QUOTE: “Important: The Lowest rating is appropriate if all or almost all of the MC (main content) on the page is copied with little or no time, effort, expertise, manual curation, or added value for users. Such pages should be rated Lowest, even if the page assigns credit for the content to another source.” – Google Search Quality Evaluator Guidelines, 2017
Duplicate Content Best Practices
Google DOES NOT have a duplicate content penalty, despite the myth. Google rewards unique content and the signals associated with added value. Google filters duplicate content in SERPS. Google DEMOTES copied content in SERPS.
Google DEMOTES manipulative duplicated content in SERPS. Google PENALISES low-quality, verbose, spun content copied from other web pages. Do NOT expect to rank high in Google with content found on other, more trusted sites.
- Only add unique, human-edited, helpful content to your web pages.
- Don’t add content to your pages that is found verbatim on other pages on the web.
- Do not ‘spin‘ text on pages on your site, even with AI.
- Don’t create thin pages with little value added to users.
- Implement the rel=” canonical” link element on all pages on your site to minimise duplicate content.
- Apply 301 permanent redirects where necessary.
- Use the URL parameter handling tool in Google Search Console where necessary.
- Reduce Googlebot crawl expectations.
- Consolidate ranking equity & potential in high-quality canonical pages.
- Minimise boilerplate repetition across your site.
- Don’t block Google from your duplicate content, just manage it better.
- Sites with separate mobile URLs should just move to a responsive design.
- Note that canonical link elements can be ignored by Google.
- Avoid publishing stubs for text “coming soon”.
- Minimise similar content across your pages.
- Do NOT canonicalise component pages in a series to the first page.
- Google don’t use link-rel-next/prev at all. You can use it if you want, but don’t rely on it alone.
- Translated content is not duplicate content.
- Block Google from crawling thin internal search results pages.
- Check for content on your site that duplicates content found elsewhere.
- An easy way to find duplicate content is to use Google search using “quotes”
- Use Google Search Console to fix duplicate content issues on your site.
I’ve audited thousands of websites over 20 years as a professional SEO. Here is what you need to know about SEO in 2022 and a free tool to help you manage your projects or learn about SEO: https://t.co/WwZgEa8yBd A thread (1/10) pic.twitter.com/Abh5m3TOi4
— Shaun Anderson (@Hobo_Web) July 1, 2022
Copied Content
TLDR: ‘Duplicate content‘ is NOT mentioned **once** in the recently published Search Quality Raters Guidelines. ‘Copied content’, is.
Semantics aside, duplicate content is evidently treated differently by Google than copied content, with the difference being the INTENT and nature of the duplicated text.
Duplicated content is often not manipulative and is commonplace on the web and often free from malicious intent. It is not penalised, but it is not optimal. Copied content can often be penalised algorithmically or manually. Don’t be ‘spinning’ ‘copied’ text to make it unique!
Google clearly says that the practice of making your text more ‘unique’, using low-quality techniques like adding synonyms and related words is:
QUOTE: “probably more counter productive than actually helping your website” John Mueller, Google
Google’s Andrey Lipattsev is adamant: Google DOES NOT have a duplicate content penalty.
He clearly wants people to understand it is NOT a penalty if Google discovers your content is not unique and doesn’t rank your page above a competitor’s page.
QUOTE: “You heard right there is no duplicate content penalty… I would avoid talking about duplicate content penalties for spam purposes because then it’s not about duplicate content then it’s about generating in a very often in an automated way content that is not so much duplicated as kind of fast and scraped from multiple places and then potentially probably monetized in some way or another and it just doesn’t serve any purpose other than to gain traffic redirect traffic maybe make some money for the person who created it this is not about content that gets really sort of created for any kind of reason other than just to be there so I person I don’t think about it as duplicate content there is just this disparity it’s the same thing as saying that maybe we created gibberish is some sort of a duplicate content of words but otherwise also exists like I I would really separate those two issues because the things that Aamon led in with URLs generated on WordPress and the things they were going to discuss today later maybe about e-commerce sites and so on I wouldn’t want people to confuse those two.” Andrey Lipattsev, Google 2016
Also, as John Mueller points out, Google picks the best option to show users depending on who they are and where they are. So sometimes, your duplicate content will appear to users where relevant.
This latest advice from Google is useful in that it clarifies Google’s position, which I quickly paraphrase below:
- There is no duplicate content penalty
- Google rewards UNIQUENESS and the signals associated with ADDED VALUE
- Google FILTERS duplicate content
- Duplicate content can slow Google down in finding new content
- XML sitemaps are just about the BEST technical method of helping Google discover your new content
- Duplicate content is probably not going to set your marketing on fire. Copied and spun content certainly isn’t either.
- Google wants you to concentrate signals in canonical documents, and it wants you to focus on making these canonical pages BETTER for USERS.
- For SEO, it is not necessarily the abundance of duplicate content on a website that is the real issue. It’s the lack of positive signals that NO unique content or added value provides that will fail to help you rank faster and better in Google.
A sensible strategy for SEO would still appear to be to reduce Googlebot crawl expectations and consolidate ranking equity & potential in high-quality canonical pages and you do that by minimising duplicate or near-duplicate content.
A self-defeating strategy would be to ‘optimise’ low-quality or non-unique pages or present low-quality pages to users.
Webmasters are confused about ‘penalties’ for duplicate content, which is a natural part of the web landscape, because Google claims there is NO duplicate content penalty, yet rankings can be impacted negatively, apparently, by what looks like ‘duplicate content’ problems.
The reality is that if Google classifies your duplicate content as THIN content, or MANIPULATIVE BOILER-PLATE or NEAR DUPLICATE ‘SPUN’ content, then you probably DO have a severe problem that violates Google’s website performance recommendations and this ‘violation’ will need ‘cleaned’ up – if – of course – you intend to rank high in Google.
Google wants us to understand that MANIPULATIVE BOILER-PLATE or NEAR DUPLICATE ‘SPUN’ content is NOT ‘duplicate content’.
Duplicate content is not necessarily ‘spammy’ to Google. Sign up for our Free SEO training course to find out more.
The rest of it is e.g:
QUOTE: “Content which is copied, but changed slightly from the original. This type of copying makes it difficult to find the exact matching original source. Sometimes just a few words are changed, or whole sentences are changed, or a “find and replace” modification is made, where one word is replaced with another throughout the text. These types of changes are deliberately done to make it difficult to find the original source of the content. We call this kind of content “copied with minimal alteration.” Google Search Quality Evaluator Guidelines, 2017
At the ten minute mark in a recent video, John Mueller of Google also clarified, with examples, that there is:
QUOTE: “No duplicate content penalty” but “We do have some things around duplicate content … that are penalty worthy” John Mueller, Google, 2015
What Is Duplicate Content?
Here is a definition from Google:
QUOTE: “Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin…..” Google Webmaster Guidelines, 2020
It’s crucial to understand that if, as a Webmaster, you republish posts, press releases, news stories or product descriptions found on ***other*** sites, then your pages are very definitely going to struggle to gain traction in Google’s SERPs (search engine results pages).
Google doesn’t like using the word ‘penalty’ but if your entire site is made of entirely of republished content – Google does not want to rank it above others who provide more of a ‘value add’ – and that can be in many areas.
If you have a multiple site strategy selling the same products – you are probably going to cannibalise your traffic in the long run, rather than dominate a niche, as you used to be able to do.
This is all down to how a search engine filters duplicate content found on other sites – and the experience Google aims to deliver for it’s users – and it’s competitors.
Mess up with duplicate content on a website, and it might look like a penalty as the end-result is the same – important pages that once ranked might not rank again – and new content might not get crawled as fast as a result.
Your website might even get a ‘manual action’ for thin content.
A good rule of thumb is; do NOT expect to rank high in Google with content found on other, more trusted sites, and don’t expect to rank at all if all you are using is automatically generated pages with no ‘value add’.
While there are exceptions to the rule, (and Google certainly treats your OWN duplicate content on your OWN site differently), your best bet in ranking is to have one single (canonical) version of content on your site with rich, unique text content that is written specifically for that page.
Google wants to reward RICH, UNIQUE, RELEVANT, INFORMATIVE and REMARKABLE content in its organic listings – and it has raised the quality bar over the last few years.
If you want to rank high in Google for valuable key phrases and for a long time – you better have good, original content for a start – and lots of it.
A very interesting statement in a recent webmaster hangout was “how much quality content do you have compared to low-quality content“. That indicates Google is looking at this ratio. John says to identify “which pages are high-quality, which pages are lower quality so that the pages that do get indexed are really the high-quality ones.“
Gary IILyes chipped in recently –
QUOTE: “DYK Google doesn’t have a duplicate content penalty, but having many URLs serving the same content burns crawl budget and may dilute signals” Gary IILyes, Google, 2017
Google is giving us a lot more specific information these days in particular areas.
QUOTE: “what does ‘ duplicate content’ mean? Content copied from other websites or original content that’s duplicated within a website? Which one to avoid most? Can a web site be demoted if original content duplicates within web site pages?”
A question was asked in a webmaster hangout and John replied:
QUOTE: “so that’s that’s a complicated question actually. So we have different types of duplicate content that we look at there from our point of view there are lots of technical reasons why within a website you might have the same content on multiple pages and from our point of view we try to help fix that for you as much as possible” John Mueller, Google 2018
And
QUOTE: “so if we can recognize that these pages have the same content on them or the same primary content on them then we’ll try to fold that into one and make sure thatall of the signals we have focus on that one page “ John Mueller, Google 2018
And, here is where it gets trickier:
QUOTE: “on the other hand if this is content copied from multiple locations then that gets to be a bit trickier for us because then we have the situation that this website has that its content on another website has the same content on it which one is actually the one that we need to show and search that makes it a lot harder because then it’s not a question between like which one of your pages we want to show but which one of these pages by different people or on different servers do we want to show.” John Mueller, Google 2018
And when it gets spammy:
QUOTE: “the trickiest one or the one where maybe it’s not trickiest the one where you really need to watch out for with regards to duplicate content is if within your content the majority of the content is copied from other sources or the majority of the content is kind of rewritten repurposed from other sources then when our algorithms look at your website they’re like well I’ve seen everything from this website before there is nothing of value here that we would miss if we didn’t Index this website because all of this content is based on something that’s available on different parts of the web.” John Mueller, Google 2018
And finally:
QUOTE: “and in a case like that it can happen that our algorithms say we need to kind of ignore this website completely we don’t need to focus on it in the search the manual webspam team might even come in and say actually it’s it’s a waste of our resources to even look at this website because it’s just pure copies of all of these other websites maybe slightly rewritten but it’s not there’s nothing unique here and in those cases we might remove a website completely from search so that’s kind of the the one that you really need to watch out for if it’s really just a matter of your content on your website in multiple URLs then from a technical point of view you can improve that slightly by kind of having fewer copies on the website but that’s not something that you really need to watch out for.” John Mueller, Google 2018
Sign up for our Free SEO training course to find out more.
Is There A Penalty For Duplicate Content On A Website?
Google has given us some explicit guidelines when it comes to managing duplication of content.
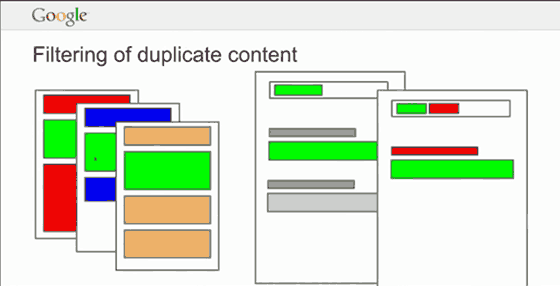
John Mueller clearly states in the video where I grabbed the above image:
QUOTE: “We don’t have a duplicate content penalty. It’s not that we would demote a site for having a lot of duplicate content.” John Mueller, Google, 2014
and
QUOTE: “You don’t get penalized for having this kind of duplicate content” – John Mueller, Google, 2014
…in which he was talking about very similar pages. John says to “provide… real unique value” on your pages.
I think that could be understood that Google is not compelled to rank your duplicate content.
If it ignores it, it’s different from a penalty. Your original content can still rank, for instance.
If “essentially, they’re the same, and just variations of keywords” that should be ok, but if you have ‘millions‘ of them- Googlebot might think you are building doorway pages, and that IS risky.
Generally speaking, Google will identify the best pages on your site if you have a decent on-site architecture and unique content.
The advice is to avoid duplicate content issues if you can and this should be common sense.
Google wants (and rewards) original content – it’s a great way to push up the cost of SEO and create a better user experience at the same time.
Google doesn’t like it when ANY TACTIC it’s used to manipulate its results, and republishing content found on other websites is a common practice of a lot of spam sites.
QUOTE: “Duplicate content on a site is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results.” Google, 2020
You don’t want to look anything like a spam site; that’s for sure – and Google WILL classify your site… as something.
The more you can make it look a human-made every page on a page by page basis with content that doesn’t appear exactly in other areas of the site – the more Google will ‘like’ it.
Google does not like automation when it comes to building the main content of a text-heavy page; that’s clear.
I don’t mind multiple copies of articles on the same site – as you find with WordPress categories or tags, but I wouldn’t have tags and categories, for instance, and expect them to rank well on a small site with a lot of higher quality competition, and especially not targeting the same keyword phrases in a way that can cannibalise your rankings.
I prefer to avoid repeated unnecessary content on my site, and when I do have 100% automatically generated or syndicated content on a site, I tell Google NOT to index it with a noindex in meta tags or XRobots or Robots.txt it out completely.
I am probably doing the safest thing, as that could be seen as manipulative if I intended to get it indexed.
Google won’t thank you, either, for spidering a calendar folder with 10,000 blank pages on it, or a blog with more categories than original content – potentially a lot of thin pages – why would they?
Sign up for our Free SEO training course to find out more.
Can You Duplicate Your Own Content Within Your Own Site?
Yes, within reason but when you duplicate text on more than one page on your site you give Google the chance to rank multiple pages for the same query and some pages rank better than others, thus negatively impacting your organic traffic levels over the longer term.
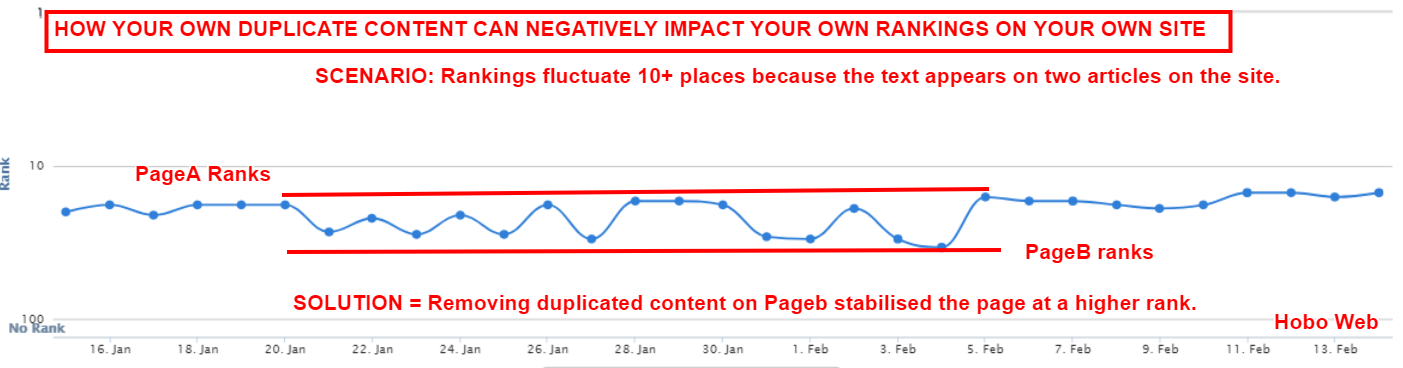
Some much larger sites reuse unique content on product and multiple category pages, for instance.
Google will not penalise this practice but:
QUOTE: “What generally happens in a case like that is we find the same text snippet on multiple pages on your website and that’s perfectly fine… What will however happen is when someone is searching for something just in that text snippet then all of these different pages are kind of competing against each other in the search results and we will try to pick one of these pages to show and try to figure out which one is the most relevant… So that could be that maybe your category pages see more traffic but that would kind of come at the cost of your product detail pages seeing less traffic.” John Mueller, Google 2018
How Does Google Work Out The Primary Version Of Duplicate Content?
The following statement from a fellow SEO rings true on some levels evidently:
QUOTE: “If there are multiple instances of the same document on the web, the highest authority URL becomes the canonical version. The rest are considered duplicates.” Dan Petrovic,Dejan, 2018
There is an interesting comment on that page too:
QUOTE: “I have a client that has a PDF on their site. They are not the original business to feature it, many people are distributors for this product line. I noticed in GSC that they are credited with incoming links, b/c the PDF exists on other sites.” Unverified Author, 2018
It may not be an entirely accurate statement nor the complete the picture but it is very interesting.
Some Google patents at least indicate some amount of thought has been put into determining the primary version of duplicated content across many sites and it appears is not limited to link authority.
QUOTE: “Is this a little-known ranking factor? The Google patent on identifying a primary version of duplicate pages does seem to find some importance in identifying what it believes to be the most important version among many duplicate documents.” Bill Slawski, 2018
I have long thought it sensible to publish to your own site, making your own the site the canonical or primary source of content you publish. Publish duplicate content to other sites to get it noticed, for sure, but where allowed link back to the original article and even better use a canonical link element to point back to your original article on your own site and help Google forward legitimate positive signals along to you (if Google wants to, that is).
Sign up for our Free SEO training course to find out more.
What is Boilerplate Content?
Wikipedia says of ‘boilerplate’ content:
QUOTE: “Boilerplate is any text that is or can be reused in new contexts or applications without being greatly changed from the original.” WIKI, 2020
…and Google says to:
QUOTE: “Minimize boilerplate repetition” Google Webmaster Guidelines, 2020
Google is very probably looking to see if your pages ‘stand on their own‘ – as John Mueller is oft fond of saying.
How would they do that algorithmically? Well, they could look to see if text blocks on your pages were unique to the page, or were very similar blocks of content to other pages on your site.
If this ‘boilerplate’ content is the content that makes up the PRIMARY content of multiple pages – Google can easily filter to ignore – or penalise – this practice.
The sensible move would be to listen to Google – and minimise – or at least diffuse – the instances of boilerplate text, page-to-page on your website.
Note that THIN CONTENT exacerbates SPUN BOILERPLATE TEXT problems on a site – as THIN CONTENT just creates more pages that can only be created with boilerplate text – itself, a problem.
E.G. – if a product has 10 URLs – one URL for each colour of the product, for instance – then the TITLE, META DESCRIPTION & PRODUCT DESCRIPTION (and other elements on the page) for these extra pages will probably rely on BOILERPLATE techniques to create them, and in doing so – you create 10 URLs on the site that do ‘not stand on their own’ and essentially duplicate text across pages.
It’s worth listening to John Mueller’s recent advice on this point. He clearly says that the practice of making your text more ‘unique’, using low-quality techniques is:
QUOTE: “probably more counter productive than actually helping your website” – John Mueller, Google 2015
If you have many pages of similar content your site, Google might have trouble choosing the page you want to rank, and it might dilute your capability to rank for what you do what to rank for.
How Does Google Deal With Duplicate Product Descriptions Across Multiple Retailer Sites?
QUESTION: “Often with designer furniture, the designer’s description of that furniture is used across dozens of sites with very minor changes…” Aamon Johns, 2017
John Mueller responded:
QUOTE: “I guess they’re two different to two different things that we need to look at on the one hand when the whole page is duplicated that’s kind of the easy situation where we can tell well this is probably exactly the same thing we can kind of skip that and the other one is what you’re talking about when a part of the page is duplicated so like that furniture blurb what a lot of sites have maybe the footer or maybe they have some kind of disclaimer on the bottom those kind of things where we see this chunk of text duplicated across a whole lot of different pages and what happens in those cases is we index all of those pages because the rest of the page is kind of unique and kind of valuable so we index those pages and then when it comes to generating the search results if we can tell that actually the part that people are searching for is duplicated across all of these pages then we’ll pick one of these pages and show it because they’re essentially equivalent so if you have I don’t know the default blurb for a piece of furniture and someone searches for a piece of text within that default blurb then we’ll know well this is the same text on all of these sites the snippet would be the same thing so it doesn’t really make sense to show all of these different pages to that user at that time of course as soon as we know more about the query as soon as it’s not just from that duplicated piece of text then it’s a lot easier for us to say well this is the one that really matches what this user is looking for so for furniture maybe the location maybe if they have additional details in the query about that type of furniture they’re looking for so all of these things can help us to figure out which one of these pages with that duplicated blurb is the one that we want to show to people.” John Mueller, Google 2017
Should I Rewrite Product Descriptions To Make The Text Unique?
Probably.
Whatever you do, beware ‘spinning the text’ – Google might have an algorithm or two focused on that sort of thing:
John has also clarified:
QUOTE: “Could we benefit if our product pages have more virtual descriptions than other pages on the web with the same products? Can a lot of the product descriptions that are well-written be considered better?” Longer isn’t necessarily better. So it’s really a case of do you have something that’s useful for the user? Is that relevant for the people who are searching? Then maybe we’ll try to show that. And just artificially rewriting content often kind of goes into the area of spinning the content where you’re just kind of making the content look unique, but actually you’re not really writing something unique up. Then that often leads to just lower quality content on these pages. So artificially re-writing things like swapping in synonyms and trying to make it look unique is probably more counterproductive than it actually helps your website. So instead, I’d really focus on the unique value that you could provide through your website which could be something that’s more than just like a slightly re-written description but rather your expert opinion on this product, for example, or the experience that you’ve built up over time on this specific product that you can show to users that does provide more value to the people on the web.” John Mueller, 2015
Sign up for our Free SEO training course to find out more.
Is There A Google Penalty For Spun Content?
John Muller confirmed in September 2019 that indeed Google will penalise spun content if generating “textual pages“. I would think that means MC (the Main Content of a page).
QUOTE: “Does Google penalize for using spun content? Yes so anytime you’re using auto generated content to create pages textual pages like that that would be considered against our webmaster guidelines so that’s something that I would definitely try to avoid there.” John Mueller, Google 2019
Does Having Different Urls For A Product Attribute (Like Size, Amount, Weight, Colour, Volume) Cause Duplicate Content Problems?
QUOTE: “You wouldn’t create individual pages for every size and color variation. You would say, well, this shoe is also available in these five colors, or in these seven sizes. So that’s something you would kind of mix into the specific product page, but you wouldn’t create separate pages for that.” John Mueller, Google, 2014
In the recent past, a product with 10 colours would end up having 10 pages on the site, one for each colour variant attribute. Looking at the pages, everything would be duplicate page to page, apart from the colour, size or another variant attribute of the product.
Webmasters went a few steps further in an attempt to make each page “unique”…. manually or automatically keyword spinning product variations and entire descriptions to rank in Google, but adding no real value add to the page.
For many sites, Google prefers not to rank pages like that, instead, it prefers one canonical detailed product page, with all variant attributes mentioned on that page, UNLESS you have unique content for the variant page that is not just low-quality spun text.
QUOTE: “variations of product “colors…for product page, but you wouldn’t create separate pages for that.” With these type of pages you are “always balancing is having really, really strong pages for these products, versus having, kind of, medium strength pages for a lot of different products.“ John Mueller, Google, 2014
John says:
QUOTE: “one kind of really, really strong generic page” trumps “hundreds” of mediocre ones.” John Mueller, Google, 2014
It’s not so much a duplicate content penalty, it’s that multiple variant pages of the same product dilute ranking signals in a way that one canonical product page would not, and that variant product pages are often not the optimal set-up to rank in Google.
A good rule of thumb is that if you have a lot of pages that look duplicate to you apart from one or two items on the page, then those pages should probably be “folded together” into one strong page.
QUOTE: “So if you have a product page and you have the different variations listed there, then we’ll be able to pick that up from that product page directly. I usually recommend to make separate pages if there is really something unique that you’re offering there that people are explicitly looking for. So if people are explicitly looking for– I don’t know– a pink iPhone with a certain model number and that’s something that’s very different from all the other iPhone models that are out there, then that’s something that might make sense to have a separate page for. But then you would also have unique content for it, as well. You’d have kind of explaining why this is pink and glow in the dark or whatever is kind of unique about this specific model. So that’s something where, if you do have something that you want to list as something separate and you wanted to rank for that separate thing, then I would create separate pages for it.” John Mueller, Google, 2016
John continues:
QUOTE: “On the other hand, if it’s just an attribute of an existing kind of product– if it’s like this shoe is available in these five sizes and these three colors– then that’s something I would just mention on a normal product page itself. So the thing that’s always happening there is you’re balancing between having a strong product page where you have one page for these different variations and kind of diluting that content and separating it out into multiple variation pages where each of these variation pages will have a lot more trouble to rank because we have to rank it separately. So that’s something where if you do have something unique and compelling to offer as in one specific variation, then fine. That can maybe rank by itself. But otherwise I would recommend more to concentrate things into one really strong product page.” John Mueller, Google, 2016
and
QUOTE: “If you can’t make something unique for that specific variation, I would just fold it into the normal product page. And people searching for that variation, they will still be able to find that product page. So that’s something where if you can’t do something unique and special for that specific variation, then really make a strong product page instead. Because that can still rank. You still have the attributes listed there as well. So if someone is searching for an iPhone in pink, then you have that kind of that match of those two phrases there anyway.” John Mueller, Google, 2016
and
QUOTE: “So you might have– I don’t know– the 64 megabyte or 64 gigabyte, the 128 gigabyte or whatever different versions of the device there. And for all of those variations, you wouldn’t make separate pages because it’s essentially just an attribute of that product.” John Mueller, Google, 2016
Ecommerce SEO Tip:
Create and publish strong, detailed, product pages and do not split up the product content into multiple alternative, indexable product variant URLs to facilitate ranking for every individual variant attribute of the product, be it colour, size, weight or volume. One page should rule them all, so to speak.
How Does Google Rate ‘Copied‘ Main Content?
QUOTE: “This is where you are swimming upstream. Copied main content is probably going to get a low rating. Copied content is not going to be a long-term strategy when creating a unique page better than your competitions’ pages.” Shaun Anderson, Hobo 2020
How To Manage Content Spread Across Multiple Domains
This is a good video (note it has somewhat outdated information about cross-domain rel canonical)
Matt Cutts updates advice on sing cross-domain rel canonical in the following video:
If you have content spread amongst multiple domains, do not expect to get all the versions appearing in Google SERPs at the same time.
This sort of duplicate content is not going to improve quality scores, either.
QUOTE: “when large portions of the website are copied across both of these sites then we assume that actually the whole website is kind of a copy of another and we try to help you by just picking one and showing that so if you don’t want that to happen then make sure that these pages are really unique that the whole website on its own can stand on its own is not seen as mostly a copy of another.” John Mueller, Google 2018
If you are following the rules whilst duplicating content across multiple domains, I would pick one canonical url on one website (the primary website) and use cross-domain canonical link elements to tell Google which is the primary URL. This way you meet Google’s guidelines, site quality scores should not be impacted negatively and you consolidate all ranking signals in one of these URLs so it can rank as best it can against competing pages.
Sign up for our Free SEO training course to find out more.
How To Deal With Content Spread Across Multiple TLDs?
QUOTE: “Do make sure that it is localized. So spell things the way that someone in the United Kingdom would spell them. Or make sure that your currency units are correct. Check on those sorts of details. But in general, I wouldn’t worry about that being classified as spam.” Matt Cutts, Google (Ex) 2011
Does Google Treat Translated Content as Duplicated Content?
QUOTE: “So if you have content in German and English, even if it’s the same content but translated, that’s not duplicate content. It’s different words. Different words on the page. These are translations, so it’s not naturally a duplicate.” John Mueller, Google 2015
No. Remember, though, to specify language alternatives using the hreflang attribute.
QUOTE: “Yes if the content is the same then it’s seen as duplicate content that’s kind of I guess the definition of duplicate content when it comes to international sites like this what generally happens is we would pick one URL as a canonical and we would use the Href Lang annotations to swap out the appropriate URL in the search results so indexing wise we try to focus on one version because it’s all the same and in the search results we would just swap out the URL.” John Mueller, Google
Sign up for our Free SEO training course to find out more.
How To Manage Duplicate Content When Reporting News Stories
QUOTE: “So if all you’re doing is taking a wire story or some other syndicate that’s produced things, and you slap that up, and it’s exactly the same text, then probably users don’t want to see 17 different copies of that whenever they do a search. More likely we’d want to see the site that’s considered more authoritative, the site that does original reporting, the site that at least writes their own version of the story rather than just re-using that syndicated particular document. It’s not the case that you need to worry about making up news. If you are the sort of site who has expertise on a particular topic, I would say just make sure that you write the article yourself rather than just using the same article that everybody else is using. At the same time, you would probably benefit by asking yourself, do I have any value add? Do I have any expertise? Because if all you’re doing is taking a story and just rehashing it, and not adding any unique insight, or anything that’s different, a different angle, no unique reporting, you didn’t contact anybody in the story, then it is a little harder to get noticed, because you sometimes get lost in the noise.” Matt Cutts, Google 2012
What is ‘Near-Duplicate’ Content, to Google?
When asked on Twitter, Googler Gary Illyes responded:
QUOTE: “Think of it as a piece of content that was slightly changed, or if it was copied 1:1 but the boilerplate is different.” Gary Illyes, Google 2017
Based on research papers, it might be the case that once Google detects a page is a near duplicate of something else, it is going to find it hard to rank this page against the source.
Can Duplicate Content Rank in Google?
Yes. There are strategies where this will still work, in the short term.
Opportunities are (in my experience) reserved for local and long tail SERPs where the top ten results page is already crammed full of low-quality results, and the SERPs are shabby – certainly not a strategy for competitive terms.
There’s not a lot of traffic in long tail results unless you do it en-mass and that could invite further site quality issues, but sometimes it’s worth exploring if using very similar content with geographic modifiers (for instance) on a site with some “domain authority” (for want of a better word) has the opportunity.
Very similar content can be useful across TLDs too. A bit spammy, but if the top ten results are already a bit spammy…
If low-quality pages are performing well in the top ten of an existing long tail SERP – then it’s worth exploring – I’ve used it in the past.
I always thought if it improves user experience and is better than what’s there in those long tail searches at present, who’s complaining?
It not exactly best practice SEO and I’d be nervous about creating any low-quality pages on your site these days.
Too many low-quality pages might cause you site-wide issues in the future, not just page level issues.
Original Content Is King, they say
Stick to original content, found on only one page on your site, for best results – especially if you have a new/young site and are building it page by page over time… and you’ll get better rankings and more traffic to your site (affiliates too!).
Yes – you can be creative and reuse and repackage content, but I always make sure if I am asked to rank a page I will require original content on the page.
Should I Block Google From Indexing My Duplicate Content?
No. There is NO NEED to block your own Duplicate Content
There was a useful post in Google forums a while back with advice from Google how to handle very similar or identical content:
“We now recommend not blocking access to duplicate content on your website, whether with a robots.txt file or other methods” John Mueller, Google, 2015
John also goes on to say some good advice about how to handle duplicate content on your own site:
- Recognize duplicate content on your website.
- Determine your preferred URLs.
- Be consistent on your website.
- Apply 301 permanent redirects where necessary and possible.
- Implement the rel=”canonical” link element on your pages where you can.
- Use the URL parameter handling tool in Google Search Console where possible.
Webmaster guidelines on content duplication used to say:
QUOTE: “Consider blocking pages from indexing: Rather than letting Google’s algorithms determine the “best” version of a document, you may wish to help guide us to your preferred version. For instance, if you don’t want us to index the printer versions of your site’s articles, disallow those directories or make use of regular expressions in your robots.txt file.” Google, 2020
but now Google is pretty clear they do NOT want us to block duplicate content, and that is reflected in the guidelines.
Google does not recommend blocking crawler access to duplicate content (dc) on your website, whether with a robots.txt file or other methods.
If search engines can’t crawl pages with dc, they can’t automatically detect that these URLs point to the same content and will therefore effectively have to treat them as separate, unique pages.
A better solution is to allow search engines to crawl these URLs, but mark them as duplicates by using the
rel="canonical"link element, the URL parameter handling tool, or 301 redirects.In cases where DC leads to us crawling too much of your website, you can also adjust the crawl rate setting in Webmaster Tools.
DC on a site is not grounds for action on that site unless it appears that the intent of the DC is to be deceptive and manipulate search engine results.
If your site suffers from DC issues, and you don’t follow the advice listed above, we do a good job of choosing a version of the content to show in our search results.
You want to minimise dupe content, rather than block it, I find the best solution to handling a problem is on a case by case basis.
Sometimes I will block Google when using OTHER people’s content on pages. I never block Google from working out my own content.
Google says it needs to detect an INTENT to manipulate Google to incur a penalty, and you should be OK if your intent is innocent, BUT it’s easy to screw up and LOOK as if you are up to something fishy.
It is also easy to fail to get the benefit of proper canonicalisation and consolidation of relevant primary content if you don’t do basic housekeeping, for want of a better turn of phrase.
Sign up for our Free SEO training course to find out more.
Is A Mobile Site Counted As Duplicate Content?
QUOTE: “Sites with separate mobile URLs should just move to a responsive design anyway…. (Separate mobile URLs makes everything much harder than it needs to be)” John Mueller, Google 2019
How Does Google Pick A Canonical URL For Your Page?
In September 2019 in the video above, Google’s John Mueller very recently aimed again to clarify how Google chooses a canonical URL from all the duplicate variant URLs available to it when it crawls your website. and offers some advice on how to help Google choose a canonical URL for your page:
QUOTE: “It’s quite common for a website to have multiple unique URLs that lead to the same content …ideally we wouldn’t even run across any of these alternate versions which is why we recommend picking one URL format and using it consistently across your website…” John Mueller, Google, 2019
How To Use Canonical Link Elements Properly
The canonical link element is extremely powerful and very important to include on your page. Every page on your site should have a canonical link element, even if it is self referencing. It’s an easy way to consolidate ranking signals from multiple versions of the same information. Note: Google will ignore misused canonicals given time.
Google recommends using the canonical link element to help minimise content duplication problems and this is of the most powerful tools at our disposal.
QUOTE: “If your site contains multiple pages with largely identical content, there are a number of ways you can indicate your preferred URL to Google. (This is called “canonicalization”.)” Google, 2020
Google SEO – Matt Cutts from Google shared tips on the rel=”canonical” tag (more accurately – the canonical link element) that the 3 top search engines now support.
Google, Yahoo!, and Microsoft have all agreed to work together in a:
QUOTE: “joint effort to help reduce duplicate content for larger, more complex sites, and the result is the new Canonical Tag”.
Example Canonical Tag From Google Webmaster Central blog:
<link rel="canonical" href="http://www.example.com/product.php?item=swedish-fish" />
The process is simple. You can put this link tag in the head section of the duplicate content URLs if you think you need it.
Should pages have self-referencing Canonical link elements?
QUOTE: “I recommend doing this self-referential canonical because it really makes it clear to us which page you want to have indexed, or what the URL should be when it is indexed. Even if you have one page, sometimes there’s different variations of the URL that can pull that page up. For example, with parameters in the end, perhaps with upper lower case or www and non-www. All of these things can be cleaned up with a rel canonical tag.” John Mueller, Google 2017
I add a self-referring canonical link element as standard these days – to ANY web page – to help work Google work out exactly which is the canonical url I am trying to rank.
Google, 2020 has offered us some advice on properly using canonicals:
Is rel=”canonical” a hint or a directive?
QUOTE: “It’s a hint that we honor strongly. We’ll take your preference into account, in conjunction with other signals, when calculating the most relevant page to display in search results.” Google
Can I use a relative path to specify the canonical, such as <link rel=”canonical” href=”product.php?item=swedish-fish” />?
QUOTE: “Yes, relative paths are recognized as expected with the <link> tag. Also, if you include a<base> link in your document, relative paths will resolve according to the base URL.” Google, 2009
Is it okay if the canonical is not an exact duplicate of the content?
QUOTE: “We allow slight differences, e.g., in the sort order of a table of products. We also recognize that we may crawl the canonical and the duplicate pages at different points in time, so we may occasionally see different versions of your content. All of that is okay with us.” Google, 2009
What if the rel=”canonical” returns a 404?
QUOTE: “We’ll continue to index your content and use a heuristic to find a canonical, but we recommend that you specify existent URLs as canonicals.“Google, 2009
What if the rel=”canonical” hasn’t yet been indexed?
QUOTE: “Like all public content on the web, we strive to discover and crawl a designated canonical URL quickly. As soon as we index it, we’ll immediately reconsider the rel=”canonical” hint.” Google, 2009
What if I have contradictory rel=”canonical” designations?
QUOTE: “Our algorithm is lenient: We can follow canonical chains, but we strongly recommend that you update links to point to a single canonical page to ensure optimal canonicalization results.” Google, 2009
Can this link tag be used to suggest a canonical URL on a completely different domain?
QUOTE: The answer is yes! We now support a cross-domain rel=”canonical” link element.” Google, 2009
Canonical Link Elements can be ignored by Google:
QUOTE: “It’s possible that we picked this up and we say oh this is good enough but if the pages are not equivalent if they’re not really the same then it’s also possible that our algorithms look at this and say well this rel canonical is probably accidentally set like this and we should ignore it” John Mueller, Google 2018
Can rel=”canonical” be a redirect?
QUOTE: “Yes, you can specify a URL that redirects as a canonical URL. Google will then process the redirect as usual and try to index it.” Google, 2009
Canonical link elements can be treated as redirects
QUOTE: “in general when you have a canonical from one page to the other one and we notice its a confirmed thing and the same content is up on both of these pages and you you have the internal links also pointing to your new canonical then usually we kind of treat that as a redirect” John Mueller, Google 2018
Tip – Redirect old, out of date content to new, freshly updated articles on the subject, minimising low-quality pages and duplicate content while at the same time, improving the depth and quality of the page you want to rank.
QUOTE: “301 Redirects are an incredibly important and often overlooked area of search engine optimisation” Shaun Anderson, Hobo 2020
Tips from Google
As with everything Google does – Google has had its own critics about its use of duplicate content on its own site for its own purposes:
There are some steps you can take to proactively address duplicate content issues, and ensure that visitors see the content you want them to:
QUOTE: “Use 301s: If you’ve restructured your site, use 301 redirects (“RedirectPermanent”) in your .htaccess file to smartly redirect users, Googlebot, and other spiders. (In Apache, you can do this with an .htaccess file; in IIS, you can do this through the administrative console.)” Google, 2020
QUOTE: “Be consistent: “Try to keep your internal linking consistent. For example, don’t link to
http://www.example.com/page/andhttp://www.example.com/pageandhttp://www.example.com/page/index.htm.” Google, 2020
I would also ensure your links are all the same case and avoid capitalisation and lower case variations of the same URL.
This type of duplication can be quickly sorted keeping internal linking consistent and proper use of canonical link elements.
QUOTE: “Use top-level domains: To help us serve the most appropriate version of a document, use top-level domains whenever possible to handle country-specific content. We’re more likely to know that
http://www.example.decontains Germany-focused content, for instance, thanhttp://www.example.com/deorhttp://de.example.com.” Google, 2020
Google also tells Webmasters to choose a preferred domain to rank in Google:
QUOTE: “Use Webmaster Tools to tell us how you prefer your site to be indexed: You can tell Google your preferred domain(for example,
http://www.example.comorhttp://example.com).” Google
…although you should ensure you handle such redirects server side, with 301 redirects redirecting all versions of a URL to one canonical URL (with a self-referring canonical link element).
QUOTE: “Minimize boilerplate repetition: For instance, instead of including lengthy copyright text on the bottom of every page, include a very brief summary and then link to a page with more details. In addition, you can use the Parameter Handling tool to specify how you would like Google to treat URL parameters. Understand your content management system: Make sure you’re familiar with how content is displayed on your web site. Blogs, forums, and related systems often show the same content in multiple formats. For example, a blog entry may appear on the home page of a blog, in an archive page, and in a page of other entries with the same label.” Google, 2020
Understand If Your CMS Produces Thin Content or Duplicate Pages
Google says:
QUOTE: “Understand your content management system: Make sure you’re familiar with how content is displayed on your website. Blogs, forums, and related systems often show the same content in multiple formats. For example, a blog entry may appear on the home page of a blog, in an archive page, and in a page of other entries with the same label.” Google, 2020
WordPress, Magento, Joomla, Drupal – they all come with slightly different SEO, duplicate content (and crawl equity performance) challenges.
For example, if you have ‘PRINT-ONLY’ versions of web pages (Joomla used to have major issues with this), that can end up displaying in Google instead of your web page if you’ve not handled it properly with canonicals.
That’s probably going to have an impact on conversions and link building – for starters. Poorly implemented mobile sites can cause duplicate content problems, too.
I would watch out for building what can look like ‘doorway pages’ to Google by creating too many keywords, tags or category pages.
Sign up for our Free SEO training course to find out more.
Will Google Penalise You For Syndicated Content?
No. When it comes to publishing your content on other websites:
QUOTE: “Syndicate carefully: If you syndicate your content on other sites, Google will always show the version we think is most appropriate for users in each given search, which may or may not be the version you’d prefer. However, it is helpful to ensure that each site on which your content is syndicated includes a link back to your original article. You can also ask those who use your syndicated material to use the noindex meta tag to prevent search engines from indexing their version of the content.” Google, 2020
The problem with syndicating your content is you can never tell if this will ultimately cost you organic traffic.
If it is on other websites – they might be getting ALL the positive signals from that content – not you.
It’s also worth noting that Google still clearly says that you CAN put links back to your original article in posts that are republished elsewhere.
But you need to be careful with that too – as those links could be classified as unnatural links.
The safest way to handle this is to ask the other site that republished your content to add a rel=canonical pointing to your original article on your site. Then your site gets the entire SEO benefit of the act of republishing your content, instead of the other site.
Links In duplicate articles do count but are risky.
A few years ago I made an observation I think that links that feature on duplicate posts that have been stolen – duplicated and republished – STILL pass anchor text value (even if it is a slight boost).
In this example, my ‘what is SEO’ post was stripped out all my links and published the article as his own.
Well, he stripped out all the links apart from one link he missed:

Yes, the link to http://www.duny*.com.pk/ was actually still pointing to my home page.
This gave me an opportunity to look at something…..
The article itself wasn’t 100% duplicate – there was a small intro text as far as I can see. It was clear by looking at Copyscape just how much of the article is unique and how much is duplicate.
So this is was 3 yr. old article republished on a low-quality site with a link back to my site within a portion of the page that’s clearly duplicate text.
I would have *thought* Google just ignored that link.
But no, Google did return my page for the following query (at the time):

The Google Cache notification (below) is now no longer available, but it was a good little tool to dig a little deeper into how Google works:

… which indicated that Google will count links (AT SOME LEVEL) even on duplicate articles republished on other sites – probably depending on the search query, and the quality of the SERP at that time (perhaps even taking into consideration the quality score of the site with the most trust?).
I have no idea if this is the case even today.
Historically, syndicating your content via RSS and encouraging folk to republish your content got your links, that counted, on some level (which might be useful for long tail searches).
Google is quite good at identifying the original article especially if the site it’s published on has a measure of trust – I’ve never had a problem with syndication of my content via RSS and let others cross post…. but I do like at least a link back, nofollow or not.

The bigger problem with content syndication is unnatural links and whether or not Google classifies your intent as manipulative.
If Google does class your intent to rank high with unnatural links, then you have a much more serious problem on your hands.
Sign up for our Free SEO training course to find out more.
Does Google Penalise ‘Thin’ Content On A Website?
Yes. Google also says about ‘thin’ content.
QUOTE: “Avoid publishing stubs: Users don’t like seeing “empty” pages, so avoid placeholders where possible. For example, don’t publish pages for which you don’t yet have real content. If you do create placeholder pages, use the noindex meta tag to block these pages from being indexed.” Google, 2020
and
QUOTE: “Minimize similar content: If you have many pages that are similar, consider expanding each page or consolidating the pages into one. For instance, if you have a travel site with separate pages for two cities, but the same information on both pages, you could either merge the pages into one page about both cities or you could expand each page to contain unique content about each city.” Google, 2020
The key things to understand about duplicate content on your web pages are:
- ‘Duplicate content’ on your own website is not necessarily ‘copied content’
- Duplicate content is a normal churn of the web. Google will rank it – for a time. Human or machine generated, there is a lot of it – and Google has a lot of experience handling it and there are many circumstances where Google finds duplicate content on websites. Not all duplicate content is a bad thing.
- If a page ranks well and Google finds it a manipulative use of duplicate content, Google can demote the page if it wants to. If it is deemed the intent is manipulative and low-quality with no value add, Google can take action on it – using manual or algorithmic actions.
- There is a very thin line between reasonable duplicate content and thin content. This is where the confusion comes in.
- Google explicitly states they don’t have a duplicate content penalty – but they do have a ‘thin content’ manual action… that looks and feels a lot like a penalty.
They also have Google Panda, an algorithm specifically designed to weed out low-quality content on websites.
Sign up for our Free SEO training course to find out more.
Minimise Any Series Of Paginated Pages On Your Site
QUOTE: “Use categories or tags to cross link so that you have a handful paginated pages per type, from where you link to the blog posts. Keep a good & balanced hierarchy, not too flat, not too deep.” John Mueller, Google 2020
Does Google Use Pagination Markup?
Some confusion arose during early 2019 as to whether using pagination markup was a worthwhile endeavor for webmasters to implement. It stemmed from Google removing its own help center documentation that laid down best practices for Pagination mark-up and John Mueller’s illuminating comment on Twitter that:
QUOTE: “We don’t use link-rel-next/prev at all. We noticed that we weren’t using rel-next/prev in indexing for a number of years now, so we thought we might as well remove the docs. Since it hasn’t been used for a while, it seems like most sites are doing pagination in reasonable ways that work regardless of these links. People make good sites, for a large part.” John Mueller, Google, 2019
Other Googlers were quick to clarify the comment:
QUOTE: “No, use pagination. let me reframe it.. Googlebot is smart enough to find your next page by looking at the links on the page, we don’t need an explicit “prev, next” signal. and yes, there are other great reasons (e.g. a11y) for why you may want or need to add those still. I think there is a misunderstanding here.. Google Search not using rel=prev,next as a signal doesn’t mean you can’t or shouldn’t use it on your pages; Search is but one consumer of said markup.” Ilya Grigorik – Web performance engineer at Google; co-chair of W3C Webperf WG, 2019
and Bing also clarified they use it, but again, not in “the ranking model”, somewhat adding to what Google’s John Mueller indicated with his tweet.
QUOTE: “We’re using rel prev/next (like most markup) as hints for page discovery and site structure understanding. At this point we’re not merging pages together in the index based on these and we’re not using prev/next in the ranking model.” Frédéric Dubut, Web Ranking & Quality PM at Bing (Microsoft), 2019
I think the simple answer here is…. continue using rel=next and rel=previous mark-up.
That is what I do, anyway.
QUOTE: “What does Google recommend now? Google is now recommending to try to make sure they put their content on a single page and not break them into multiple pages for the same piece of content. Google said on Twitter “Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search. Know and do what’s best for *your* users!” Barry Schwartz, Search Engine Land, 2019
How To Deal With Pagination Problems On Your Website
Paginated pages are not duplicate content, but often, it would be more beneficial to the user to land on the first page of the sequence.
Folding pages in a sequence and presenting a canonical URL for a group of pages has numerous benefits.
If you think you have paginated content problems on your website, it can be a frightening prospect to try and fix.
It is actually not that complicated.
Google knows that ‘Sites paginate content in various ways.’ and it is used to dealing with this type of problem on different types of sites like:
News and/or publishing sites often divide a long article into several shorter pages.
Retail sites may divide the list of items in a large product category into multiple pages.
Discussion forums often break threads into sequential URLs.
While Google says you can ‘do nothing‘ with paginated content, that might be taking a risk in a number of areas, and part of SEO is to focus on ranking a canonical version of a URL at all times.
What you do to handle paginated content will depend on your circumstances.
A better recommendation on offer is to:
QUOTE: “Specify a View All page. Searchers commonly prefer to view a whole article or category on a single page. Therefore, if we think this is what the searcher is looking for, we try to show the View All page in search results. You can also add a rel=”canonical” link to the component pages to tell Google that the View All version is the version you want to appear in search results.” Google
and
QUOTE: “Use
rel="next"andrel="prev"links to indicate the relationship between component URLs. This markup provides a strong hint to Google that you would like us to treat these pages as a logical sequence, thus consolidating their linking properties and usually sending searchers to the first page.” Google
You can also use meta robots ‘noindex,follow‘ directions on certain types of paginated content (I do), however, I would recommend you think twice before actually removing such content from Google’s index IF those URLs (or a portion of those URLs) generate a good amount of traffic from Google, and there is no explicit need for Google to follow the links to find content.
If a page is getting traffic from Google but needs to come out of the index, then I would ordinarily rely on an implementation that included the canonical link element (or redirect).
Ultimately, this depends on the situation and the type of site you are dealing with.
How To Use Rel=Next & Rel=Previous Markup, Properly
You do not need to implement Rel=Next/Prevous Markup, but it is a W3C standard, so feel free to use it if you want.
Pagination can be a tricky concept and it is easy to mess up.
Here are some notes to help you also:
- The ‘rel=“next” and rel=“previous” markup is the standard for indicating paginated pages (and this can have any page parameters included)
- Rel Canonical is for duplicate content. e.g. for session IDS OR for content which is a ‘superset’ e.g. a superset VIEW ALL Page. If Google’s algorithms PREFER a page with a ‘misused’ canonical, they will pick the page they (or their users) prefer. Canonical is a HINT, not a DIRECTIVE Google is required to honour. A page once removed from Google’s index because of misused canonical will reappear in time if Google prefers it, and it will ignore the rel=canonical on that page and index it normally.
Google does NOT completely ignore an entire sites canonical instructions if misused – rather it seems to do this url by url – but it might impact traffic levels in core updates, PAGE TO PAGE, as Google better understands your site and especially when the pages its USER’s prefer is different (when matched to a query) to the URL YOU specify in Rel=canonical. This is what Google means by a ‘hint’ not a directive. - The ‘rel=“next” and rel=“previous” markup destination URLs should all return a 200 OK response header.
- Page one in the series should have rel=next markup, but no rel=prev code, with the opposite being true of the last page in the series.
- Pages in a series should have a self-referencing canonical tag unless they specify a ‘view all page’. rel=“canonical” tells Google to index ONLY the content on the page specified in the rel=“canonical”.
- rel=“canonical” – Do NOT canonicalise component pages in a series to the first page.
You ONLY use rel=“canonical” to point to a VIEW ALL Page if one is present, OTHERWISE, all pages SHOULD have a SELF-referencing canonical tag.
QUOTE: “In cases of paginated content, we recommend either a rel=canonical from component pages to a single-page version of the article, or to use rel=”prev” and rel=”next” pagination markup.” – Google
Common mistake web developers make is to add a rel=canonical to the first page in the series or to add NOINDEX to pages in the series of a component set.
QUOTE: “While it’s fine to set rel=”canonical” from a component URL to a single view-all page, setting the canonical to the first page of a parameter-less sequence is considered improper usage.” – Google, 2012
and
QUOTE: “When you implement rel=”next” and rel=”prev” on component pages of a series, we’ll then consolidate the indexing properties from the component pages and attempt to direct users to the most relevant page/URL. This is typically the first page. There’s no need to mark page 2 to n of the series with noindex.” GOOGLE
A Google spokesperson explains why this is not optimal here: https://youtu.be/njn8uXTWiGg?t=11m52s
RE: How To Handle Time-sequential Series of Pages (e.g. in a blog) Google offers this advice:
QUESTION:
QUOTE: “Should I use the rel next/prev into [sic] the section of a blog even if the two contents are not strictly correlated (but they are just time-sequential)?”
ANSWER:
QUOTE:: “In regard to using rel=”next” and rel=”prev” for entries in your blog that “are not strictly correlated (but they are just time-sequential),” pagination markup likely isn’t the best use of your time — time-sequential pages aren’t nearly as helpful to our indexing process as semantically related content, such as pagination on component pages in an article or category.
It’s fine if you include the markup on your time-sequential pages, but please note that it’s not the most helpful use case.” John Mueller, Google, 2012
So – for internal pages that are ordered by date of publishing, it is probably better to just let Google crawl these.
Sign up for our Free SEO training course to find out more.
How Does Googe Rate Content ‘Deliberately Duplicated Across Domains‘?
It can see it as manipulative:
“…in some cases, content is deliberately duplicated across domains in an attempt to manipulate search engine rankings or win more traffic.
Deceptive practices like this can result in a poor user experience, when a visitor sees substantially the same content repeated within a set of search results.
Google tries hard to index and show pages with distinct information.
This filtering means, for instance, that if your site has a “regular” and “printer” version of each article, and neither of these is blocked with a noindex meta tag, we’ll choose one of them to list.
In the rare cases in which Google perceives that duplicate content may be shown with intent to manipulate our rankings and deceive our users, we’ll also make appropriate adjustments in the indexing and ranking of the sites involved.
As a result, the ranking of the site may suffer, or the site might be removed entirely from the Google index, in which case it will no longer appear in search results. GOOGLE, 2020
If you are trying to compete in competitive niches, you need original content that’s not found on other pages in the same form on your site, and THIS IS, EVEN MORE, IMPORTANT WHEN THAT CONTENT IS FOUND ON OTHER PAGES ON OTHER WEBSITES.
Google isn’t under any obligation to rank your version of content – in the end, it depends on who’s site has got the most domain authority or most links coming to the page.
Well, historically at least – it is often the page that satisfies users the most.
If you want to avoid being filtered by duplicate content algorithms, produce unique content.
Should You Block Google from Crawling Internal Search Result Pages?
Yes. According to Google.
Google wants you to use Robots text to block internal search results. Google recommends “not allowing internal search pages to be indexed”.
While there are ways around this guideline that do not produce ‘infinite search spaces”, letting Google index and rank your internal search pages is a VERY risky manoeuvre (over time) if you are in a competitive industry.
These recommendations are actually in webmaster guidelines.
QUOTE: “Use the robots.txt file on your web server to manage your crawling budget by preventing crawling of infinite spaces such as search result pages. Keep your robots.txt file up to date.” Google 2017
Letting Google crawl and index your internal search results pages is an ‘inefficient’ from a crawling and indexing.
Such pages cause “problems in search” for Google, and Google has a history of ‘snapping back’ on companies who break such guidelines to their profit.
Sign up for our Free SEO training course to find out more.
TIP: “noindex, follow” “is essentially kind of the same as a” “noindex, nofollow” John Mueller
Many use NOINDEX,FOLLOW on such pages (blog sub pages, date based archives etc) to remove them from the index by a recent talk from John Mueller would indicate a change in how Google treated noindexed links and the attribute ‘follow’ in the meta robots instruction.
QUOTE: “So it’s kind of tricky with noindex. Which I think is something somewhat of a misconception in general with a the SEO community. In that with a noindex and follow it’s still the case that we see the noindex. And in the first step we say okay you don’t want this page shown in the search results. We’ll still keep it in our index, we just won’t show it and then we can follow those links. But if we see the noindex there for longer than we think this page really doesn’t want to be used in search so we will remove it completely. And then we won’t follow the links anyway. So in noindex and follow is essentially kind of the same as a noindex, nofollow. There’s no real big difference there in the long run.” John Muller, 2017
Don’t link to often from your own sites internal links to pages that are no-indexed.
Further reading: https://webmasters.googleblog.com/2012/03/video-about-pagination-with-relnext-and.html
Are Uppercase and Lowercase URLs Counted as TWO different pages to Google?
Yes. Uppercase and lowercase versions of a URL are classed as TWO different pages for Google.
Best practice has long been to force lowercase URLs on your server, and be consistent when linking to internal pages on your website and use only lowercase URLs when creating internal links.
The video below offers recent (2017) confirmation of this challenge – with the advice being to use canonicals or redirects to fix this issue, and this would be whatever was more efficient from a crawling and indexing perspective (which I think to be 301 redirects in this instance, where necessary, and a overhaul of the internal linking structure):
…and when asked recently (2017) on Twitter, former Googler Matt Cutts replied:
QUOTE: “Is there ANY SEO-relevant reason to force lowercase urls?” 2017
Matt replied:
QUOTE: “Unifying links on a single URL” Matt Cutts, Former Google, 2017
Do Trailing Slashes Cause Duplicate Content Challenges on a Website?
Sometimes. It depends on whether the trailing slashes are on internal pages on a site, or on the root, and which protocol is being used.
Google clarified on whether or not forgetting to add trailing slashes on a website URL causes problems on your site:
QUOTE: “I noticed there was some confusion around trailing slashes on URLs, so I hope this helps. tl;dr: slash on root/hostname=doesn’t matter; slash elsewhere=does matter (they’re different URLs) ” John Mueller, Google, 2017
He offered a guide to help fix the common issues:

Note – I aim to use a trailing slash in almost all cases to help ensure consistency of canonical URLs across a site when it comes to internal linking or external link building.
Redirect Non-WWW To WWW (or Vice Versa)
QUOTE: “The preferred domain is the one that you would liked used to index your site’s pages (sometimes this is referred to as the canonical domain). Links may point to your site using both the www and non-www versions of the URL (for instance, http://www.example.com and http://example.com). The preferred domain is the version that you want used for your site in the search results.” Google, 2018
Your site probably has canonicalisation issues (especially if you have an e-commerce website) and it might start at the domain level and this can exacerbate duplicate content problems on your website.
Simply put, https://www.hobo-web.co.uk/ can be treated by Google as a different URL than http://hobo-web.co.uk/ even though it’s the same page, and it can get even more complicated.
Its thought REAL Pagerank can be diluted if Google gets confused about your URLs and speaking simply you don’t want this PR diluted (in theory).
That’s why many, including myself, redirect non-www to www (or vice versa) if the site is on a Linux/Apache server (in the htaccess file –
Options +FollowSymLinks
RewriteEngine on
RewriteCond %{HTTP_HOST} ^hobo-web.co.uk [NC]
RewriteRule ^(.*)$ https://www.hobo-web.co.uk/$1 [L,R=301]
Basically, you are redirecting all the Google juice to one canonical version of a URL.
This is a MUST HAVE best practice.
It keeps it simple when optimising for Google. It should be noted; it’s incredibly important not to mix the two types of www/non-www on site when linking your internal pages!
Note Google asks you which domain you prefer to set as your canonical domain in Google Webmaster Tools.
QUOTE: “Note: Once you’ve set your preferred domain, you may want to use a 301 redirect to redirect traffic from your non-preferred domain, so that other search engines and visitors know which version you prefer.” Google
Sign up for our Free SEO training course to find out more.
Does The Google Panda Algorithm Penalise Duplicate Content?
QUOTE: “Google’s Panda Update is a search filter introduced in February 2011 meant to stop sites with poor quality content from working their way into Google’s top search results. Panda is updated from time-to-time. When this happens, sites previously hit may escape, if they’ve made the right changes.” SearchEngineLand, 2020
Google Panda (a somewhat deprecated SEO term) was the name of a series of major Google search results changes starting back in 2011. The simple answer to the question is….
No – but if you have “copied content” on your site, then you probably will be impacted negatively to various degrees.
A part of Google Panda algorithm is focused on thin pages and (many think) the ratio of good-quality content to low-quality content on a site and user feedback to Google as a proxy for satisfaction levels.
In the original announcement about Google Panda we were specifically told that the following was a ‘bad’ thing:
QUOTE: “Does the site have duplicate, overlapping, or redundant articles?” Google, 2020
If Google is rating your pages on content quality, or lack of it, as we are told, and user satisfaction – on some level – and a lot of your site is duplicate content that provides no positive user satisfaction feedback to Google – then that may be a problem too.
Google offers some advice on thin pages (emphasis mine):
QUOTE: “Here are a few common examples of pages that often have thin content with little or no added value: 1 . Automatically generated content, 2. Thin affiliate pages 3. Content from other sources. For example: Scraped content or low-quality guest blog posts. 4. Doorway pages“
Everything I’ve bolded in the last two quotes is essentially about what many SEO have traditionally labeled (incorrectly) as ‘duplicate content’.
This might be ‘semantics’, but Google calls that type of duplicate content ‘spam’.
Google is, even more, explicit when it tells you how to clean up this ‘violation’:
QUOTE: “Next, follow the steps below to identify and correct the violation(s) on your site: Check for content on your site that duplicates content found elsewhere.” Google
So beware.
Google says there is NO duplicate content penalty, but if Google classifies your “duplicate content” as “copied content”, “thin content” or “boilerplate”, or hastily rewritten or worse “synonymised” or “spun text”, then you MAY WELL have a problem!
A serious challenge, if your entire site is built like that.
And how Google rates thin pages changes over time, with a quality bar that is always going to rise and that your pages need to keep up with.
Especially if rehashing content is what you do.
Google Panda does not penalise a site for duplicate content, but it does measure site and content ‘quality’. Google Panda actually DEMOTES a site where it determines an intent to manipulate the algorithms.
Google Panda:
QUOTE: “measures the quality of a site pretty much by looking at the vast majority of the pages at least. But essentially allows us to take quality of the whole site into account when ranking pages from that particular site and adjust the ranking accordingly for the pages. [Google Panda] is an adjustment. Basically, we figured that site is trying to game our systems, and unfortunately, successfully. So we will adjust the rank. We will push the site back just to make sure that it’s not working anymore.” Gary Illyes, Google Spokesperson, 2016
TIP – Look out for soft 404 errors in Google Webmaster tools (now called Google Search Console) as examples of pages Google are classing as low-quality, user-unfriendly thin pages.
Sign up for our Free SEO training course to find out more.
Using Google Search Console To Identify Duplicates
Use Google Search Console to fix duplicate content issues on your site.
Note that Google says:
QUOTE: “You should not expect all URLs on your site to be indexed. Your goal is to get the canonical version of every page indexed. Any duplicate or alternate pages will be labeled “Excluded” in this report (Index Coverage Status report). Duplicate or alternate pages have substantially the same content as the canonical page. Having a page marked duplicate or alternate is a good thing; it means that we’ve found the canonical page and indexed it. You can find the canonical for any URL by running the URL Inspection tool.” Google Official Guidelines, 2019
The Excluded report essentially lists:
QUOTE: “The page is not indexed, but we think that was your intention. (For example, you might have deliberately excluded it by a noindex directive, or it might be a duplicate of a canonical page that we’ve already indexed on your site.)…. These pages are typically not indexed, and we think that is appropriate. These pages are either duplicates of indexed pages, or blocked from indexing by some mechanism on your site, or otherwise not indexed for a reason that we think is not an error.” Google Official Guidelines, 2019
Tips Google provides in Search Console include an “Everything is OK”:
QUOTE: “Alternate page with proper canonical tag: This page is a duplicate of a page that Google recognizes as canonical. This page correctly points to the canonical page, so there is nothing for you to do.”Google 2020
and two error messages, one being”Duplicate without user-selected canonical:“:
QUOTE: “Duplicate without user-selected canonical: This page has duplicates, none of which is marked canonical. We think this page is not the canonical one. You should explicitly mark the canonical for this page. Inspecting this URL should show the Google-selected canonical URL.” Search Console, 2019
and another, “Duplicate, Google chose different canonical than user”:
QUOTE: “Duplicate, Google chose different canonical than user: This page is marked as canonical for a set of pages, but Google thinks another URL makes a better canonical. Google has indexed the page that we consider canonical rather than this one. We recommend that you explicitly mark this page as a duplicate of the canonical URL. This page was discovered without an explicit crawl request. Inspecting this URL should show the Google-selected canonical URL.” Search Console, 2019
Sign up for our Free SEO training course to find out more.
How To Check For Duplicate Content On A Website?
An easy way to find duplicate content is to use Google search.
Just take a piece of text content from your site and put it “in quotes” as a search on Google.
Google will tell you how many pages that piece of content it found on pages in its index of the web. The page that ranks for that content is often the original, too.
The best known online duplicate content checker tool is Copyscape and I particularly like this little tool too, which check duplicate content ratio between two selections of text.
If you find evidence of plagiarism, you can file a DMCA or contact Google, but I haven’t ever bothered with that, and many folks have republished my articles over the years.
I once found my article (word for word) in a paid advert in a printed magazine before, for someone else!
Comments:
A few marketers and Google spokespeople have commented on this article on social circles (presented as images throughout this article)
- John Mueller (Google)
- Martin MacDonald (Web Marketing School)
- Richard Baxter (Built Visible)
- Cyrus Shephard
- Bill Slawski
- Barry Adams (Polemic Digital)
More reading
- http://googlewebmastercentral.blogspot.co.uk/2009/02/specify-your-canonical.html
- https://support.google.com/webmasters/answer/66359?hl=en
- http://googlewebmastercentral.blogspot.com/2009/10/reunifying-duplicate-content-on-your.html
- https://webmasters.googleblog.com/2011/05/more-guidance-on-building-high-quality.html
- https://support.google.com/webmasters/answer/2604719?hl=en
- http://www.SEObythesea.com/2008/02/google-omits-needless-words-on-your-pages/
- http://searchengineland.com/google-panda-demotes-adjusts-rankings-not-devalue-261142
- https://builtvisible.com/duplicate-content-detection/
Comments are closed.