
This is part 1 of 2 of my evidence-based framework for SEO (Search Engine Optimisation) strategy. Part 2 is my final post on Hobo SEO Blog (Thursday).
TLDR: Based on the revelations from the Google Content Warehouse, an effective on-page SEO strategy should be built around the following core principles (which I explore in this article):
- Optimise for the entire ranking pipeline.
- Engineer for “good clicks,” not just any click.
- Treat site authority as a primary goal.
- Invest in content that shows “effort”.
- Be patient with new sites and pages.
- Use short, evergreen URLs from the start and protect page history.
- Update the substance, not just the date.
- Remember that your entire site experience is being measured.
- Remember, each new article should add to your topical authority, not dilute it.
This guide is for serious SEO practitioners. Want to know more? Here it is:
Google’s Internal Content Warehouse API Leak
The accidental publication of Google’s internal Content Warehouse API documentation in March 2024 represents the most significant event in the history of Search Engine Optimisation.
Traditionally, the SEO industry operated on a combination of official guidance, reverse engineering, and hard-won intuition.
The leak, spanning over 2,500 pages and detailing 14,014 attributes across 2,596 modules, has irrevocably shifted this paradigm from one of inference to one of evidence
It provides an unprecedented, though incomplete, blueprint of the data points Google’s systems collect and evaluate to rank the web.
The most fundamental revelation from this documentation is the definitive dismantling of the myth of a single, monolithic “Google Algorithm.”
The reality is far more complex and modular.
Google Search does not rely on one overarching formula but on a sophisticated, multi-layered ecosystem of interconnected microservices and specialised systems, each performing a distinct function, sometimes competing with each other within a broader processing pipeline.
Understanding this architecture is the new prerequisite for effective on-page SEO, as it reframes the objective from optimising for a single score to optimising a page’s successful passage through a series of distinct evaluation gates.
The Composite Document: The Master File for a URL
The leak reveals that for every document it processes, Google creates a master data object known as a CompositeDoc.
This can be thought of as the central file or container that holds all the disparate signals and attributes associated with a single URL.
It is within this CompositeDoc that the various modules and scores – from on-page quality signals (qualitysignals) and technical data (robotsinfolist) to user engagement metrics (perDocData) and link information (anchors) – are stored and organised.
This structure confirms that Google’s evaluation is a process of aggregation, where dozens of specialised analyses are compiled into a single, comprehensive profile for a webpage before it is ranked.
The Two Pillars of Ranking: Quality (Q*) and Popularity (P*)
Insights from the DOJ v. Google antitrust trial, corroborated by the leak, reveal that Google’s ranking philosophy is built on two fundamental, top-level signals: a site-level quality score known as Q* (pronounced “Q-star”) and a popularity signal known as P*.
A trial exhibit stated plainly that “Q* (page quality (i.e., the notion of trustworthiness)) is incredibly important“.
This Q* score functions as a query-independent, largely static measure of a site’s overall quality.
The P* signal, meanwhile, captures the popularity of websites by using Chrome browsing data and analysing the number of links (anchors) between pages.
These two pillars serve as foundational inputs that guide subsequent processes, including how frequently a site’s pages are crawled.
The Core Ranking and Serving Pipeline
Analysis of the leaked modules reveals a clear, sequential processing flow for how a document is scored, ranked, and ultimately presented to a user.
This pipeline consists of several key stages, each with its own set of priorities and signals.
Mustang: The Primary Scoring and Ranking System
At the heart of the initial ranking process lies a system named Mustang.
The documentation identifies Mustang as the primary engine responsible for the initial scoring, ranking, and serving of search results. This system is where the foundational, intrinsic qualities of a web page are evaluated.
Many of the traditional on-page SEO factors – such as the relevance of a title tag to a query, the originality of the content, and the presence of spam signals – are likely processed and scored within this core system.
A page’s journey through the ranking process begins here; a page must first qualify based on its fundamental on-page characteristics to even be considered for subsequent, more dynamic evaluations.
Topicality (T*): The ‘ABC’ of Relevance
The DOJ trial revealed that “Topicality” is a formal, engineered system within Google, designated as T*.
Its explicit function is to compute a document’s fundamental, query-dependent relevance, serving as a “base score” that answers the question: how relevant is this document to the specific terms used in this search query?
This T* score is composed of three core “ABC signals“:
- A – Anchors: This signal is derived from the anchor text of hyperlinks pointing to the target document. It confirms the enduring importance of descriptive anchor text as a powerful signal of what other pages on the web believe a document is about. Testimony clarified that this signal is derived purely from links between web pages and does not involve user click data.
- B – Body: This is the most traditional information retrieval signal, based on the presence and prominence of query terms within the text content of the document itself. Testimony from Google’s Vice President of Search, Pandu Nayak, emphasised that the words on the page – and where they occur in the page title, headings, and body text – are “actually kind of crucial” for ranking.
- C – Clicks: This signal is derived directly from user behaviour, specifically how long a user dwelled on a clicked-upon page before returning to the search results page (SERP). The inclusion of a direct user engagement metric at this foundational level of relevance scoring underscores the centrality of user feedback to Google’s core ranking logic.
These three signals are combined in what was described as a “relatively hand-crafted way” to generate the final T* score, allowing engineers to understand and adjust how each factor contributes to relevance.
NavBoost: The User Behaviour Re-Ranking System
Once Mustang has produced an initial set of rankings, a powerful re-ranking system called NavBoost comes into play.
