Get a full review of your your website
Based on ground truth evidence from antitrust DOJ trial documents reviewed, the content data warehouse leak, Google Quality Rater guidelines, Google Search Essentials, and over 20 years experience in SEO (search engine optimisation), and some admitted logical inference of my own, I present that E-E-A-T is a condensation of Q-Star (Q*) and ‘Site_Quality’ score is the output.
For all intents and purposes, E-E-A-T is Q-Star. E-E-A-T is Quality Score, or a proxy of it, at least.
Conceptually speaking, E-E-A-T is Google’s doctrine codified.
E-E-A-T (Experience-Expertise-Authoritativeness-Trust)
Google’s philosophy is built on a single, foundational concept: Trust.
The Search Quality Rater Guidelines (QRG), the E-E-A-T framework within it, and the Helpful Content Update are not separate initiatives; they are interconnected systems designed to define, measure, and reward trust.
According to Google’s own documentation, “Of these aspects, trust is most important“.
This is the core principle of the evaluation model.
The other components – Experience, Expertise, and Authoritativeness – support the central concept of Trust.
A page can demonstrate expertise, but if it is untrustworthy, it will be assigned the lowest possible quality rating because, as the September 11 2025, guidelines state, “Trust is the most important member of the E-E-A-T family because untrustworthy pages have low E-E-A-T no matter how Experienced, Expert, or Authoritative they may seem“.
This is especially true for “Your Money or Your Life” (YMYL) topics, where a lack of trustworthiness can cause real-world harm.
“‘Even the most fascinating content, if tied to an anonymous profile, simply won’t be seen because of its excessively low rank.’ Cited to Eric Schmidt, ex-Google, 2014.
Deconstructing Q-Star (Q*): The Core Inputs

The phrase “Brands are how you sort out the cesspool” was a statement by former Google CEO Eric Schmidt in 2008, suggesting that in the rapidly expanding and largely unregulated internet, trusted brands act as a signal of quality and reliability, helping users navigate through a sea of potentially false or low-quality content.
He saw brands not as the problem, but as the solution to the challenges posed by the “cesspool” of information online, offering a way to organise and trust the content available.
The concept of a site-level quality score is not new; its lineage can be traced back to the 2011 Google Panda update, which was Google’s first major attempt to “reduce rankings for low-quality sites” on a site-wide basis.
The modern Q* system, called Q-Star internally, is the direct descendant of this initiative – a composite score that reflects a site’s overall credibility and utility, independent of any specific query.
Sworn testimony from Google’s Vice President of Search, Hyung-Jin Kim, during the DOJ vs. Google trial, underscored the system’s foundational role.
Kim noted, “Q* (page quality, i.e., the notion of trustworthiness) is incredibly important” and testified that the “Quality score is hugely important even today. Page quality is something people complain about the most”.
He recounted that Google formed a Page Quality team in response to “content farms” flooding search results, developing methods to identify authoritative sources and demote low-quality pages. This quality score is “generally static across multiple queries and not connected to a specific query,” making it a persistent reputation metric that is “largely related to the site rather than the query”. In short, Google uses this system to “consistently reward pages that demonstrate experience, expertise, authority, and trust (E-E-A-T), and that reputation persists across queries”.
- Link-Based Authority (PageRank): A key input to the Q* score is a modern version of PageRank, which is now framed as measuring a page’s “distance from a known good source“. The system uses a set of trusted “seed” sites for a given topic, and pages closer to these seeds in the web’s link graph receive a stronger PageRank score, which contributes to a higher Q*.
- Brand Authority & User Engagement: For established sites with sufficient user data, the score is heavily influenced by real-world brand authority signals. Google measures this by looking at “how many times users specifically search for your brand or domain name“, how often they select the site in search results, and how often the brand appears in anchor text. This is complemented by user engagement data from systems like NavBoost, which uses Chrome data.
- Predictive Models for New Sites: When a site is new or lacks sufficient user data, Google uses a predictive model. It analyses the content to create a “phrase model”—a numerical representation of the website—and then “predicts how good your site is likely to be based on its resemblance to known, trusted entities“.
Clearly, a lot goes into Q*.
Insights from The Content Warehouse Leak
Here’s a visualisation of the content data warehouse leak modules and attributes and how it all comes together:

Decompressing the ‘CompressedQualitySignals’ Module
Mike King did a great write-up at the time. I remember when this leaked, this was he first thing I looked for – a quality score module.
