes how a user should behave over time, and if a user doesn’t conform to this model, their click data can be disregarded. The safeguards can be designed to accomplish two main objectives: (1) ensure democracy in the votes (e.g., one single vote per cookie and/or IP for a given query-URL pair), and (2) entirely remove the information coming from cookies or IP addresses that do not look natural in their browsing behavior (e.g., abnormal distribution of click positions, click durations, clicks_per_minute/hour/day, etc.). Suspicious clicks can be removed, and the click signals for queries that appear to be spmed need not be used (e.g., queries for which the clicks feature a distribution of user agents, cookie ages, etc. that do not look normal).
And just like Google can make a matrix of documents & queries, they could also choose to put more weight on search accounts associated with topical expert users based on their historical click patterns.
Moreover, the weighting can be adjusted based on the determined type of the user both in terms of how click duration is translated into good clicks versus not-so-good clicks, and in terms of how much weight to give to the good clicks from a particular user group versus another user group. Some user’s implicit feedback may be more valuable than other users due to the details of a user’s review process. For example, a user that almost always clicks on the highest ranked result can have his good clicks assigned lower weights than a user who more often clicks results lower in the ranking first (since the second user is likely more discriminating in his assessment of what constitutes a good result). In addition, a user can be classified based on his or her query stream. Users that issue many queries on (or related to) a given topic T (e.g., queries related to law) can be presumed to have a high degree of expertise with respect to the given topic T, and their click data can be weighted accordingly for other queries by them on (or related to) the given topic T.
Google was using click data to drive their search rankings as far back as 2009. David Naylor was perhaps the first person who publicly spotted this. Google was ranking Australian websites for [tennis court hire] in the UK & Ireland, in part because that is where most of the click signal came from. That phrase was most widely searched for in Australia. In the years since Google has done a better job of geographically isolating clicks to prevent things like the problem David Naylor noticed, where almost all search results in one geographic region came from a different country.
Whenever SEOs mention using click data to search engineers, the search engineers quickly respond about how they might consider any signal but clicks would be a noisy signal. But if a signal has noise an engineer would work around the noise by finding ways to filter the noise out or combine multiple signals. To this day Google states they are still working to filter noise from the link graph: “We continued to protect the value of authoritative and relevant links as an important ranking signal for Search.”
The site with millions of inbound links, few intentional visits & those who do visit quickly click the back button (due to a heavy ad load, poor user experience, low quality content, shallow content, outdated content, or some other bait-n-switch approach)…that’s an outlier. Preventing those sorts of sites from ranking well would be another way of protecting the value of authoritative & relevant links.
Best Practices Vary Across Time & By Market + Category
Along the way, concurrent with the above sorts of updates, Google also improved their spelling auto-correct features, auto-completed search queries for many years through a featured called Google Instant (though they later undid forced query auto-completion while retaining automated search suggestions), and then they rolled out a few other algorithms that further allowed them to model language & user behavior.
Today it would be much harder to get paid above median wages explicitly for sucking at basic spelling or scaling some other individual shortcut to the moon, like pouring millions of low quality articles into a (formerly!) trusted domain.
Nearly a decade after Panda, eHow’s rankings still haven’t recovered.
Back when I got started with SEO the phrase Indian SEO company was associated with cut-rate work where people were buying exclusively based on price. Sort of like a “I got a $500 budget for link building, but can not under any circumstance invest more than $5 in any individual link.” Part of how my wife met me was she hired a hack SEO from San Diego who outsourced all the work to India and marked the price up about 100-fold while claiming it was all done in the United States. He created reciprocal links pages that got her site penalized & it didn’t rank until after she took her reciprocal links page down.
With that sort of behavior widespread (hack US firm teaching people working in an emerging market poor practices), it likely meant many SEO “best practices” which were learned in an emerging market (particularly where the web was also underdeveloped) would be more inclined to being spammy. Considering how far ahead many Western markets were on the early Internet & how India has so many languages & how most web usage in India is based on mobile devices where it is hard for users to create links, it only makes sense that Google would want to place more weight on end user data in such a market.
If you set your computer location to India Bing’s search box lists 9 different languages to choose from.
The above is not to state anything derogatory about any emerging market, but rather that various signals are stronger in some markets than others. And competition is stronger in some markets than others.
Search engines can only rank what exists.
“In a lot of Eastern European – but not just Eastern European markets – I think it is an issue for the majority of the [bream? muffled] countries, for the Arabic-speaking world, there just isn’t enough content as compared to the percentage of the Internet population that those regions represent. I don’t have up to date data, I know that a couple years ago we looked at Arabic for example and then the disparity was enormous. so if I’m not mistaken the Arabic speaking population of the world is maybe 5 to 6%, maybe more, correct me if I am wrong. But very definitely the amount of Arabic content in our index is several orders below that. So that means we do not have enough Arabic content to give to our Arabic users even if we wanted to. And you can exploit that amazingly easily and if you create a bit of content in Arabic, whatever it looks like we’re gonna go you know we don’t have anything else to serve this and it ends up being horrible. and people will say you know this works. I keyword stuffed the hell out of this page, bought some links, and there it is number one. There is nothing else to show, so yeah you’re number one. the moment somebody actually goes out and creates high quality content that’s there for the long haul, you’ll be out and that there will be one.” – Andrey Lipattsev – Search Quality Senior Strategist at Google Ireland, on Mar 23, 2016
Impacting the Economics of Publishing
Now search engines can certainly influence the economics of various types of media. At one point some otherwise credible media outlets were pitching the Demand Media IPO narrative that Demand Media was the publisher of the future & what other media outlets will look like. Years later, after heavily squeezing on the partner network & promoting programmatic advertising that reduces CPMs by the day Google is funding partnerships with multiple news publishers like McClatchy & Gatehouse to try to revive the news dead zones even Facebook is struggling with.
“Facebook Inc. has been looking to boost its local-news offerings since a 2017 survey showed most of its users were clamoring for more. It has run into a problem: There simply isn’t enough local news in vast swaths of the country. … more than one in five newspapers have closed in the past decade and a half, leaving half the counties in the nation with just one newspaper, and 200 counties with no newspaper at all.”
As mainstream newspapers continue laying off journalists, Facebook’s news efforts are likely to continue failing unless they include direct economic incentives, as Google’s programmatic ad push broke the banner ad:
“Thanks to the convoluted machinery of Internet advertising, the advertising world went from being about content publishers and advertising context—The Times unilaterally declaring, via its ‘rate card’, that ads in the Times Style section cost $30 per thousand impressions—to the users themselves and the data that targets them—Zappo’s saying it wants to show this specific shoe ad to this specific user (or type of user), regardless of publisher context. Flipping the script from a historically publisher-controlled mediascape to an advertiser (and advertiser intermediary) controlled one was really Google’s doing. Facebook merely rode the now-cresting wave, borrowing outside media’s content via its own users’ sharing, while undermining media’s ability to monetize via Facebook’s own user-data-centric advertising machinery. Conventional media lost both distribution and monetization at once, a mortal blow.”
Google is offering news publishers audience development & business development tools.
Heavy Investment in Emerging Markets Quickly Evolves the Markets
As the web grows rapidly in India, they’ll have a thousand flowers bloom. In 5 years the competition in India & other emerging markets will be much tougher as those markets continue to grow rapidly. Media is much cheaper to produce in India than it is in the United States. Labor costs are lower & they never had the economic albatross that is the ACA adversely impact their economy. At some point the level of investment & increased competition will mean early techniques stop having as much efficacy. Chinese companies are aggressively investing in India.
“If you break India into a pyramid, the top 100 million (urban) consumers who think and behave more like Americans are well-served,” says Amit Jangir, who leads India investments at 01VC, a Chinese venture capital firm based in Shanghai. The early stage venture firm has invested in micro-lending firms FlashCash and SmartCoin based in India. The new target is the next 200 million to 600 million consumers, who do not have a go-to entertainment, payment or ecommerce platform yet— and there is gonna be a unicorn in each of these verticals, says Jangir, adding that it will be not be as easy for a player to win this market considering the diversity and low ticket sizes.
RankBrain
RankBrain appears to be based on using user clickpaths on head keywords to help bleed rankings across into related searches which are searched less frequently. A Googler didn’t state this specifically, but it is how they would be able to use models of searcher behavior to refine search results for keywords which are rarely searched for.
In a recent interview in Scientific American a Google engineer stated: “By design, search engines have learned to associate short queries with the targets of those searches by tracking pages that are visited as a result of the query, making the results returned both faster and more accurate than they otherwise would have been.”
Now a person might go out and try to search for something a bunch of times or pay other people to search for a topic and click a specific listing, but some of the related Google patents on using click data (which keep getting updated) mentioned how they can discount or turn off the signal if there is an unnatural spike of traffic on a specific keyword, or if there is an unnatural spike of traffic heading to a particular website or web page.
And, since Google is tracking the behavior of end users on their own website, anomalous behavior is easier to track than it is tracking something across the broader web where signals are more indirect. Google can take advantage of their wide distribution of Chrome & Android where users are regularly logged into Google & pervasively tracked to place more weight on users where they had credit card data, a long account history with regular normal search behavior, heavy Gmail users, etc.
Plus there is a huge gap between the cost of traffic & the ability to monetize it. You might have to pay someone a dime or a quarter to search for something & there is no guarantee it will work on a sustainable basis even if you paid hundreds or thousands of people to do it. Any of those experimental searchers will have no lasting value unless they influence rank, but even if they do influence rankings it might only last temporarily. If you bought a bunch of traffic into something genuine Google searchers didn’t like then even if it started to rank better temporarily the rankings would quickly fall back if the real end user searchers disliked the site relative to other sites which already rank.
This is part of the reason why so many SEO blogs mention brand, brand, brand. If people are specifically looking for you in volume & Google can see that thousands or millions of people specifically want to access your site then that can impact how you rank elsewhere.
Even looking at something inside the search results for a while (dwell time) or quickly skipping over it to have a deeper scroll depth can be a ranking signal. Some Google patents mention how they can use mouse pointer location on desktop or scroll data from the viewport on mobile devices as a quality signal.
Neural Matching
Last year Danny Sullivan mentioned how Google rolled out neural matching to better understand the intent behind a search query.
This is a look back at a big change in search but which continues to be important: understanding synonyms. How people search is often different from information that people write solutions about. pic.twitter.com/sBcR4tR4eT— Danny Sullivan (@dannysullivan) September 24, 2018
Last few months, Google has been using neural matching, –AI method to better connect words to concepts. Super synonyms, in a way, and impacting 30% of queries. Don’t know what “soapopera effect” is to search for it? We can better figure it out. pic.twitter.com/Qrwp5hKFNz— Danny Sullivan (@dannysullivan) September 24, 2018
The above Tweets capture what the neural matching technology intends to do. Google also stated:
we’ve now reached the point where neural networks can help us take a major leap forward from understanding words to understanding concepts. Neural embeddings, an approach developed in the field of neural networks, allow us to transform words to fuzzier representations of the underlying concepts, and then match the concepts in the query with the concepts in the document. We call this technique neural matching.
To help people understand the difference between neural matching & RankBrain, Google told SEL: “RankBrain helps Google better relate pages to concepts. Neural matching helps Google better relate words to searches.”
There are a couple research papers on neural matching.
The first one was titled A Deep Relevance Matching Model for Ad-hoc Retrieval. It mentioned using Word2vec & here are a few quotes from the research paper
- “Successful relevance matching requires proper handling of the exact matching signals, query term importance, and diverse matching requirements.”
- “the interaction-focused model, which first builds local level interactions (i.e., local matching signals) between two pieces of text, and then uses deep neural networks to learn hierarchical interaction patterns for matching.”
- “according to the diverse matching requirement, relevance matching is not position related since it could happen in any position in a long document.”
- “Most NLP tasks concern semantic matching, i.e., identifying the semantic meaning and infer”ring the semantic relations between two pieces of text, while the ad-hoc retrieval task is mainly about relevance matching, i.e., identifying whether a document is relevant to a given query.”
- “Since the ad-hoc retrieval task is fundamentally a ranking problem, we employ a pairwise ranking loss such as hinge loss to train our deep relevance matching model.”
The paper mentions how semantic matching falls down when compared against relevancy matching because:
- semantic matching relies on similarity matching signals (some words or phrases with the same meaning might be semantically distant), compositional meanings (matching sentences more than meaning) & a global matching requirement (comparing things in their entirety instead of looking at the best matching part of a longer document); whereas,
- relevance matching can put significant weight on exact matching signals (weighting an exact match higher than a near match), adjust weighting on query term importance (one word might or phrase in a search query might have a far higher discrimination value & might deserve far more weight than the next) & leverage diverse matching requirements (allowing relevancy matching to happen in any part of a longer document)
Here are a couple images from the above research paper
And then the second research paper is
Deep Relevancy Ranking Using Enhanced Dcoument-Query Interactions
“interaction-based models are less efficient, since one cannot index a document representation independently of the query. This is less important, though, when relevancy ranking methods rerank the top documents returned by a conventional IR engine, which is the scenario we consider here.”
That same sort of re-ranking concept is being better understood across the industry. There are ranking signals that earn some base level ranking, and then results get re-ranked based on other factors like how well a result matches the user intent.
Here are a couple images from the above research paper.
For those who hate the idea of reading research papers or patent applications, Martinibuster also wrote about the technology here. About the only part of his post I would debate is this one:
“Does this mean publishers should use more synonyms? Adding synonyms has always seemed to me to be a variation of keyword spamming. I have always considered it a naive suggestion. The purpose of Google understanding synonyms is simply to understand the context and meaning of a page. Communicating clearly and consistently is, in my opinion, more important than spamming a page with keywords and synonyms.”
I think one should always consider user experience over other factors, however a person could still use variations throughout the copy & pick up a bit more traffic without coming across as spammy. Danny Sullivan mentioned the super synonym concept was impacting 30% of search queries, so there are still a lot which may only be available to those who use a specific phrase on their page.
Martinibuster also wrote another blog post tying more research papers & patents to the above. You could probably spend a month reading all the related patents & research papers.
The above sort of language modeling & end user click feedback compliment links-based ranking signals in a way that makes it much harder to luck one’s way into any form of success by being a terrible speller or just bombing away at link manipulation without much concern toward any other aspect of the user experience or market you operate in.
Pre-penalized Shortcuts
Google was even issued a patent for predicting site quality based upon the N-grams used on the site & comparing those against the N-grams used on other established site where quality has already been scored via other methods: “The phrase model can be used to predict a site quality score for a new site; in particular, this can be done in the absence of other information. The goal is to predict a score that is comparable to the baseline site quality scores of the previously-scored sites.”
Have you considered using a PLR package to generate the shell of your site’s content? Good luck with that as some sites trying that shortcut might be pre-penalized from birth.
Navigating the Maze
When I started in SEO one of my friends had a dad who is vastly smarter than I am. He advised me that Google engineers were smarter, had more capital, had more exposure, had more data, etc etc etc … and thus SEO was ultimately going to be a malinvestment.
Back then he was at least partially wrong because influencing search was so easy.
But in the current market, 16 years later, we are near the infection point where he would finally be right.
At some point the shortcuts stop working & it makes sense to try a different approach.
The flip side of all the above changes is as the algorithms have become more complex they have went from being a headwind to people ignorant about SEO to being a tailwind to those who do not focus excessively on SEO in isolation.
If one is a dominant voice in a particular market, if they break industry news, if they have key exclusives, if they spot & name the industry trends, if their site becomes a must read & is what amounts to a habit … then they perhaps become viewed as an entity. Entity-related signals help them & those signals that are working against the people who might have lucked into a bit of success become a tailwind rather than a headwind.
If your work defines your industry, then any efforts to model entities, user behavior or the language of your industry are going to boost your work on a relative basis.
This requires sites to publish frequently enough to be a habit, or publish highly differentiated content which is strong enough that it is worth the wait.
Those which publish frequently without being particularly differentiated are almost guaranteed to eventually walk into a penalty of some sort. And each additional person who reads marginal, undifferentiated content (particularly if it has an ad-heavy layout) is one additional visitor that site is closer to eventually getting whacked. Success becomes self regulating. Any short-term success becomes self defeating if one has a highly opportunistic short-term focus.
Those who write content that only they could write are more likely to have sustained success.