The leak provides overwhelming confirmation of this system, which was previously alluded to in documents from the DOJ antitrust trial.
NavBoost is one of Google’s strongest and most influential ranking signals, and its function is to adjust the initial rankings based on vast logs of user behaviour data. The system is trained on a rolling 13-month window of aggregated user click data.
The documentation reveals that NavBoost operates on click and impression data from systems internally referred to as “Glue” (a comprehensive query log) and “Craps” (a system for processing click and impression signals).
This system doesn’t just count raw clicks; it analyses nuanced patterns of user engagement to determine satisfaction.
A page that performs well in Mustang’s content-based evaluation can be significantly promoted or demoted by NavBoost depending on how real users interact with it in the search results.
The QualityNavboostCrapsAgingData module further reveals that this click data is segmented into age-based buckets, such as lastWeekBucket and lastMonthBucket, showing that the system analyses user behaviour in the context of a document’s age. Read more about the Google Craps system.
This stage acts as a crucial validation layer, where the theoretical relevance of a page is tested against its demonstrated utility.
“Twiddlers”: The Final Editorial Layer
Following the initial scoring by Mustang and the user-behaviour adjustments by NavBoost, the leak reveals a final, powerful layer of the system known as “Twiddlers.”
These are re-ranking functions that provide Google with final editorial control over its search results. A Twiddler can adjust the score of a document or change its ranking entirely based on a specific set of criteria, acting as a final overlay to fine-tune the SERPs.
The documentation references several types of these re-ranking functions, illustrating their versatility:
FreshnessTwiddler: This function is designed to boost newer, more timely content for queries where freshness is a critical factor.QualityBoost: This Twiddler enhances the ranking of pages that exhibit strong quality signals, potentially amplifying the scores of content deemed highly authoritative or trustworthy.RealTimeBoost: This function likely adjusts rankings in real-time based on current events, breaking news, or emerging trends, ensuring that search results remain relevant to the immediate context.- Other Demotions: Twiddlers can also demote content for various reasons, such as having low-quality product reviews, mismatched links, or signals from the SERP that indicate user dissatisfaction.
This multi-stage architecture – Mustang for initial scoring, T* for relevance, NavBoost for user validation, and Twiddlers for final editorial adjustments – fundamentally alters the strategic calculus of on-page SEO.
It is no longer sufficient to optimise a page in isolation.
A successful strategy must consider the entire journey.
A page can be perfectly optimised with relevant keywords and structured content to achieve a high score from Mustang, but if users consistently click on it and immediately return to the search results, it will be demoted by NavBoost.
Similarly, a page that satisfies both Mustang and NavBoost could still be suppressed by a Twiddler if it’s in a sensitive niche like product reviews and is deemed to be of low quality.
Therefore, modern on-page SEO is not about achieving a single, static score; it is about ensuring a page successfully qualifies, is validated, and avoids demotion at each distinct gate in the ranking pipeline.
The Technical Backbone: Indexing, Tiers, and Document History
The leak provides a fascinating look into the very structure of Google’s index, revealing it is not a monolithic, flat database but a highly structured and tiered system designed for efficiency.
This architecture, managed by systems like Alexandria, SegIndexer, and TeraGoogle, has direct implications for how content is valued and accessed.
The index is arranged in tiers based on a document’s importance and update frequency.
The most critical, frequently updated, and regularly accessed content is stored in high-speed flash memory for rapid retrieval. Less important content is kept on solid-state drives, while rarely updated or accessed content is relegated to standard hard drives.
This tiered structure means that a page’s perceived quality and freshness can determine its physical placement within Google’s infrastructure, affecting how quickly it can be processed and served in rankings.
The URL as an Immutable Historical Record
This sophisticated storage system maintains an extensive historical record of the web.
The leak confirms that Google keeps a copy of all versions of every page it has ever indexed, with analysis suggesting it primarily uses the last 20 changes to a URL when analysing links.
This, combined with the documentHistory demotion for new URLs, underscores that changing a URL is a significant and costly action. See here for more on how to SEO URLs.
It potentially resets the page’s history, discarding the accumulated trust and forcing the new URL to start over.
This reinforces the critical importance of careful URL planning and the use of permanent (301) redirects when changes are absolutely necessary.
The URL as a Signal: Host Age, History, and Structure
The leaked documentation confirms that the ranking URL is far from a simple, passive address for a document. Instead, Google’s systems treat the URL and its host domain as an active source of signals that are evaluated for trust, history, context, and potential spam.
This analysis begins before the content of the page is even fully considered, establishing a foundational layer of trust – or distrust – that influences all subsequent evaluations
The Confirmed Existence of a “Sandbox”
For years, Google representatives have publicly and repeatedly denied the existence of a “sandbox” – a probationary period where new websites are temporarily suppressed in search results. The leaked documentation directly contradicts these statements.
Within the PerDocData module, the documentation details an attribute named hostAge.
Its description explicitly states that it is used “to sandbox fresh spam in serving time”. This is further supported by the registrationinfo attribute, which stores the creation and expiration dates of the domain, and the domainAge attribute, which tracks the age of the entire domain, reinforcing the concept of temporal trust.
This system is not a blanket penalty but appears to be a risk-management feature designed to observe a new host and prevent low-quality or spammy sites from achieving prominent rankings before they have established a track record.