If the Q* system is the “engine” that calculates quality; the 2024 leak provided us with its official parts list. It is worth noting when referring to this leak that Google confirmed it was legit and commented on it (from sworn testimony in the recent Google V DOJ Antitrust Trial): “There was a leak of Google documents which named certain components of Google’s ranking system, but the documents don’t go into specifics of the curves and thresholds. The documents alone do not give you enough details to figure it out, but the data likely does.”
I examined a component module named GoogleApi.ContentWarehouse.V1.Model.CompressedQualitySignals, which, based on its description and attributes, is the technical confirmation of the entire “Quality Score” concept.
Its description reveals its critical role:
A message containing per doc signals that are compressed and included in Mustang and TeraGoogle. For TeraGoogle, this message is included in perdocdata which means it can be used in preliminary scoring.
Let’s deconstruct this. These are “compressed signals” used for “preliminary scoring.” The documentation adds a stark warning:
CAREFUL: For TeraGoogle, this data resides in very limited serving memory (Flash storage) for a huge number of documents.
This isn’t just a random collection of data.
This is a document’s essential “rap sheet.” These are the few, critical signals Google must be able to access instantaneously for every document in its index to make a foundational judgment of quality before applying more complex, query-time calculations.
This module is the “cheat sheet” that feeds the Q* system. And what’s on it? A literal roll-call of quality factors. This module is where Google stores the inputs for its quality score, which we can group by theme:
1. Core Quality & Authority Scores
These are the foundational “at-a-glance” scores for the document and site:
siteAuthority: The very attribute we’ve identified as a site-level score “applied in Qstar.”pqData: The encoded “Page Quality” signals.unauthoritativeScore: A specific signal for unauthoritative content.lowQuality: A general score for low-quality pages.vlqNsr: This stands for Very Low Quality Neural Site Rank. The documentation notes this is a specific quality score for the “video” content type.nsrConfidence: A score for Google’s confidence in its own Neutral Site Rank, a key meta-signal.pairwiseqScoringData: Data from a “Pairwise Quality” model, a machine-learning method that ranks documents by comparing them in pairs (e.g., “is Doc A better than Doc B?”).crapsAbsoluteHostSignals: A host-level (site-wide) signal derived fromCraps, Google’s click-and-impression tracking system. This directly links user click behaviour to the core quality profile.
2. Demotions & Penalties
A long list of negative signals that act as “demerits” against the document:
pandaDemotion&babyPandaV2Demotion: Direct confirmation of the Panda update’s legacy, bundled as a core quality signal.scamness: A score (from 0-1023) that measures how “scammy” a page appears.serpDemotion: A signal noting if the page has been demoted based on negative user behaviour in the search results.navDemotion: A demotion possibly related to poor site navigation.exactMatchDomainDemotion: A demotion signal, presumably to lower the rank of “exact match” keyword domains.anchorMismatchDemotion: A demotion for when the anchor text of an incoming link doesn’t match the page’s content.
3. Promotions & Granular/Topical Scores
These are positive scores or highly specific classifiers for niche content:
authorityPromotion: The flip side of demotion, an integer for “authority promotion.”productReview...(group): A whole cluster of attributes showing a granular scoring system just for the “product review” topic. This includes:productReviewPDemoteSite: A demotion confidence score for the entire site.productReviewPUhqPage: A score for the “possibility of a page being an Ultra High Quality review page.”
nsrOverrideBid: A value used in Q* for “emergency overrides,” a powerful action reserved for specific quality-related cases.
4. Topical & Thematic Signals
Signals that define what the site is about, which is foundational to its authority:
topicEmbeddingsVersionedData: Data on topic embeddings, a key signal used to measure a site’s topical authority and focus.
5. A “Living” Score: Experimental & Versioned Signals
Finally, the module’s contents prove the Quality Score isn’t a static, unchanging number but a living, breathing system that is constantly being tested and refined:
experimentalQstarSignal,experimentalQstarSiteSignal: A cluster of “experimental” signals explicitly used by “an experimental Q* component” to “quickly run LEs (Live Experiments) with new components.”nsrVersionedData: A “Versioned NSR score” used for “continuous evaluation of the upcoming NSR version and assess quality impact.”
This module is the technical confirmation of our thesis. It’s not the final score, but the raw ingredients fed directly into the Q* system. It is the “rap sheet,” “cheat sheet,” and “test lab” for Google’s organic Quality Score all rolled into one.
