QUOTE: “Back in 2018, I was reading the official Hobo Web site while commuting, on the metro, bus, at work, or the gym. The clarity and depth of information there kept me going, especially after losing over 3,000 websites due to the August 1st, 2018 Google update… One day, while browsing Hobo Web, I came across a link to SEO by the Sea. I clicked on it and that moment changed my life. Today, I lead a community of over 50,000 members and run a private course with 2,500 students. All of this was made possible thanks to two foundational resources: Hobo Web and SEO by the Sea. That’s why Shaun Anderson and Bill Slawski have always been the lighthouses of my SEO journey.” Koray Tuğberk GÜBÜR @KorayGubur 2025
And look what happened to that guy!
In fact, Koray also gave me one of my favourite mentions:
Shaun Anderson; I also suggest you to follow him. He doesn’t share so much things on Twitter but hobo webco uk is one of the greatest places that you can actually learn real seo and i am not talking about like five quick hacks that you can do or i’m not talking about six shortcuts tips blah blah not these type of idiotic titles they won’t appear there and you won’t have popular seo names here you will have real world research. Boring things but real things and here i have written without I wouldn’t have found my own company.” – Koray Tuğberk GÜBÜR, 2022
Thank you, Koray.
During Lockdown, by the way, dear reader, it was a younger Koray (amongst few others) who even kept me half interested in SEO. I always knew (the basics) of what he legitimately made his name synonymous with, I’m sure: Topical Authority. It has been nice to revisit the topic.
Read on if you want to learn SEO the same way I did, starting back in 2000. It’s the path that experts like Koray Tuğberk GÜBÜR and so many others followed, all of us learning from the late Bill Slawski and other SEO legends. For nearly 20 years, I’ve had the pleasure of documenting this approach on the Hobo SEO blog.
For those 20 years, SEO has been an art and science (I use that term loosely) of inference, a practice of observing the shadows on the cave wall to deduce the shape of the object casting them.
SEOs like myself pored over every cryptic clue from Googlers who would throw a bone to those who could listen and think critically – I mean, no wonder!
But the landmark combination of sworn testimony from the U.S. Department of Justice v. Google trial and the accidental publication of Google’s internal Content Warehouse API documentation has transformed the black box into a blueprint.
For practitioners like myself who have spent 25 years working from the evidence available, this moment is nothing short of a Rosetta Stone; it provides the canonical, engineered reality behind the theories we have carefully constructed.
These revelations have given us the foundational data object for every URL in the index: the CompositeDoc.
This “master record” is the top-level protocol container that aggregates all known information about a single document.
Nestled within it is the most critical component for strategic analysis, the PerDocData model – what I’ve come to call the comprehensive “digital dossier” or “rap sheet” that Google maintains on every URL it indexes.
Understanding this architecture is no longer an academic exercise; it allows us to align our strategy directly with the core logic of the index itself.
This article deconstructs this newly visible architecture, revealing a fundamental, engineered split between two core evaluation systems.
- The first assesses Query-Independent Authority (Q), answering the question, “Is this source trustworthy?”.
- The second calculates Query-Dependent Relevance (Topicality, or T), answering the question, “Is this document relevant to this specific query?”.
By dissecting the specific, measurable attributes that feed these systems, this report provides a definitive, evidence-based framework for mastering Topical Authority by systematically building a perfect CompositeDoc that excels at every level of Google’s evaluation.
Part 1: Deconstructing Google’s Two Core Ranking Systems
Google’s ranking is not a single, monolithic algorithm but a sophisticated, multi-stage pipeline that interrogates the CompositeDoc and its nested PerDocData module for every URL.
This process is engineered to answer two fundamental questions that form the bedrock of search quality: “Is this document trustworthy?” and “Is this document relevant?”. The answers are calculated by two distinct, yet interconnected, macro-systems: the Authority System (Q*) and the Relevance System (T*).
A. The Authority System (Q*): A Multi-Layered Assessment of Quality
This system assesses the inherent, query-independent authority of a website. It is the modern, continuously updated evolution of the site-level quality assessments pioneered by the Google Panda update.
Q* is a slow-moving, persistent reputation metric that acts as a foundational quality score for a domain and its pages.
The public-facing name for the enforcement of these principles is the Helpful Content System (HCS), but the underlying machinery is the Q* system. E-E-A-T is not a single score but an emergent property of the dozens of granular signals that make up a site’s Q* profile, which are now, for the first time, visible to us.
1. The Foundational Score & Algorithmic Momentum (predictedDefaultNsr)
At the very heart of the Q* system is a baseline quality and trust score known as predictedDefaultNsr, or Normalised Site Rank.
This attribute functions as the default quality assessment for a URL, a head start (or handicap) granted before it has even had a chance to accumulate extensive user engagement data. Crucially, the documentation defines this attribute as a VersionedFloatSignal, a technical detail with profound strategic implications.
The term VersionedFloatSignal explicitly confirms that Google does not just store a page’s current quality score; it maintains a historical record of that score over time.
This transforms a static quality snapshot into a time-series dataset.
Consequently, a site’s quality trajectory – whether it is consistently improving, remaining stable, or declining over months and years – becomes a powerful meta-signal in its own right.
This creates what can be described as “algorithmic momentum“.
A website with a long and consistent history of high-quality signals, as recorded in its versioned predictedDefaultNsr, builds positive momentum.
This acts as a tailwind, making the site more resilient to minor quality fluctuations and algorithm updates, and significantly harder for newer competitors to dislodge.
Conversely, a site with a history of low-quality signals carries a negative momentum that must be overcome through sustained, long-term investment in quality.
This technical reality confirms that SEO is a long game; short-term tactics are strategically flawed because they fail to build the positive historical trajectory that underpins algorithmic trust.
