Disclaimer: This is not official. Any article (like this) dealing with the Google Content Data Warehouse leak requires a lot of logical inference when putting together the framework for SEOs, as I have done with this article. I urge you to double-check my work and use critical thinking when applying anything for the leaks to your site. My aim with these articles is essentially to confirm that Google does, as it claims, try to identify trusted sites to rank in its index. The aim is to irrefutably confirm white hat SEO has purpose in 2026 – and that purpose is to build high-quality websites. This article was first published on: 14 July 2025: Feedback and corrections welcome.
If you work in SEO (Search Engine Optimisation), you’ve likely heard about the Google Content Warehouse API leak. The news broke in 2024, right when I was deep into building Hobo SEO Dashboard.
It wasn’t actually until trial testimony in February 2025 that the legitimacy and significance of the leaked documents were all but confirmed.

Well, it was game on as soon as that statement broke (for me). For me, there was now a reason to immerse myself in this leak. I knew Mike King had blazed the trail with seminal work around the leak (with help from Dan Petrovic). My purpose was different. Could I build an evidence-based SEO framework aligned to work with Google? Could I find anything not public knowledge? The answer is yes to both questions.
But let’s begin back in 2024.
In the aftermath of the HCU Helpful Content Update
In the spring of 2024, the digital world was simmering.
A tension had been building for months between Google and the global community of search engine optimisation (SEO) professionals, marketers, and independent publishers who depend on its traffic for their livelihoods, especially after the impact of the September 2023 HCU Update.
It was in this climate of uncertainty that a simple, automated mistake became the spark that ignited a firestorm of revelation.
For someone like me, who started in this field before Google was even a household name, these events represent the end of an era – the era of creative investigative inference and educated guesswork.
For over 25 years, SEO has been a craft of reverse-engineering a black box.
How SEOs worked pre-leak
We operated on a combination of official guidance, experimentation, anecodtes and hard-won intuition. The landmark U.S. DOJ v. Google antitrust trial and the unprecedented leak of Google’s internal Content Warehouse API documentation have, for the first time, shattered that box.
We’ve moved from reverse-engineering to having the blueprints.
This isn’t another list of Google ranking factors; it’s a look at the very container that holds them.
The leak didn’t give us a “secret recipe” but something almost as valuable – the architectural plans.
Did Google respond to the leak in the SERPs?
Looks like it. Take note of the flux in Algoroo (a SERPs activity monitor by Dan Petrovic). There was an enormous amount of flux in the SERPS post-leak in 2024.
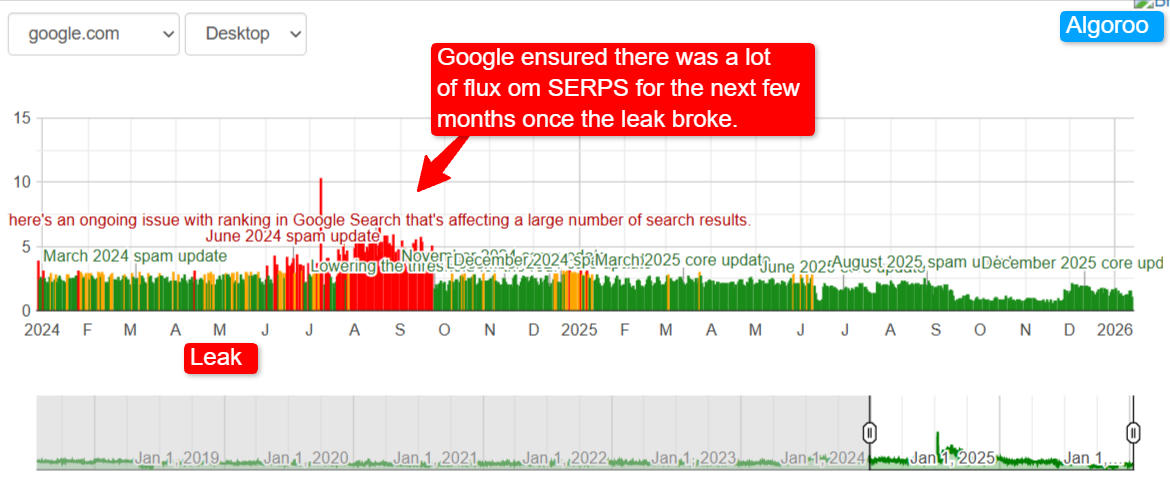
That image looks to me as if Google changed the weights of things directly after the leak. It might have been Google forced to lean more into Authority and Trust to avoid manipulation. Maybe they just hit randomise on some stuff. Nobody knows. To my mind, they are kind of trapped between documentation, code and quality rater guidelines here. Doctrine, as I call it.