Insights from an Exploit
Further confirming the existence and function of a site-level quality score, Mark Williams-Cook discovered and analysed a separate Google API endpoint exploit.
As detailed in a previous analysis on Hobo Web, this exploit provided a real-time view into how Google scores websites, revealing a Site_Quality attribute that functions as a critical gatekeeper for visibility.
Williams-Cook’s analysis of over 90 million queries revealed that Google calculates this score at the subdomain level on a scale of 0 to 1.
Interestingly, he identified a specific threshold: sites with a quality score below 0.4 were found to be ineligible for prominent search features like Featured Snippets and “People Also Ask” boxes.
This demonstrates that a site must pass a fundamental quality check before its content can even compete for these highly visible SERP features. His research confirmed that this score is derived from the same types of signals mentioned in the main leak and DOJ trial: brand visibility (branded searches), user interactions (clicks), and anchor text relevance.
These findings provide a quantitative layer to the concept of siteAuthority, showing that it is not just an abstract idea but a measurable score with direct, threshold-based consequences for a site’s ranking potential.
The Helpful Content Update: Algorithmically Enforcing Trust
The Helpful Content Update (HCU) acts as the primary algorithmic enforcement mechanism for these principles. Initially a separate system, the HCU is now fully integrated into the main core ranking algorithm. As Google’s Search Liaison Danny Sullivan stated, “It is now part of a ‘core ranking system that’s assessing helpfulness on all types of aspects.”
The HCU is designed to reward “people-first” content that leaves a visitor feeling they have had a “satisfying experience”.
A satisfying experience is intrinsically linked to Trust. The update penalises content that erodes trust, such as pages that merely summarise what others have said without adding value. In this way, the HCU and E-E-A-T are “very closely aligned,” with the update serving to algorithmically identify the signals of helpfulness and trustworthiness that the QRG asks human raters to look for.
Ultimately, the Q* score is the technical culmination of this entire trust-based evaluation. The principles laid out in the QRG and enforced by the HCU are the inputs that the Q* system is engineered to measure.
A high Q* score is the algorithmic reflection of a site that successfully demonstrates the signals of trust, experience, and expertise that Google’s guidelines prioritise.
The Failure State: The Disconnected Entity Hypothesis and QRG Section 2.5.2
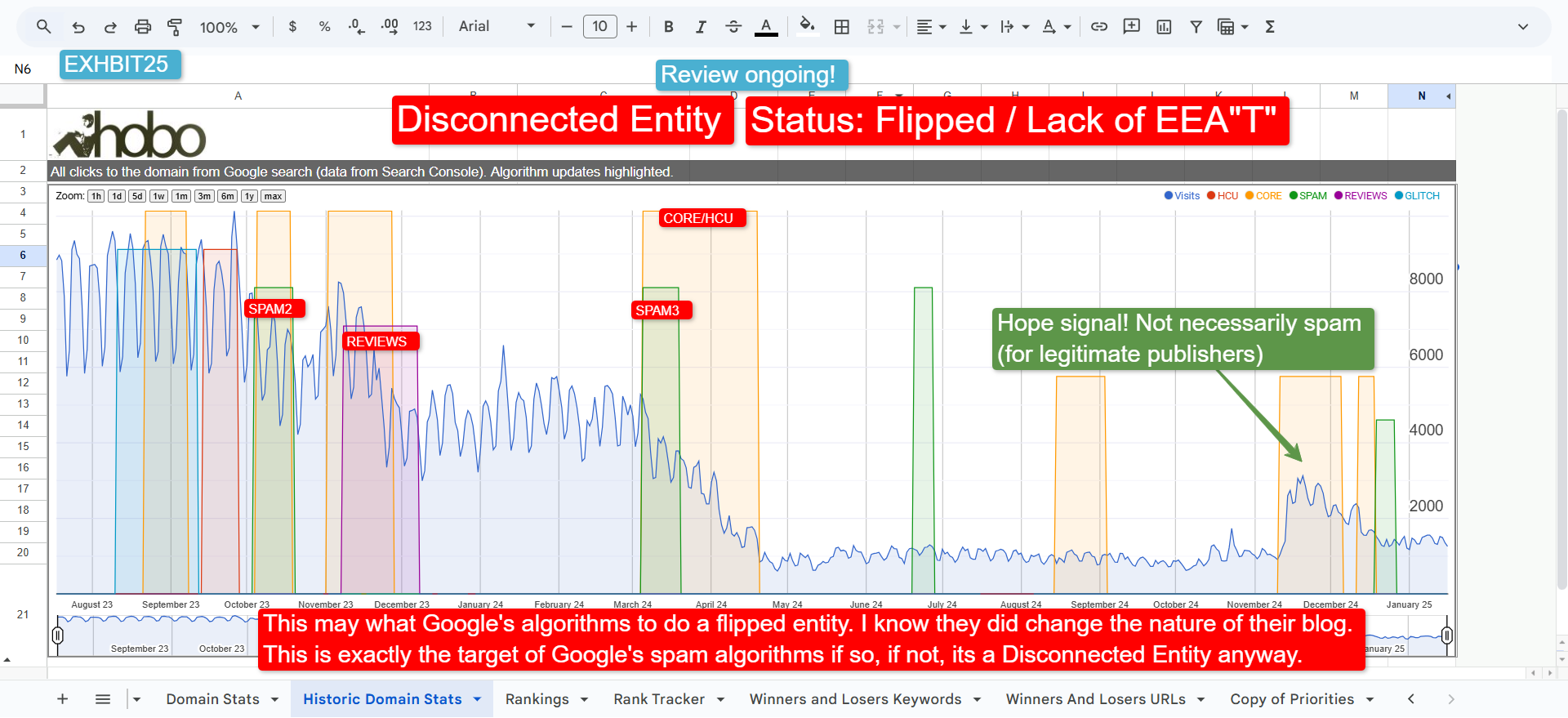
If a site has good content and solid links, why might it still fail to rank? The Disconnected Entity Hypothesis provides a compelling answer, and its foundation lies in a specific instruction given to Google’s human Quality Raters.
The hypothesis posits that Google’s updates target “Disconnected Entities”—websites lacking a strong, verifiable connection to a trusted real-world entity. This isn’t just a theory; it’s based on the explicit instructions in the QRG. Specifically, Section 2.5.2 instructs raters to locate who owns and operates a website and who is responsible for the content.
A lack of this information is what defines a disconnected entity. When a site fails this fundamental transparency test, its quality signals have no entity to attach to. This breaks the entire E-E-A-T evaluation:
-
Experience & Expertise cannot be verified without a known author or organisation.
-
Authoritativeness is diluted because links and mentions don’t point to a recognised entity.
-
Trust is fundamentally missing, leaving a critical gap in the Q* evaluation.
A disconnected entity, even with well-written content, fails the foundational trust check.
As the Helpful Content Update explanation posits, such a site is, by definition, unhelpful, because “A LACK OF TRUST is the biggest lever (at least one of them) to decimate anyone’s rankings”.
The Q* system cannot grant a high Site_Quality score, and it is likely to be filtered or suppressed.
The Recalibration: Why Core Updates Matter
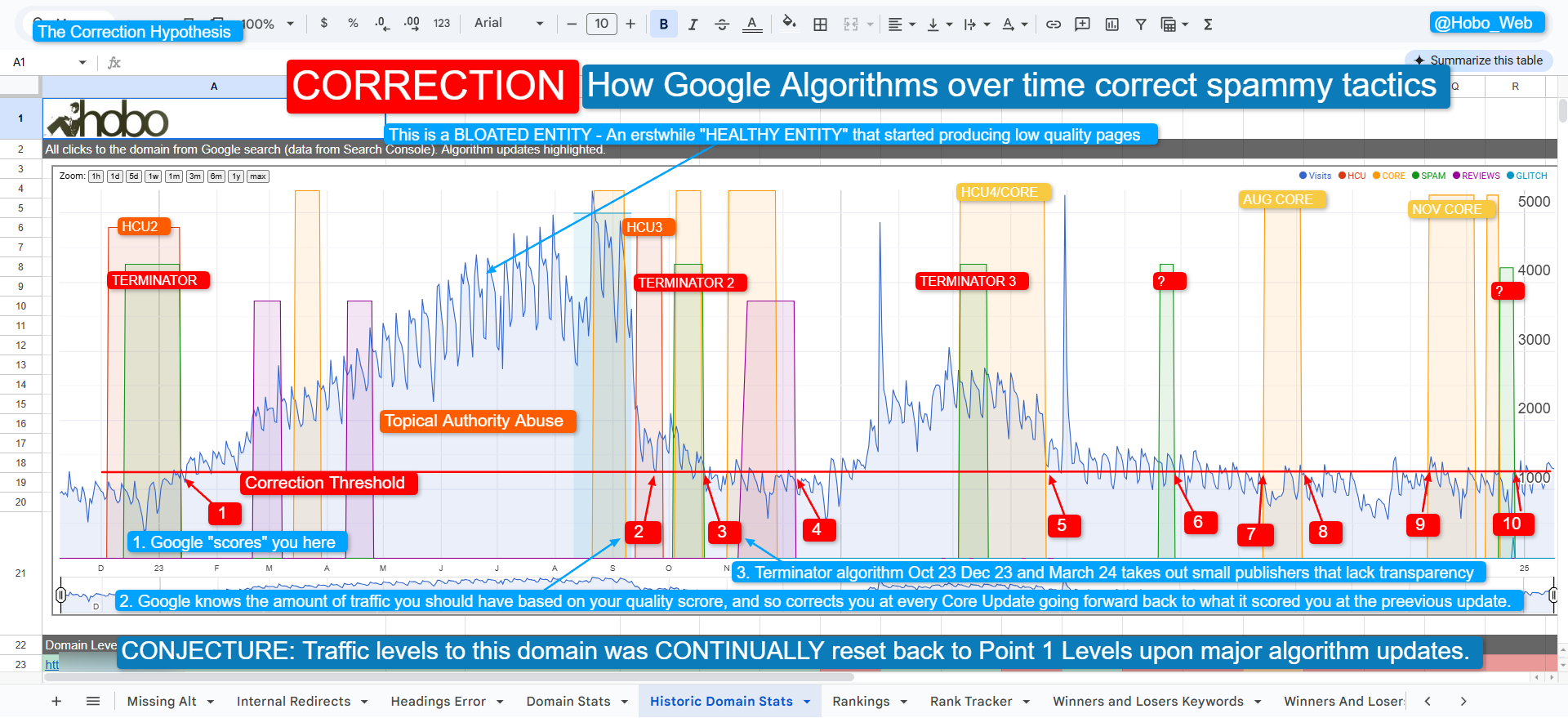
“We figured that site is trying to game our systems… So we will adjust the rank. We will push the site back just to make sure that it’s not working anymore.” Gary Illyes, Google 2016
Google’s core updates are the moments when this entire quality system is recalibrated. Signals related to trust, entity connections, and helpfulness take time to solidify. Between updates, raw link power can sometimes dominate in highly competitive niches.
However, during a core update, the Q* system rebalances all of its inputs. The full weight of the E-E-A-T framework “shows through,” moderating the influence of any single factor. These updates are designed to “correct rankings and terminate and discard spam“, with spam being defined as “an unknown, disconnected, unhealthy entity”.
This is when sites that have successfully established themselves as trustworthy, connected entities see their quality recognised, while disconnected or unhelpful sites may see their visibility decline.
The Role of Human Quality Raters
This entire quality framework is tested and refined by Google’s ~16,000 human Search Quality Raters. These raters are tasked with assessing the quality of search results based on the detailed instructions in the QRG.
As I’ve shared previously, their feedback is then used to evaluate, train and refine the ranking algorithms.
While their ratings do not directly change the ranking of a specific page, they provide the ground-truth data that teaches Google’s machine learning systems what human beings consider to be high-quality, trustworthy content.
The Google Quality Evaluation Guidelines as a Blueprint for the Q* Score
It is reasonable to infer that everything else mentioned in the Quality Rater Guidelines is also measured by the systems that feed the Q* score (and probably even the P* score. Since the 2014 leak of the original guidelines, I have recommended that SEO professionals treat the QRG as a technical blueprint for the signals Google’s algorithms are attempting to replicate. The 2024 leak provides the technical confirmation for this long-held view.
Everything the QRG instructs a human rater to look for can be connected to a plausible algorithmic signal revealed in the leaks. These are not just abstract concepts; they are artefacts that feed the Q* engine. Other interesting examples include:
- Trust (The “Who, How, and Why”): The foundation of the QRG’s trust evaluation is transparency. Google’s own documentation encourages creators to self-assess their content by asking “Who, How, and Why”:
- The “Who” directly corresponds to Section 2.5.2 of the Google Quality Rater Guidelines, which instructs raters to find who is responsible for the site. A failure to provide clear author and ownership information is the primary signal of a Disconnected Entity, which is foundational to the Q* score.
- The “How” concerns the creation process. Google wants to know, “Did you use AI assistance? (If so, how?)”. This is not just a philosophical question. The leak confirms a direct technical link with the
contentEffortattribute, described as an “LLM-based effort estimation for article pages”. This signal helps Google determine how easily a page could be replicated, a key indicator of low-effort, potentially AI-generated content. Furthermore, the QRG instructs raters to check for “typical AI errors such as invented references or inconsistent sentences,” algorithmically flagging content that appears to be mass-produced without context. - The “Why” evaluates the content’s purpose. Raters are asked to determine if the content exists “primarily for helping people” or “primarily for attracting search traffic”. This aligns with the goals of the Helpful Content Update, which penalises content that erodes trust.
The leak contained specific attributes that appear to be directly related to evaluating AI and low-effort content.
These are not just theoretical concepts; they are measurable signals that Google’s systems are designed to capture.
Key AI-Related Attributes from the Leak
The most significant attribute is contentEffort. This is described in the documentation as an “LLM-based effort estimation for article pages”. This is a crucial piece of evidence.
It suggests Google is using its own Large Language Models (LLMs) to analyse content and assign a score based on the perceived “effort” that went into its creation. The likely purpose of this is to identify content that can be easily replicated, a hallmark of low-quality, mass-produced, or AI-generated articles.
The Direct Link to the Quality Rater Guidelines
This technical evidence is the flip side of the coin to the instructions given to Google’s human raters and the guidance provided to creators.
- Penalising Low-Effort AI Content: The Quality Rater Guidelines (QRG) are explicit on this point. A page can receive the “Lowest” quality rating if its main content is “auto or AI generated… with little to no effort, little to no originality, and little to no added value for visitors”. The
contentEffortattribute appears to be the direct algorithmic tool to identify this. - Spotting AI Hallmarks: The guidelines also train raters to look for “typical AI errors such as invented references or inconsistent sentences” and to penalise content that seems like “mass production without context”. This shows that both humans and algorithms are tasked with identifying the tell-tale signs of unedited, low-quality AI output.
- The “How” of Content Creation: This all ties directly into the “How” part of Google’s “Who, How, and Why” framework. In their own documentation for creators, Google asks them to self-assess by asking specific questions about automation :
- “Is the use of automation, including AI-generation, self-evident to visitors through disclosures or in other ways?”
- “Are you providing background about how automation or AI generation was used to create content?”
- “Are you explaining why automation or AI was seen as useful to produce content?”
The existence of the contentEffort signal, combined with this explicit guidance, confirms a direct causal link.
Google is not against AI-generated content in principle, but it has built technical systems to measure the effort, originality, and value of that content. Simultaneously, it is telling creators that transparency about the creation process (the “How”) is a key component of building trust.
A disclaimer about AI use is a direct answer to the questions Google wants creators to address.
Other items worth noting are:
- Ad Experience: The QRG instructs raters to penalise pages with an “excessive amount of ads that distract from or interfere with the main content”. The leak confirms this with attributes like
Interstitial, which specifically relates to disruptive, full-screen ads. - Mobile Friendliness: The QRG asks raters to consider if content “displays well for mobile devices when viewed on them“. This is directly mirrored by the existence of the
SmartphonePerDocDatamodule in the leak, confirming a dedicated set of quality signals for mobile usability. - Page Layout and Usability: Raters are told to evaluate “how easily can visitors navigate to or locate the main content of your pages“. The leak confirms that Google measures proxies for this, such as the average font size of terms in a document, which helps determine the visual hierarchy and readability of the content.
- Website Maintenance: The QRG penalises sites that appear unmaintained or abandoned, for instance, by having a high number of “broken links“. This is algorithmically measured through technical health signals. A site with a high number of broken links or server errors will send negative signals to the systems that feed the Q* score.
This demonstrates that the QRG is not just a philosophical guide; it is the most detailed specification sheet we have for the inputs that determine a site’s foundational Quality Score.
In short, Site_Quality is the output from Q-Star.
E-E-A-T is Google’s Organic Quality Score.

Like this article – you will love the follow up: The ContentEffort Attribute, the Helpful Content System and E-E-A-T. Is Gemini behind the HCU?
Disclosure: Hobo Web uses generative AI when specifically writing about our own experiences, ideas, stories, concepts, tools, tool documentation or research. Our tools of choice for this process is Google Gemini Pro 2.5 Deep Research. This assistance helps ensure our customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was verified as correct by Shaun Anderson. Published on: 22 September 2025 See our AI policy.