A mistake people often make is to look at someone successful, then try to do what they are doing, assuming it will lead to similar success.This is backward.Find something you enjoy doing & are curious about.Get obsessed, & become one of the best at it.It will monetize itself.— Neil Strauss (@neilstrauss) March 30, 2019
Keyword Not Provided, But it Just Clicks
When SEO Was Easy
When I got started on the web over 15 years ago I created an overly broad & shallow website that had little chance of making money because it was utterly undifferentiated and crappy. In spite of my best (worst?) efforts while being a complete newbie, sometimes I would go to the mailbox and see a check for a couple hundred or a couple thousand dollars come in. My old roommate & I went to Coachella & when the trip was over I returned to a bunch of mail to catch up on & realized I had made way more while not working than what I spent on that trip.
What was the secret to a total newbie making decent income by accident?
Horrible spelling.
Back then search engines were not as sophisticated with their spelling correction features & I was one of 3 or 4 people in the search index that misspelled the name of an online casino the same way many searchers did.
The high minded excuse for why I did not scale that would be claiming I knew it was a temporary trick that was somehow beneath me. The more accurate reason would be thinking in part it was a lucky fluke rather than thinking in systems. If I were clever at the time I would have created the misspeller’s guide to online gambling, though I think I was just so excited to make anything from the web that I perhaps lacked the ambition & foresight to scale things back then.
In the decade that followed I had a number of other lucky breaks like that. One time one of the original internet bubble companies that managed to stay around put up a sitewide footer link targeting the concept that one of my sites made decent money from. This was just before the great recession, before Panda existed. The concept they targeted had 3 or 4 ways to describe it. 2 of them were very profitable & if they targeted either of the most profitable versions with that page the targeting would have sort of carried over to both. They would have outranked me if they targeted the correct version, but they didn’t so their mistargeting was a huge win for me.
Search Gets Complex
Search today is much more complex. In the years since those easy-n-cheesy wins, Google has rolled out many updates which aim to feature sought after destination sites while diminishing the sites which rely one “one simple trick” to rank.
Arguably the quality of the search results has improved significantly as search has become more powerful, more feature rich & has layered in more relevancy signals.
Many quality small web publishers have went away due to some combination of increased competition, algorithmic shifts & uncertainty, and reduced monetization as more ad spend was redirected toward Google & Facebook. But the impact as felt by any given publisher is not the impact as felt by the ecosystem as a whole. Many terrible websites have also went away, while some formerly obscure though higher-quality sites rose to prominence.
There was the Vince update in 2009, which boosted the rankings of many branded websites.
Then in 2011 there was Panda as an extension of Vince, which tanked the rankings of many sites that published hundreds of thousands or millions of thin content pages while boosting the rankings of trusted branded destinations.
Then there was Penguin, which was a penalty that hit many websites which had heavily manipulated or otherwise aggressive appearing link profiles. Google felt there was a lot of noise in the link graph, which was their justification for the Penguin.
There were updates which lowered the rankings of many exact match domains. And then increased ad load in the search results along with the other above ranking shifts further lowered the ability to rank keyword-driven domain names. If your domain is generically descriptive then there is a limit to how differentiated & memorable you can make it if you are targeting the core market the keywords are aligned with.
There is a reason eBay is more popular than auction.com, Google is more popular than search.com, Yahoo is more popular than portal.com & Amazon is more popular than a store.com or a shop.com. When that winner take most impact of many online markets is coupled with the move away from using classic relevancy signals the economics shift to where is makes a lot more sense to carry the heavy overhead of establishing a strong brand.
Branded and navigational search queries could be used in the relevancy algorithm stack to confirm the quality of a site & verify (or dispute) the veracity of other signals.
Historically relevant algo shortcuts become less appealing as they become less relevant to the current ecosystem & even less aligned with the future trends of the market. Add in negative incentives for pushing on a string (penalties on top of wasting the capital outlay) and a more holistic approach certainly makes sense.
Modeling Web Users & Modeling Language
PageRank was an attempt to model the random surfer.
When Google is pervasively monitoring most users across the web they can shift to directly measuring their behaviors instead of using indirect signals.
Years ago Bill Slawski wrote about the long click in which he opened by quoting Steven Levy’s In the Plex: How Google Thinks, Works, and Shapes our Lives
“On the most basic level, Google could see how satisfied users were. To paraphrase Tolstoy, happy users were all the same. The best sign of their happiness was the “Long Click” — This occurred when someone went to a search result, ideally the top one, and did not return. That meant Google has successfully fulfilled the query.”
Of course, there’s a patent for that. In Modifying search result ranking based on implicit user feedback they state:
user reactions to particular search results or search result lists may be gauged, so that results on which users often click will receive a higher ranking. The general assumption under such an approach is that searching users are often the best judges of relevance, so that if they select a particular search result, it is likely to be relevant, or at least more relevant than the presented alternatives.
If you are a known brand you are more likely to get clicked on than a random unknown entity in the same market.
And if you are something people are specifically seeking out, they are likely to stay on your website for an extended period of time.
One aspect of the subject matter described in this specification can be embodied in a computer-implemented method that includes determining a measure of relevance for a document result within a context of a search query for which the document result is returned, the determining being based on a first number in relation to a second number, the first number corresponding to longer views of the document result, and the second number corresponding to at least shorter views of the document result; and outputting the measure of relevance to a ranking engine for ranking of search results, including the document result, for a new search corresponding to the search query. The first number can include a number of the longer views of the document result, the second number can include a total number of views of the document result, and the determining can include dividing the number of longer views by the total number of views.
Attempts to manipulate such data may not work.
safeguards against spammers (users who generate fraudulent clicks in an attempt to boost certain search results) can be taken to help ensure that the user selection data is meaningful, even when very little data is available for a given (rare) query. These safeguards can include employing a user model that describes how a user should behave over time, and if a user doesn’t conform to this model, their click data can be disregarded. The safeguards can be designed to accomplish two main objectives: (1) ensure democracy in the votes (e.g., one single vote per cookie and/or IP for a given query-URL pair), and (2) entirely remove the information coming from cookies or IP addresses that do not look natural in their browsing behavior (e.g., abnormal distribution of click positions, click durations, clicks_per_minute/hour/day, etc.). Suspicious clicks can be removed, and the click signals for queries that appear to be spmed need not be used (e.g., queries for which the clicks feature a distribution of user agents, cookie ages, etc. that do not look normal).
And just like Google can make a matrix of documents & queries, they could also choose to put more weight on search accounts associated with topical expert users based on their historical click patterns.
Moreover, the weighting can be adjusted based on the determined type of the user both in terms of how click duration is translated into good clicks versus not-so-good clicks, and in terms of how much weight to give to the good clicks from a particular user group versus another user group. Some user’s implicit feedback may be more valuable than other users due to the details of a user’s review process. For example, a user that almost always clicks on the highest ranked result can have his good clicks assigned lower weights than a user who more often clicks results lower in the ranking first (since the second user is likely more discriminating in his assessment of what constitutes a good result). In addition, a user can be classified based on his or her query stream. Users that issue many queries on (or related to) a given topic T (e.g., queries related to law) can be presumed to have a high degree of expertise with respect to the given topic T, and their click data can be weighted accordingly for other queries by them on (or related to) the given topic T.
Google was using click data to drive their search rankings as far back as 2009. David Naylor was perhaps the first person who publicly spotted this. Google was ranking Australian websites for [tennis court hire] in the UK & Ireland, in part because that is where most of the click signal came from. That phrase was most widely searched for in Australia. In the years since Google has done a better job of geographically isolating clicks to prevent things like the problem David Naylor noticed, where almost all search results in one geographic region came from a different country.
Whenever SEOs mention using click data to search engineers, the search engineers quickly respond about how they might consider any signal but clicks would be a noisy signal. But if a signal has noise an engineer would work around the noise by finding ways to filter the noise out or combine multiple signals. To this day Google states they are still working to filter noise from the link graph: “We continued to protect the value of authoritative and relevant links as an important ranking signal for Search.”
The site with millions of inbound links, few intentional visits & those who do visit quickly click the back button (due to a heavy ad load, poor user experience, low quality content, shallow content, outdated content, or some other bait-n-switch approach)…that’s an outlier. Preventing those sorts of sites from ranking well would be another way of protecting the value of authoritative & relevant links.
Best Practices Vary Across Time & By Market + Category
Along the way, concurrent with the above sorts of updates, Google also improved their spelling auto-correct features, auto-completed search queries for many years through a featured called Google Instant (though they later undid forced query auto-completion while retaining automated search suggestions), and then they rolled out a few other algorithms that further allowed them to model language & user behavior.
Today it would be much harder to get paid above median wages explicitly for sucking at basic spelling or scaling some other individual shortcut to the moon, like pouring millions of low quality articles into a (formerly!) trusted domain.
Nearly a decade after Panda, eHow’s rankings still haven’t recovered.
Back when I got started with SEO the phrase Indian SEO company was associated with cut-rate work where people were buying exclusively based on price. Sort of like a “I got a $500 budget for link building, but can not under any circumstance invest more than $5 in any individual link.” Part of how my wife met me was she hired a hack SEO from San Diego who outsourced all the work to India and marked the price up about 100-fold while claiming it was all done in the United States. He created reciprocal links pages that got her site penalized & it didn’t rank until after she took her reciprocal links page down.
With that sort of behavior widespread (hack US firm teaching people working in an emerging market poor practices), it likely meant many SEO “best practices” which were learned in an emerging market (particularly where the web was also underdeveloped) would be more inclined to being spammy. Considering how far ahead many Western markets were on the early Internet & how India has so many languages & how most web usage in India is based on mobile devices where it is hard for users to create links, it only makes sense that Google would want to place more weight on end user data in such a market.
If you set your computer location to India Bing’s search box lists 9 different languages to choose from.
The above is not to state anything derogatory about any emerging market, but rather that various signals are stronger in some markets than others. And competition is stronger in some markets than others.
Search engines can only rank what exists.
“In a lot of Eastern European – but not just Eastern European markets – I think it is an issue for the majority of the [bream? muffled] countries, for the Arabic-speaking world, there just isn’t enough content as compared to the percentage of the Internet population that those regions represent. I don’t have up to date data, I know that a couple years ago we looked at Arabic for example and then the disparity was enormous. so if I’m not mistaken the Arabic speaking population of the world is maybe 5 to 6%, maybe more, correct me if I am wrong. But very definitely the amount of Arabic content in our index is several orders below that. So that means we do not have enough Arabic content to give to our Arabic users even if we wanted to. And you can exploit that amazingly easily and if you create a bit of content in Arabic, whatever it looks like we’re gonna go you know we don’t have anything else to serve this and it ends up being horrible. and people will say you know this works. I keyword stuffed the hell out of this page, bought some links, and there it is number one. There is nothing else to show, so yeah you’re number one. the moment somebody actually goes out and creates high quality content that’s there for the long haul, you’ll be out and that there will be one.” – Andrey Lipattsev – Search Quality Senior Strategist at Google Ireland, on Mar 23, 2016
Impacting the Economics of Publishing
Now search engines can certainly influence the economics of various types of media. At one point some otherwise credible media outlets were pitching the Demand Media IPO narrative that Demand Media was the publisher of the future & what other media outlets will look like. Years later, after heavily squeezing on the partner network & promoting programmatic advertising that reduces CPMs by the day Google is funding partnerships with multiple news publishers like McClatchy & Gatehouse to try to revive the news dead zones even Facebook is struggling with.
“Facebook Inc. has been looking to boost its local-news offerings since a 2017 survey showed most of its users were clamoring for more. It has run into a problem: There simply isn’t enough local news in vast swaths of the country. … more than one in five newspapers have closed in the past decade and a half, leaving half the counties in the nation with just one newspaper, and 200 counties with no newspaper at all.”
As mainstream newspapers continue laying off journalists, Facebook’s news efforts are likely to continue failing unless they include direct economic incentives, as Google’s programmatic ad push broke the banner ad:
“Thanks to the convoluted machinery of Internet advertising, the advertising world went from being about content publishers and advertising context—The Times unilaterally declaring, via its ‘rate card’, that ads in the Times Style section cost $30 per thousand impressions—to the users themselves and the data that targets them—Zappo’s saying it wants to show this specific shoe ad to this specific user (or type of user), regardless of publisher context. Flipping the script from a historically publisher-controlled mediascape to an advertiser (and advertiser intermediary) controlled one was really Google’s doing. Facebook merely rode the now-cresting wave, borrowing outside media’s content via its own users’ sharing, while undermining media’s ability to monetize via Facebook’s own user-data-centric advertising machinery. Conventional media lost both distribution and monetization at once, a mortal blow.”
Google is offering news publishers audience development & business development tools.
Heavy Investment in Emerging Markets Quickly Evolves the Markets
As the web grows rapidly in India, they’ll have a thousand flowers bloom. In 5 years the competition in India & other emerging markets will be much tougher as those markets continue to grow rapidly. Media is much cheaper to produce in India than it is in the United States. Labor costs are lower & they never had the economic albatross that is the ACA adversely impact their economy. At some point the level of investment & increased competition will mean early techniques stop having as much efficacy. Chinese companies are aggressively investing in India.
“If you break India into a pyramid, the top 100 million (urban) consumers who think and behave more like Americans are well-served,” says Amit Jangir, who leads India investments at 01VC, a Chinese venture capital firm based in Shanghai. The early stage venture firm has invested in micro-lending firms FlashCash and SmartCoin based in India. The new target is the next 200 million to 600 million consumers, who do not have a go-to entertainment, payment or ecommerce platform yet— and there is gonna be a unicorn in each of these verticals, says Jangir, adding that it will be not be as easy for a player to win this market considering the diversity and low ticket sizes.
RankBrain
RankBrain appears to be based on using user clickpaths on head keywords to help bleed rankings across into related searches which are searched less frequently. A Googler didn’t state this specifically, but it is how they would be able to use models of searcher behavior to refine search results for keywords which are rarely searched for.
In a recent interview in Scientific American a Google engineer stated: “By design, search engines have learned to associate short queries with the targets of those searches by tracking pages that are visited as a result of the query, making the results returned both faster and more accurate than they otherwise would have been.”
Now a person might go out and try to search for something a bunch of times or pay other people to search for a topic and click a specific listing, but some of the related Google patents on using click data (which keep getting updated) mentioned how they can discount or turn off the signal if there is an unnatural spike of traffic on a specific keyword, or if there is an unnatural spike of traffic heading to a particular website or web page.
And, since Google is tracking the behavior of end users on their own website, anomalous behavior is easier to track than it is tracking something across the broader web where signals are more indirect. Google can take advantage of their wide distribution of Chrome & Android where users are regularly logged into Google & pervasively tracked to place more weight on users where they had credit card data, a long account history with regular normal search behavior, heavy Gmail users, etc.
Plus there is a huge gap between the cost of traffic & the ability to monetize it. You might have to pay someone a dime or a quarter to search for something & there is no guarantee it will work on a sustainable basis even if you paid hundreds or thousands of people to do it. Any of those experimental searchers will have no lasting value unless they influence rank, but even if they do influence rankings it might only last temporarily. If you bought a bunch of traffic into something genuine Google searchers didn’t like then even if it started to rank better temporarily the rankings would quickly fall back if the real end user searchers disliked the site relative to other sites which already rank.
This is part of the reason why so many SEO blogs mention brand, brand, brand. If people are specifically looking for you in volume & Google can see that thousands or millions of people specifically want to access your site then that can impact how you rank elsewhere.
Even looking at something inside the search results for a while (dwell time) or quickly skipping over it to have a deeper scroll depth can be a ranking signal. Some Google patents mention how they can use mouse pointer location on desktop or scroll data from the viewport on mobile devices as a quality signal.
Neural Matching
Last year Danny Sullivan mentioned how Google rolled out neural matching to better understand the intent behind a search query.
This is a look back at a big change in search but which continues to be important: understanding synonyms. How people search is often different from information that people write solutions about. pic.twitter.com/sBcR4tR4eT— Danny Sullivan (@dannysullivan) September 24, 2018
Last few months, Google has been using neural matching, –AI method to better connect words to concepts. Super synonyms, in a way, and impacting 30% of queries. Don’t know what “soapopera effect” is to search for it? We can better figure it out. pic.twitter.com/Qrwp5hKFNz— Danny Sullivan (@dannysullivan) September 24, 2018
The above Tweets capture what the neural matching technology intends to do. Google also stated:
we’ve now reached the point where neural networks can help us take a major leap forward from understanding words to understanding concepts. Neural embeddings, an approach developed in the field of neural networks, allow us to transform words to fuzzier representations of the underlying concepts, and then match the concepts in the query with the concepts in the document. We call this technique neural matching.
To help people understand the difference between neural matching & RankBrain, Google told SEL: “RankBrain helps Google better relate pages to concepts. Neural matching helps Google better relate words to searches.”