2. Content Quality, Effort, and Integrity
The Q* system contains a suite of specialised signals designed to provide a multi-dimensional view of a page’s content, evaluating it based on the effort of its creation, its originality, and its fundamental integrity.
- contentEffort: Perhaps the most significant revelation for content strategy, this attribute is defined as an “LLM-based effort estimation for article pages“. It is the technical lynchpin of the Helpful Content System, representing a direct attempt to algorithmically quantify the human labour, resources, and intellectual investment in a piece of content. A key function of this score appears to be an assessment of the “ease with which a page could be replicated”. Content that is formulaic, generic, or lacks unique insight can be easily reproduced by competitors or AI models and thus receives a low score. Conversely, content rich with original data, expert interviews, custom visuals, and deep analysis is difficult and costly to replicate, signalling a high-effort, non-commoditised asset worthy of a high ranking.
- OriginalContentScore: This attribute is a direct legacy of the Panda update, designed to measure the uniqueness of a page’s content. It specifically targets and combats thin, templated, or duplicative text, rewarding pages that introduce new information to the web corpus rather than simply summarising existing sources.
- chard: While its exact function is not fully detailed, its placement alongside other specialised classifiers like ymylHealthScore and ymylNewsScore strongly suggests chard acts as a multi-purpose content integrity predictor. Its primary role is likely as an initial classifier that determines if content falls into a sensitive Your Money or Your Life (YMYL) category. Triggering this classifier ensures that the content is subjected to a much stricter set of evaluation standards, where signals related to trust and authoritativeness are given significantly more weight (although this would all need further analysis).
For years, E-E-A-T has been discussed as an abstract concept for human raters. These leaked attributes reveal the engineered components Google uses to translate that framework into a scalable, machine-readable system.
- contentEffort provides a measurable proxy for “Expertise” and “Experience.”
- OriginalContentScore algorithmically assesses a key component of “Authoritativeness.”
- And the chard classifier identifies content where “Trust” is paramount.
Optimising for E-E-A-T is therefore no longer a conceptual exercise; it is about creating content that demonstrably scores well on these specific, measurable attributes.
3. Freshness and Timeliness
Google’s assessment of freshness is far more sophisticated than simply reading a publication date. The leak confirms a nuanced system designed to reward genuine content improvement while resisting manipulation.
- lastSignificantUpdate: This timestamp is the system’s core mechanism for differentiating between minor edits (like fixing a typo) and substantial content revisions. A page’s freshness clock is only reset if the changes made are deemed algorithmically “significant,” a determination likely made by comparing document versions and calculating a change-score. This confirms that simply changing a byline date without making meaningful updates is an ineffective tactic.
- semanticDateInfo: This attribute stores confidence scores for dates that are derived semantically from analysing the content’s meaning. Google’s Natural Language Processing can identify the temporal context of the text itself. Suppose a publisher manipulates a byline date to appear current, but the article’s text discusses events from several years ago in the past tense. In that case, the system will trust the semantic interpretation, effectively overriding the deceptive timestamp.
These signals feed into re-ranking systems called “Twiddlers.”
Specifically, the FreshnessTwiddler is a re-ranking function that boosts timely content for queries that deserve it.
This reveals a gated, two-factor system for freshness.
First, an update must be “significant” enough to trigger the lastSignificantUpdate signal.
Second, that signal only provides a ranking benefit when the query is one that Google has identified as deserving fresh results (a concept known as QDF, or “Query Deserves Freshness”).
The strategic imperative is not to update everything constantly, but to identify QDF-sensitive topics and focus significant update efforts there.
4. Semantic and Topical Understanding
Google’s understanding of topics has evolved far beyond keywords to a mathematically precise model of concepts and their relationships. This is the technical foundation of Topical Authority.
- EntityAnnotations: This module attaches specific Knowledge Graph entities (internally referenced as webrefEntities) to the page’s content. This allows Google to move beyond ambiguous strings of text and understand the real-world people, places, and concepts a page is about.
- site2vecEmbeddingEncoded: This attribute is a compressed vector embedding – a numerical representation – of an entire site’s content. This is the technical engine that allows Google to mathematically measure a site’s overall theme and compare it to other sites. This embedding is the foundation for two critical metrics that quantify topical authority.