The Penalty for Newness: documentHistory
This temporal evaluation extends beyond the host level to individual pages. The documentation references a demotion factor called documentHistory. This signal indicates that a “page without history, or a URL that is new to Search” will have its score negatively impacted.
This reveals a two-tiered system of temporal evaluation.
A brand-new website launching its first pages is subject to both the hostAge sandbox at the domain level and the documentHistory demotion at the page level. In contrast, a new page published on an established, trusted domain would bypass the hostAge filter but would still need to overcome the initial hurdle of the documentHistory demotion.
This structure suggests a “temporal trust” model where Google’s default state for any new digital asset – be it a host or a page – is one of inherent distrust.
Trust is not a given; it must be earned over time.
The mechanism for graduating from this probationary status is likely the accumulation of positive signals, such as a history of positive user engagement (goodClicks) and the acquisition of high-quality backlinks, which serve to validate the asset’s quality and utility.
The URL String as a Date Signal
Google’s systems actively parse the URL string itself for signals, particularly for date information. The leak identifies an attribute called syntacticDate and another called urldate, both of which are dates extracted directly from the URL or the page’s title.
This has significant strategic implications.
For example, publishing an article with the URL /blog/best-laptops-for-2024/ creates a permanent, unchangeable syntacticDate signal of “2024.”
While this may be beneficial in the short term, in subsequent years it can create a signal conflict if the content is updated.
An article updated for 2025 with a new byline date will still carry the immutable “2024” signal in its URL, potentially confusing freshness systems.
This provides a strong, data-backed argument for using evergreen URL structures that omit dates or other volatile keywords, thereby avoiding built-in signal conflicts and preserving the historical value of the URL over the long term.
In an AI-powered search ecosystem, these stable, descriptive URLs become even more critical, acting as a “Canonical Source of Ground Truth” that helps AI systems confidently connect a piece of content to a specific entity.
Anatomy of a Page: Core Content Attributes and Scores

While domain-level and user-behaviour signals are critically important, the foundation of on-page SEO remains the content and structure of the page itself.
The leaked documentation provides an unprecedented look into the specific attributes and scores that Google’s Content Warehouse uses to deconstruct, analyse, and evaluate the textual and structural elements of a ranking URL.
These features are likely primary inputs for the Mustang ranking system.
Title, Content, and Quality Scoring
The analysis of a page begins with its most fundamental elements: the title and the body content. The leak confirms several long-held SEO best practices and reveals new layers of sophistication in how content is scored.
- Title Tag Relevance (
titlematchScore): The documentation confirms the existence of atitlematchScore, which values how well the page title matches the user’s query. This is further supported by aBadTitleInfoflag, suggesting that Google’s systems actively identify and penalise poorly constructed titles. Further attributes likeoriginalTitleHardTokenCountandtitleHardTokenCountWithoutStopwordsshow a deep level of title analysis, counting the number of words (tokens) with and without common stopwords. This serves as direct evidence for the continued importance of precise and relevant keyword targeting within the<title>tag. Note your Title Link in Google is never guaranteed and is selected based on quality by the Google Goldmine system. - Content Originality and Length: Google employs a nuanced approach to evaluating content based on its length and uniqueness.
OriginalContentScore: For shorter pieces of content, the system uses anOriginalContentScore, which appears to be a score from 0 to 512 based on the content’s originality. This suggests that for concise content, uniqueness is a primary measure of quality. This process is supported by technical methods likeContentChecksum96to generate a fingerprint of the page’s content andshingleInfo, which breaks content into overlapping chunks to detect duplicates.- Document Truncation: The documentation indicates that the Mustang system has a maximum number of tokens (words and parts of words) that it will consider for a given document. This means that extremely long documents may be truncated, with the content at the end of the page potentially being ignored or given less weight. This reinforces the classic “inverted pyramid” writing style, where the most important information and keywords should be placed early in the content to ensure they are processed.
- Content Penalties: The system is armed with a battery of attributes to identify and penalise low-quality content at both the page and site level.
- Document-Level Spam: Attributes like
DocLevelSpamScore,SpamWordScore,gibberishScores, andkeywordStuffingScoretarget specific on-page violations. - Link-Based Spam: The system analyses anchor text for manipulation (
IsAnchorBayesSpam), measures the likelihood that a page links out to known spam sites (spamrank), and even scores links based on their age (ScaledLinkAgeSpamScore). - Site-Wide Spam: The SpamBrain system provides site-level spam scores (
spambrainData), indicating that a site’s overall spam profile can impact individual pages.
- Document-Level Spam: Attributes like
- Content Classification: Google doesn’t just score content for quality; it classifies it by type and purpose. The
commercialScoreattribute measures how commercial a document is, suggesting a distinction between informational and transactional content. Other attributes likensrIsVideoFocusedSite,porninfo, andTagPageScoreshow that Google identifies sites with a specific content focus (video, adult) and can devalue certain page types like low-quality tag pages.
A Deeper Understanding of Freshness and Updates
The leak reveals that Google’s understanding of “freshness” is far more advanced than simply looking at a publication date. The system uses a trio of attributes to build a comprehensive picture of a document’s timeliness, along with signals about significant updates.
BylineDate: This is the most straightforward signal – the date that is explicitly stated on the page.SyntacticDate: As discussed previously, this is a date that the system extracts from the URL string or the page’s title.SemanticDate: This is the most sophisticated of the three. It is a date derived from the content of the page itself. The system evaluates the information, sources, and data referenced within the text to determine if they are up-to-date relative to the broader corpus of information on the web about that topic.lastSignificantUpdate: This attribute tracks the timestamp of the last significant change to the document, allowing the system to differentiate between minor edits and substantial content revisions.richcontentData: In an even more granular analysis, this attribute stores information about what content was inserted, deleted, or replaced. This means Google’s systems can algorithmically determine the magnitude and nature of a content update, moving far beyond simple date-stamping.
This multi-faceted approach is a clear defence against “freshness spam,” where a publisher might simply change the content BylineDate without actually updating the content.
A true content freshness strategy must focus on updating the core substance of the information, not just the metadata.
Entity Association, Structure, and Presentation
Beyond the raw text, Google’s systems evaluate who wrote the content, how it is structured, and even how it is visually presented.
- Entity Association: The documentation confirms that Google explicitly stores author information and works to determine if an entity mentioned on the page is also the author of that page. This is part of a broader system of entity recognition, evidenced by the
webrefEntitiesattribute, which associates a document with known entities from Google’s Knowledge Graph. This indicates that Google is building connections between content and the real-world people, places, and things it discusses. - Document Structure (
pageregions): In a highly significant revelation, thepageregionsattribute indicates that Google’s systems encode the positional ranges for different regions of a document. This strongly implies that Google understands the structure of a webpage (e.g., header, footer, sidebar, main content) and likely weighs the content in each region differently. Words and links placed in the main body content are almost certainly valued more highly than those in a boilerplate footer. This structure is also critical for Passage Indexing and AI Overviews, as clear headings create distinct “chunks” of information that AI systems can easily extract and understand. - Multimedia and Rich Content: The system specifically analyses non-textual elements on a page. Attributes like
docImagesanddocVideosstore information about the images and videos embedded in a document. Furthermore, therichsnippetattribute stores the structured data (like Schema.org markup) extracted from the page, which is used to generate rich results in the SERPs. While thelongdescattribute was historically used for detailed image descriptions, it is now deprecated and should be avoided. See here for more on how to SEO your images and here for how to SEO Alt Text. - Font Size as a Weighting Signal: In a surprising but logical revelation, the documentation indicates that Google tracks the average weighted font size of terms within a document. This strongly suggests that words that are visually emphasised – through larger font sizes in headings (H1, H2, etc.) or through bolding – are given more weight in the content analysis process. See here for how to SEO your headings.
Page Experience and Technical Signals
The leak confirms that technical page experience signals are stored on a per-document basis, moving them from abstract best practices to concrete, measured attributes.
The voltData module contains page UX signals, while the desktopInterstitials attribute specifically targets and likely penalises the use of intrusive pop-ups on desktop devices.
The viewport meta tag is also a critical signal, essential for mobile-friendliness and a core part of the overall Quality (Q*) score.
This provides definitive evidence that a poor user experience, enforced through technical means, can be a direct negative factor for a page. Mobile seo should be your priority.

To synthesise these findings, the following table outlines the most critical on-page attributes revealed in the leak, their function, and their strategic implications for SEO.
The ‘Content Effort’ Signal: Quantifying Quality
Among the most strategically significant revelations from the leak is the existence of an attribute named contentEffort. This metric represents a sophisticated, machine-learning-driven attempt to quantify a previously abstract concept: the amount of human effort invested in creating a piece of content.
Defined in the documentation as an “LLM-based effort estimation for article pages,” contentEffort is a variable within the QualityNsrPQData module, placing it at the heart of Google’s page quality evaluation systems.
This attribute is not just another signal; it appears to be the technical foundation of Google’s “Helpful Content System” (HCS), which aims to reward content created for people and penalise content made primarily for search engines.
The contentEffort score seems to be calculated based on an assessment of the “ease with which a page could be replicated”.
Content that is generic, formulaic, or lacks unique insight can be easily reproduced by competitors or AI models and would likely receive a low contentEffort score.
Conversely, content that is rich with original research, expert interviews, custom visuals, and deep analysis is difficult and expensive to replicate, signalling a high-value, non-commoditised asset deserving of a higher score.
A low contentEffort score may act as a primary classifier for unhelpful content, potentially triggering the site-wide demotion associated with the HCS.
The User Is the Judge: Clicks, Chrome Data, and Quality Validation
Perhaps the most significant area where the leak exposed a chasm between Google’s public statements and its internal practices is the role of user engagement data in ranking.
For years, Google spokespeople have consistently downplayed or outright denied the use of clicks and other user behaviours as direct ranking signals, often framing them as useful only for evaluation or personalisation.
The documentation paints a very different picture, providing overwhelming evidence that user interaction data, collected from both search results and the Chrome browser, is a primary mechanism for validating and re-ranking content.
This reveals a two-part definition of quality within Google’s systems.
The first part is “potential quality,” which is determined by the intrinsic, on-page factors analysed by systems like Mustang.
The second, and arguably more powerful, part is “proven quality,” which is determined by how real users interact with the content.
A page can have perfect potential quality, but it will ultimately be demoted if it fails to achieve proven quality in the eyes of users.
Clicks vs. Quality: A Critical Distinction
A crucial revelation from the DOJ trial was Google’s caution against using raw click metrics as a proxy for quality.
Testimony revealed a “very strong observation that people tend to click on lower-quality, less-authoritative content” disproportionately.
This means that simply chasing the highest click-through rate can be misleading, as users are often drawn to “clickbait” over more trustworthy pages.