There are a couple research papers on neural matching.
The first one was titled A Deep Relevance Matching Model for Ad-hoc Retrieval. It mentioned using Word2vec & here are a few quotes from the research paper
- “Successful relevance matching requires proper handling of the exact matching signals, query term importance, and diverse matching requirements.”
- “the interaction-focused model, which first builds local level interactions (i.e., local matching signals) between two pieces of text, and then uses deep neural networks to learn hierarchical interaction patterns for matching.”
- “according to the diverse matching requirement, relevance matching is not position related since it could happen in any position in a long document.”
- “Most NLP tasks concern semantic matching, i.e., identifying the semantic meaning and infer”ring the semantic relations between two pieces of text, while the ad-hoc retrieval task is mainly about relevance matching, i.e., identifying whether a document is relevant to a given query.”
- “Since the ad-hoc retrieval task is fundamentally a ranking problem, we employ a pairwise ranking loss such as hinge loss to train our deep relevance matching model.”
The paper mentions how semantic matching falls down when compared against relevancy matching because:
- semantic matching relies on similarity matching signals (some words or phrases with the same meaning might be semantically distant), compositional meanings (matching sentences more than meaning) & a global matching requirement (comparing things in their entirety instead of looking at the best matching part of a longer document); whereas,
- relevance matching can put significant weight on exact matching signals (weighting an exact match higher than a near match), adjust weighting on query term importance (one word might or phrase in a search query might have a far higher discrimination value & might deserve far more weight than the next) & leverage diverse matching requirements (allowing relevancy matching to happen in any part of a longer document)
Here are a couple images from the above research paper
And then the second research paper is
Deep Relevancy Ranking Using Enhanced Dcoument-Query Interactions
“interaction-based models are less efficient, since one cannot index a document representation independently of the query. This is less important, though, when relevancy ranking methods rerank the top documents returned by a conventional IR engine, which is the scenario we consider here.”
That same sort of re-ranking concept is being better understood across the industry. There are ranking signals that earn some base level ranking, and then results get re-ranked based on other factors like how well a result matches the user intent.
Here are a couple images from the above research paper.
For those who hate the idea of reading research papers or patent applications, Martinibuster also wrote about the technology here. About the only part of his post I would debate is this one:
“Does this mean publishers should use more synonyms? Adding synonyms has always seemed to me to be a variation of keyword spamming. I have always considered it a naive suggestion. The purpose of Google understanding synonyms is simply to understand the context and meaning of a page. Communicating clearly and consistently is, in my opinion, more important than spamming a page with keywords and synonyms.”
I think one should always consider user experience over other factors, however a person could still use variations throughout the copy & pick up a bit more traffic without coming across as spammy. Danny Sullivan mentioned the super synonym concept was impacting 30% of search queries, so there are still a lot which may only be available to those who use a specific phrase on their page.
Martinibuster also wrote another blog post tying more research papers & patents to the above. You could probably spend a month reading all the related patents & research papers.
The above sort of language modeling & end user click feedback compliment links-based ranking signals in a way that makes it much harder to luck one’s way into any form of success by being a terrible speller or just bombing away at link manipulation without much concern toward any other aspect of the user experience or market you operate in.
Pre-penalized Shortcuts
Google was even issued a patent for predicting site quality based upon the N-grams used on the site & comparing those against the N-grams used on other established site where quality has already been scored via other methods: “The phrase model can be used to predict a site quality score for a new site; in particular, this can be done in the absence of other information. The goal is to predict a score that is comparable to the baseline site quality scores of the previously-scored sites.”
Have you considered using a PLR package to generate the shell of your site’s content? Good luck with that as some sites trying that shortcut might be pre-penalized from birth.
Navigating the Maze
When I started in SEO one of my friends had a dad who is vastly smarter than I am. He advised me that Google engineers were smarter, had more capital, had more exposure, had more data, etc etc etc … and thus SEO was ultimately going to be a malinvestment.
Back then he was at least partially wrong because influencing search was so easy.
But in the current market, 16 years later, we are near the infection point where he would finally be right.
At some point the shortcuts stop working & it makes sense to try a different approach.
The flip side of all the above changes is as the algorithms have become more complex they have went from being a headwind to people ignorant about SEO to being a tailwind to those who do not focus excessively on SEO in isolation.
If one is a dominant voice in a particular market, if they break industry news, if they have key exclusives, if they spot & name the industry trends, if their site becomes a must read & is what amounts to a habit … then they perhaps become viewed as an entity. Entity-related signals help them & those signals that are working against the people who might have lucked into a bit of success become a tailwind rather than a headwind.
If your work defines your industry, then any efforts to model entities, user behavior or the language of your industry are going to boost your work on a relative basis.
This requires sites to publish frequently enough to be a habit, or publish highly differentiated content which is strong enough that it is worth the wait.
Those which publish frequently without being particularly differentiated are almost guaranteed to eventually walk into a penalty of some sort. And each additional person who reads marginal, undifferentiated content (particularly if it has an ad-heavy layout) is one additional visitor that site is closer to eventually getting whacked. Success becomes self regulating. Any short-term success becomes self defeating if one has a highly opportunistic short-term focus.
Those who write content that only they could write are more likely to have sustained success.
A mistake people often make is to look at someone successful, then try to do what they are doing, assuming it will lead to similar success.
This is backward.
Find something you enjoy doing & are curious about.
Get obsessed, & become one of the best at it.
It will monetize itself.— Neil Strauss (@neilstrauss) March 30, 2019
How The Internet Happened: From Netscape to the iPhone
Brian McCullough, who runs Internet History Podcast, also wrote a book named How The Internet Happened: From Netscape to the iPhone which did a fantastic job of capturing the ethos of the early web and telling the backstory of so many people & projects behind it’s evolution.
I think the quote which best the magic of the early web is
Jim Clark came from the world of machines and hardware, where development schedules were measured in years—even decades—and where “doing a startup” meant factories, manufacturing, inventory, shipping schedules and the like. But the Mosaic team had stumbled upon something simpler. They had discovered that you could dream up a product, code it, release it to the ether and change the world overnight. Thanks to the Internet, users could download your product, give you feedback on it, and you could release an update, all in the same day. In the web world, development schedules could be measured in weeks.
The part I bolded in the above quote from the book really captures the magic of the Internet & what pulled so many people toward the early web.
The current web – dominated by never-ending feeds & a variety of closed silos – is a big shift from the early days of web comics & other underground cool stuff people created & shared because they thought it was neat.
Many established players missed the actual direction of the web by trying to create something more akin to the web of today before the infrastructure could support it. Many of the “big things” driving web adoption relied heavily on chance luck – combined with a lot of hard work & a willingness to be responsive to feedback & data.
- Even when Marc Andreessen moved to the valley he thought he was late and he had “missed the whole thing,” but he saw the relentless growth of the web & decided making another web browser was the play that made sense at the time.
- Tim Berners-Lee was dismayed when Andreessen’s web browser enabled embedded image support in web documents.
- Early Amazon review features were originally for editorial content from Amazon itself. Bezos originally wanted to launch a broad-based Amazon like it is today, but realized it would be too capital intensive & focused on books off the start so he could sell a known commodity with a long tail. Amazon was initially built off leveraging 2 book distributors ( Ingram and Baker & Taylor) & R. R. Bowker’s Books In Print catalog. They also did clever hacks to meet minimum order requirements like ordering out of stock books as part of their order, so they could only order what customers had purchased.
- eBay began as an /aw/ subfolder on the eBay domain name which was hosted on a residential internet connection. Pierre Omidyar coded the auction service over labor day weekend in 1995. The domain had other sections focused on topics like ebola. It was switched from AuctionWeb to a stand alone site only after the ISP started charging for a business line. It had no formal Paypal integration or anything like that, rather when listings started to charge a commission, merchants would mail physical checks in to pay for the platform share of their sales. Beanie Babies also helped skyrocket platform usage.
- The reason AOL carpet bombed the United States with CDs – at their peak half of all CDs produced were AOL CDs – was their initial response rate was around 10%, a crazy number for untargeted direct mail.
- Priceline was lucky to have survived the bubble as their idea was to spread broadly across other categories beyond travel & they were losing about $30 per airline ticket sold.
- The broader web bubble left behind valuable infrastructure like unused fiber to fuel continued growth long after the bubble popped. The dot com bubble was possible in part because there was a secular bull market in bonds stemming back to the early 1980s & falling debt service payments increased financial leverage and company valuations.
- TED members hissed at Bill Gross when he unveiled GoTo.com, which ranked “search” results based on advertiser bids.
- Excite turned down offering the Google founders $1.6 million for the PageRank technology in part because Larry Page insisted to Excite CEO George Bell ‘If we come to work for Excite, you need to rip out all the Excite technology and replace it with [our] search.’ And, ultimately, that’s—in my recollection—where the deal fell apart.”
- Steve Jobs initially disliked the multi-touch technology that mobile would rely on, one of the early iPhone prototypes had the iPod clickwheel, and Apple was against offering an app store in any form. Steve Jobs so loathed his interactions with the record labels that he did not want to build a phone & first licensed iTunes to Motorola, where they made the horrible ROKR phone. He only ended up building a phone after Cingular / AT&T begged him to.
- Wikipedia was originally launched as a back up feeder site that was to feed into Nupedia.
- Even after Facebook had strong traction, Marc Zuckerberg kept working on other projects like a file sharing service. Facebook’s news feed was publicly hated based on the complaints, but it almost instantly led to a doubling of usage of the site so they never dumped it. After spreading from college to college Facebook struggled to expand ad other businesses & opening registration up to all was a hail mary move to see if it would rekindle growth instead of selling to Yahoo! for a billion dollars.
The book offers a lot of color to many important web related companies.
And many companies which were only briefly mentioned also ran into the same sort of lucky breaks the above companies did. Paypal was heavily reliant on eBay for initial distribution, but even that was something they initially tried to block until it became so obvious they stopped fighting it:
“At some point I sort of quit trying to stop the EBay users and mostly focused on figuring out how to not lose money,” Levchin recalls. … In the late 2000s, almost a decade after it first went public, PayPal was drifting toward obsolescence and consistently alienating the small businesses that paid it to handle their online checkout. Much of the company’s code was being written offshore to cut costs, and the best programmers and designers had fled the company. … PayPal’s conversion rate is lights-out: Eighty-nine percent of the time a customer gets to its checkout page, he makes the purchase. For other online credit and debit card transactions, that number sits at about 50 percent.
Here is a podcast interview of Brian McCullough by Chris Dixon.
How The Internet Happened: From Netscape to the iPhone is a great book well worth a read for anyone interested in the web.
Categories:
How The Internet Happened: From Netscape to the iPhone
Brian McCullough, who runs Internet History Podcast, also wrote a book named How The Internet Happened: From Netscape to the iPhone which did a fantastic job of capturing the ethos of the early web and telling the backstory of so many people & projects behind it’s evolution.
I think the quote which best the magic of the early web is
Jim Clark came from the world of machines and hardware, where development schedules were measured in years—even decades—and where “doing a startup” meant factories, manufacturing, inventory, shipping schedules and the like. But the Mosaic team had stumbled upon something simpler. They had discovered that you could dream up a product, code it, release it to the ether and change the world overnight. Thanks to the Internet, users could download your product, give you feedback on it, and you could release an update, all in the same day. In the web world, development schedules could be measured in weeks.
The part I bolded in the above quote from the book really captures the magic of the Internet & what pulled so many people toward the early web.
The current web – dominated by never-ending feeds & a variety of closed silos – is a big shift from the early days of web comics & other underground cool stuff people created & shared because they thought it was neat.
Many established players missed the actual direction of the web by trying to create something more akin to the web of today before the infrastructure could support it. Many of the “big things” driving web adoption relied heavily on chance luck – combined with a lot of hard work & a willingness to be responsive to feedback & data.
- Even when Marc Andreessen moved to the valley he thought he was late and he had “missed the whole thing,” but he saw the relentless growth of the web & decided making another web browser was the play that made sense at the time.
- Tim Berners-Lee was dismayed when Andreessen’s web browser enabled embedded image support in web documents.
- Early Amazon review features were originally for editorial content from Amazon itself. Bezos originally wanted to launch a broad-based Amazon like it is today, but realized it would be too capital intensive & focused on books off the start so he could sell a known commodity with a long tail. Amazon was initially built off leveraging 2 book distributors ( Ingram and Baker & Taylor) & R. R. Bowker’s Books In Print catalog. They also did clever hacks to meet minimum order requirements like ordering out of stock books as part of their order, so they could only order what customers had purchased.
Amazon employees:
2018 647,500
2017 566,000
2016 341,400
2015 230,800
2014 154,100
2013 117,300
2012 88,400
2011 56,200
2010 33,700
2009 24,300
2008 20,700
2007 17,000
2006 13,900
2005 12,000
2004 9000
2003 7800
2002 7500
2001 7800
2000 9000
1999 7600
1998 2100
1997 614
1996 158— Jon Erlichman (@JonErlichman) April 8, 2019 - eBay began as an /aw/ subfolder on the eBay domain name which was hosted on a residential internet connection. Pierre Omidyar coded the auction service over labor day weekend in 1995. The domain had other sections focused on topics like ebola. It was switched from AuctionWeb to a stand alone site only after the ISP started charging for a business line. It had no formal Paypal integration or anything like that, rather when listings started to charge a commission, merchants would mail physical checks in to pay for the platform share of their sales. Beanie Babies also helped skyrocket platform usage.
- The reason AOL carpet bombed the United States with CDs – at their peak half of all CDs produced were AOL CDs – was their initial response rate was around 10%, a crazy number for untargeted direct mail.
- Priceline was lucky to have survived the bubble as their idea was to spread broadly across other categories beyond travel & they were losing about $30 per airline ticket sold.
- The broader web bubble left behind valuable infrastructure like unused fiber to fuel continued growth long after the bubble popped. The dot com bubble was possible in part because there was a secular bull market in bonds stemming back to the early 1980s & falling debt service payments increased financial leverage and company valuations.
- TED members hissed at Bill Gross when he unveiled GoTo.com, which ranked “search” results based on advertiser bids.
- Excite turned down offering the Google founders $1.6 million for the PageRank technology in part because Larry Page insisted to Excite CEO George Bell ‘If we come to work for Excite, you need to rip out all the Excite technology and replace it with [our] search.’ And, ultimately, that’s—in my recollection—where the deal fell apart.”
- Steve Jobs initially disliked the multi-touch technology that mobile would rely on, one of the early iPhone prototypes had the iPod clickwheel, and Apple was against offering an app store in any form. Steve Jobs so loathed his interactions with the record labels that he did not want to build a phone & first licensed iTunes to Motorola, where they made the horrible ROKR phone. He only ended up building a phone after Cingular / AT&T begged him to.
- Wikipedia was originally launched as a back up feeder site that was to feed into Nupedia.
- Even after Facebook had strong traction, Marc Zuckerberg kept working on other projects like a file sharing service. Facebook’s news feed was publicly hated based on the complaints, but it almost instantly led to a doubling of usage of the site so they never dumped it. After spreading from college to college Facebook struggled to expand ad other businesses & opening registration up to all was a hail mary move to see if it would rekindle growth instead of selling to Yahoo! for a billion dollars.
The book offers a lot of color to many important web related companies.
And many companies which were only briefly mentioned also ran into the same sort of lucky breaks the above companies did. Paypal was heavily reliant on eBay for initial distribution, but even that was something they initially tried to block until it became so obvious they stopped fighting it:
“At some point I sort of quit trying to stop the EBay users and mostly focused on figuring out how to not lose money,” Levchin recalls. … In the late 2000s, almost a decade after it first went public, PayPal was drifting toward obsolescence and consistently alienating the small businesses that paid it to handle their online checkout. Much of the company’s code was being written offshore to cut costs, and the best programmers and designers had fled the company. … PayPal’s conversion rate is lights-out: Eighty-nine percent of the time a customer gets to its checkout page, he makes the purchase. For other online credit and debit card transactions, that number sits at about 50 percent.
Here is a podcast interview of Brian McCullough by Chris Dixon.
How The Internet Happened: From Netscape to the iPhone is a great book well worth a read for anyone interested in the web.
Categories:
Google Florida 2.0 Algorithm Update: Early Observations
It has been a while since Google has had a major algorithm update.
They recently announced one which began on the 12th of March.
This week, we released a broad core algorithm update, as we do several times per year. Our guidance about such updates remains as we’ve covered before. Please see these tweets for more about that:https://t.co/uPlEdSLHoXhttps://t.co/tmfQkhdjPL— Google SearchLiaison (@searchliaison) March 13, 2019
What changed?