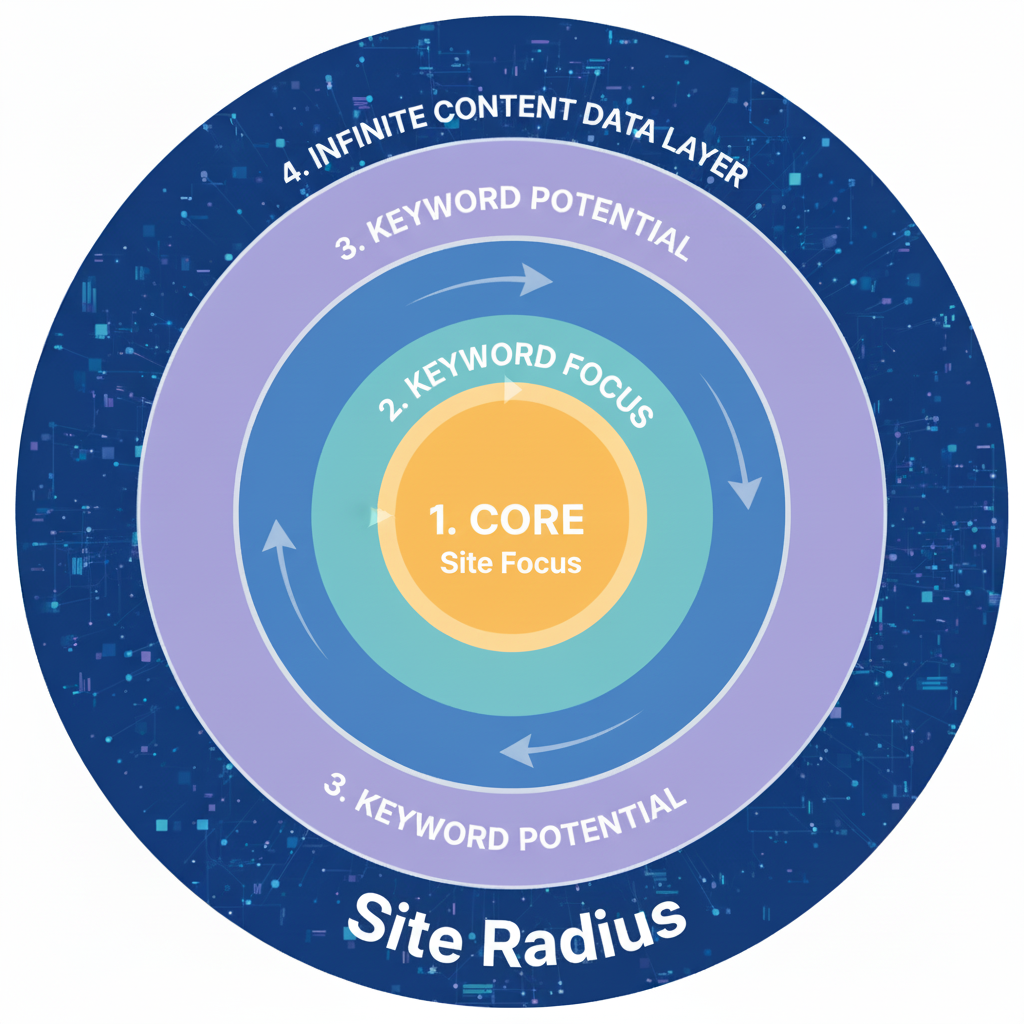
- siteFocusScore: This score quantifies how dedicated and focused a site is to a specific topic. A high score indicates a specialist site, while a low score suggests a generalist or unfocused one.
- siteRadius: This metric measures how much an individual page’s content deviates from the site’s central theme, as established by the siteFocusScore. A page with a low siteRadius is closely aligned with the site’s core topic, while a high siteRadius indicates a topical outlier.
- asteroidBeltIntents: While not fully detailed in the leak, the name of this system strongly implies a highly granular model for document intent classification. It suggests Google assigns multiple, specific intent scores to a single page, moving far beyond simple informational, commercial, or transactional labels into a much more complex and multi-faceted understanding of what a user might want to accomplish on that page.
These attributes confirm that “Topical Authority” is not an abstract concept but the measurable outcome of a mathematical calculation.
A site demonstrates topical authority by achieving a high siteFocusScore and ensuring that all of its important content has a low siteRadius.
This makes actions like pruning or improving off-topic content a direct and measurable way to strengthen a domain’s calculated authority.
4.1 Topical Authority: Deconstructing Site Radius, Focus, and Quality
The leaked Google documentation has confirmed that “Topical Authority” is not an abstract concept but the result of a precise mathematical model.
This system evaluates a website’s content to determine its thematic focus, but it’s crucial to understand that this calculation is distinct from the assessment of its overall quality and trustworthiness.
The foundation of this topical analysis rests on a few key attributes, primarily siteRadius, siteFocusScore, and the underlying site2vecEmbeddingEncoded technology.
4.2 The Solar System Model: siteRadius and siteFocusScore
The easiest way to understand these concepts is through an analogy: think of your website as a solar system.
- Your site’s core topic is the Sun ☀️.
- Each page on your site is a planet.
In this model, the two key metrics work together:
siteRadiusis the orbit of an individual planet. It measures how much a single page’s content deviates from the site’s central theme (the Sun). A page that’s highly relevant has a tight, close orbit, signifying a lowsiteRadius. A page that’s off-topic is like a distant planet in a wide, eccentric orbit, signifying a highsiteRadius.siteFocusScoreis the measurement of the entire solar system’s coherence. It’s the site-wide aggregation of all the individualsiteRadiusmeasurements. A site with a high score is like a tightly packed, orderly solar system where every planet has a lowsiteRadius. A site with a low score is a scattered, unfocused system with planets all over the place. The underlying technology that defines the “gravity” of this system and allows Google to measure its shape issite2vec.
4.3 Visualise a Site’s Topical State with Marbles
We can visualise different states of topical health using this framework using marbles. The green areas represent content with a low siteRadius (close to the core topic), while orange and red represent content with a high siteRadius (topical outliers).
Perfect Topicality: The ideal for a niche authority site. It would have a very high siteFocusScore because every single page has a low siteRadius. All the pages are related. Google will be sure what your next article is going to be about.

High Focus with Topical Drift: A common state for a strong site that has a few off-topic posts. These outlier pages have a high siteRadius and, if numerous enough, can begin to lower the overall siteFocusScore. Trim off-topic pages from the site unless they are picking up high-quality links.
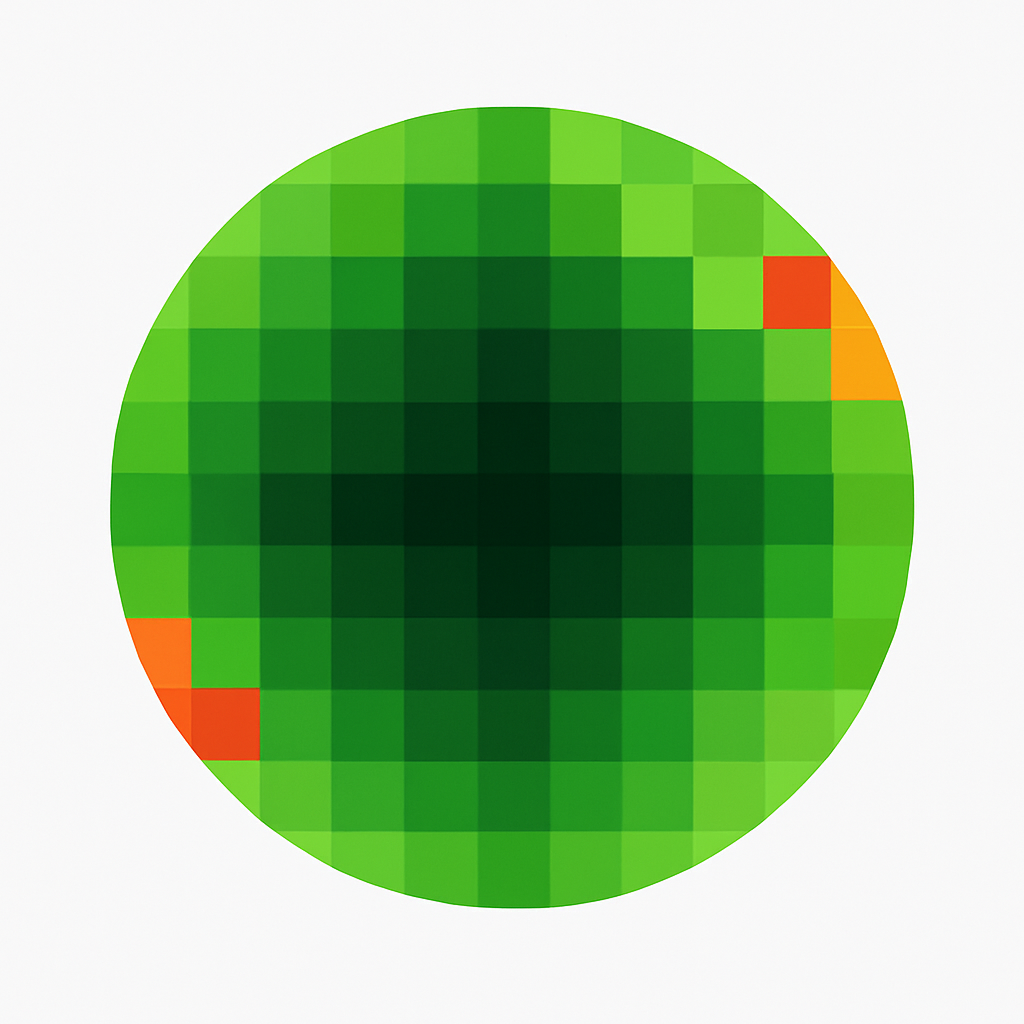
Generalist Site with a Niche Core: This site has a core of expertise, but it’s diluted by a large amount of tangentially related content with a high siteRadius. This wide radius of content significantly lowers the overall siteFocusScore. These sites do not look like the niche sites Google wants for a lot of keywords. A site whose pages perform poorly for everything ranks for nothing.

Fragmented Authority: Represents a site trying to be an expert in two distinct topics. This creates a confusing mathematical identity (site2vec) and a low siteFocusScore, as there is no single “sun” for the system to orbit. This could be a hack, or someone in your office linking your site to their gambling sites (I jest), or you suddenly publishing completely off-topic content.
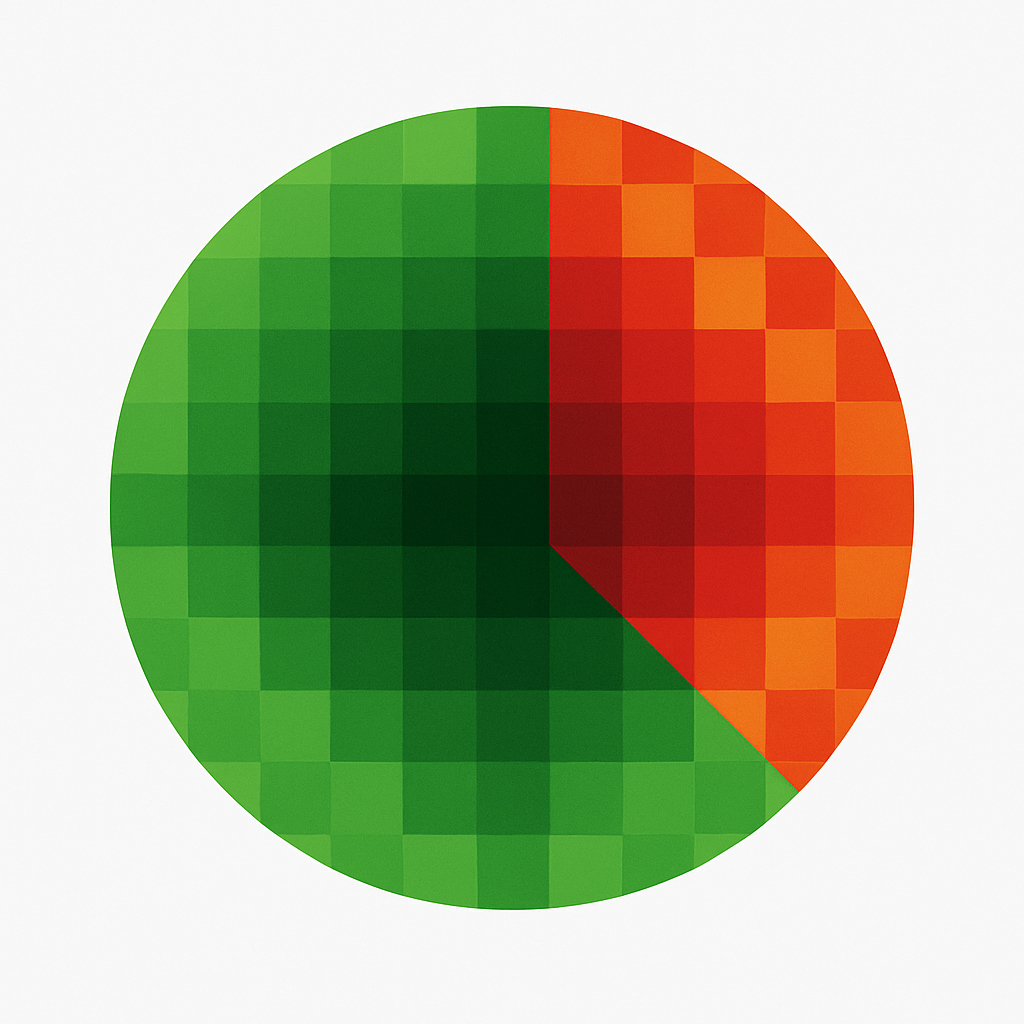
The visual metaphor can also be extended to page quality or link building.
If you don’t have the authority, you would do well to focus on your own topic of expertise in future.
And go deep! There is an infinite content data layer crammed with information with your name on it. Really.
I call it the Infinite Synthetic Content Data Layer, and I call the art of mining it “Inference Optimisation“.
Get links and visitors off green marbles!
4.4 The Crucial Distinction: Topical Focus ≠ Site Quality
A common mistake is to equate a high siteFocusScore with a high-quality site. These are two separate assessments.
The New York Times is a perfect example. It’s a pinnacle of site quality in Google’s eyes, with immense authority and trust. However, it is a generalist site, not a topically focused one. It covers hundreds of subjects. Its site2vec pattern is that of a “trusted major news portal,” which is a known, high-quality pattern, but it would not have a high siteFocusScore in the way a niche site would.
Conversely, you could create a website entirely focused on a single, obscure topic. Every page could have a very low siteRadius, resulting in a nearly perfect siteFocusScore. However, if the content is thin, untrustworthy, and has no backlinks, Google will still see it as a very low-quality site.
4.5 The Outlier Effect: When Bad Focus Becomes a Quality Problem
While focus and quality are measured separately, a severely confused topical structure can indirectly harm your site’s perceived authority. Google’s systems are built on pattern recognition.
They have learned the mathematical patterns of what trustworthy sites in various categories look like.
A site with a strange topical mix – like a blog that is 50% about vegan baking and 50% about heavy metal repair – becomes a mathematical outlier.
It doesn’t fit the known pattern of a trusted food blog or a trusted industrial repair site. Because it’s hard to classify, it may be harder for Google to trust, indirectly impacting its ability to rank even for its core topics.
You can extrapolate that particular example to your own niche.
4.6 Topical Cohesion
This video was a response to the article you are reading. Its core argument – aiming to “tweak my verbage” – is that “Topical Cohesion” is a practical, designable SEO strategy that is more effective and controllable than the vague, often misunderstood concept of “Topical Authority.”
The host, Carolyn Holzman, argues that “Topical Cohesion” (which she relates to the terms siteFocus and siteRadius I shared from the Google leak. is the key to signalling relevance to Google’s systems, whereas “authority” is something that is “conferred” by others and cannot be directly built.
I agree with this verbage tweaking so much, I am using it myself in some recent docs. I think it does well to help visualise the difference between topical authority and topical cohesion from a strategic point of view.
This is good advice, I elected to add to the article.
5. Trust & Safety Signals
A robust suite of attributes forms the “Trust” pillar of E-E-A-T, functioning primarily as a liability model where negative signals can suppress the performance of an entire domain.
- Content and Link Integrity: This includes a variety of signals that act as trust liabilities. Attributes like scamness, GibberishScore, and urlPoisoningData are used to identify and penalise deceptive or nonsensical content. A crucial signal is spamrank, which measures the likelihood that a document links out to known spam sites, penalising pages that associate with bad link neighbourhoods.
- Page Experience and Clutter: A newly revealed and highly impactful signal is clutterScore. This is a site-level signal that algorithmically measures on-page clutter from ads, pop-ups, and other intrusive elements. Because it is calculated at the site level, aggressive monetisation and a poor user experience on one section of a site (such as an old, neglected blog) can contribute to a negative clutterScore that suppresses the ranking potential of the entire domain, including its high-quality pages (because penalties can be smeared across an entire set of URLs).
Building trust is therefore as much about diligently auditing for and removing these negatives as it is about adding positives.
A comprehensive trust strategy must include regular audits for outbound link quality, on-page ad experience, and other potential trust liabilities across the entire domain.
| Table 1: Key Leaked Authority (Q*) Attributes and Their Strategic Implications | ||
| Attribute Name | Definition & Function | Strategic SEO Action |
| predictedDefaultNsr | A versioned, historical baseline quality score for a URL. | Implement a long-term, consistent content quality and site maintenance programme to build positive “algorithmic momentum.” |
| contentEffort | An LLM-based estimation of the human labour invested in creating a page. | Shift content budgets from volume to value. Invest in original research, unique data, and custom multimedia that is difficult to replicate. |
| siteAuthority | A holistic, site-wide quality score, the modern evolution of Panda. | Conduct site-wide audits to prune or improve all low-quality, low-engagement pages, as they can suppress the entire domain’s authority. |
| clutterScore | A site-level penalty for on-page ad clutter and poor user experience. | Audit and rationalise ad placements across the entire site, especially on older content, to avoid a site-wide penalty. |
| onsiteProminence | A measure of a page’s internal importance based on simulated traffic flow. | Develop a strategic internal linking architecture that funnels authority from prominent pages (e.g., the homepage) to important target pages. |
5.1 Revisiting PageRank: Prominence, Trust, and Sculpting
PageRank is the foundational algorithm that started it all, but its modern implementation is far more sophisticated than the simple idea of “link juice.”
While the core principle of using links as votes remains, the system now deeply integrates concepts of internal site structure, trust, and neighbourhood quality. The leaked documentation gives us specific insight into attributes that are crucial to understanding modern PageRank: onsiteProminence and spamrank.
5.2 Internal Prominence: Heating Up Your Pages
For years, SEOs have focused on how external links pass authority.