Google, I’d wager, won’t be ripping it all out and starting again.
It looks to me as if they are leaning heavily into Trust. If you don’t have it, you are toast.
An Evidence-Based SEO Framework
The Google leak allows us to build a new “canon of SEO truth” based on verifiable “evidence”.
It confirms what many of us have long advocated: the most sustainable success comes not from chasing algorithms, but from understanding the fundamental architecture of how a search engine perceives and organises information. The unlocked warehouse proves that the focus must shift from attempting to please a secretive machine to demonstrably satisfying a now-quantifiable human user.
The leak’s most profound impact isn’t the revelation of new tactics, but its overwhelming validation of the core, user-first principles that many veteran SEOs have championed for years, often in the face of Google’s public misdirection.
Google representatives consistently and publicly minimised core beliefs of the SEO community – that a website’s overall authority matters (siteAuthority), that user clicks influence rankings (Navboost), and that new sites face a probationary period (Hostage).
The leak served as a stunning vindication, confirming that our instincts, honed through years of observation, were largely correct.
The direct contradiction doesn’t just expose a new tactic; it confirms that the foundational SEO strategy of building a trusted brand that users actively engage with was correct all along.
The leak isn’t a call to change strategy but to double down on the right strategy with newfound confidence and precision, armed with the knowledge of the specific mechanisms that measure its success.
This article will dissect the anatomy of the leak, explore its most significant revelations by integrating deep technical details from my ebook, Hobo Technical SEO, and lay out the new strategic playbook for any business that wishes to thrive in a post-leak world, investing marketing budgets where they matter.
Timeline of a leak
| Date(s) | Event | Trial Context | Significance |
| Oct 20, 2020 | DOJ, with 11 states, files antitrust lawsuit against Google for monopolising the search and search advertising markets. | Search Monopoly | Marks the beginning of the landmark legal challenge to Google’s core business model. |
| Jan 24, 2023 | DOJ, with several states, files a second antitrust lawsuit against Google for monopolising the digital advertising technology (“ad tech”) market. | Ad Tech Monopoly | Opens a second legal front targeting the mechanisms through which Google monetises its dominance. |
| Sep – Nov 2023 | The liability phase of the search monopoly trial takes place in a 10-week bench trial before U.S. District Judge Amit P. Mehta. | Search Monopoly | Key evidence is presented, and witnesses, including Google executives, provide sworn testimony. |
| Mar 13/27, 2024 | An automated bot, yoshi-code-bot, inadvertently publishes a copy of Google’s internal Content Warehouse API documentation to a public GitHub repository. |
N/A | The accidental disclosure occurs, but the information remains largely unnoticed by the public. Dan Petrovic confirms knowledge and is in private communications with Google about the leak. It turns out it “Looks like the code for the ContentWarehouse has been available on GitHub since Sept 20, 2022, in Google’s official client repos for PHP, Java, and Ruby.” via @Derek_Perkins – Commit 2c5917a yoshi-code-bot yoshi-code-bot authored on Oct 1, 2022 |
| May 5, 2024 | Erfan Azimi discovers the public repository and shares the documents with industry experts Rand Fishkin and Michael King. Dan Petrovic confirms prior knowledge of the documents. | N/A | The process of verification and analysis begins within a small circle of experts. |
| May 7, 2024 | Google removes the public GitHub repository after becoming aware of its exposure. | N/A | Google acts to contain the leak, but the documents have already been copied and circulated. |
| May 27, 2024 | Fishkin and King publish their coordinated analyses with the help of Dan Petrovic, bringing the leak to global public attention and igniting widespread industry discussion. | N/A | The leak becomes a major public event, triggering a crisis of credibility for Google. |
| May 29, 2024 | Google issues an official statement to media outlets, cautioning against making assumptions based on “out-of-context, outdated, or incomplete information”. | N/A | Google confirms the documents’ authenticity through a non-denial denial while attempting to discredit their relevance. |