It appears multiple things did.
When Google rolled out the original version of Penguin on April 24, 2012 (primarily focused on link spam) they also rolled out an update to an on-page spam classifier for misdirection.

And, over time, it was quite common for Panda & Penguin updates to be sandwiched together.
If you were Google & had the ability to look under the hood to see why things changed, you would probably want to obfuscate any major update by changing multiple things at once to make reverse engineering the change much harder.
Anyone who operates a single website (& lacks the ability to look under the hood) will have almost no clue about what changed or how to adjust with the algorithms.
In the most recent algorithm update some sites which were penalized in prior “quality” updates have recovered.

Though many of those recoveries are only partial.
Many SEO blogs will publish articles about how they cracked the code on the latest update by publishing charts like the first one without publishing that second chart showing the broader context.
The first penalty any website receives might be the first of a series of penalties.
If Google smokes your site & it does not cause a PR incident & nobody really cares that you are gone, then there is a very good chance things will go from bad to worse to worser to worsterest, technically speaking.
“In this age, in this country, public sentiment is everything. With it, nothing can fail; against it, nothing can succeed. Whoever molds public sentiment goes deeper than he who enacts statutes, or pronounces judicial decisions.” – Abraham Lincoln
Absent effort & investment to evolve FASTER than the broader web, sites which are hit with one penalty will often further accumulate other penalties. It is like compound interest working in reverse – a pile of algorithmic debt which must be dug out of before the bleeding stops.
Further, many recoveries may be nothing more than a fleeting invitation to false hope. To pour more resources into a site that is struggling in an apparent death loop.
The above site which had its first positive algorithmic response in a couple years achieved that in part by heavily de-monetizing. After the algorithm updates already demonetized the website over 90%, what harm was there in removing 90% of what remained to see how it would react? So now it will get more traffic (at least for a while) but then what exactly is the traffic worth to a site that has no revenue engine tied to it?
That is ultimately the hard part. Obtaining a stable stream of traffic while monetizing at a decent yield, without the monetizing efforts leading to the traffic disappearing.
A buddy who owns the above site was working on link cleanup & content improvement on & off for about a half year with no results. Each month was a little worse than the prior month. It was only after I told him to remove the aggressive ads a few months back that he likely had any chance of seeing any sort of traffic recovery. Now he at least has a pulse of traffic & can look into lighter touch means of monetization.
If a site is consistently penalized then the problem might not be an algorithmic false positive, but rather the business model of the site.
The more something looks like eHow the more fickle Google’s algorithmic with receive it.
Google does not like websites that sit at the end of the value chain & extract profits without having to bear far greater risk & expense earlier into the cycle.
Thin rewrites, largely speaking, don’t add value to the ecosystem. Doorway pages don’t either. And something that was propped up by a bunch of keyword-rich low-quality links is (in most cases) probably genuinely lacking in some other aspect.
Generally speaking, Google would like themselves to be the entity at the end of the value chain extracting excess profits from markets.
This is the purpose of the knowledge graph & featured snippets. To allow the results to answer the most basic queries without third party publishers getting anything. The knowledge graph serve as a floating vertical that eat an increasing share of the value chain & force publishers to move higher up the funnel & publish more differentiated content.
As Google adds features to the search results (flight price trends, a hotel booking service on the day AirBNB announced they acquired HotelTonight, ecommerce product purchase on Google, shoppable image ads just ahead of the Pinterest IPO, etc.) it forces other players in the value chain to consolidate (Expedia owns Orbitz, Travelocity, Hotwire & a bunch of other sites) or add greater value to remain a differentiated & sought after destination (travel review site TripAdvisor was crushed by the shift to mobile & the inability to monetize mobile traffic, so they eventually had to shift away from being exclusively a reviews site to offer event & hotel booking features to remain relevant).
It is never easy changing a successful & profitable business model, but it is even harder to intentionally reduce revenues further or spend aggressively to improve quality AFTER income has fallen 50% or more.
Some people do the opposite & make up for a revenue shortfall by publishing more lower end content at an ever faster rate and/or increasing ad load. Either of which typically makes their user engagement metrics worse while making their site less differentiated & more likely to receive additional bonus penalties to drive traffic even lower.
In some ways I think the ability for a site to survive & remain though a penalty is itself a quality signal for Google.
Some sites which are overly reliant on search & have no external sources of traffic are ultimately sites which tried to behave too similarly to the monopoly that ultimately displaced them. And over time the tech monopolies are growing more powerful as the ecosystem around them burns down:
If you had to choose a date for when the internet died, it would be in the year 2014. Before then, traffic to websites came from many sources, and the web was a lively ecosystem. But beginning in 2014, more than half of all traffic began coming from just two sources: Facebook and Google. Today, over 70 percent of traffic is dominated by those two platforms.
Businesses which have sustainable profit margins & slack (in terms of management time & resources to deploy) can better cope with algorithmic changes & change with the market.
Over the past half decade or so there have been multiple changes that drastically shifted the online publishing landscape:
- the shift to mobile, which both offers publishers lower ad yields while making the central ad networks more ad heavy in a way that reduces traffic to third party sites
- the rise of the knowledge graph & featured snippets which often mean publishers remain uncompensated for their work
- higher ad loads which also lower organic reach (on both search & social channels)
- the rise of programmatic advertising, which further gutted display ad CPMs
- the rise of ad blockers
- increasing algorithmic uncertainty & a higher barrier to entry
Each one of the above could take a double digit percent out of a site’s revenues, particularly if a site was reliant on display ads. Add them together and a website which was not even algorithmically penalized could still see a 60%+ decline in revenues. Mix in a penalty and that decline can chop a zero or two off the total revenues.
Businesses with lower margins can try to offset declines with increased ad spending, but that only works if you are not in a market with 2 & 20 VC fueled competition:
Startups spend almost 40 cents of every VC dollar on Google, Facebook, and Amazon. We don’t necessarily know which channels they will choose or the particularities of how they will spend money on user acquisition, but we do know more or less what’s going to happen. Advertising spend in tech has become an arms race: fresh tactics go stale in months, and customer acquisition costs keep rising. In a world where only one company thinks this way, or where one business is executing at a level above everyone else – like Facebook in its time – this tactic is extremely effective. However, when everyone is acting this way, the industry collectively becomes an accelerating treadmill. Ad impressions and click-throughs get bid up to outrageous prices by startups flush with venture money, and prospective users demand more and more subsidized products to gain their initial attention. The dynamics we’ve entered is, in many ways, creating a dangerous, high stakes Ponzi scheme.
And sometimes the platform claws back a second or third bite of the apple. Amazon.com charges merchants for fulfillment, warehousing, transaction based fees, etc. And they’ve pushed hard into launching hundreds of private label brands which pollute the interface & force brands to buy ads even on their own branded keyword terms.
They’ve recently jumped the shark by adding a bonus feature where even when a brand paid Amazon to send traffic to their listing, Amazon would insert a spam popover offering a cheaper private label branded product:
Amazon.com tested a pop-up feature on its app that in some instances pitched its private-label goods on rivals’ product pages, an experiment that shows the e-commerce giant’s aggressiveness in hawking lower-priced products including its own house brands. The recent experiment, conducted in Amazon’s mobile app, went a step further than the display ads that commonly appear within search results and product pages. This test pushed pop-up windows that took over much of a product page, forcing customers to either click through to the lower-cost Amazon products or dismiss them before continuing to shop. … When a customer using Amazon’s mobile app searched for “AAA batteries,” for example, the first link was a sponsored listing from Energizer Holdings Inc. After clicking on the listing, a pop-up window appeared, offering less expensive AmazonBasics AAA batteries.”
Buying those Amazon ads was quite literally subsidizing a direct competitor pushing you into irrelevance.
And while Amazon is destroying brand equity, AWS is doing investor relations matchmaking for startups. Anything to keep the current bubble going ahead of the Uber IPO that will likely mark the top in the stock market.
Some thoughts on Silicon Valley’s endgame. We have long said the biggest risk to the bull market is an Uber IPO. That is now upon us.— Jawad Mian (@jsmian) March 16, 2019
As the market caps of big tech companies climb they need to be more predatious to grow into the valuations & retain employees with stock options at an ever-increasing strike price.
They’ve created bubbles in their own backyards where each raise requires another. Teachers either drive hours to work or live in houses subsidized by loans from the tech monopolies that get a piece of the upside (provided they can keep their own bubbles inflated).
“It is an uncommon arrangement — employer as landlord — that is starting to catch on elsewhere as school employees say they cannot afford to live comfortably in regions awash in tech dollars. … Holly Gonzalez, 34, a kindergarten teacher in East San Jose, and her husband, Daniel, a school district I.T. specialist, were able to buy a three-bedroom apartment for $610,000 this summer with help from their parents and from Landed. When they sell the home, they will owe Landed 25 percent of any gain in its value. The company is financed partly by the Chan Zuckerberg Initiative, Mark Zuckerberg’s charitable arm.”
The above sort of dynamics have some claiming peak California:
The cycle further benefits from the Alchian-Allen effect: agglomerating industries have higher productivity, which raises the cost of living and prices out other industries, raising concentration over time. … Since startups raise the variance within whatever industry they’re started in, the natural constituency for them is someone who doesn’t have capital deployed in the industry. If you’re an asset owner, you want low volatility. … Historically, startups have created a constant supply of volatility for tech companies; the next generation is always cannibalizing the previous one. So chip companies in the 1970s created the PC companies of the 80s, but PC companies sourced cheaper and cheaper chips, commoditizing the product until Intel managed to fight back. Meanwhile, the OS turned PCs into a commodity, then search engines and social media turned the OS into a commodity, and presumably this process will continue indefinitely. … As long as higher rents raise the cost of starting a pre-revenue company, fewer people will join them, so more people will join established companies, where they’ll earn market salaries and continue to push up rents. And one of the things they’ll do there is optimize ad loads, which places another tax on startups. More dangerously, this is an incremental tax on growth rather than a fixed tax on headcount, so it puts pressure on out-year valuations, not just upfront cash flow.
If you live hundreds of miles away the tech companies may have no impact on your rental or purchase price, but you can’t really control the algorithms or the ecosystem.
All you can really control is your mindset & ensuring you have optionality baked into your business model.
- If you are debt-levered you have little to no optionality. Savings give you optionality. Savings allow you to run at a loss for a period of time while also investing in improving your site and perhaps having a few other sites in other markets.
- If you operate a single website that is heavily reliant on a third party for distribution then you have little to no optionality. If you have multiple projects that enables you to shift your attention toward working on whatever is going up and to the right while letting anything that is failing pass time without becoming overly reliant on something you can’t change. This is why it often makes sense for a brand merchant to operate their own ecommerce website even if 90% of their sales come from Amazon. It gives you optionality should the tech monopoly become abusive or otherwise harm you (even if the intent was rather than outright misanthropic).
As the update ensues Google will collect more data with how users interact with the result set & determine how to weight different signals, along with re-scoring sites that recovered based on the new engagement data.
Recently a Bing engineer named Frédéric Dubut described how they score relevancy signals used in updates
As early as 2005, we used neural networks to power our search engine and you can still find rare pictures of Satya Nadella, VP of Search and Advertising at the time, showcasing our web ranking advances. … The “training” process of a machine learning model is generally iterative (and all automated). At each step, the model is tweaking the weight of each feature in the direction where it expects to decrease the error the most. After each step, the algorithm remeasures the rating of all the SERPs (based on the known URL/query pair ratings) to evaluate how it’s doing. Rinse and repeat.
That same process is ongoing with Google now & in the coming weeks there’ll be the next phase of the current update.
So far it looks like some quality-based re-scoring was done & some sites which were overly reliant on anchor text got clipped. On the back end of the update there’ll be another quality-based re-scoring, but the sites that were hit for excessive manipulation of anchor text via link building efforts will likely remain penalized for a good chunk of time.
Categories:
Google Florida 2.0 Algorithm Update: Early Observations
It has been a while since Google has had a major algorithm update.
They recently announced one which began on the 12th of March.
This week, we released a broad core algorithm update, as we do several times per year. Our guidance about such updates remains as we’ve covered before. Please see these tweets for more about that:https://t.co/uPlEdSLHoXhttps://t.co/tmfQkhdjPL— Google SearchLiaison (@searchliaison) March 13, 2019
What changed?
It appears multiple things did.
When Google rolled out the original version of Penguin on April 24, 2012 (primarily focused on link spam) they also rolled out an update to an on-page spam classifier for misdirection.
And, over time, it was quite common for Panda & Penguin updates to be sandwiched together.
If you were Google & had the ability to look under the hood to see why things changed, you would probably want to obfuscate any major update by changing multiple things at once to make reverse engineering the change much harder.
Anyone who operates a single website (& lacks the ability to look under the hood) will have almost no clue about what changed or how to adjust with the algorithms.
In the most recent algorithm update some sites which were penalized in prior “quality” updates have recovered.
Though many of those recoveries are only partial.
Many SEO blogs will publish articles about how they cracked the code on the latest update by publishing charts like the first one without publishing that second chart showing the broader context.
The first penalty any website receives might be the first of a series of penalties.
If Google smokes your site & it does not cause a PR incident & nobody really cares that you are gone, then there is a very good chance things will go from bad to worse to worser to worsterest, technically speaking.
“In this age, in this country, public sentiment is everything. With it, nothing can fail; against it, nothing can succeed. Whoever molds public sentiment goes deeper than he who enacts statutes, or pronounces judicial decisions.” – Abraham Lincoln
Absent effort & investment to evolve FASTER than the broader web, sites which are hit with one penalty will often further accumulate other penalties. It is like compound interest working in reverse – a pile of algorithmic debt which must be dug out of before the bleeding stops.
Further, many recoveries may be nothing more than a fleeting invitation to false hope. To pour more resources into a site that is struggling in an apparent death loop.
The above site which had its first positive algorithmic response in a couple years achieved that in part by heavily de-monetizing. After the algorithm updates already demonetized the website over 90%, what harm was there in removing 90% of what remained to see how it would react? So now it will get more traffic (at least for a while) but then what exactly is the traffic worth to a site that has no revenue engine tied to it?
That is ultimately the hard part. Obtaining a stable stream of traffic while monetizing at a decent yield, without the monetizing efforts leading to the traffic disappearing.
A buddy who owns the above site was working on link cleanup & content improvement on & off for about a half year with no results. Each month was a little worse than the prior month. It was only after I told him to remove the aggressive ads a few months back that he likely had any chance of seeing any sort of traffic recovery. Now he at least has a pulse of traffic & can look into lighter touch means of monetization.
If a site is consistently penalized then the problem might not be an algorithmic false positive, but rather the business model of the site.
The more something looks like eHow the more fickle Google’s algorithmic with receive it.
Google does not like websites that sit at the end of the value chain & extract profits without having to bear far greater risk & expense earlier into the cycle.
Thin rewrites, largely speaking, don’t add value to the ecosystem. Doorway pages don’t either. And something that was propped up by a bunch of keyword-rich low-quality links is (in most cases) probably genuinely lacking in some other aspect.
Generally speaking, Google would like themselves to be the entity at the end of the value chain extracting excess profits from markets.
RIP Quora!!! Q&A On Google – Showing Questions That Need Answers In Search https://t.co/mejXUDwGhT pic.twitter.com/8Cv1iKjDh2— John Shehata (@JShehata) March 18, 2019
This is the purpose of the knowledge graph & featured snippets. To allow the results to answer the most basic queries without third party publishers getting anything. The knowledge graph serve as a floating vertical that eat an increasing share of the value chain & force publishers to move higher up the funnel & publish more differentiated content.
As Google adds features to the search results (flight price trends, a hotel booking service on the day AirBNB announced they acquired HotelTonight, ecommerce product purchase on Google, shoppable image ads just ahead of the Pinterest IPO, etc.) it forces other players in the value chain to consolidate (Expedia owns Orbitz, Travelocity, Hotwire & a bunch of other sites) or add greater value to remain a differentiated & sought after destination (travel review site TripAdvisor was crushed by the shift to mobile & the inability to monetize mobile traffic, so they eventually had to shift away from being exclusively a reviews site to offer event & hotel booking features to remain relevant).
It is never easy changing a successful & profitable business model, but it is even harder to intentionally reduce revenues further or spend aggressively to improve quality AFTER income has fallen 50% or more.