One engineer warned, “If we were guided too much by clicks, our results would be of a lower quality than we’re targeting”.
This confirms that while Google uses nuanced click signals like dwell time to refine relevance (via T* and NavBoost), it avoids using raw click volume as a direct measure of authority or quality.
Chrome Browser Data: The Proprietary User Panel
The leak also definitively confirms another long-debated topic: Google uses data from its Chrome browser to inform its ranking systems.
This gives Google a massive, high-fidelity, and proprietary panel of real user data that goes far beyond interactions on the search results page.
This is further corroborated by DOJ trial documents, which revealed the P* (Popularity) signal “uses Chrome data” to help quantify a page’s popularity.
Unlike data from Google Analytics, which is opt-in and can be blocked, Chrome data is collected at the browser level from a vast and representative sample of web users.
This provides an unfiltered view of a site’s overall popularity, engagement, and user experience. Key attributes revealed in the leak include:
chromeInTotal: An attribute that tracks the total number of views or visits a site receives from Chrome users, regardless of whether those visits originated from a Google search. This is a powerful measure of a site’s overall brand gravity and direct traffic.topUrl: The documentation indicates that Chrome click data is used to identify the most important or popular pages on a site. This information can then be used to power SERP features like sitelinks, which highlight a site’s key pages directly in the search results.
The use of Chrome data fundamentally elevates the importance of the total user experience. Google is not guessing about user engagement; it has a direct data feed.
This means that an on-page SEO strategy must extend beyond optimising a single landing page.
The entire site experience – from navigation to page speed to the quality of subsequent pages visited – is now a measurable input.
A site that users actively seek out, visit directly, spend significant time on, and return to frequently is building a positive data profile within Google’s systems, which can directly and positively influence its performance in organic search.
The goal of on-page SEO, therefore, expands to engineering a complete user journey that generates these positive signals.
The Site Authority Halo: How Domain-Level Factors Influence Your Page
The leak makes it unequivocally clear that a page does not rank in a vacuum.
Its potential for success is heavily influenced by a “halo effect” created by the authority, reputation, and overall quality of the domain on which it resides.
Google’s systems compute numerous site-wide signals that provide a foundational layer of trust, and this domain-level assessment acts as a powerful multiplier – or a limiting ceiling – on the performance of any individual piece of content.
siteAuthority is Real
For over a decade, the concept of “Domain Authority” has been a staple of the SEO industry, primarily through metrics developed by third-party tool providers like Moz.
Concurrently, Google officials have consistently muddied the waters around the existence of any such internal, single site-wide authority score.
The leaked documentation settles this debate. It confirms the existence of an attribute explicitly named siteAuthority.
While the exact formula for its calculation is not detailed, its presence as a stored attribute within the Content Warehouse is definitive proof that Google does, in fact, compute a site-level measure of authority.
This metric is a key input into the manifestation of the Q* (Quality) score revealed during the DOJ trial, which functions as a site-level measure of quality and trustworthiness.
This score likely synthesises a variety of signals, including the quality and quantity of the site’s backlink profile, its historical performance, and user engagement metrics, into a single, overarching score representing the domain’s credibility.
The Anatomy of Site Quality: Deconstructing the Q* Score
The QualityNsrNsrData module, referenced throughout the leak, appears to be the technical home for many of the component signals that make up the site-level Q* score.
This module provides a granular view of how Google algorithmically assesses a site’s overall quality, moving far beyond simple link metrics. Key attributes include:
- Content-Based Quality (
tofu): This attribute is described as a “site-level tofu score,” which acts as a quality predictor based on the site’s content. This suggests a site-wide roll-up of content quality signals. - User Experience Penalties (
clutterScore): This is a direct penalty applied to sites that have a large number of “distracting/annoying resources.” This confirms that a poor user experience, characterised by excessive ads or pop-ups, can result in a site-level quality demotion. - Editorial Boosts (
smallPersonalSite): In a fascinating revelation, this attribute provides a promotional score for small personal sites or blogs. This indicates an editorial decision to boost a certain type of content that might otherwise struggle to compete on traditional authority metrics. - User-Generated Content (
ugcScore): This score is specifically designed to evaluate sites with significant user-generated content. A high score likely indicates a well-moderated and high-quality community, while a low score could signal spam or low-value contributions. - User Behaviour Signals: The module reinforces the importance of user data by including site-level metrics like
chromeInTotal(total views from Chrome),directFrac(the fraction of direct traffic), andimpressions, confirming that brand gravity and user engagement are core components of the Q* score.
Homepage PageRank and Brand Signals
The concept of PageRank, Google’s original link-based authority algorithm, is still very much alive within the ranking systems. The leak reveals a particularly interesting implementation: the PageRank of a site’s homepage is associated with every single document on that site.
The documentation references multiple versions of PageRank, including the now-deprecated toolbarPagerank, underscoring the concept’s long evolution and continued relevance.
This has a profound effect on new content.
A new page published on a high-authority site, like The New York Times, does not start with zero authority.
It inherits a baseline level of trust and authority from the homepage’s powerful PageRank score.
Conversely, a new page on a brand-new domain starts with a very low baseline.
This homepage PageRank likely serves as a proxy score for new pages until they have had enough time to accrue their own specific signals (like direct links and user engagement data).
This concept of internal authority is further reinforced by the onsiteProminence attribute.
This feature measures the importance of a specific page within its own site. It is calculated by simulating the flow of traffic from the site’s homepage and other pages that receive a high number of clicks.
This confirms that a page’s authority is not just determined by external links, but also by its prominence in the internal linking structure, effectively creating an internal PageRank that boosts key pages.
Google Search is explicitly designed to recognise and reward brands. The documentation contains several attributes that measure brand strength:
siteNavBrandingScoreandsiteNavBrandQualityScore: These attributes appear to measure how effectively a site communicates its brand identity through its navigation and overall presentation.navBrandWeight: This attribute suggests that click data from the NavBoost system is weighted differently for navigational (branded) search queries. This means a user searching for “Hobo SEO” and clicking on the Hobo-web.co.uk result sends a much stronger positive signal than a click on a non-branded query. This authority is also codified through thequeriesForWhichOfficialattribute, which flags a specific page as the official result for a given query, country, and language, solidifying its status as the definitive source.sitemap: Interestingly, this attribute does not refer to XML sitemaps but to the algorithmically generated sitelinks that appear under a main search result. The fact that Google stores this information with the document indicates it has a clear, data-driven understanding of a site’s most important navigational pages.
These findings demonstrate that a page’s potential is intrinsically capped by its domain’s authority.
On-page optimisation of an individual article can only achieve so much if the underlying domain is perceived as having low authority.
This confirms that a successful SEO strategy cannot be a purely page-level endeavour. It requires a dual focus: first, creating excellent, well-optimised individual pages, and second, simultaneously executing domain-level initiatives designed to raise the site’s overall siteAuthority.
These initiatives include building a high-quality backlink profile to the homepage and other core pages, fostering positive site-wide user engagement, and investing in brand-building activities that encourage direct traffic and branded searches.
Raising the domain’s authority is like raising the tide- it lifts all the content “boats” on that site.
Editorial Overlays: Whitelists and Sensitive Topics
Beyond the fully automated algorithmic signals, the leak confirms the existence of explicit editorial overlays, particularly for sensitive or critical topics.
This reveals a layer of semi-manual control where Google pre-determines which sources are eligible to rank for certain types of queries.
The documentation contains attributes such as isElectionAuthority and isCovidLocalAuthority, which function as whitelists for domains deemed authoritative on topics like elections and public health. During the COVID-19 pandemic and major elections, these systems were likely used to elevate information from official government and health organisations while suppressing other sources.
While intended to combat misinformation, the existence of these whitelists confirms that for certain “Your Money or Your Life” topics, ranking is not a purely meritocratic process based on SEO signals alone, but is subject to an additional layer of editorial approval.
E-E-A-T as a Guiding Principle for Quality
The concepts revealed in the leak, such as contentEffort and siteAuthority, do not exist in a strategic vacuum.
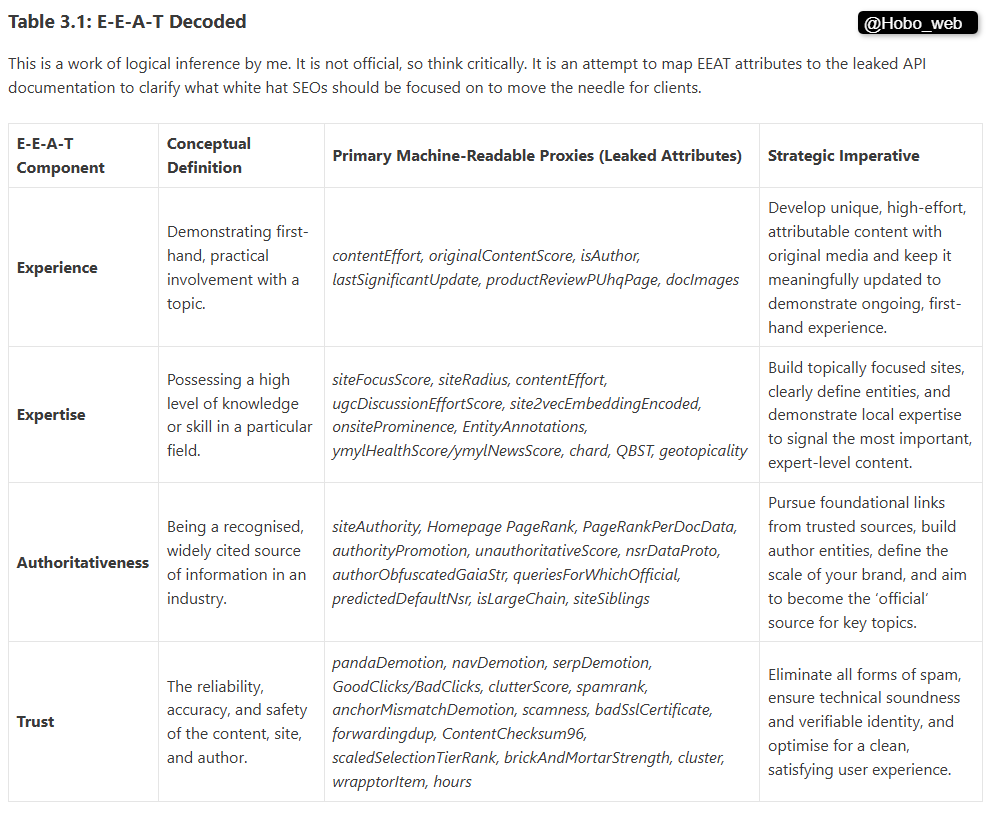
They are the technical implementation of a broader philosophical framework that Google has been promoting for years: E-E-A-T, which stands for Experience, Expertise, Authoritativeness, and Trustworthiness.