However, the onsiteProminence attribute confirms that Google meticulously maps how authority flows within your own website. To understand this, my metaphor of “Links as Lasers.”
Think of your powerful pages (like the homepage) as power sources .
Your internal links are not pipes that spill water everywhere; they are lasers ⚡ that direct that energy with precision. You cannot point the laser everywhere at once; you must choose your targets.
- Heating Up a Page: When you focus multiple lasers (internal links from powerful pages) onto a single target page, you concentrate energy and authority on it. This process “heats the page up,” signalling its importance to Google and significantly boosting its
onsiteProminence. - Cold Pages: Conversely, pages buried deep within your site with few or no internal links pointing to them receive no energy. They are left “cold,” telling Google they are unimportant and effectively freezing them out of any meaningful authority.
This confirms that a “flat” site architecture is strategically weak.
It leaves every page lukewarm rather than creating pillars of authority.
The goal is to practice thermal management: identify your most critical pages and systematically heat them up with focused internal links from your most prominent content. And remember. None of this works unless users are clicking on your links. So choose wisely.
5.3 External Trust: The Company You Keep
When it comes to external links, the focus has shifted from pure volume to trust and relevance. The spamrank attribute is a clear indicator of this, functioning as a “guilt by association” signal. It specifically measures the likelihood that your page links out to known spammy or low-quality domains.
Linking to a disreputable “bad neighborhood” on the web can directly harm your page’s perceived trustworthiness.
Modern PageRank isn’t just a vote; it’s an endorsement. By linking to another site, you are vouching for its quality. If you consistently vouch for untrustworthy sites, Google will start to question your own site’s integrity.
Therefore, a modern PageRank strategy must be defensive as well as offensive
It involves not only acquiring high-quality backlinks but also diligently auditing your outbound links. Curation is key; you must ensure you are a responsible citizen of the web, linking only to other high-quality, relevant resources. This protects your own site’s spamrank score and reinforces its position within a trusted part of the web graph.
5.4 A Note on “PageRank Sculpting”
In the past, SEOs practised what was known as “PageRank sculpting.” This was the tactic of using the rel="nofollow" attribute on internal links (e.g., links to a privacy policy or contact page) with the goal of preventing PageRank from flowing to those “unimportant” pages, thereby preserving more of it to be funneled to “important” money pages.
However, Google changed how this works years ago. The PageRank intended for a nofollowed link simply vanishes from the calculation for that page. It is not re-assigned to the other links.
Using the “Links as Lasers” metaphor, applying nofollow to an internal link doesn’t make your other lasers stronger; it just shuts one of them off. You’re actively deleting a portion of that page’s expected outbound heat. The modern and correct approach is not to block PageRank flow with nofollow, but to guide it intelligently through your site architecture and manage your onsiteProminence by linking strategically to the pages you want to heat up.
B. The Relevance System (T*): A Look Inside the Goldmine Engine
While Q* measures a site’s inherent, slow-moving authority, T* calculates a document’s dynamic, query-dependent relevance.
This is the outcome of a real-time competition.
Sworn testimony in the DOJ trial revealed this system is formally designated as T* and is built upon the foundational “ABC” (Anchors, Body, Clicks) signals.
The Content Warehouse leak provided the codename for the engine that operationalises this process (which I was credited by Barry Swartz at SERoundtable – the most credible newsman in SEO for many decades) for finding via original research: “Goldmine“.
Sourcing the lineup (The ‘A’ & ‘B’ Signals)

Goldmine begins by gathering a pool of potential SERP titles and relevance signals from various sources.
This directly corresponds to the “Anchors” and “Body” signals described by Google executives in court. The system scores these using internal factors like goldmineBodyFactor and goldmineAnchorFactor. Key sources include:
- The content of the <title> tag.
- Main headings on the page (e.g., <h1>).
- The anchor text of links pointing to the page.
This process traces its roots directly to the Penguin update, which was designed to target manipulative link-building schemes.
The existence of a specific penalty attribute, anchorMismatchDemotion, confirms this legacy.
This signal actively demotes pages where inbound link anchor text is not topically relevant to the target page’s content, punishing attempts to use irrelevant links to manipulate rankings. Avoid this practice.
The AI Quality Filter (BlockBERT):
Once candidates are sourced, they are passed through an AI quality filter.
The goldmineBlockbertFactor scores each candidate on its semantic coherence and contextual relevance to the page’s content.
This uses a variant of the powerful BERT language model to ensure that the chosen title is a high-quality, natural language representation of the document’s topic, filtering out keyword-stuffed or nonsensical options.
The User Behaviour Arbiter (The ‘C’ Signal):
The final and most powerful judge in the Goldmine system is the user.
The goldmineNavboostFactor uses historical user engagement data from the NavBoost system as the ultimate arbiter of relevance.
This is the “Clicks” signal.
Sworn testimony from the DOJ trial confirmed that NavBoostis a critical ranking system that analyses a rolling 13-month window of aggregated user click data. It tracks specific metrics of user satisfaction, including:
- goodClicks: Clicks where the user appears satisfied with the result and does not immediately return to the SERP.
- badClicks: Clicks where the user quickly returns to the search results (pogo-sticking), signalling dissatisfaction.
- lastLongestClicks: Considered a particularly strong signal of success, this identifies the final result a user clicks on and dwells on, suggesting their search journey has ended successfully on that page.
This architecture reveals a performance-validated loop.
The ‘A’ (Anchors) and ‘B’ (Body) signals provide the initial, predicted relevance score that gets a page into the competition.
However,the ‘C’ (Clicks) signal, via NavBoost, provides the validated relevance score based on real-world user behaviour.
This user data is then fed back into the Goldmine system, influencing which title link and result is shown to the next user.
On-page SEO is the ticket to the dance; user experience and click satisfaction is how you win.
Part 2: The Unified Ranking Model: The Indexing Tiers and Ranking Pipeline
The Q* and T* systems do not operate in isolation. They are critical components within a larger, sequential processing pipeline that a document must successfully navigate to achieve and maintain visibility.
A document’s journey through this pipeline is heavily influenced from the very beginning by the quality tier to which it is assigned. My analysis of the documentation reveals a process of progressive disqualification, where a weakness at any stage can invalidate strengths in others.
Stage 1: Indexing Tiers (“Base, Zeppelins, Landfills”)
The journey begins at indexing. The documentation confirms a long theorised tiered indexing system with specific internal names: “Base,” “Zeppelins,” and “Landfills“.
A system named SegIndexer is responsible for placing documents into these tiers based on a variety of quality signals.
A document’s scaledSelectionTierRank, a language-normalised score, determines its position within this hierarchy. High-quality, authoritative documents reside in the “Base” tier, affording them maximum ranking potential.
Average content may be placed in “Zeppelins,” while low-quality, untrustworthy, or spammy content is relegated to “Landfills,” severely limiting its ability to ever rank for meaningful queries.
A document can be effectively disqualified before the ranking process even begins if it is relegated to the Landfills.
Stage 2: Initial Retrieval (Mustang)
For documents that make it into the main index tiers, the first stage of real-time ranking is conducted by a retrieval system named Mustang.
Mustang performs a first-pass evaluation, rapidly scoring a vast number of documents based on foundational relevance and pre-computed quality signals.
These signals are stored in a highly optimised module called CompressedQualitySignals, which acts as a “cheat sheet” containing critical scores like siteAuthority and pandaDemotion.
A site’s foundational Q* profile, as represented in these compressed signals, acts as a critical gatekeeper
If a site’s overall quality score is too low, its pages may be disqualified by Mustang before they can even compete on query-specific relevance.
Stage 3: Re-ranking (Twiddlers)
The provisional results from Mustang are then passed to a powerful subsequent layer of re-ranking functions known internally as “Twiddlers”. These functions act as fine-tuning mechanisms, applying boosts or demotions based on specific, often dynamic, criteria.
We have already discussed the FreshnessTwiddler, which boosts new content for QDF queries.
The most strategically significant Twiddler, however, is NavBoost.
This system re-ranks the results based on the vast repository of historical user click behaviour, promoting pages that have a proven track record of satisfying users (earning goodClicks and lastLongestClicks) and demoting those that do not.
A page can rank well initially out of Mustang but be progressively disqualified over time if it consistently fails the user-satisfaction test applied by NavBoost.
Final Filter (Diversity)
Even if a document successfully navigates all previous stages, a final filter may be applied to manage the overall diversity of the search results page.
The existence of an attribute named crowdingdata suggests a system designed to measure and control for SERP diversity, preventing a single domain from dominating the results for a given query, even if its pages are individually the highest-scoring.
This ensures a healthier and more competitive ecosystem for users, but it means that even a perfect document can be filtered out if its domain is already over-represented on the SERP.
Part 3: The Unified Blueprint: A Prioritised Framework for Authority
Translating this technical deconstruction into an actionable strategy requires a prioritised framework.
This “Maslow’s Hierarchy of SEO Needs” provides a systematic approach, ensuring foundational elements are secure before advancing to more sophisticated optimisations. Each level is now explicitly mapped to the specific leaked attributes it is designed to influence.
Level 1 (Foundation): Accessibility & Canonicalisation
This foundational layer is about ensuring Google can discover, access, and consolidate signals for your content into a single, clean CompositeDoc. Without this, all other efforts are wasted.
- Ensure Indexability: This is the most basic requirement. Verify that pages are not blocked by robots.txt or noindex tags. A valid SSL certificate is non-negotiable, as a failure here can trigger a negative badSslCertificate signal.
- Establish a Single Source of Truth: Implement a comprehensive canonicalisation strategy to combat duplicate content. Use permanent 301 redirects (which populate the forwardingdup signal) for moved pages and the rel=”canonical” link element to consolidate signals for pages with similar content. This prevents Google from fragmenting your authority across multiple, competing CompositeDocs.
Level 2 (Content): Quality, Relevance & Structure
With the foundation in place, the focus shifts to the content itself. The goal is to create assets that are recognised as high-value by both machines and humans.
- Create High-Value Content: This is no longer a subjective goal. The objective is to create content that will generate a high OriginalContentScore for its uniqueness and a positive contentEffort score for the demonstrable labour and expertise invested in its creation. This means prioritising original research, unique data, and custom multimedia over content volume.
- Engineer “Signal Coherence”: The Goldmine engine thrives on consistency. Your page’s <title>, <h1>, and the anchor text of your most important internal links must send a clear and consistent message about the page’s core topic. This alignment provides a strong, unambiguous relevance signal.
- Structure for Machines: Make it easy for Google to deconstruct and understand your content. Implement comprehensive Schema.org markup to populate the richsnippet field and make your content eligible for rich results in the SERPs. Use a clear, logical HTML structure with proper headings (<h1>, <h2>, etc.) to help Google identify key sections and entities for its EntityAnnotations module.
Level 3 (Authority): Link Equity & Trust
This level focuses on building and managing the signals that contribute to your site’s overall Q* score and its perceived authority within the wider web ecosystem.
- Build a Positive Trajectory: The predictedDefaultNsr score is versioned and historical. This means that consistent, long-term investment in quality is algorithmically rewarded. Focus on a sustained programme of content improvement and site maintenance to build positive “algorithmic momentum.”
- Demonstrate Freshness: For topics that are time-sensitive or subject to QDF, regularly perform substantial content revisions. The goal is to do more than just fix a typo; it is to make meaningful improvements that are significant enough to trigger the lastSignificantUpdate signal and earn a potential boost from the FreshnessTwiddler.
- Build Internal Prominence: The onsiteProminence attribute is Google’s measure of a page’s importance within its own site, calculated by simulating traffic flow. Strategically link from your strongest pages (like the homepage or high-traffic articles) to other important content to boost their internal authority and signal their importance to your site’s structure.
- Curate Your Link Neighbourhood: Trust is determined in part by association. Regularly audit your outbound links and avoid linking to spammy or low-quality sites. This is essential for maintaining a positive spamrank score and demonstrating that your site is a responsible member of the web community.
Level 4 (Enhancement): User Satisfaction & Experience
The pinnacle of the hierarchy is optimising for the end-user. In the post-leak world, user satisfaction is not a vague ideal; it is a quantifiable and powerful set of ranking signals.
- Optimise for the “Satisfied Click”: Your titles and meta descriptions must make an accurate promise to the user on the SERP. Then, your on-page experience and content must over-deliver on that promise. The ultimate goal is to earn the powerful lastLongestClicks signal from the NavBoost system, which tells Google that your page successfully ended the user’s search journey.
- Ensure Flawless Page Experience: A fast, mobile-friendly site with a clean, intuitive layout is a prerequisite for a positive user experience. This means minimising on-page ad clutter to maintain a low clutterScore and ensuring the page is easy to navigate. A poor page experience is a leading cause of badClicks and subsequent demotion by the NavBoost re-ranking system.
Merging the Frameworks: The Crossover of Method and Measurement
A long-standing principle from my approach, captured in earlier ebooks, is that “A successful SEO strategy helps your website get relevant, get trusted, and get popular“.
This simple mantra perfectly encapsulates the end goals that both the post-leak analysis and Koray’s framework strive to achieve, albeit through different lenses. The former provides the technical measurements, while the latter provides the architectural method.
- Getting Relevant: This is the essence of topicality. Gübür’s framework provides the how with the Topical Map and Semantic Content Network, a practical blueprint for creating a comprehensive and interconnected body of work. The leaked data provides the what with attributes like
siteFocusScoreandsiteRadius, which are Google’s mathematical calculations of how successful that work has been. - Getting Trusted: This speaks to foundational, query-independent quality. Gübür’s framework builds this through the accumulation of Historical Data and the application of a rigorous Holistic SEO Writing System designed to produce high-value content. The leak validates this by revealing
predictedDefaultNsras a versioned signal that tracks quality over time (“algorithmic momentum”) andcontentEffortas a direct attempt to quantify the labour and expertise in a page. - Getting Popular: This is the ultimate validation from users. The leak identifies the specific mechanism for this: the NavBoost system and its powerful
lastLongestClickssignal, which proves a page has satisfied a user’s query. Gübür’s framework views this outcome as the natural result of becoming a definitive, low “Cost of Retrieval” resource that is so comprehensive and well-structured that users and search engines alike prefer it.
Conclusion: The Path Forward
The era of SEO as an art of inference is definitely over.
The combined revelations from the US V DOJ trial, the Content Warehouse leak, Mike King’s seminal intial coverage of the leak, Barry Schwartz news reporting and support for independent writers (like me) over all that time, and over the 25 years I’ve been paying attention, Rand Fishkin’s early work on Quality Score Aaron Wall‘s seminial advice even away back to the minus 6 debacle, AJ Kohn’s direction on clicks and pogosticking in 2008, and Jim Boykin’s early insights on link building, Mark Williams Cook’s work on Quality_Score, Screaming Frog and the likes of Bill (and Amonn Johns) and Koray’s work (and others like them) with patents have provided an evidence-based and tested blueprint of Google’s ranking architecture – as I thought it might. I will throw in John Andrew’s here for showing me what I can only describe as “meta marketing” – I literally only came up with that – on Sphinn over a decade ago. I wonder if he recognises the meta examples I do lol.
The goal of modern SEO is to assist Google in building the best possible CompositeDoc for your content.
This is not achieved through tactical trickery but through a holistic, dual-pronged strategy.
First is the strategy of Proactive Quality: building a deep reservoir of foundational, query-independent authority (Q*).
This requires a recognition that a page’s authority is a historically-aware, multi-layered calculation that starts with a baseline trust score (predictedDefaultNsr) and is constantly refined by a host of specialised models that measure everything from human effort (contentEffort) to site-wide topical focus (siteFocusScore). This is a long-term investment in building a positive algorithmic momentum.
Second is the strategy of Reactive Performance: proving that foundational quality in the real-time, query-dependent competition for user satisfaction in the SERPs (T*).
This is won by demonstrably satisfying users, earning the click-based validation of the NavBoost system, and becoming the page that successfully ends the search journey.
The only viable path forward is to build a genuinely high-quality, authoritative, and user-centric digital asset that excels at every stage of this now-documented evaluation pipeline.
The black box has been opened, and it has confirmed what guideline-driven practitioners have long believed: in the end, quality is the only durable strategy.
You might also be interested in – The Definitive Guide to On-Page SEO.
Read next
Read my article that Cyrus Shephard so gracefully highlighted at AHREF Evolve 2025 conference: E-E-A-T Decoded: Google’s Experience, Expertise, Authoritativeness, and Trust.

The fastest way to contact me is through X (formerly Twitter). This is the only channel I have notifications turned on for. If I didn’t do that, it would be impossible to operate. I endeavour to view all emails by the end of the day, UK time. LinkedIn is checked every few days. Please note that Facebook messages are checked much less frequently. I also have a Bluesky account.
You can also contact me directly by email.

Disclosure: I use generative AI when specifically writing about my own experiences, ideas, stories, concepts, tools, tool documentation or research. My tool of choice for this process is Google Gemini Pro 2.5 Deep Research (and ChatGPT 5 for image generation). I have over 20 years writing about accessible website development and SEO (search engine optimisation). This assistance helps ensure our customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was conceived, edited, and verified as correct by me (and is under constant development). See my AI policy.