Some people do the opposite & make up for a revenue shortfall by publishing more lower end content at an ever faster rate and/or increasing ad load. Either of which typically makes their user engagement metrics worse while making their site less differentiated & more likely to receive additional bonus penalties to drive traffic even lower.
In some ways I think the ability for a site to survive & remain though a penalty is itself a quality signal for Google.
Some sites which are overly reliant on search & have no external sources of traffic are ultimately sites which tried to behave too similarly to the monopoly that ultimately displaced them. And over time the tech monopolies are growing more powerful as the ecosystem around them burns down:
If you had to choose a date for when the internet died, it would be in the year 2014. Before then, traffic to websites came from many sources, and the web was a lively ecosystem. But beginning in 2014, more than half of all traffic began coming from just two sources: Facebook and Google. Today, over 70 percent of traffic is dominated by those two platforms.
Businesses which have sustainable profit margins & slack (in terms of management time & resources to deploy) can better cope with algorithmic changes & change with the market.
Over the past half decade or so there have been multiple changes that drastically shifted the online publishing landscape:
- the shift to mobile, which both offers publishers lower ad yields while making the central ad networks more ad heavy in a way that reduces traffic to third party sites
- the rise of the knowledge graph & featured snippets which often mean publishers remain uncompensated for their work
- higher ad loads which also lower organic reach (on both search & social channels)
- the rise of programmatic advertising, which further gutted display ad CPMs
- the rise of ad blockers
- increasing algorithmic uncertainty & a higher barrier to entry
Each one of the above could take a double digit percent out of a site’s revenues, particularly if a site was reliant on display ads. Add them together and a website which was not even algorithmically penalized could still see a 60%+ decline in revenues. Mix in a penalty and that decline can chop a zero or two off the total revenues.
Businesses with lower margins can try to offset declines with increased ad spending, but that only works if you are not in a market with 2 & 20 VC fueled competition:
Startups spend almost 40 cents of every VC dollar on Google, Facebook, and Amazon. We don’t necessarily know which channels they will choose or the particularities of how they will spend money on user acquisition, but we do know more or less what’s going to happen. Advertising spend in tech has become an arms race: fresh tactics go stale in months, and customer acquisition costs keep rising. In a world where only one company thinks this way, or where one business is executing at a level above everyone else – like Facebook in its time – this tactic is extremely effective. However, when everyone is acting this way, the industry collectively becomes an accelerating treadmill. Ad impressions and click-throughs get bid up to outrageous prices by startups flush with venture money, and prospective users demand more and more subsidized products to gain their initial attention. The dynamics we’ve entered is, in many ways, creating a dangerous, high stakes Ponzi scheme.
And sometimes the platform claws back a second or third bite of the apple. Amazon.com charges merchants for fulfillment, warehousing, transaction based fees, etc. And they’ve pushed hard into launching hundreds of private label brands which pollute the interface & force brands to buy ads even on their own branded keyword terms.
They’ve recently jumped the shark by adding a bonus feature where even when a brand paid Amazon to send traffic to their listing, Amazon would insert a spam popover offering a cheaper private label branded product:
Amazon.com tested a pop-up feature on its app that in some instances pitched its private-label goods on rivals’ product pages, an experiment that shows the e-commerce giant’s aggressiveness in hawking lower-priced products including its own house brands. The recent experiment, conducted in Amazon’s mobile app, went a step further than the display ads that commonly appear within search results and product pages. This test pushed pop-up windows that took over much of a product page, forcing customers to either click through to the lower-cost Amazon products or dismiss them before continuing to shop. … When a customer using Amazon’s mobile app searched for “AAA batteries,” for example, the first link was a sponsored listing from Energizer Holdings Inc. After clicking on the listing, a pop-up window appeared, offering less expensive AmazonBasics AAA batteries.”
Buying those Amazon ads was quite literally subsidizing a direct competitor pushing you into irrelevance.
And while Amazon is destroying brand equity, AWS is doing investor relations matchmaking for startups. Anything to keep the current bubble going ahead of the Uber IPO that will likely mark the top in the stock market.
Some thoughts on Silicon Valley’s endgame. We have long said the biggest risk to the bull market is an Uber IPO. That is now upon us.— Jawad Mian (@jsmian) March 16, 2019
As the market caps of big tech companies climb they need to be more predatious to grow into the valuations & retain employees with stock options at an ever-increasing strike price.
They’ve created bubbles in their own backyards where each raise requires another. Teachers either drive hours to work or live in houses subsidized by loans from the tech monopolies that get a piece of the upside (provided they can keep their own bubbles inflated).
“It is an uncommon arrangement — employer as landlord — that is starting to catch on elsewhere as school employees say they cannot afford to live comfortably in regions awash in tech dollars. … Holly Gonzalez, 34, a kindergarten teacher in East San Jose, and her husband, Daniel, a school district I.T. specialist, were able to buy a three-bedroom apartment for $610,000 this summer with help from their parents and from Landed. When they sell the home, they will owe Landed 25 percent of any gain in its value. The company is financed partly by the Chan Zuckerberg Initiative, Mark Zuckerberg’s charitable arm.”
The above sort of dynamics have some claiming peak California:
The cycle further benefits from the Alchian-Allen effect: agglomerating industries have higher productivity, which raises the cost of living and prices out other industries, raising concentration over time. … Since startups raise the variance within whatever industry they’re started in, the natural constituency for them is someone who doesn’t have capital deployed in the industry. If you’re an asset owner, you want low volatility. … Historically, startups have created a constant supply of volatility for tech companies; the next generation is always cannibalizing the previous one. So chip companies in the 1970s created the PC companies of the 80s, but PC companies sourced cheaper and cheaper chips, commoditizing the product until Intel managed to fight back. Meanwhile, the OS turned PCs into a commodity, then search engines and social media turned the OS into a commodity, and presumably this process will continue indefinitely. … As long as higher rents raise the cost of starting a pre-revenue company, fewer people will join them, so more people will join established companies, where they’ll earn market salaries and continue to push up rents. And one of the things they’ll do there is optimize ad loads, which places another tax on startups. More dangerously, this is an incremental tax on growth rather than a fixed tax on headcount, so it puts pressure on out-year valuations, not just upfront cash flow.
If you live hundreds of miles away the tech companies may have no impact on your rental or purchase price, but you can’t really control the algorithms or the ecosystem.
All you can really control is your mindset & ensuring you have optionality baked into your business model.
- If you are debt-levered you have little to no optionality. Savings give you optionality. Savings allow you to run at a loss for a period of time while also investing in improving your site and perhaps having a few other sites in other markets.
- If you operate a single website that is heavily reliant on a third party for distribution then you have little to no optionality. If you have multiple projects that enables you to shift your attention toward working on whatever is going up and to the right while letting anything that is failing pass time without becoming overly reliant on something you can’t change. This is why it often makes sense for a brand merchant to operate their own ecommerce website even if 90% of their sales come from Amazon. It gives you optionality should the tech monopoly become abusive or otherwise harm you (even if the intent was benign rather than outright misanthropic).
As the update ensues Google will collect more data with how users interact with the result set & determine how to weight different signals, along with re-scoring sites that recovered based on the new engagement data.
Recently a Bing engineer named Frédéric Dubut described how they score relevancy signals used in updates
As early as 2005, we used neural networks to power our search engine and you can still find rare pictures of Satya Nadella, VP of Search and Advertising at the time, showcasing our web ranking advances. … The “training” process of a machine learning model is generally iterative (and all automated). At each step, the model is tweaking the weight of each feature in the direction where it expects to decrease the error the most. After each step, the algorithm remeasures the rating of all the SERPs (based on the known URL/query pair ratings) to evaluate how it’s doing. Rinse and repeat.
That same process is ongoing with Google now & in the coming weeks there’ll be the next phase of the current update.
So far it looks like some quality-based re-scoring was done & some sites which were overly reliant on anchor text got clipped. On the back end of the update there’ll be another quality-based re-scoring, but the sites that were hit for excessive manipulation of anchor text via link building efforts will likely remain penalized for a good chunk of time.
Update: It appears a major reverberation of this update occurred on April 7th. From early analysis, Google is mixing in showing results for related midtail concepts on a core industry search term & they are also in some cases pushing more aggressively on doing internal site-level searches to rank a more relevant internal page for a query where they homepage might have ranked in the past.
Categories:
A Darker Shade of Gray
Google’s original breakthrough in search was placing weight on links & using them to approximate the behavior of web users.
The abstract of
The PageRank Citation Ranking: Bringing Order to the Web reads
The importance of a Web page is an inherently subjective matter, which depends on the readers interests, knowledge and attitudes. But there is still much that can be said objectively about the relative importance of Web pages. This paper describes PageRank, a method for rating Web pages objectively and mechanically, effectively measuring the human interest and attention devoted to them. We compare PageRank to an idealized random Web surfer. We show how to efficiently compute PageRank for large numbers of pages. And, we show how to apply PageRank to search and to user navigation.
Back when I got started in the search game if you wanted to rank better you simply threw more links at whatever you wanted to rank & used the anchor text you wanted to rank for. A friend (who will remain nameless here!) used to rank websites for one-word search queries in major industries without even looking at them. :D
Suffice it to say, as more people read about PageRank & learned the influence of anchor text, Google had to advance their algorithms in order to counteract efforts to manipulate them.
Over the years as Google has grown more dominant they have been able to create many other signals. Some signals might be easy to understand & explain, while signals that approximate abstract concepts (like brand) might be a bit more convoluted to understand or attempt to explain.
Google owns the most widely used web browser (Chrome) & the most popular mobile operating system (Android). Owning those gives Google unique insights to where they do not need to place as much weight on a links-driven approximation of a random web user. They can see what users actually do & model their algorithms based on that.
Google considers the user experience an important part of their ranking algorithms. That was a big part of the heavy push for making mobile responsive web designs.
On your money or your life topics Google considers the experience so important they have an acronym covering the categories (YMYL) and place greater emphasis on the reliability of the user experience.
Nobody wants to die from a junk piece of medical advice or a matching service which invites predators into their homes.
The Wall Street Journal publishes original reporting which is so influential they almost act as the missing regulator in many instances.
Last Friday the WSJ covered the business practices of Care.com, a company which counts Alphabet’s Capital G as its biggest shareholder.
Behind Care.com’s appeal is a pledge to “help families make informed hiring decisions” about caregivers, as it has said on its website. Still, Care.com largely leaves it to families to figure out whether the caregivers it lists are trustworthy. … In about 9 instances over the past six years, caregivers in the U.S. who had police records were listed on Care.com and later were accused of committing crimes while caring for customers’ children or elderly relatives … Alleged crimes included theft, child abuse, sexual assault and murder. The Journal also found hundreds of instances in which day-care centers listed on Care.com as state-licensed didn’t appear to be. … Care.com states on listings that it doesn’t verify licenses, in small gray type at the bottom … A spokeswoman said that Care.com, like other companies, adds listings found in “publicly available data,” and that most day-care centers on its site didn’t pay for their listings. She said in the next few years Care.com will begin a program in which it vets day-care centers.
By Monday Care.com’s stock was sliding, which led to prompt corrective actions:
Previously the company warned users in small grey type at the bottom of a day-care center listing that it didn’t verify credentials or licensing information. Care.com said Monday it “has made more prominent” that notice.
To this day, Care.com’s homepage states…
“Care.com does not employ any care provider or care seeker nor is it responsible for the conduct of any care provider or care seeker. … The information contained in member profiles, job posts and applications are supplied by care providers and care seekers themselves and is not information generated or verified by Care.com.”
…in an ever so slightly darker shade of gray.
So far it appears to have worked for them.
What’s your favorite color?
Categories:
A Darker Shade of Gray
Google’s original breakthrough in search was placing weight on links & using them to approximate the behavior of web users.
The abstract of
The PageRank Citation Ranking: Bringing Order to the Web reads
The importance of a Web page is an inherently subjective matter, which depends on the readers interests, knowledge and attitudes. But there is still much that can be said objectively about the relative importance of Web pages. This paper describes PageRank, a method for rating Web pages objectively and mechanically, effectively measuring the human interest and attention devoted to them. We compare PageRank to an idealized random Web surfer. We show how to efficiently compute PageRank for large numbers of pages. And, we show how to apply PageRank to search and to user navigation.
Back when I got started in the search game if you wanted to rank better you simply threw more links at whatever you wanted to rank & used the anchor text you wanted to rank for. A friend (who will remain nameless here!) used to rank websites for one-word search queries in major industries without even looking at them. :D
Suffice it to say, as more people read about PageRank & learned the influence of anchor text, Google had to advance their algorithms in order to counteract efforts to manipulate them.
Over the years as Google has grown more dominant they have been able to create many other signals. Some signals might be easy to understand & explain, while signals that approximate abstract concepts (like brand) might be a bit more convoluted to understand or attempt to explain.
Google owns the most widely used web browser (Chrome) & the most popular mobile operating system (Android). Owning those gives Google unique insights to where they do not need to place as much weight on a links-driven approximation of a random web user. They can see what users actually do & model their algorithms based on that.
Google considers the user experience an important part of their ranking algorithms. That was a big part of the heavy push for making mobile responsive web designs.
On your money or your life topics Google considers the experience so important they have an acronym covering the categories (YMYL) and place greater emphasis on the reliability of the user experience.
Nobody wants to die from a junk piece of medical advice or a matching service which invites predators into their homes.
The Wall Street Journal publishes original reporting which is so influential they almost act as the missing regulator in many instances.
Last Friday the WSJ covered the business practices of Care.com, a company which counts Alphabet’s Capital G as its biggest shareholder.
Behind Care.com’s appeal is a pledge to “help families make informed hiring decisions” about caregivers, as it has said on its website. Still, Care.com largely leaves it to families to figure out whether the caregivers it lists are trustworthy. … In about 9 instances over the past six years, caregivers in the U.S. who had police records were listed on Care.com and later were accused of committing crimes while caring for customers’ children or elderly relatives … Alleged crimes included theft, child abuse, sexual assault and murder. The Journal also found hundreds of instances in which day-care centers listed on Care.com as state-licensed didn’t appear to be. … Care.com states on listings that it doesn’t verify licenses, in small gray type at the bottom … A spokeswoman said that Care.com, like other companies, adds listings found in “publicly available data,” and that most day-care centers on its site didn’t pay for their listings. She said in the next few years Care.com will begin a program in which it vets day-care centers.
By Monday Care.com’s stock was sliding, which led to prompt corrective actions:
Previously the company warned users in small grey type at the bottom of a day-care center listing that it didn’t verify credentials or licensing information. Care.com said Monday it “has made more prominent” that notice.
To this day, Care.com’s homepage states…
“Care.com does not employ any care provider or care seeker nor is it responsible for the conduct of any care provider or care seeker. … The information contained in member profiles, job posts and applications are supplied by care providers and care seekers themselves and is not information generated or verified by Care.com.”
…in an ever so slightly darker shade of gray.
So far it appears to have worked for them.
What’s your favorite color?
Categories:
Left is Right & Up is Down
Probably the single best video to watch to understand the power of Google & Facebook (or even most of the major problems across society) is this following video about pleasure versus happiness.
In constantly seeking pleasure we forego happiness.
The “feed” based central aggregation networks are just like slot machines in your pocket: variable reward circuitry which self-optimizes around exploiting your flaws to eat as much attention as possible.
The above is not an accident. It is, rather, as intended:
“That means that we needed to sort of give you a little dopamine hit every once in a while because someone liked or commented on a photo or a post or whatever … It’s a social validation feedback loop … You’re exploiting a vulnerability in human psychology … [The inventors] understood this, consciously, and we did it anyway.”
- Happy? Good! Share posed photos to make your friends feel their lives are worse than your life is.
- Outraged? Good! Click an ad.
- Hopeless? Good. There is a product which can deliver you pleasure…if only you can…click an ad.
Using machine learning to drive rankings is ultimately an exercise in confirmation bias:
For “Should abortion be legal?” Google cited a South African news site saying, “It is not the place of government to legislate against woman’s choices.”
When asked, “Should abortion be illegal?” it promoted an answer from obscure clickbait site listland.com stating, “Abortion is murder.”
Excellent work Google in using your featured snippets to help make the world more absolutist, polarized & toxic.
The central network operators not only attempt to manipulate people at the emotional level, but the layout of the interface also sets default user patterns.
Most users tend to focus their attention on the left side of the page: “if we were to slice a maximized page down the middle, 80% of the fixations fell on the left half of the screen (even more than our previous finding of 69%). The remaining 20% of fixations were on the right half of the screen.”