Originating from Google’s Search Quality Rater Guidelines (QRG), E-E-A-T is the codified approach human evaluators use to assess the quality and reliability of content, and their ratings are used to train Google’s core AI ranking models.
- Experience: This pillar values content created by someone with demonstrable, first-hand experience. A product review from someone who has actually used the product is valued more highly. The recent addition of “Experience” to the framework is seen as a direct response to the rise of AI-generated content, which cannot possess genuine experience.
- Expertise: This refers to the creator’s depth of knowledge and skill in a particular field.
- Authoritativeness: This measures the reputation of the creator, the content, and the website as a whole.
- Trustworthiness: This is the foundation of the framework, encompassing the accuracy, transparency, and security of the content and the site.
The leaked attributes provide a direct mapping to these principles.
contentEffort and OriginalContentScore are algorithmic measures of the effort, talent, and originality that are hallmarks of Expertise.
The author attribute and the siteAuthority score are direct measures of Authoritativeness and Trustworthiness.
Therefore, a successful on-page strategy should use the E-E-A-T framework as a guide to create content that will naturally align with the technical signals Google is now confirmed to be measuring.
The Disconnected Entity Hypothesis
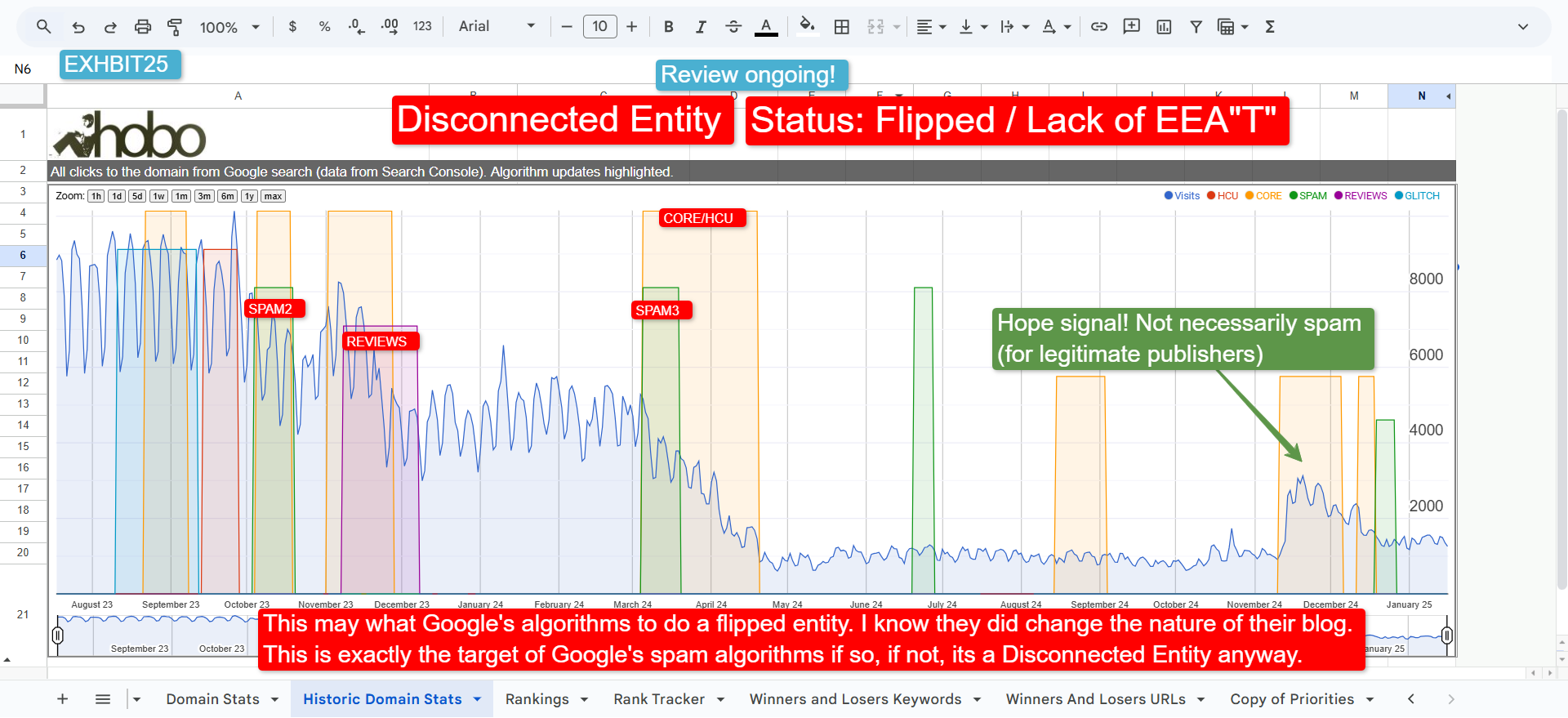
The “Disconnected Entity Hypothesis” attempts to explain why some sites with seemingly high-quality content fail to perform well, particularly after Google’s Helpful Content and Spam updates.
The theory posits that Google algorithmically demotes sites that lack sufficient transparency and trust signals connecting them to a credible, real-world entity
These sites are “disconnected” because Google cannot verify who is behind the content, triggering algorithmic distrust.
A lack of clear ownership, author information, and contact details are primary signals of a disconnected entity.
This aligns with Google’s emphasis on Trust as the most critical component of E-E-A-T and suggests that without a foundation of verifiable identicalness, even well-written content may be classified as unhelpful.
A Unified On-Page Strategy: Key Principles from the Content Warehouse
The 14,014 attributes detailed in the Content Warehouse API documentation provide a complex and sometimes overwhelming picture of Google’s inner workings.
However, synthesising the most salient findings reveals a coherent and actionable strategic framework for modern on-page SEO.
This framework moves beyond checklists and tactics to embrace a set of core principles grounded in the newly revealed architecture of Google’s ranking systems. I do have this in a free checklist if you want it.
For years, Google’s public advice to “focus on the user” and “create great content” often felt vague and disconnected from the technical realities of SEO.
The leak bridges this gap, revealing the specific, quantifiable metrics Google uses to measure exactly those things. It vindicates a holistic, user-centric model of SEO by showing that metrics like goodClicks, lastLongestClicks, chromeInTotal, siteAuthority, and contentEffort are the engineering proxies for user satisfaction, brand trust, and content value.
The most sustainable on-page strategy is no longer about attempting to please a secretive machine, but about demonstrably satisfying a now-quantifiable human user.
Principle 1: Optimise for the Pipeline, Not Just the Page
The most significant strategic shift required is to move from a static, page-centric view of optimisation to a dynamic, process-oriented one.
The existence of the Mustang -> NavBoost -> Twiddlers pipeline means that on-page SEO is a multi-stage qualification process.
- Actionable Strategy: Content must be created to satisfy two distinct audiences in sequence. First, it must be technically sound, topically relevant, and clearly structured to pass the initial machine-based evaluation of systems like Mustang. Second, and more importantly, it must be genuinely useful, engaging, and satisfying to a human user to generate the positive click signals required to pass the NavBoost validation stage.
Principle 2: Build Temporal Trust
The confirmation of the hostAge sandbox and the documentHistory demotion proves that trust is a function of time. New assets are treated with inherent suspicion.
- Actionable Strategy: For new websites and new pages, the initial strategic goal should not be to rank for competitive terms immediately. Instead, the focus should be on “graduating” from this probationary phase. This involves consistently publishing high-quality, topically focused content and accumulating positive signals—such as social shares, niche backlinks, and, most importantly, positive user engagement data—that demonstrate the asset’s value and trustworthiness over time. Patience is a structural requirement.
Principle 3: Pursue Information Density and Semantic Freshness
The documentation shows a preference for content that is both original and information-rich, while also being current in its substance, not just its timestamp.
- Actionable Strategy: Content should be concise enough to avoid truncation by the Mustang system’s token limit, ensuring key information is presented early. For shorter pieces, the focus must be on extreme originality to achieve a high
OriginalContentScore. For all content, freshness strategies must evolve. Instead of simply updating theBylineDate, the core focus must be on updating the facts, sources, and data within the content to satisfy theSemanticDateandrichcontentDataevaluations.
Principle 4: Engineer for “Good Clicks”
With the confirmation of NavBoost and its reliance on click patterns, the user’s interaction with the search result snippet becomes a critical on-page concern. The goal is not just to earn a click, but to earn a “good click.”
- Actionable Strategy: The page title and meta description are the primary tools for setting user expectations. They must be crafted not only for keyword relevance but also for accuracy and value proposition. The objective is to attract a click from a user whose intent genuinely matches the content, thereby maximising the probability of a long dwell time (
lastLongestClicks) and minimising the chance of a quick bounce-back to the SERP, which would generate negative signals likebadClicksandSERP Demotion.
Principle 5: Cultivate Topical and Site-Level Authority
A page’s success is inextricably linked to the authority of its domain. The leak confirms this through attributes like siteAuthority, homepage PageRank inheritance, and siteFocusScore.
- Actionable Strategy: On-page SEO must operate on two parallel tracks. At the page level, every piece of content should be tightly aligned with the site’s core topic to reinforce its
siteFocusScore. At the domain level, a continuous effort must be made to increase the overallsiteAuthority– topical authority – by improving the inputs to the Q* score – such as reducing on-site clutter, managing UGC quality, and fostering a positive overall user experience that drives direct engagement (measured viachromeInTotal). This domain-level work raises the foundational authority from which all individual pages can benefit.
Read next: The Definitive Guide to SEO Audits after the Google Leak.
Read next
Read my article that Cyrus Shephard so gracefully highlighted at AHREF Evolve 2025 conference: E-E-A-T Decoded: Google’s Experience, Expertise, Authoritativeness, and Trust.

The fastest way to contact me is through X (formerly Twitter). This is the only channel I have notifications turned on for. If I didn’t do that, it would be impossible to operate. I endeavour to view all emails by the end of the day, UK time. LinkedIn is checked every few days. Please note that Facebook messages are checked much less frequently. I also have a Bluesky account.


You can also contact me directly by email.
Disclosure: I use generative AI when specifically writing about my own experiences, ideas, stories, concepts, tools, tool documentation or research. My tool of choice for this process is Google Gemini Pro 2.5 Deep Research (and ChatGPT 5 for image generation). I have over 20 years writing about accessible website development and SEO (search engine optimisation). This assistance helps ensure our customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was conceived, edited, and verified as correct by me (and is under constant development). See my AI policy.