| Aug 8, 2024 | Judge Mehta issues his opinion, finding Google liable for illegally maintaining its monopoly in the general search market. | Search Monopoly | The court validates the DOJ’s core argument, setting the stage for a remedies phase. |
| Sep 9 – 27, 2024 | The ad tech monopoly trial takes place in a three-week bench trial before U.S. District Judge Leonie M. Brinkema. | Ad Tech Monopoly | Evidence regarding Google’s control over the ad tech stack is presented. |
| Apr 17, 2025 | Judge Brinkema rules that Google illegally monopolised the publisher ad server and ad exchange markets in violation of the Sherman Act. | Ad Tech Monopoly | The court delivers a second major antitrust loss for Google. |
| May 2025 | The remedies phase of the search monopoly trial takes place to determine the penalties for Google’s illegal monopolisation. | Search Monopoly | Arguments are heard regarding potential structural and behavioural remedies. |
| Sep 2, 2025 | Judge Mehta issues his remedies ruling, ordering Google to share data with rivals but stopping short of forcing a sale of Chrome or Android. | Search Monopoly | The final judgment in the search case avoids a structural breakup but imposes significant behavioural constraints. |
| Sep – Oct 2025 | SEO Shaun Anderson publishes “Strategic SEO 2025” and a series of detailed analyses on Hobo SEO Blog, connecting the DOJ trial testimony with the technical specifics from the Content Warehouse leak, webmaster guidelines, the quality rater general guidelines and E-E-A-T. | N/A | Synthesises the two major events into a cohesive, evidence-based framework for the SEO industry, solidifying the “new canon of truth” about Google’s ranking systems. The on-page seo framework and the SEO audit framework. |
Google’s Statements on the 2024 Leak

What Google Said About the Leak
When thousands of pages of Google’s internal Content Warehouse API documentation were accidentally published in the spring of 2024, the company faced a significant credibility crisis.
Its response was a carefully orchestrated exercise in corporate crisis management, unfolding in two distinct arenas: the court of public opinion and the court of law.
“We would caution against making inaccurate assumptions about Search based on out-of-context, outdated, or incomplete information. We’ve shared extensive information about how Search works and the types of factors that our systems weigh, while also working to protect the integrity of our results from manipulation”.
The Legal Admission: Google’s Acknowledgement of the Leak in Court
While Google’s public relations team worked to contain the fallout, its legal adversaries took notice.
The most direct and significant acknowledgement of the leak came not from a press release, but from within the context of the DOJ’s antitrust litigation based on a call dated February 18, 2025 Call with Google Engineer HJ Kim.
This single sentence is profoundly important. It represents the only known instance of the May 2024 leak being formally entered into the record of the legal proceedings.
In a government filing, the DOJ made a tactical, if qualified, reference to the event:
“There was a leak of Google documents which named certain components of Google’s ranking system, but the documents don’t go into specifics of the curves and thresholds”.
While the DOJ immediately qualified the statement – noting the documents lacked specifics on weighting, a point that mirrored Google’s own public defence – the admission itself was critical.
It confirmed that the U.S. government, in its official capacity as plaintiff, was aware of the leak and acknowledged the documents as originating from Google.
This legal acknowledgement, combined with the public non-denial, created a unified reality.
Google could no longer plausibly deny the documents’ authenticity. Its strategy was limited to managing their interpretation.
The company’s official position, both in public and as reflected in the court filing, was consistent: the documents are real, but they don’t tell the whole story. As I note in my analysis on the Hobo SEO blog, the leak, corroborated by the trial testimony, dismantled “the myth of a single ‘Google Algorithm,’ revealing instead a multi-layered processing pipeline”.
Google’s statements, both public and legal, were a tacit admission of this complexity, used as a shield against the crisis of credibility the leak had ignited.
The story of the leak was not a dramatic, cloak-and-dagger operation.
There was no shadowy whistleblower or sophisticated cyberattack. Instead, on March 13, 2024, an automated software bot named yoshi-code-bot made a routine update to a public GitHub repository. In doing so, it inadvertently published thousands of pages of Google’s highly sensitive, internal API documentation.
The Core Data Structures
The scale was immense, spanning over 2,500 pages and detailing 14,014 distinct attributes across 2,596 modules.
There are a number of versions of the api leak available, and I have summarised the most important modules in the course of this investigation.
Google’s official response was a standard non-denial denial, confirming the documents were authentic but urging the public to avoid making “inaccurate assumptions about Search based on out-of-context, outdated, or incomplete information”.
To understand the leak’s implications, you must first understand the containers that hold the data. These are the core data structures that form the foundation of Google’s index.
- The
CompositeDoc: Think of this as the master record or folder for a single URL. It’s a “protocol record” that aggregates all known information about a document, from its core content to its link profile and quality scores. It is the foundational data object for any given URL in Google’s systems. - The
PerDocDataModel: Within theCompositeDocis arguably the most critical component for SEO analysis: thePerDocDatamodel. This is the comprehensive ‘digital dossier’ or “rap sheet” Google keeps on every URL. It’s the primary container for the vast majority of document-level signals—on-page factors, quality scores, spam signals, freshness metrics, and user engagement data—that are made accessible to the ranking pipeline. Its structure as a Protocol Buffer (Protobuf) is a key reason Google can operate with such efficiency at a colossal scale. - The
CompressedQualitySignalsModule: This is a highly optimised “cheat sheet” containing a curated set of the most critical signals, such assiteAuthority,pandaDemotion, andnavDemotion. Its purpose is to enable rapid, preliminary quality scoring in systems like Mustang and TeraGoogle, where memory is extremely limited. The documentation contains a stark warning: “CAREFUL: For TeraGoogle, this data resides in very limited serving memory (Flash storage) for a huge number of documents”.
The very existence of this compressed module reveals a fundamental truth about how Google ranks content: a document’s potential is heavily determined before a user even types a query. The hardware constraints of Google’s serving infrastructure force an extreme focus on efficiency.
Only the most vital, computationally inexpensive signals can be included in this preliminary check. This implies a two-stage process. First, a document must pass a “pre-flight check” based on its CompressedQualitySignals.
Only if it passes this gate is it then subjected to the more resource-intensive final ranking by the main systems.
SEO, therefore, is not just about query-time relevance; it’s about maintaining a clean “rap sheet” of these compressed quality signals to even be eligible to compete in the first place.
Deconstructing the Ranking Pipeline: A Multi-Stage Journey
Perhaps the most fundamental insight from the leak is that the popular conception of a single, monolithic “Google Algorithm” is a fiction.
The documentation confirms a far more complex reality: a layered ecosystem of interconnected microservices, each with a specialised function, working together in a processing pipeline. A successful strategy must address signals relevant to each stage of this process.
Based on the leak and trial documents, we can now map out this journey with evidence-based clarity.
This multi-stage architecture proves that Google’s process is far more nuanced and dynamic than a simple mathematical formula.
A document must first possess strong foundational signals to pass the initial Mustang ranking, then it must prove its worth through user interaction to succeed in the NavBoost re-ranking stage, all while competing for space on a modular SERP assembled by Glue and Tangram.
NavBoost: The Confirmed Primacy of the User Vote
While the DOJ trial first brought NavBoost into the public eye, the Content Warehouse leak gave us an unprecedented look at its mechanics.
This is a dedicated deep dive into what testimony called “one of the important signals that we have“. For years, we knew clicks mattered, but now we know the name of the system and the specific metrics it measures.

NavBoost is a powerful “Twiddler” that re-ranks results based on user click behaviour. Sworn testimony from Google executives like Pandu Nayak during the DOJ trial confirmed its existence, its use of a rolling 13-month window of aggregated click data, and its critical role in refining search results.
“Dwell time, CTR, whatever Fishkin’s new theory is, those are generally made up crap. Search is much more simple than people think.” Gary Ilyes 2019 Reddit Thread
The leak provided the technical specifics, revealing, somewhat ironically the Craps module, which appears to handle the storage and processing of click and impression signals for NavBoost.
The key metrics tracked include:
goodClicks: Clicks where the user appears satisfied with the result.badClicks: Clicks where the user quickly returns to the search results, a behaviour known as “pogo-sticking,” which signals dissatisfaction.lastLongestClicks: Considered a particularly strong signal of success, this identifies the final result a user clicks on and dwells on, suggesting their search journey has ended successfully.unsquashedClicks: A metric that likely represents clicks that have been vetted and are considered genuine user interactions, as opposed to spam or bot activity.
The long-standing debate about whether clicks are a ranking factor can now be resolved with a more nuanced understanding. Google’s public statements that “clicks are not a direct ranking factor” and the evidence of NavBoost’s power are not a contradiction; they describe two different stages of the ranking pipeline.
Clicks likely have a minimal direct impact on a page’s initial ranking as determined by the Mustang system. That first pass is based on more traditional signals of relevance and authority.
However, a page’s ability to maintain or improve that ranking is heavily dependent on its performance in the NavBoost re-ranking stage.
A page with excellent on-page SEO might rank well initially but will be demoted by NavBoost if it consistently fails to satisfy users, generating a high ratio of badClicks.
This resolves a major industry debate and provides a much more sophisticated model: traditional SEO gets you to the starting line (Mustang), but a superior user experience wins the race (NavBoost).
A Taxonomy of Signals: The Evidence in the Code

The leak provides a rich vocabulary of specific signals, moving our understanding from abstract concepts to concrete, named attributes. This section provides a taxonomy of some of the most impactful signals revealed, which will form the basis for more detailed articles on the Hobo blog.
Authority & Trust Signals

These signals measure the overall trust, authority, and reputation of a page or an entire domain. They are foundational to Google’s assessment of a source’s reliability.
siteAuthority: This is the long-debated “domain authority” metric, confirmed as a real, calculated, and persistent score. Stored in theCompressedQualitySignalsmodule, it is a primary input into the site-wide quality score system, internally referred to as .siteFocusScore&siteRadius: These attributes provide a measure of a site’s topical specialisation.siteFocusScorequantifies how much a site concentrates on a specific topic, whilesiteRadiusmeasures how far a given page’s topic deviates from the site’s core theme. This confirms that niche authority is algorithmically measured and rewarded.hostAge: Found in thePerDocDatamodule, this attribute is used to “sandbox fresh spam,” providing the technical basis for the long-theorised “sandbox” effect where new sites or content face an initial period of limited visibility.
Content Quality & Helpfulness Signals

These attributes are designed to algorithmically quantify content quality, originality, and the effort invested in its creation.
contentEffort: Perhaps the most significant revelation for content creators this is an “LLM-based effort estimation for article pages”. It is the likely technical engine behind the Helpful Content System (HCS), algorithmically measuring the human labour, originality, and resources invested in creating a piece of content.OriginalContentScore: A specific score designed to measure the uniqueness of a page’s content. This is particularly important for shorter pieces of content where demonstrating value can be more challenging.pandaDemotion: The ghost of the 2011 Panda update lives on. This attribute, stored inCompressedQualitySignals, confirms that Panda’s principles have been codified into a persistent, site-wide demotion factor that penalises domains with a high percentage of low-quality, thin, or duplicate content.
User Experience & Clutter Signals

These signals directly measure and penalise aspects of a page or site that create a poor user experience.
clutterScore: A site-level penalty signal that looks for “distracting/annoying resources.” The documentation notes that this signal can be “smeared,” meaning a penalty found on a sample of bad URLs can be extrapolated to a larger cluster of similar pages. This makes site-wide template and ad-placement hygiene critical.navDemotion: A specific demotion signal explicitly linked to “poor navigation or user experience issues” on a website, stored inCompressedQualitySignals.- Mobile Penalties: The
SmartphonePerDocDatamodule contains explicit boolean flags and scaled penalties for poor mobile experiences, includingviolatesMobileInterstitialPolicyfor intrusive pop-ups andadsDensityInterstitialViolationStrengthfor pages with excessive ad density.
On-Page Relevance Signals

These attributes measure how well specific on-page elements align with the page’s topic and user intent.
titlematchScore: A direct, calculated metric that measures how well a page’s title tag matches the content of the page itself. This confirms the title tag’s role as a primary statement of intent for a document.ugcDiscussionEffortScore: Found in theCompressedQualitySignalsmodule, this is a score for the quality and effort of user-generated discussions and comments. It confirms that a vibrant, well-moderated, and high-quality on-page community is a tangible positive signal.
The New Strategic Playbook: From Pleasing to Proving
The ultimate value of this accidental revelation is the profound strategic realignment it demands. The era of inference is over. We now have an evidence-based framework that confirms sustainable success in Google’s ecosystem is less about manipulating an opaque algorithm and more about building a genuine, authoritative brand that users actively seek, trust, and engage with.
The leak demands a unified strategy that addresses both the proactive and reactive elements of Google’s ranking pipeline.
First, you must focus on Proactive Quality, which is about building for the foundational quality score system ().
This involves a long-term commitment to establishing your entire domain as a credible and trustworthy source. The goal is to build a site that Google’s systems trust by default.
This means cultivating a high siteAuthority score through deep topical focus (siteFocusScore), earning high-quality links to build PageRank, and demonstrating E-E-A-T (where it is contextually relevant to the purpose of the page) through clear authorship and factually accurate content.
It also requires impeccable site hygiene to avoid the accumulation of “algorithmic debt” from site-wide demotion signals like pandaDemotion and clutterScore.
Even Google Penguin is mentioned in the leak (see unnatual links).

Second, you must optimise for Reactive Performance, which is about winning in the NavBoost re-ranking system. This involves creating content and user experiences that demonstrably satisfy users, generating a high volume of positive click signals like goodClicks and, most importantly, lastLongestClicks.
This is about proving, through the direct vote of user behaviour, that your content is the most satisfying answer for a given query. A page with a high siteAuthority might get an initial good ranking, but it will not sustain it without positive user interaction data.
And remember, Page Quality (PQ rating) is important on a page level and a site level, through the mechanisms pqData and siteQualityStddev.
Froom my primary research I discovered the Goldmine system, and Firefly system.
Google also has a ractorScore attribute. This looks like a mechanism to detect AI content.
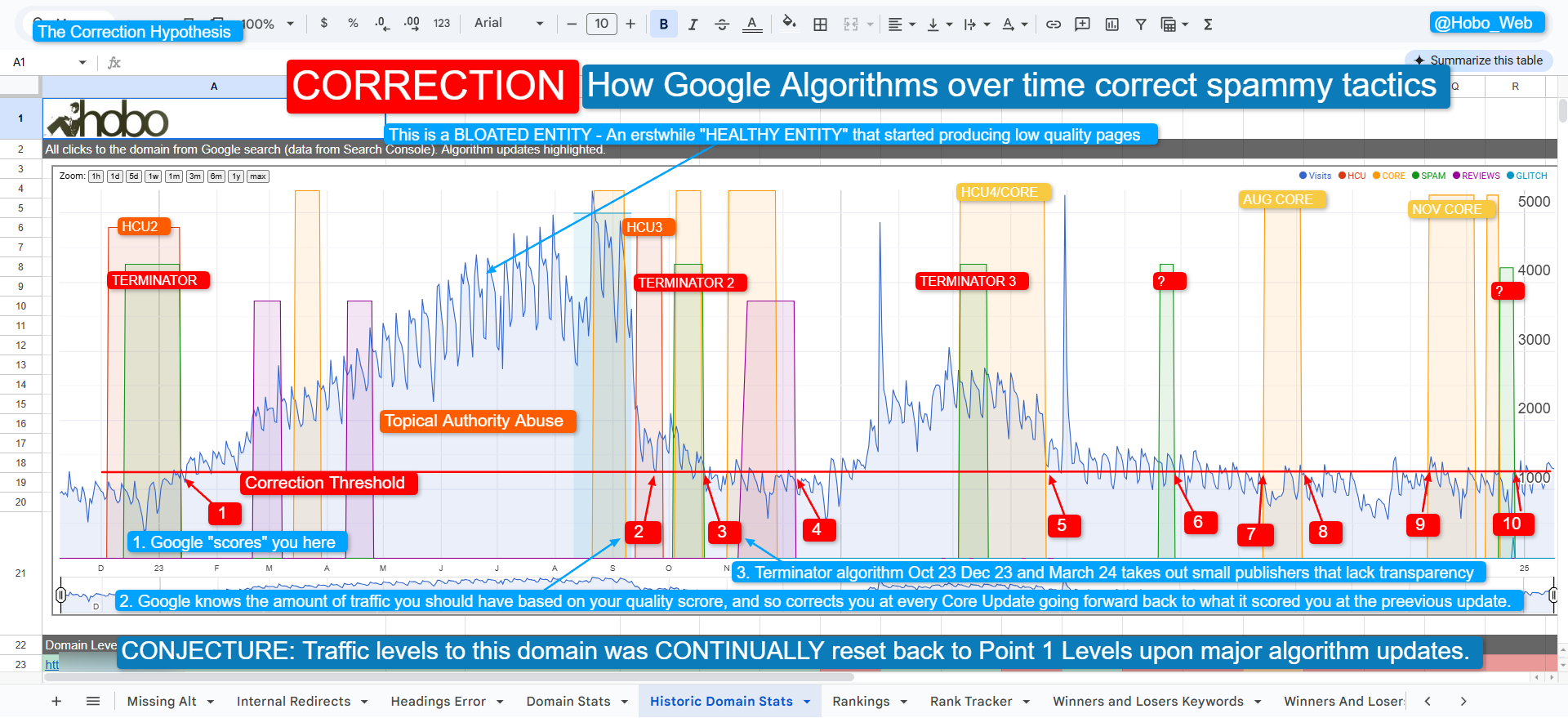
As I say Google is a system of competing philoshopies.
I am interested in attributes SEOs should be interested in. Attributes that are endemic to Google’s system and direction and is reflected in Google webmaster guidelines and the search quality evaluator guide – that is – things that probably are not going to change much even in the wake of the Google leak.
My analysis is focused on creating framweorks for on page SEO and seo audit frameworks based on evidence in the leak. In light of that whicle I might explain the importance of links and clicks, for instance, I do not granularily describe how to abuse these systems. I show you the systems you need to align with.
In fact one of the most affirming confirmations in the leak for me was that Google is a system of competing philoshopies, where E-E-A-T – Google’s docrtine – is codified at a foundational system level. This is still incredibly useful information even though the leak is public and no doubt Google will have changed and modified things.
For the last 25 years, my core philosophy has remained consistent: build technically sound, fast, and genuinely useful websites for people. The stuff I was looking for in the leak is foundational to Google’s entire philoshopy.
Doctrine I believe Google will not be changing.
What the leak means for SEO strategy into the future
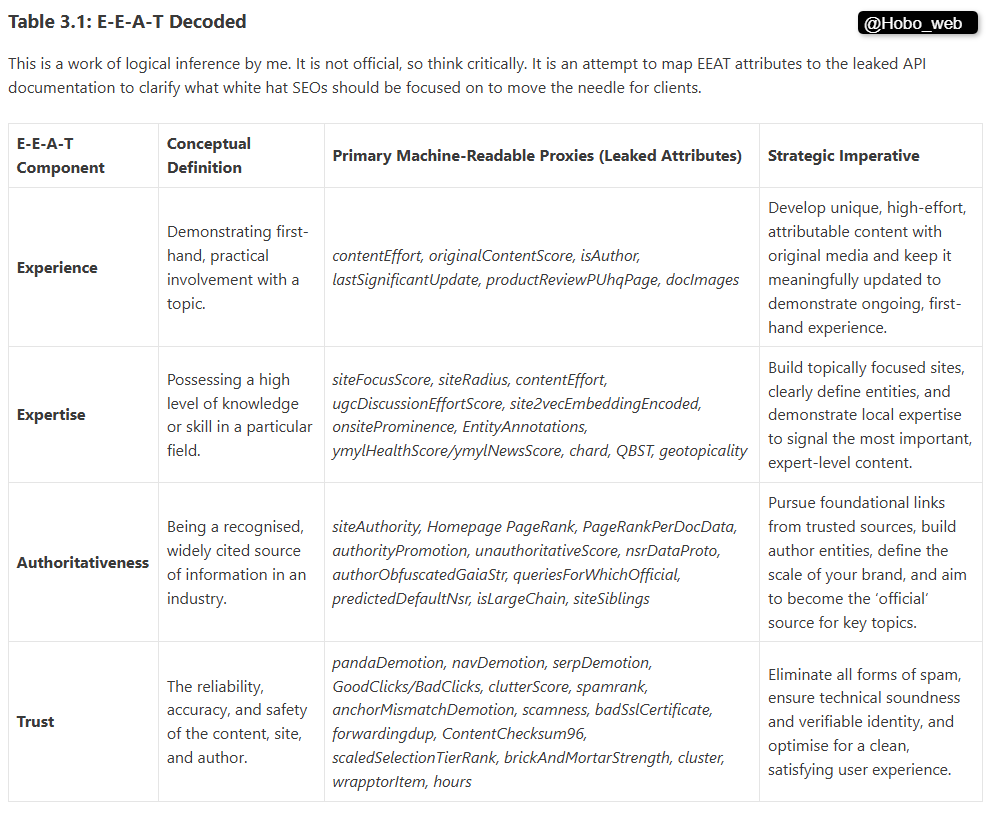
“If you know the enemy and know yourself, you need not fear the result of a hundred battles.”
— Sun Tzu, The Art of War
The leak is the ultimate vindication for this long-term, brand-building, “people-first” approach. It means Pagerank matters, a lot. It means Content Effort matters a lot. It means Site Focus and Site radius matter a lot. Page quality matters a lot. Clutter Score matters a lot.
Google is a system of competing philosophies. Q* Q-Star, P* Popularity signal and T*Topicality determine rankings. E-E-A-T is Google’s doctrine, codified.
The difference now is that we have the vocabulary, the blueprints, and the evidence to prove it. The guesswork is over. We also have blueprints to create frameworks for Local SEO, Image SEO and Entity SEO. And I did.
Check out my article on SEO strategy or my article mapping the google leak to algorithm updates and mapping E-E-A-T to leaked attributes.
When the enemy knows his plans are known, he changes tactics, not doctrine. Blueprints lose tactical sharpness, but they preserve strategic truth.
What was lost:
-
The asymmetry of knowledge.
-
The long window of silent advantage.
-
The ability to test without resistance.
What remains invaluable:
-
Proof of governing philosophy.
-
Confirmation of invariant priorities.
-
Validation of what cannot change without destroying the system itself.
Weapons age quickly. Doctrine does not. The leak did not reveal how to win battles tomorrow. It revealed how wars are decided. Google can rotate thresholds, rename systems, blur weights, inject noise.
But it cannot abandon:
-
Trust accumulation.
-
Reputation memory.
-
User satisfaction as adjudicator.
-
Pre-ranking eligibility gates.
-
Resource-constrained triage.
An empire at scale cannot act otherwise. So the exposure was tactically clumsy but strategically clarifying. The black box was not opened to steal its gears.
It was opened to confirm its axis. Those who chased exploits lost their edge. Those who sought alignment gained certainty. Thus the correct move now is not imitation, but construction.
While the DOJ antitrust trial thinks different about monopolistic practices of Google, I don’t really see Google search quality measures as such as the enemy here. Also I have a deep understanding over 20 years of experience, a lot to do with recovering sites traffic after core updates, an intrinsic familiarisation with official Google documentation and Google statements, primary analysis of the Google leak, deep analysis of HCU victim data and anti-trust testimony.
To treat Google as an enemy you are actively fighting against is slightly anthromorphic, short sighted (except for all but the most talented) and included for a bit of fun.
Do not fight the algorithm we see.
Build for the philosophy confirmed in the leak.
That knowledge does not expire.
“There is no instance of a nation benefiting from prolonged warfare.”
— Sun Tzu, The Art of War


The fastest way to contact me is through X (formerly Twitter). This is the only channel I have notifications turned on for. If I didn’t do that, it would be impossible to operate. I endeavour to view all emails by the end of the day, UK time. LinkedIn is checked every few days. Please note that Facebook messages are checked much less frequently. I also have a Bluesky account.
You can also contact me directly by email.
This is my art.
Disclosure: I use generative AI when specifically writing about my own experiences, ideas, stories, concepts, tools, tool documentation or research. My tool of choice for this process is Google Gemini Pro 2.5 Deep Research. I have over 20 years writing about accessible website development and SEO (search engine optimisation). This assistance helps ensure our customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was conceived add edited verified as correct by me (and is under constant development). See my AI policy.