This behavior is even more prevalent on search results pages: “On SERPs, almost all fixations (94%) fell on the left side of the page, and 60% those fixations can be isolated to the leftmost 400px.”
On mobile, obviously, the attention is focused on what is above the fold. That which is below the fold sort of doesn’t even exist for a large subset of the population.
Outside of a few central monopoly attention merchant players, the ad-based web is dying.
Mashable has raised about $46 million in VC funding over the past 4 years. And they just sold for about $50 million.
Breaking even is about as good as it gets in a web controlled by the Google / Facebook duopoly. :D
Other hopeful unicorn media startups appear to have peaked as well. That BuzzFeed IPO is on hold: “Some BuzzFeed investors have become worried about the company’s performance and rising costs for expansions in areas like news and entertainment. Those frustrations were aired at a board meeting in recent weeks, in which directors took management to task, the people familiar with the situation said.”
Google’s Chrome web browser will soon have an ad blocker baked into it. Of course the central networks opt out of applying this feature to themselves. Facebook makes serious coin by blocking ad blockers. Google pays Adblock Plus to unblock ads on Google.com & boy are there a lot of ads there.
Format your pages like Google does their search results and they will tell you it is a piss poor user experience & a form of spam – whacking you with a penalty for it.
Of course Google isn’t the only search engine doing this. Mix in ads with a double listing and sometimes there will only be 1 website listed above the fold.
I’ve even seen some Bing search results where organic results have a “Web” label on them – which is conveniently larger than the ad label that is on ads. That is in addition to other tricks like…
lots of ad extensions that push organics below the fold on anything with the slightest commercial intent
bolding throughout ads (title, description, URL) with much lighter bolding of organics
only showing 6 organic results on commercial searches that are likely to generate ad clicks
As bad as either of the above looks in terms of ad load or result diversity on the desktop, it is only worse on mobile.
On mobile devices organic search results can be so hard to find that people ask questions like “Are there any search engines where you don’t have to literally scroll to see a result that isn’t an advertisement?“
The answer is yes.
But other than that, it is slim pickings.
In an online ecosystem where virtually every innovation is copied or deemed spam, sustainable publishing only works if your business model is different than the central network operators.
Not only is there the aggressive horizontal ad layer for anything with a hint of commercial intent, but now the scrape layer which was first applied to travel is being spread across other categories like ecommerce.
Ecommerce retailers beware. There is now a GIANT knowledge panel result on mobile that takes up the entire top half of the SERP -> Google updates mobile product knowledge panels to show even more info in one spot: https://t.co/3JMsMHuQmJ pic.twitter.com/5uD8zZiSrK— Glenn Gabe (@glenngabe) November 14, 2017
Here are 2 examples. And alarms are going off at Amazon now. Yes, Prime is killer, but organic search traffic is going to tank. Go ahead & scroll down to the organic listings (if you dare).And if anyone clicks the module, they are taken away from the SERPs into G-Land. Wow. :) pic.twitter.com/SswOPj4iGd— Glenn Gabe (@glenngabe) November 14, 2017
The more of your content Google can scrape-n-displace in the search results the less reason there is to visit your website & the more ad-heavy Google can make their interface because they shagged the content from your site.
Simply look at the market caps of the big tech monopolies vs companies in adjacent markets. The aggregate trend is expressed in the stock price. And it is further expressed in the inability for the unicorn media companies to go public.
As big as Snapchat & Twitter are, nobody who invested in either IPO is sitting on a winner today.
Google is outraged anyone might question the numbers & if the current set up is reasonable:
Mr Harris described as “factually incorrect” suggestions that Google was “stealing” ad revenue from publishers, saying that two thirds of the revenues generated by online content went to its originators.
“I’ve heard lots of people say that Google and Facebook are “ruthlessly stealing” all the advertising revenue that publishers hoped to acquire through online editions,” he told the gathering.
“There is no advertising on Google News. Zero. Indeed you will rarely see advertising around news cycles in Google Search either.
Sure it is not the ad revenues they are stealing.
Rather it is the content.
Either by scraping, or by ranking proprietary formats (AMP) above other higher quality content which is not published using the proprietary format & then later attaching crappier & crappier deals to the (faux) “open source” proprietary content format.
As Google grabs the content & cuts the content creator off from the audience while attaching conditions, Google’s PR hacks will tell you they want you to click through to the source:
Google spokeswoman Susan Cadrecha said the company’s goal isn’t to do the thinking for users but “to help you find relevant information quickly and easily.” She added, “We encourage users to understand the full context by clicking through to the source.”
except they are the ones adding extra duplicative layers which make it harder to do.
Google keeps extracting content from publishers & eating the value chain. Some publishers have tried to offset this by putting more ads on their own site while also getting further distribution by adopting the proprietary AMP format. Those who realized AMP was garbage in terms of monetization viewed it as a way to offer teasers to drive users to their websites.
The partial story approach is getting killed though. Either you give Google everything, or they want nothing.
That is, after all, how monopolies negotiate – ultimatums.
Those who don’t give Google their full content will soon receive manual action penalty notifications
Important: Starting 2/1/18, Google is requiring that AMP urls be comparable to the canonical page content. If not, Google will direct users to the non-AMP urls. And the urls won’t be in the Top Stories carousel. Site owners will receive a manual action: https://t.co/ROhbI6TMVz pic.twitter.com/hb9FTluV0S— Glenn Gabe (@glenngabe) November 16, 2017
The value of news content is not zero.
Being the go-to resource for those sorts of “no money here” news topics also enables Google to be the go-to resource for searches for [auto insurance quote] and other highly commercial search terms where Google might make $50 or $100 per click.
Every month Google announces new ad features.
Economics drive everything in publishing. But you have to see how one market position enables another. Google & Facebook are not strong in China, so Toutiao – the top news app in China – is valued at about $20 billion.
Now that Yahoo! has been acquired by Verizon, they’ve decided to shut down their news app. Unprofitable segments are worth more as a write off than as an ongoing concern. Look for Verizon to further take AIM at shutting down additional parts of AOL & Yahoo.
Firefox recently updated to make its underlying rendering engine faster & more stable. As part of the upgrade they killed off many third party extensions, including ours. We plan to update them soon (a few days perhaps), but those who need the extensions working today may want to install something like (Comodo Dragon (or another browser based on the prior Firefox core) & install our extensions in that web browser.
As another part of the most recent Firefox update, Firefox dumped Yahoo! Search for Google search as their default search engine in a new multiyear deal where financial terms were not disclosed.
Yahoo! certainly deserved to lose that deal.
First, they signed a contract with Mozilla containing a change-of-ownership poison pill where Mozilla would still make $375 million a year from them even if they dump Yahoo!. Given what Yahoo! sold for this amounts to about 10% of the company price for the next couple years.
Second, Yahoo! overpaid for the Firefox distribution deal to where they had to make their user experience even more awful to try to get the numbers to back out.
Here is a navigational search result on Yahoo! where the requested site only appears in the right rail knowledge graph.
The “organic” result set has been removed. There’s a Yahoo! News insert, a Yahoo Local insert, an ad inviting you to download Firefox (bet that has since been removed!), other search suggestions, and then graphical ads to try to get you to find office furniture or other irrelevant stuff.
Here is how awful those sorts of search results are: Yahoo! was so embarrassed at the lack of quality of their result set that they put their logo at the upper right edge of the page.
So now they’ll be losing a million a day for a few years based on Marissa Mayer’s fantastic Firefox deal.
And search is just another vertical they made irrelevant.
When they outsourced many verticals & then finally shut down most of the remaining ones, they only left a few key ones:
On our recent earnings call, Yahoo outlined out a plan to simplify our business and focus our effort on our four most successful content areas – News, Sports, Finance and Lifestyle. To that end, today we will begin phasing out the following Digital Magazines: Yahoo Food, Yahoo Health, Yahoo Parenting, Yahoo Makers, Yahoo Travel, Yahoo Autos and Yahoo Real Estate.
And for the key verticals they kept, they have pages like the following, which look like a diet version of eHow
Every day they send users away to other sites with deeper content. And eventually people find one they like (like TheAthletic or Dunc’d On) & then Yahoo! stops being a habit.
Meanwhile many people get their broader general news from Facebook, Google shifted their search app to include news, Apple offers a great news app, the default new tab on Microsoft Edge browser lists a localize news feed. Any of those is a superior user experience to Yahoo!.
It is hard to see what Yahoo!’s role is going forward.
Other than the user email accounts (& whatever legal liabilities are associated with the chronic user account hacking incidents), it is hard to see what Verizon bought in Yahoo!.
Categories:
Left is Right & Up is Down
Probably the single best video to watch to understand the power of Google & Facebook (or even most of the major problems across society) is this following video about pleasure versus happiness.
In constantly seeking pleasure we forego happiness.
The “feed” based central aggregation networks are just like slot machines in your pocket: variable reward circuitry which self-optimizes around exploiting your flaws to eat as much attention as possible.
The above is not an accident. It is, rather, as intended:
“That means that we needed to sort of give you a little dopamine hit every once in a while because someone liked or commented on a photo or a post or whatever … It’s a social validation feedback loop … You’re exploiting a vulnerability in human psychology … [The inventors] understood this, consciously, and we did it anyway.”
- Happy? Good! Share posed photos to make your friends feel their lives are worse than your life is.
- Outraged? Good! Click an ad.
- Hopeless? Good. There is a product which can deliver you pleasure…if only you can…click an ad.
Using machine learning to drive rankings is ultimately an exercise in confirmation bias:
For “Should abortion be legal?” Google cited a South African news site saying, “It is not the place of government to legislate against woman’s choices.”
When asked, “Should abortion be illegal?” it promoted an answer from obscure clickbait site listland.com stating, “Abortion is murder.”
Excellent work Google in using your featured snippets to help make the world more absolutist, polarized & toxic.
The central network operators not only attempt to manipulate people at the emotional level, but the layout of the interface also sets default user patterns.
Most users tend to focus their attention on the left side of the page: “if we were to slice a maximized page down the middle, 80% of the fixations fell on the left half of the screen (even more than our previous finding of 69%). The remaining 20% of fixations were on the right half of the screen.”
This behavior is even more prevalent on search results pages: “On SERPs, almost all fixations (94%) fell on the left side of the page, and 60% those fixations can be isolated to the leftmost 400px.”
On mobile, obviously, the attention is focused on what is above the fold. That which is below the fold sort of doesn’t even exist for a large subset of the population.
Outside of a few central monopoly attention merchant players, the ad-based web is dying.
Mashable has raised about $46 million in VC funding over the past 4 years. And they just sold for about $50 million.
Breaking even is about as good as it gets in a web controlled by the Google / Facebook duopoly. :D
Other hopeful unicorn media startups appear to have peaked as well. That BuzzFeed IPO is on hold: “Some BuzzFeed investors have become worried about the company’s performance and rising costs for expansions in areas like news and entertainment. Those frustrations were aired at a board meeting in recent weeks, in which directors took management to task, the people familiar with the situation said.”
Google’s Chrome web browser will soon have an ad blocker baked into it. Of course the central networks opt out of applying this feature to themselves. Facebook makes serious coin by blocking ad blockers. Google pays Adblock Plus to unblock ads on Google.com & boy are there a lot of ads there.
Format your pages like Google does their search results and they will tell you it is a piss poor user experience & a form of spam – whacking you with a penalty for it.
Of course Google isn’t the only search engine doing this. Mix in ads with a double listing and sometimes there will only be 1 website listed above the fold.
I’ve even seen some Bing search results where organic results have a “Web” label on them – which is conveniently larger than the ad label that is on ads. That is in addition to other tricks like…
- lots of ad extensions that push organics below the fold on anything with the slightest commercial intent
- bolding throughout ads (title, description, URL) with much lighter bolding of organics
- only showing 6 organic results on commercial searches that are likely to generate ad clicks
As bad as either of the above looks in terms of ad load or result diversity on the desktop, it is only worse on mobile.
On mobile devices organic search results can be so hard to find that people ask questions like “Are there any search engines where you don’t have to literally scroll to see a result that isn’t an advertisement?“
The answer is yes.
But other than that, it is slim pickings.
In an online ecosystem where virtually every innovation is copied or deemed spam, sustainable publishing only works if your business model is different than the central network operators.
Not only is there the aggressive horizontal ad layer for anything with a hint of commercial intent, but now the scrape layer which was first applied to travel is being spread across other categories like ecommerce.
Ecommerce retailers beware. There is now a GIANT knowledge panel result on mobile that takes up the entire top half of the SERP -> Google updates mobile product knowledge panels to show even more info in one spot: https://t.co/3JMsMHuQmJ pic.twitter.com/5uD8zZiSrK— Glenn Gabe (@glenngabe) November 14, 2017
Here are 2 examples. And alarms are going off at Amazon now. Yes, Prime is killer, but organic search traffic is going to tank. Go ahead & scroll down to the organic listings (if you dare).And if anyone clicks the module, they are taken away from the SERPs into G-Land. Wow. :) pic.twitter.com/SswOPj4iGd— Glenn Gabe (@glenngabe) November 14, 2017
The more of your content Google can scrape-n-displace in the search results the less reason there is to visit your website & the more ad-heavy Google can make their interface because they shagged the content from your site.
Simply look at the market caps of the big tech monopolies vs companies in adjacent markets. The aggregate trend is expressed in the stock price. And it is further expressed in the inability for the unicorn media companies to go public.
As big as Snapchat & Twitter are, nobody who invested in either IPO is sitting on a winner today.
Google is outraged anyone might question the numbers & if the current set up is reasonable:
Mr Harris described as “factually incorrect” suggestions that Google was “stealing” ad revenue from publishers, saying that two thirds of the revenues generated by online content went to its originators.
“I’ve heard lots of people say that Google and Facebook are “ruthlessly stealing” all the advertising revenue that publishers hoped to acquire through online editions,” he told the gathering.
“There is no advertising on Google News. Zero. Indeed you will rarely see advertising around news cycles in Google Search either.
Sure it is not the ad revenues they are stealing.
Rather it is the content.
Either by scraping, or by ranking proprietary formats (AMP) above other higher quality content which is not published using the proprietary format & then later attaching crappier & crappier deals to the (faux) “open source” proprietary content format.
As Google grabs the content & cuts the content creator off from the audience while attaching conditions, Google’s PR hacks will tell you they want you to click through to the source:
Google spokeswoman Susan Cadrecha said the company’s goal isn’t to do the thinking for users but “to help you find relevant information quickly and easily.” She added, “We encourage users to understand the full context by clicking through to the source.”
except they are the ones adding extra duplicative layers which make it harder to do.
Google keeps extracting content from publishers & eating the value chain. Some publishers have tried to offset this by putting more ads on their own site while also getting further distribution by adopting the proprietary AMP format. Those who realized AMP was garbage in terms of monetization viewed it as a way to offer teasers to drive users to their websites.
The partial story approach is getting killed though. Either you give Google everything, or they want nothing.
That is, after all, how monopolies negotiate – ultimatums.
Those who don’t give Google their full content will soon receive manual action penalty notifications
Important: Starting 2/1/18, Google is requiring that AMP urls be comparable to the canonical page content. If not, Google will direct users to the non-AMP urls. And the urls won’t be in the Top Stories carousel. Site owners will receive a manual action: https://t.co/ROhbI6TMVz pic.twitter.com/hb9FTluV0S— Glenn Gabe (@glenngabe) November 16, 2017
The value of news content is not zero.
Being the go-to resource for those sorts of “no money here” news topics also enables Google to be the go-to resource for searches for [auto insurance quote] and other highly commercial search terms where Google might make $50 or $100 per click.
Every month Google announces new ad features.
Economics drive everything in publishing. But you have to see how one market position enables another. Google & Facebook are not strong in China, so Toutiao – the top news app in China – is valued at about $20 billion.
Now that Yahoo! has been acquired by Verizon, they’ve decided to shut down their news app. Unprofitable segments are worth more as a write off than as an ongoing concern. Look for Verizon to further take AIM at shutting down additional parts of AOL & Yahoo.
Firefox recently updated to make its underlying rendering engine faster & more stable. As part of the upgrade they killed off many third party extensions, including ours. We plan to update them soon (a few days perhaps), but those who need the extensions working today may want to install something like (Comodo Dragon (or another browser based on the prior Firefox core) & install our extensions in that web browser.
As another part of the most recent Firefox update, Firefox dumped Yahoo! Search for Google search as their default search engine in a new multiyear deal where financial terms were not disclosed.
Yahoo! certainly deserved to lose that deal.
First, they signed a contract with Mozilla containing a change-of-ownership poison pill where Mozilla would still make $375 million a year from them even if they dump Yahoo!. Given what Yahoo! sold for this amounts to about 10% of the company price for the next couple years.
Second, Yahoo! overpaid for the Firefox distribution deal to where they had to make their user experience even more awful to try to get the numbers to back out.
Here is a navigational search result on Yahoo! where the requested site only appears in the right rail knowledge graph.
The “organic” result set has been removed. There’s a Yahoo! News insert, a Yahoo Local insert, an ad inviting you to download Firefox (bet that has since been removed!), other search suggestions, and then graphical ads to try to get you to find office furniture or other irrelevant stuff.
Here is how awful those sorts of search results are: Yahoo! was so embarrassed at the lack of quality of their result set that they put their logo at the upper right edge of the page.
So now they’ll be losing a million a day for a few years based on Marissa Mayer’s fantastic Firefox deal.
And search is just another vertical they made irrelevant.
When they outsourced many verticals & then finally shut down most of the remaining ones, they only left a few key ones:
On our recent earnings call, Yahoo outlined out a plan to simplify our business and focus our effort on our four most successful content areas – News, Sports, Finance and Lifestyle. To that end, today we will begin phasing out the following Digital Magazines: Yahoo Food, Yahoo Health, Yahoo Parenting, Yahoo Makers, Yahoo Travel, Yahoo Autos and Yahoo Real Estate.
And for the key verticals they kept, they have pages like the following, which look like a diet version of eHow
Every day they send users away to other sites with deeper content. And eventually people find one they like (like TheAthletic or Dunc’d On) & then Yahoo! stops being a habit.
Meanwhile many people get their broader general news from Facebook, Google shifted their search app to include news, Apple offers a great news app, the default new tab on Microsoft Edge browser lists a localize news feed. Any of those is a superior user experience to Yahoo!.
It is hard to see what Yahoo!’s role is going forward.
Other than the user email accounts (& whatever legal liabilities are associated with the chronic user account hacking incidents), it is hard to see what Verizon bought in Yahoo!.
Categories:
Grist for the Machine
Grist
Much like publishers, employees at the big tech monopolies can end up little more than grist.
Products & product categories come & go, but even if you build “the one” you still may lose everything in the process.
Imagine building the most successful consumer product of all time only to realize:’The iPhone is the reason I’m divorced,’ Andy Grignon, a senior iPhone engineer, tells me. I heard that sentiment more than once throughout my dozens of interviews with the iPhone’s key architects and engineers.’Yeah, the iPhone ruined more than a few marriages,’ says another.
Microsoft is laying off thousands of salespeople.
Google colluded with competitors to sign anti-employee agreements & now they are trying to hold down labor costs with modular housing built on leased government property. They can tout innovation they bring to Africa, but at their core the tech monopolies are still largely abusive. What’s telling is that these companies keep using their monopoly profits to buy more real estate near their corporate headquarters, keeping jobs there in spite of the extreme local living costs.
“There’s been essentially no dispersion of tech jobs,’ said Mr. Kolko, who conducted the research.’Which metro is the next Silicon Valley? The answer is none, at least for the foreseeable future. Silicon Valley still stands apart.’
Making $180,000 a year can price one out of the local real estate market, requiring living in a van or a two hour commute. An $81,000 salary can require a 3 hour commute.
If you are priced out of the market by the monopoly de jour, you can always pray!
The hype surrounding transformative technology that disintermediates geography & other legacy restraints only lasts so long: “The narrative isn’t the product of any single malfunction, but rather the result of overhyped marketing, deficiencies in operating with deep learning and GPUs and intensive data preparation demands.”
AI is often a man standing behind a curtain.
The big tech companies are all about equality, opportunity & innovation. At some point either the jobs move to China or China-like conditions have to move to the job. No benefits, insurance cost passed onto the temp worker, etc.
Google’s outsourced freelance workers have to figure out how to pay for their own health insurance:
A manager named LFEditorCat told the raters in chat that the pay cut had come at the behest of’Big G’s lawyers,’ referring to Google. Later, a rater asked Jackson,’If Google made this change, can Google reverse this change, in theory?’ Jackson replied,’The chances of this changing are less than zero IMO.’
That’s rather unfortunate, as the people who watch the beheading videos will likely need PTSD treatment.
The tech companies are also leveraging many “off the books” employees for last mile programs, where the wage is anything but livable after the cost of fuel, insurance & vehicle maintenance. They are accelerating the worst aspects of consolidated power:
America really is undergoing a radical change in the structure of our political economy. And yet this revolutionary shift of power, control, and wealth has remained all but unrecognized and unstudied … Since the 1990s, large companies have increasingly relied on temporary help to do work that formerly was performed by permanent salaried employees. These arrangements enable firms to hire and fire workers with far greater flexibility and free them from having to provide traditional benefits like unemployment insurance, health insurance, retirement plans, and paid vacations. The workers themselves go by many different names: temps, contingent workers, contractors, freelancers. But while some fit the traditional sense of what it means to be an entrepreneur or independent business owner, many, if not most, do not-precisely because they remain entirely dependent on a single power for their employment.
Dedication & devotion are important traits. Are you willing to do everything you can to go the last mile? “Lyft published a blog post praising a driver who kept picking up fares even after she went into labor and was driving to the hospital to give birth.”
Then again, the health industry is a great driver of consumption:
About 1.8 million workers were out of the labor force for “other” reasons at the beginning of this year, meaning they were not retired, in school, disabled or taking care of a loved one, according to Atlanta Federal Reserve data. Of those people, nearly half — roughly 881,000 workers — said in a survey that they had taken an opioid the day before, according to a study published last year by former White House economist Alan Krueger.”
Creating fake cancer patients is a practical way to make sales.
That is until they stop some of the scams & view those people as no longer worth the economic cost. Those people are only dying off at a rate of about 90 people a day. Long commutes are associated with depression. And enough people are taking anti-depressants that it shows up elsewhere in the food chain.
Rehabilitation is hard work:
After a few years of buildup, Obamacare kicked the scams into high gear. …. With exchange plans largely locked into paying for medically required tests, patients (and their urine) became gold mines. Some labs started offering kickbacks to treatment centers, who in turn began splitting the profits with halfway houses that would tempt clients with free rent and other services. … Street-level patient brokers and phone room lead generators stepped up to fill the beds with strategies across the ethical spectrum, including signing addicts up for Obamacare and paying their premiums.
Google made a lot of money from that scam until it got negative PR coverage.
The story says Wall Street is *unhappy* at the too low $475,000 price tag for this medicine. https://t.co/Fw4RXok2V1— Matt Stoller (@matthewstoller) September 4, 2017
At the company, we’re family. Once you are done washing the dishes, you can live in the garage. Just make sure you juice!
When platform monopolies dictate the roll-out of technology, there is less and less innovation, fewer places to invest, less to invent. Eventually, the rhetoric of innovation turns into DISRUPT, a quickly canceled show on MSNBC, and Juicero, a Google-backed punchline.
This moment of stagnating innovation and productivity is happening because Silicon Valley has turned its back on its most important political friend: antitrust. Instead, it’s embraced what it should understand as the enemy of innovation: monopoly.
And the snowflake narrative not only relies on the “off the books” marginalized freelance employees to maintain lush benefits for the core employees, but those core employees can easily end up thrown under the bus because accusation is guilt. Uniformity of political ideology is the zenith of a just world.
Some marketing/framing savvy pple figured out that the most effective way to build a fascist movement is to call it:antifascist.— NassimNicholasTaleb (@nntaleb) August 31, 2017
Celebrate diversity in all aspects of life – except thoughtTM.
Identity politics 2.0 wars come to Google. Oh no. But mass spying is fine since its equal opportunity predation.https://t.co/BArOsWb1ho— Julian Assange (@JulianAssange) August 6, 2017
Free speech is now considered violence. Free speech has real cost. So if you disagree with someone, “people you might have to work with may simply punch you in the face” – former Google diversity expert Yonatan Zunger.
Anything but the facts!
Mob rule – with a splash of violence – for the win.
Social justice is the antithesis of justice.
It is the aspie guy getting fired for not understanding the full gender “spectrum.”
Google exploits the mental abilities of its aspie workers but lets them burn at the stake when its disability, too much honesty, manifests. pic.twitter.com/Sd1A0KJvc0— Julian Assange (@JulianAssange) August 15, 2017
It is the repression of truth: “Truth equals virtue equals happiness. You cannot solve serious social problems by telling lies or punishing people who tell truth.”
Most meetings at Google are recorded. Anyone at Google can watch it. We’re trying to be really open about everything…except for this. They don’t want any paper trail for any of these things. They were telling us about a lot of these potentially illegal practices that they’ve been doing to try to increase diversity. Basically treating people differently based on what their race or gender are. – James Damore
The recursive feedback loops & reactionary filtering are so bad that some sites promoting socialism are now being dragged to the Google gulag.
In a set of guidelines issued to Google evaluators in March, elaborated in April by Google VP of Engineering Ben Gomes, the company instructed its search evaluators to flag pages returning’conspiracy theories’ or’upsetting’ content unless’the query clearly indicates the user is seeking an alternative viewpoint.’ The changes to the search rankings of WSWS content are consistent with such a mechanism. Users of Google will be able to find the WSWS if they specifically include’World Socialist Web Site’ in their search request. But if their inquiry simply includes term such as’Trotsky,”Trotskyism,”Marxism,”socialism’ or’inequality,’ they will not find the site.
Every website which has a following & challenges power is considered “fake news” or “conspiracy theory” until many years later, when many of the prior “nutjob conspiracies” turn out to be accurate representations of reality.
Under its new so-called anti-fake-news program, Google algorithms have in the past few months moved socialist, anti-war, and progressive websites from previously prominent positions in Google searches to positions up to 50 search result pages from the first page, essentially removing them from the search results any searcher will see. Counterpunch, World Socialsit Website, Democracy Now, American Civil liberties Union, Wikileaks are just a few of the websites which have experienced severe reductions in their returns from Google searches.
In the meantime townhall meetings celebrating diversity will be canceled & differentiated voices will be marginalized to protect the mob from themselves.
What does the above say about tech monopolies wanting to alter the structure of society when their internal ideals are based on fundamental lies? They can’t hold an internal meeting addressing sacred cows because “ultimately the loudest voices on the fringes drive the perception and reaction” but why not let them distribute swarms of animals with bacteria & see what happens? Let’s make Earth a beta.
FANG
The more I study the macro picture the more concerned I get about the long term ramifications of a financially ever more divergent society. pic.twitter.com/KoY60fAfe2— Sven Henrich (@NorthmanTrader) August 9, 2017
Monopoly platforms are only growing more dominant by the day.
Over the past three decades, the U.S. government has permitted corporate giants to take over an ever-increasing share of the economy. Monopoly-the ultimate enemy of free-market competition-now pervades every corner of American life … Economic power, in fact, is more concentrated than ever: According to a study published earlier this year, half of all publicly traded companies have disappeared over the past four decades.
And you don’t have to subscribe to deep state conspiracy theory in order to see the impacts.
Nike selling on Amazon=media cos selling to Netflix=news orgs publishing straight to Facebook. https://t.co/3hpVIsymXD— Miriam Gottfried (@miriamgottfried) June 28, 2017
The revenue, value & profit transfer is overt:
It is no coincidence that from 2012 to 2016, Amazon, Google and Facebook’s revenues increased by $137 billion and the remaining Fortune 497 revenues contracted by $97 billion.
Netflix, Amazon, Apple, Google, Facebook … are all aggressively investing in video content as bandwidth is getting cheaper & they need differentiated content to drive subscription revenues. If the big players are bidding competitively to have differentiated video content that puts a bid under some premium content, but for ad-supported content the relatively high CPMs on video content might fall sharply in the years to come.
From a partner perspective, if you only get a percent of revenue that transfers all the risk onto you, how is the new Facebook video feature going to be any better than being a YouTube partner? As video becomes more widespread, won’t that lower CPMs?
One publisher said its Facebook-monetized videos had an average CPM of 15 cents. A second publisher, which calculated ad rates based on video views that lasted long enough to reach the ad break, said the average CPM for its mid-rolls is 75 cents. A third publisher made roughly $500 from more than 20 million total video views on that page in September.
That’s how monopolies work. Whatever is hot at the moment gets pitched as the future, but underneath the hood all compliments get commoditized:
as a result of this increased market power, the big superstar companies have been raising their prices and cutting their wages. This has lifted profits and boosted the stock market, but it has also held down real wages, diverted more of the nation’s income to business owners, and increased inequality. It has also held back productivity, since raising prices restricts economic output.
The future of the web is closed, proprietary silos that mirror what existed before the web:
If in five years I’m just watching NFL-endorsed ESPN clips through a syndication deal with a messaging app, and Vice is just an age-skewed Viacom with better audience data, and I’m looking up the same trivia on Genius instead of Wikipedia, and’publications’ are just content agencies that solve temporary optimization issues for much larger platforms, what will have been point of the last twenty years of creating things for the web?
They’ve all won their respective markets & are now converging:
We’ve been in the celebration phase all year as Microsoft, Google, Amazon, Apple, Netflix and Facebook take their place in the pantheon of classic American monopolists. These firms and a few others, it is now widely acknowledged, dominate everything. There is no day-part in which they do not dominate the battle for consumers’ attention. There is no business safe from their ambitions. There are no industries in which their influence and encroachment are not currently being felt.
The web shifts information-based value chains to universal distribution at zero marginal cost, which shifts most of the value extraction to the attention merchants.
The raw feed stock for these centralized platforms isn’t particularly profitable:
despite a user base near the size of Instagram’s, Tumblr never quite figured out how to make money at the level Facebook has led managers and shareholders to expect … running a platform for culture creation is, increasingly, a charity operation undertaken by larger companies. Servers are expensive, and advertisers would rather just throw money at Facebook than take a chance
Those resting in the shadows of the giants will keep getting crushed: “They let big tech crawl, parse, and resell their IP, catalyzing an extraordinary transfer in wealth from the creators to the platforms.”
The. Problem. Everywhere. Is. Unaccountable. Monopoly. Power. That. Is. Why. Voters. Everywhere. Are. Angry.— Matt Stoller (@matthewstoller) September 24, 2017
They’ll take the influence & margins, but not the responsibility normally associated with such a position:
“Facebook has embraced the healthy gross margins and influence of a media firm but is allergic to the responsibilities of a media firm,” Mr. Galloway says. … For Facebook, a company with more than $14 billion in free cash flow in the past year, to say it is adding 250 people to its safety and security efforts is’pissing in the ocean,’ Mr. Galloway says.’They could add 25,000 people, spend $1 billion on AI technologies to help those 25,000 employees sort, filter and ID questionable content and advertisers, and their cash flow would decline 10% to 20%.’
It’s why there’s a management shake up at Pandora, Soundcloud laid off 40% of their staff & Vimeo canceled their subscription service before it was even launched.
Deregulation, as commonly understood, is actually just moving regulatory authority from democratic institutions to private ones.— Matt Stoller (@matthewstoller) September 23, 2017
With the winners of the web determined, it’s time to start locking down the ecosystem with DRM:
Practically speaking, bypassing DRM isn’t hard (Google’s version of DRM was broken for six years before anyone noticed), but that doesn’t matter. Even low-quality DRM gets the copyright owner the extremely profitable right to stop their customers and competitors from using their products except in the ways that the rightsholder specifies. … for a browser to support EME, it must also license a “Content Decryption Module” (CDM). Without a CDM, video just doesn’t work. All the big incumbents advocating for DRM have licenses for CDMs, but new entrants to the market will struggle to get these CDMs, and in order to get them, they have to make promises to restrict otherwise legal activities … We’re dismayed to see the W3C literally overrule the concerns of its public interest members, security experts, accessibility members and innovative startup members, putting the institution’s thumb on the scales for the large incumbents that dominate the web, ensuring that dominance lasts forever.
After years of loosey goosey privacy violations by the tech monopoly players, draconian privacy laws will block new competitors:
More significantly, the GDPR extends the concept of’personal data’ to bring it into line with the online world. The regulation stipulates, for example, that an online identifier, such as a device’s IP address, can now be personal data. So next year, a wide range of identifiers that had hitherto lain outside the law will be regarded as personal data, reflecting changes in technology and the way organisations collect information about people. … Facebook and Google should be OK, because they claim to have the’consent’ of their users. But the data-broking crowd do not have that consent.
GDRP is less than 8 months away.
If you can’t get the fat thumb accidental mobile ad clicks then you need to convert formerly free services to a paid version or sell video ads. Yahoo! shut down most their verticals, was acquired by Verizon, and is now part of Oath. Oath’s strategy is so sound Katie Couric left:
Oath’s video unit, however, had begun doubling down on the type of highly shareable,’snackable’ bites that people gobble up on their smartphones and Facebook feeds. … . What frustrates her like nothing else, two people close to Couric told me, is when she encounters fans and they ask her what she’s up to these days.
When content is atomized into the smallest bits & recycling is encouraged only the central network operators without editorial content costs win.
Even Reddit is pushing crappy autoplay videos for the sake of ads. There’s no chance of it working for them, but they’ll still try, as Google & Facebook have enviable market caps.
Mic laid off journalists and is pivoting to video.
It doesn’t work, but why not try.
The TV networks which focused on the sort of junk short-form video content that is failing online are also seeing low ratings.
Probably just a coincidence.
Some of the “innovative” upstart web publishers are recycling TV ads as video content to run pre-roll ads on. An ad inside an ad.
Some suggest the repackaging and reposting of ads highlights the’pivot to video’ mentality many publishers now demonstrate. The push to churn out video content to feed platforms and to attract potentially lucrative video advertising is increasingly viewed as a potential solution to an increasingly challenging business model problem.
Publishers might also get paid a commission on any sales they help drive by including affiliate links alongside the videos. If these links drive users to purchase the products, then the publisher gets a cut.
Is there any chance recycling low quality infomercial styled ads as placeholder auto-play video content to run prerolls on is a sustainable business practice?
If that counts as strategic thinking in online publishing, count me as a short.
For years whenever the Adobe Flash plugin for Firefox had a security update users who hit the page got a negative option install of Google Chrome as their default web browser. And Google constantly markets Chrome across their properties:
Google is aggressively using its monopoly position in Internet services such as Google Mail, Google Calendar and YouTube to advertise Chrome. Browsers are a mature product and its hard to compete in a mature market if your main competitor has access to billions of dollars worth of free marketing.
It only takes a single yes on any of those billions of ad impressions (or an accidental opt in on the negative option bundling with security updates) for the default web browser to change permanently.
There’s no way Mozilla can compete with Google on economics trying to buy back an audience.
Mozilla is willing to buy influence, too – particularly in mobile, where it’s so weak. One option is paying partners to distribute Firefox on their phones.’We’re going to have to put money toward it,’ Dixon says, but she expects it’ll pay off when Mozilla can share revenue from the resulting search traffic.
They have no chance of winning when they focus on wedge issues like fake news. Much like their mobile operating system, it is a distraction. And the core economics of paying for distribution won’t work either. How can Mozilla get a slice of an advertiser’s ad budget through Yahoo through Bing & compete against Google’s bid?
Google is willing to enter uneconomic deals to keep their monopoly power. Look no further than the $1 billion investment they made in AOL which they quickly wrote down by $726 million.
Google pays Apple $3 billion PER YEAR to be the default search provider in Safari. Verizon acquired Yahoo! for $4.48 billion. There’s no chance of Yahoo! outbidding Google for default Safari search placement & if Apple liked the idea they would have bought Yahoo!. It is hard to want to take a big risk & spend billions on something that might not back out when you get paid billions to not take any risk.
Even Microsoft would be taking a big risk in making a competitive bid for the Apple search placement. Microsoft recently disclosed “Search advertising revenue increased $124 million or 8%.” If $124 million is 8% then their quarterly search ad revenue is $1.674 billion. To outbid Google they would have to bid over half their total search revenues.
Regulatory Capture
“I have a foreboding of an America in which my children’s or grandchildren’s time – when the United States is a service and information economy; when nearly all the key manufacturing industries have slipped away to other countries; when awesome technological powers are in the hands of a very few, and no one representing the public interest can even grasp the issues; when the people have lost the ability to set their own agendas or knowledgeably question those in authority; when, clutching our crystals and nervously consulting our horoscopes, our critical faculties in decline, unable to distinguish between what feels good and what’s true, we slide, almost without noticing, back into superstition and darkness. The dumbing down of america is most evident in the slow decay of substantive content in the enormously influential media, the 30-second sound bites (now down to 10 seconds or less), lowest common denominator programming, credulous presentations on pseudoscience and superstition, but especially a kind of celebration of ignorance.” – Carl Sagan, The Demon-haunted World, 1996
Fascinating. Obama felt he had zero authority even while President except to ask nicely. Zero will to govern. https://t.co/935OaRpV2X— Matt Stoller (@matthewstoller) September 25, 2017
The monopoly platforms have remained unscathed by government regulatory efforts in the U.S. Google got so good at lobbying they made Goldman Sachs look like amateurs. It never hurts to place your lawyers in the body that (should) regulate you: “Wright left the FTC in August 2015, returning to George Mason. Just five months later, he had a new position as’of counsel’ at Wilson Sonsini, Google’s primary outside law firm.”
…the 3rd former FTC commissioner in a row to join a firm that represents Google https://t.co/Zu92c5nILh— Luther Lowe (@lutherlowe) September 6, 2017
Remember how Google engineers repeatedly announced how people who bought or sold links without clear machine & human readable disclosure are scum? One way to take .edu link building to the next level is to sponsor academic research without disclosure:
Some researchers share their papers before publication and let Google give suggestions, according to thousands of pages of emails obtained by the Journal in public-records requests of more than a dozen university professors. The professors don’t always reveal Google’s backing in their research, and few disclosed the financial ties in subsequent articles on the same or similar topics, the Journal found. … Google officials in Washington compiled wish lists of academic papers that included working titles, abstracts and budgets for each proposed paper-then they searched for willing authors, according to a former employee and a former Google lobbyist. … Mr. Sokol, though, had extensive financial ties to Google, according to his emails obtained by the Journal. He was a part-time attorney at the Silicon Valley law firm of Wilson Sonsini Goodrich & Rosati, which has Google as a client. The 2016 paper’s co-author was also a partner at the law firm, which didn’t respond to requests for comment.
- Buy link without disclosure = potential influence ranking in search results = evil spammer SEO
- Buy academic research without disclosure (even if lack of disclosure is intentional & the person who didn’t disclose is willing to lie to hide the connection) = directly influence economic & political outcomes = saint Google
As bad as that is, Google has non profit think tanks fire ENTIRE TEAMS if they suggest regulatory action against Google is just:
“We are in the process of trying to expand our relationship with Google on some absolutely key points,’ Ms. Slaughter wrote in an email to Mr. Lynn, urging him to’just THINK about how you are imperiling funding for others.’
“What happened has little to do with New America, and everything to do with Google and monopoly power. One reason that American governance is dysfunctional is because of the capture of much academic and NGO infrastructure by power. That this happened obviously and clumsily at one think tank is not the point. The point is that this is a *system* of power. I have deep respect for the scholars at New America and the work done there. The point here is how *Google* and monopolies operate. I’ll make one other political point about monopoly power. Democracies all over the world are seeing an upsurge in anger. Why? Scholars have tended to look at political differences, like does a different social safety net have an impact on populism. But it makes more sense to understand what countries have in common. Multi-nationals stretch over… multiple nations. So if you think, we do, that corporations are part of our political system, then populism everywhere monopolies operate isn’t a surprise. Because these are the same monopolies. Google is part of the American political system, and the European one, and so on and so forth.” – Matt Stoller
Any dissent of Google is verboten:
in recent years, Google has become greedy about owning not just search capacities, video and maps, but also the shape of public discourse. As the Wall Street Journal recently reported, Google has recruited and cultivated law professors who support its views. And as the New York Times recently reported, it has become invested in building curriculum for our public schools, and has created political strategy to get schools to adopt its products. This year, Google is on track to spend more money than any company in America on lobbying.
“I just got off the phone with Eric Schmidt and he is pulling all of his money.” – Anne-Marie Slaughter
They not only directly control the think tanks, but also state who & what the think tanks may fund:
Google’s director of policy communications, Bob Boorstin, emailed the Rose Foundation (a major funder of Consumer Watchdog) complaining about Consumer Watchdog and asking the charity to consider “whether there might be better groups in which to place your trust and resources.”
They can also, you know, blackball your media organization or outright penalize you. The more aggressive you are with monetization the more leverage they have to arbitrarily hit you if you don’t play ball.
Six years ago, I was pressured to unpublish a critical piece about Google’s monopolistic practices after the company got upset about it. In my case, the post stayed unpublished. I was working for Forbes at the time, and was new to my job.
…
Google never challenged the accuracy of the reporting. Instead, a Google spokesperson told me that I needed to unpublish the story because the meeting had been confidential, and the information discussed there had been subject to a non-disclosure agreement between Google and Forbes. (I had signed no such agreement, hadn’t been told the meeting was confidential, and had identified myself as a journalist.)
Sometimes the threat is explicit:
“You’re already asking very difficult questions to Mr. Juncker,’ the YouTube employee said before Birbes’ interview in an exchange she captured on video.’You’re talking about corporate lobbies. You don’t want to get on the wrong side of YouTube and the European Commission… Well, except if you don’t care about having a long career on YouTube.’
Concentrated source of power manipulates the media. Not new, rather typical. Which is precisely why monopolies should be broken up once they have a track record of abusing the public trust:
As more and more of the economy become sown up by monopolistic corporations, there are fewer and fewer opportunities for entrepreneurship. … By design, the private business corporation is geared to pursue its own interests. It’s our job as citizens to structure a political economy that keeps corporations small enough to ensure that their actions never threaten the people’s sovereignty over our nation.
How much control can one entity get before it becomes excessive?
Google controls upwards of 80 percent of global search-and the capital to either acquire or crush any newcomers. They are bringing us a hardly gilded age of prosperity but depressed competition, economic stagnation, and, increasingly, a chilling desire to control the national conversation.
Google thinks their business is too complex to exist in a single organization. They restructured to minimize their legal risks:
The switch is partly related to Google’s transformation from a listed public company into a business owned by a holding company. The change helps keep potential challenges in one business from spreading to another, according to Dana Hobart, a litigator with the Buchalter law firm in Los Angeles.
Isn’t that an admission they should be broken up?
Early Xoogler Doug Edwards wrote: “[Larry Page] wondered how Google could become like a better version of the RIAA – not just a mediator of digital music licensing – but a marketplace for fair distribution of all forms of digitized content.”
A better version of the RIAA as a north star sure seems like an accurate analogy:
In an explosive new allegation, a renowned architect has accused Google of racketeering, saying in a lawsuit the company has a pattern of stealing trade secrets from people it first invites to collaborate. …’It’s cheaper to steal than to develop your own technology,’ Buether said.’You can take it from somebody else and you have a virtually unlimited budget to fight these things in court.’ …’It’s even worse than just using the proprietary information – they actually then claim ownership through patent applications,’ Buether said.
The following slide expresses Google’s views on premium content
No surprise the Content Creators Coalition called for Congressional Investigation into Google’s Distortion of Public Policy Debates:
Google’s efforts to monopolize civil society in support of the company’s balance-sheet-driven agenda is as dangerous as it is wrong. For years, we have watched as Google used its monopoly powers to hurt artists and music creators while profiting off stolen content. For years, we have warned about Google’s actions that stifle the views of anyone who disagrees with its business practices, while claiming to champion free speech.
In a world where monopolies are built with mission statements like’to organize the world’s information and make it universally accessible and useful’ it makes sense to seal court documents, bury regulatory findings, or else the slogan doesn’t fit as the consumer harm was obvious.
“The 160-page critique, which was supposed to remain private but was inadvertently disclosed in an open-records request, concluded that Google’s ‘conduct has resulted – and will result – in real harm to consumers.’ ” But Google was never penalized, because the political appointees overrode the staff recommendation, an action rarely taken by the FTC. The Journal pointed out that Google, whose executives donated more money to the Obama campaign than any company, had held scores of meetings at the White House between the time the staff filed its report and the ultimate decision to drop the enforcement action.
Some scrappy (& perhaps masochistic players) have been fighting the monopoly game for over a decade:
June 2006: Foundem’s Google search penalty begins. Foundem starts an arduous campaign to have the penalty lifted.
September 2007: Foundem is’whitelisted’ for AdWords (i.e. Google manually grants Foundem immunity from its AdWords penalty).
December 2009: Foundem is’whitelisted’ for Google natural search (i.e. Google manually grants Foundem immunity from its search penalty)
For many years Google has “manipulated search results to favor its own comparison-shopping service. … Google both demotes competitors’ offerings in search rankings and artificially inserts its own service in a box above all other search results, regardless of their relevance.”
After losing for over a decade, on the 27th of June a win was finally delivered when the European Commission issued a manual action to negate the spam, when they fined Google €2.42 billion for abusing dominance as search engine by giving illegal advantage to own comparison shopping service.
“What Google has done is illegal under EU antitrust rules. It denied other companies the chance to compete on the merits and to innovate. And most importantly, it denied European consumers a genuine choice of services and the full benefits of innovation.” – Margrethe Vestager
That fine looks to be the first of multiple record-breaking fines as “Sources expect the Android fine to be substantially higher than the shopping penalty.”
That fine was well deserved:
Quoting internal Google documents and emails, the report shows that the company created a list of rival comparison shopping sites that it would artificially lower in the general search results, even though tests showed that Google users’liked the quality of the [rival] sites’ and gave negative feedback on the proposed changes. Google reworked its search algorithm at least four times, the documents show, and altered its established rating criteria before the proposed changes received’slightly positive’ user feedback. … Google’s displayed prices for everyday products, such as watches, anti-wrinkle cream and wireless routers, were roughly 50 percent higher – sometimes more – than those on rival sites. A subsequent study by a consumer protection group found similar results. A study by the Financial Times also documented the higher prices.
Nonetheless, Google is appealing it. The ease with which Google quickly crafted a response was telling.
The competitors who were slaughtered by monopolistic bundling won’t recover‘The damage has been done. The industry is on its knees, and this is not going to put it back,’ said Mr. Stables, who has decided to participate in Google’s new auctions despite misgivings.’I’m sort of shocked that they’ve come out with this,’ he added.
Google claims they’ll be running their EU shopping ads as a separate company with positive profit margins & that advertisers won’t be bidding against themselves if they are on multiple platforms. Anyone who believes that stuff hasn’t dropped a few thousand dollars on a Flash-only website after AdWords turned on Enhanced campaigns against their wishes – charging the advertisers dollars per click to send users to a blank page which would not load.
Hell may freeze over, causing the FTC to look into Google’s Android bundling similarly to how Microsoft’s OS bundling was looked at.
If hell doesn’t freeze over, it is likely because Google further ramped up their lobbying efforts, donating to political organizations they claim to be ideologically opposed to.
“Monopolists can improve their products to better serve their customers just like any other market participant” <– FTC Chair just said this— Matt Stoller (@matthewstoller) September 12, 2017
The Fight Against Rising (& Declining) Nationalism
As a global corporation above & beyond borders, Google has long been against nationalism. Eric Schmidt’s Hillary Clinton once wrote: “My dream is a hemispheric common market, with open trade and open borders, some time in the future with energy that is as green and sustainable as we can get it, powering growth and opportunity for every person in the hemisphere.”
Apparently Google flacks did not get that memo (or they got the new memo about Eric Schmidt’s Donald Trump), because they were quick to denounce the European Commission’s move as anti-American:
We are writing to express our deep concerns about the European Union’s aggressive and heavy-handed antitrust enforcement action against American companies. It has become increasingly clear that, rather than being grounded in a transparent legal framework, these various investigations and complaints are being driven by politics and protectionist policies that harm open-competition practices, consumers, and unfairly target American companies,.
The above nonsense was in spite of Yelp carrying a heavy load.
The lion’s share of work on EU case was advanced by US companies who had to go to Europe after a politically captured FTC failed them. 6/x— Luther Lowe (@lutherlowe) June 26, 2017
Yelp celebrated the victory: “Google has been found guilty of engaging in illegal conduct with the aim of promoting its vertical search services. Although the decision addresses comparison shopping services, the European Commission has also recognized that the same illegal behavior applies to other verticals, including local search.”
It’s not a’grudge.’ Extractive platforms competing with their ecosystem is the Achilles heel of the entire economy https://t.co/uLKSLC6vQy— Tim O’Reilly (@timoreilly) July 2, 2017
The EU is also looking for an expert to monitor Google’s algorithm. It certainly isn’t hard to find areas where the home team wins.
Wait until the EU realizes #Google issue much bigger than paid listings; domains(.)google ranks ahead of #GoDaddy pic.twitter.com/nKLrzKNUAc— The Domains (@thedomains) June 27, 2017
Categories: