QUOTE: “One piece of advice I tend to give people is to aim for a niche within your niche where you can be the best by a long stretch. Find something where people explicitly seek YOU out, not just “cheap X” (where even if you rank, chances are they’ll click around to other sites anyway).” John Mueller, Google 2018
Make sure Google can crawl your website, index and rank all your primary pages by only serving Googlebot high-quality, user-friendly and fast-loading pages to index.
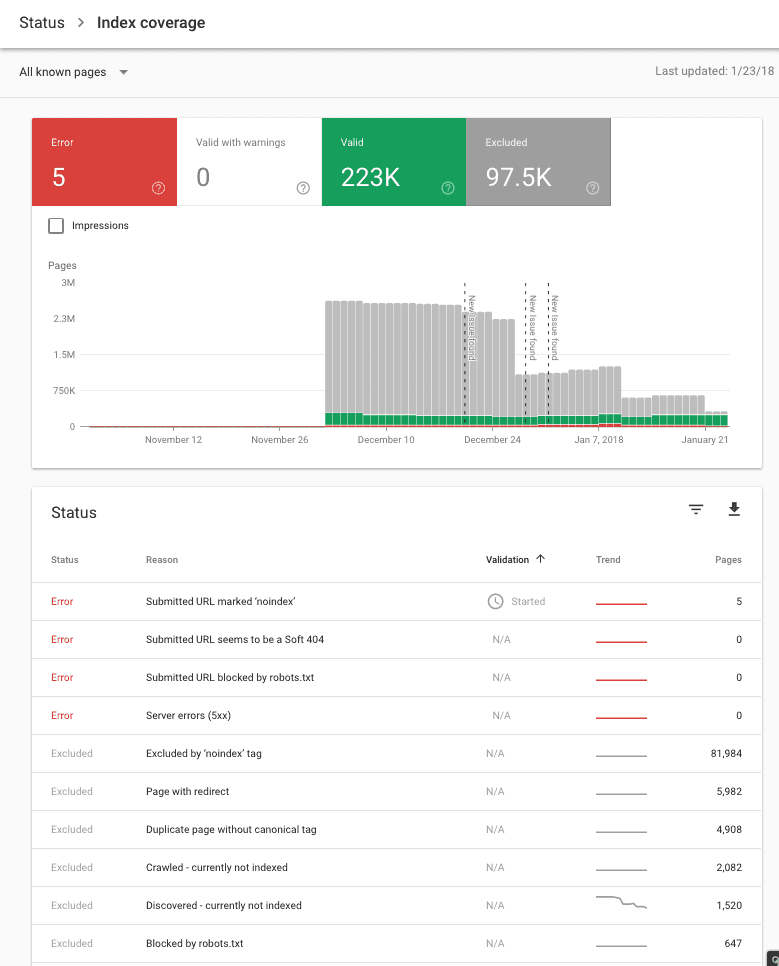
Check out the Indexation Report In Google Search Console
This is sure to be an invaluable addition to Google Search Console for some larger sites.
If you submit an XML sitemap file in Search Console, Google will help you better understand why certain pages are not indexed.
As you can see, Google goes to great lengths to help you to identify indexation problems on your website, including, in this example:
| Status | Reason | Validation | Trend | Pages |
|---|---|---|---|---|
| Error | Submitted URL marked ‘noindex’ |
Started
|
5 | |
| Error | Server errors (5xx) |
N/A
|
0 | |
| Error | Submitted URL blocked by robots.txt |
N/A
|
0 | |
| Error | Submitted URL seems to be a Soft 404 |
N/A
|
0 | |
| Excluded | Excluded by ‘noindex’ tag |
N/A
|
81,984 | |
| Excluded | Page with redirect |
N/A
|
5,982 | |
| Excluded | Duplicate page without canonical tag |
N/A
|
4,908 | |
| Excluded | Crawled – currently not indexed |
N/A
|
2,082 | |
| Excluded | Discovered – currently not indexed |
N/A
|
1,520 | |
| Excluded | Blocked by robots.txt |
N/A
|
647 | |
| Excluded | Alternate page with proper canonical tag |
N/A
|
201 | |
| Excluded | Soft 404 |
N/A
|
147 | |
| Excluded | Submitted URL not selected as canonical |
N/A
|
34 | |
| Valid | Indexed, not submitted in sitemap |
N/A
|
221,004 | |
| Valid | Submitted and indexed |
N/A
|
2,144 |
How To Use The Indexation Report In Google Search Console
QUOTE: “Find out which of your pages have been crawled and indexed by Google. In this episode of Search Console Training…. how to use the Index Coverage report to assess its status and identify issues.” GoogleWMC, 2020
Will Google Index Every Page on Your Website?
No.
QUOTE: “We never index all known URLs, that’s pretty normal. I’d focus on making the site awesome and inspiring, then things usually work out better“. John Mueller, 2018
Some URLs are not that important to Google, some are duplicates, some have conflicting indexation instructions and some pages are low-quality or even spammy.
Low-Quality Content On Part of A Web Site Can Affect Rankings For The Same Website On More Important Keyword Rankings
Moz has a good video on the Google organic quality score theory.
One thing that could have been explained better in the video was that Moz has topical authority world wide for ‘Google SEO’ terms, hence why they can rank so easily for ‘organic quality score’.
But the explanation of the quality score is a good introduction for beginners.
This is also quite relevant to a question answered last week in the Google Webmaster Hangout which was:
“QUESTION – Is it possible that if the algorithm doesn’t particularly like our blog articles as much that it could affect our ranking and quality score on the core Content?”
resulting in an answer:
“ANSWER: JOHN MUELLER (GOOGLE): Theoretically, that’s possible. I mean it’s kind of like we look at your web site overall. And if there’s this big chunk of content here or this big chunk kind of important wise of your content, there that looks really iffy, then that kind of reflects across the overall picture of your website. But I don’t know in your case, if it’s really a situation that your blog is really terrible.”
Google has introduced (at least) a ‘percieved’ risk to publishing lots of lower-quality pages on your site to in an effort to curb production of old-style SEO friendly content based on manipulating early search engine algorithms.
We are dealing with algorithms designed to target old style SEO – that focus on the truism that DOMAIN ‘REPUTATION’ plus LOTS of PAGES equals LOTS of Keywords equals LOTS of Google traffic.
A big site can’t just get away with publishing LOTS of lower quality content in the cavalier way they used to – not without the ‘fear’ of primary content being impacted and organic search traffic throttled negatively to important pages on the site.
Google is very probably using user metrics in some way to determine the ‘quality’ of your site.
QUESTION – “I mean, would you recommend going back through articles that we posted and if there’s ones that we don’t necessarily think are great articles, that we just take them away and delete them?”
The reply was:
JOHN MUELLER: I think that’s always an option.Yeah. That’s something that–I’ve seen sites do that across the board,not specifically for blogs, but for content in general, where they would regularly go through all of their content and see, well, this content doesn’t get any clicks, or everyone who goes there kind of runs off screaming.
Deleting content is not always the optimal way to handle MANY types of low-quality content – far from it, in fact. Nuking it is the last option unless the pages really are ‘dead‘ content.
Any clean-up should go hand in hand with giving Google something it is going to value on your site e.g. NEW high-quality content:

The final piece of advice is interesting, too.
It gives us an insight into how Google might actually deal with your site:
JOHN MUELLER: “Then maybe that’s something where you can collect some metrics and say, well, everything that’s below this threshold, we’ll make a decision whether or not to significantly improve it or just get rid of it.”
E.g. (paraphrasing!)
You can probably rely on Google to ‘collect some metrics and say, well, everything that’s below this threshold, we’ll “…(insert punishment spread out over time).
Google probably has a quality score of some sort, and your site probably has a rating whatever that is relevant to (and if you get any real traffic from Google, often a manual rating).
If you have a big site, certain parts of your site will be rated more useful than others to Google.
Improving the quality of your content certainly works to improve traffic, as does intelligently managing your content across the site. Positive results from this process are NOT going to happen overnight.
If you are creating content for blogging purposes, consider the following:
Google says:
QUOTE: “Creating compelling and useful content will likely influence your website more than any of the other factors.” Google, 2017
There is no one particular way to create web pages that successfully rank in Google but you must ensure:
QUOTE: “that your content kind of stands on its own” John Mueller, Google 2015
If you have an optimised platform on which to publish it, high-quality content is the number 1 user experience area to focus on across websites to earn traffic from Google.
If you have been impacted by Google’s content quality algorithms, your focus should be on ‘improving content’ on your site rather than deleting content:
If you want to learn how to optimise your website content then read on.
When You Add Pages To A Website, “you spread the value across the whole set, and all of them get a little bit less.”
This statement from Google is incredibly important:
QUOTE: “Usually you can’t just arbitrarily expand a site and expect the old pages to rank the same, and the new pages to rank as well. All else being the same, if you add pages, you spread the value across the whole set, and all of them get a little bit less. Of course, if you’re building up a business, then more of your pages can attract more attention, and you can sell more things, so usually “all else” doesn’t remain the same. At any rate, I’d build this more around your business needs — if you think you need pages to sell your products/services better, make them.” John Mueller, Google 2018
When you expand the content on a website, you apparently dilute the ‘value’ you already have, “all else being the same“. This is a good statement to have.
This certainly seems to be an ‘answer‘ to ‘domain authority‘ abuse and ‘doorway page‘ abuse. It is also going to make webmasters think twice about the type of “SEO friendly content” they publish.
If your pages are low-quality, and you add more pages to your site of similar quality, then your overall low-quality value Google assigns to your website is lowered still. That value is probably based on content relevance and E.A.T. (high-quality backlinks and expertise) and that is generally a measure of how well you deliver for Google visitors.
We already know that low-quality content on one part of a website can impact rankings for other keywords on other (even high-quality) pages on the same website.
When making ‘SEO-friendly’ content you need to ask yourself:
- Is this new ‘SEO-friendly’ content going to pick up links? Do it.
- Is this new content going to be useful for your current website visitors? Do it, carefully.
- Is this new content autogenerated across many pages? Think twice. Expect value to be diluted in some way.
- Does the site already have lots of low-quality content? Deal with that, first, by improving it. Get rid of stale and irrelevant content.
- Do you have the keywords you want to rank for on the site? Get those on pages you already have without keyword stuffing and prepare to make a high-quality site PLUS high-quality content (as these are 2 different factors) to target specific keyword phrases.
You also need to ask yourself WHY Google would rank 10,000 or 100K of your pages for free, just because you tweaked a few keywords?
Herein lies the answer to many ranking and indexing problems.
TAKEAWAY: Don’t add lots of pages to your site where the single purpose is to meet known Google keyword relevance signals. You may get de-valued for it. Do add content to your site that has a clear purpose for your users.
Is Your Content ‘useful for Google users‘?
QUOTE: “Our Webmaster Guidelines advise you to create websites with original content that adds value for users.” Google, 2018
Content quality is one area to focus on if you are to avoid demotion in Google.
QUOTE: “high quality content is something I’d focus on. I see lots and lots of SEO blogs talking about user experience, which I think is a great thing to focus on as well. Because that essentially kind of focuses on what we are trying to look at as well. We want to rank content that is useful for (Google users) and if your content is really useful for them, then we want to rank it.” John Mueller, Google 2016
This article aims to cover the most significant challenges of writing ‘SEO-friendly’ text and web page copy for Google. High-quality content is one aspect of a high-quality page on a high-quality site.
SEO is NO LONGER about adding keywords to pages with 300 words of text. In fact, that practice can be toxic to a site.
Your content needs to be useful to Google users.
If you run an affiliate website or have content that appears on other sites, this is even more important.
QUOTE: “This is particularly important for sites that participate in affiliate programs. Typically, affiliate websites feature product descriptions that appear on sites across that affiliate network. As a result, sites featuring mostly content from affiliate networks can suffer in Google’s search rankings, because they do not have enough added value content that differentiates them from other sites on the web.” Google, 2018
and
QUOTE: “Google believes that pure, or “thin,” affiliate websites do not provide additional value for web users, especially (but not only) if they are part of a program that distributes its content across a network of affiliates. These sites often appear to be cookie-cutter sites or templates the same or similar content replicated within the same site, or across multiple domains or languages. Because a search results page could return several of these sites, all with the same content, thin affiliates create a frustrating user experience.” Google, 2018
An example of a ‘thin-affiliate‘ site is a site where “product descriptions and reviews are copied directly from the original merchant without any original content or added value” and “where the majority of the site is made for affiliation and contains a limited amount of original content or added value for users”.
Google says that “Good affiliates add value, for example by offering original product reviews, ratings, navigation of products or categories, and product comparisons“.
Google offers us the following advice when dealing with sites with low-value content:
-
QUOTE: “Affiliate program content should form only a minor part of the content of your site if the content adds no additional features.” Google, 2018
-
QUOTE: “Ask yourself why a user would want to visit your site first rather than visiting the original merchant directly. Make sure your site adds substantial value beyond simply republishing content available from the original merchant.” Google, 2018
-
QUOTE: “The more targeted the affiliate program is to your site’s content, the more value it will add and the more likely you will be to rank better in Google search results.”Google, 2018
-
QUOTE: “Keep your content updated and relevant. Fresh, on-topic information increases the likelihood that your content will be crawled by Googlebot and clicked on by users.”Google, 2018
Google Demotion Algorithms Target Low-Quality Content
Optimising (without improving) low-quality content springs traps set by ever-improving core quality algorithms.
What this means is that ‘optimising’ low-quality pages is very much swimming upstream.
Optimising low-quality pages without value-add is self-defeating, now that the algorithms – and manual quality rating efforts – have got that stuff nailed down.
If you optimise low-quality pages using old school SEO techniques, you will be hit with a low-quality algorithm (like the Quality Update or Google Panda).
You must avoid boilerplate text, spun text or duplicate content when creating pages – or you are Panda Bamboo – as Google hinted at in the 2015 Quality Rater’s Guide.
QUOTE: “6.1 Low Quality Main Content One of the most important considerations in PQ rating is the quality of the MC. The quality of the MC is determined by how much time, effort, expertise, and talent/skill have gone into the creation of the page. Consider this example: Most students have to write papers for high school or college. Many students take shortcuts to save time and effort by doing one or more of the following:
- Buying papers online or getting someone else to write for them
- Making things up.
- Writing quickly with no drafts or editing.
- Filling the report with large pictures or other distracting content.
- Copying the entire report from an encyclopedia, or paraphrasing content by changing words or sentence structure here and there.
- Using commonly known facts, for example, “Argentina is a country. People live in Argentina. Argentina has borders. Some people like Argentina.”
- Using a lot of words to communicate only basic ideas or facts, for example, “Pandas eat bamboo. Pandas eat a lot of bamboo. It’s the best food for a Panda bear.”
Unfortunately, the content of some webpages is similarly created. We will consider content to be Low quality if it is created without adequate time, effort, expertise, or talent/skill. Pages with low quality MC do not achieve their purpose well. Important: Low quality MC is a sufficient reason to give a page a Low quality rating.”
Google rewards uniqueness or punishes the lack of it.
The number 1 way to do ‘SEO copywriting‘ will be to edit the actual page copy to continually add unique content and improve its accuracy, uniqueness, relevance, succinctness, and use.
Low-Quality Content Is Not Meant To Rank High in Google.

A Google spokesman said not that long ago that Google Panda was about preventing types of sites that shouldn’t rank for particular keywords from ranking for them.
QUOTE: “(Google Panda) measures the quality of a site pretty much by looking at the vast majority of the pages at least. But essentially allows us to take quality of the whole site into account when ranking pages from that particular site and adjust the ranking accordingly for the pages. So essentially, if you want a blunt answer, it will not devalue, it will actually demote. Basically, we figured that site is trying to game our systems, and unfortunately, successfully. So we will adjust the rank. We will push the site back just to make sure that it’s not working anymore.” Gary Illyes – Search Engine Land, 2017
When Google demotes your page for duplicate content practices, and there’s nothing left in the way of unique content to continue ranking you for – your web pages will mostly be ignored by Google.
The way I look at it – once Google strips away all the stuff it ignores (duplicate text) – what’s left? In effect, that’s what you can expect Google to reward you for. If what is left is boilerplate synonymised text content – that’s now being classed as web spam – or ‘spinning’.
NOTE – The ratio of duplicate content on any page is going to hurt you if you have more duplicate text than unique content. A simple check of the pages, page to page, on the site is all that’s needed to ensure each page is DIFFERENT (regarding text) page-to-page.
If you have large sections of duplicate text page-to-page – that is a problem that should be targeted and removed.
It is important to note:
- The main text content on the page must be unique to avoid Google’s page quality algorithms.
- Verbose text must NOT be created or spun automatically
- Text should NOT be optimised to a template as this just creates a footprint across many pages that can be interpreted as redundant or manipulative boilerplate text.
- Text should be HIGHLY descriptive, unique and concise
- If you have a lot of pages to address, the main priority is to create a UNIQUE couple of paragraphs of text, at least, for the MC (Main Content). Pages do not need thousands of words to rank. They just need to MEET A SPECIFIC USER INTENT and not TRIP ‘LOW_QUALTY’ FILTERS. A page with just a few sentences of unique text still meets this requirement (150-300 words) – for now.
- When it comes to out-competing competitor pages, you are going to have to look at what the top competing page is doing when it comes to main content text. Chances are – they have some unique text on the page. If they rank with duplicate text, either their SUPPLEMENTARY CONTENT is better, or the competitor domain has more RANKING ABILITY because of either GOOD BACKLINKS or BETTER USER EXPERIENCE.
- Updating content on a site should be a priority as Google rewards fresher content for certain searches.
Help Google Help You Index More Pages
This is no longer about repeating keywords. ANYTHING you do to IMPROVE the page is going to be a potential SEO benefit. That could be:
- creating fresh content
- removing doorway-type pages
- cleaning up or removing thin-content on a site
- adding relevant keywords and key phrases to relevant pages
- constantly improving pages to keep them relevant
- fixing poor grammar and spelling mistakes
- adding synonyms and related key phrases to text
- reducing keyword stuffing
- reducing the ratio of duplicated text on your page to unique text
- removing old outdated links or out-of-date content
- rewording sentences to take out sales or marketing fluff and focusing more on the USER INTENT (e.g. give them the facts first including pros and cons – for instance – through reviews) and purpose of the page.
- merging many old stale pages into one, fresh page, which is updated periodically to keep it relevant
- Conciseness, while still maximising relevance and keyword coverage
- Improving important keyword phrase prominence throughout your page copy (you can have too much, or too little, and it is going to take testing to find out what is the optimal presentation will be)
- Topic modelling
A great writer can get away with fluff but the rest of us probably should focus on being concise.
Low-quality fluff is easily discounted by Google these days – and can leave a toxic footprint on a website.
Minimise the production of doorway-type pages you produce on your site
You will need another content strategy. If you are forced to employ these type of pages, you need to do it in a better way.
QUOTE: “if you have a handful of locations and you have unique valuable content to provide for those individual locations I think providing that on your website is perfectly fine if you have hundreds of locations then putting out separate landing pages for every city or every region is almost more like creating a bunch of doorway pages so that’s something I really discourage” John Mueller Google 2017
Are you making ‘doorway pages’ and don’t even know it?
QUOTE: “Google algorithms consistently target sites with doorway pages in quality algorithm updates. The definition of a “doorway page” can change over time.” Shaun Anderson, Hobo 2020
Minimise the production of thin pages you produce on your site
You will need to check how sloppy your CMS is. Make sure it does not inadvertently produce pages with little to no unique content on them (especially if you have ads on them).
QUOTE: “John says to avoid lots of “just automatically generated” pages and “if these are pages that are not automatically generated, then I wouldn’t see that as web spam.” Conversely then “automatically generated” content = web spam? It is evident Googlebot expects to see a well formed 404 if no page exists at a url.” Shaun Anderson, Hobo 2020
Create Useful 404 Pages
I mentioned previously that Google gives clear advice on creating useful 404 pages:
- Tell visitors clearly that the page they’re looking for can’t be found
- Use language that is friendly and inviting
- Make sure your 404 page uses the same look and feel (including navigation) as the rest of your site.
- Consider adding links to your most popular articles or posts, as well as a link to your site’s home page.
- Think about providing a way for users to report a broken link.
- Make sure that your webserver returns an actual 404 HTTP status code when a missing page is requested
It is incredibly important to create useful and proper 404 pages. This will help prevent Google recording lots of autogenerated thin pages on your site (both a security risk and a rankings risk).
You can use 410 responses for expired content that is never coming back.
A poor 404 page and user interaction with it, can only lead to a ‘poor user experience’ signal at Google’s end, for a number of reasons, so you must:
QUOTE: “Create useful 404 pages“ Google, 2018
and
QUOTE: “Tell visitors clearly that the page they’re looking for can’t be found. Use language that is friendly and inviting. Make sure your 404 page uses the same look and feel (including navigation) as the rest of your site. Consider adding links to your most popular articles or posts, as well as a link to your site’s home page. Think about providing a way for users to report a broken link. No matter how beautiful and useful your custom 404 page, you probably don’t want it to appear in Google search results. In order to prevent 404 pages from being indexed by Google and other search engines, make sure that your webserver returns an actual 404 HTTP status code when a missing page is requested.” Google, 2018
….. all that is need doing is to follow the guideline as exactly as Google tells you to do it.
Ratings for Pages with Error Messages or No MC
Google doesn’t want to index pages without a specific purpose or sufficient main content. A good 404 page and proper setup prevents a lot of this from happening in the first place.
QUOTE: “Some pages load with content created by the webmaster, but have an error message or are missing MC. Pages may lack MC for various reasons. Sometimes, the page is “broken” and the content does not load properly or at all. Sometimes, the content is no longer available and the page displays an error message with this information. Many websites have a few “broken” or non-functioning pages. This is normal, and those individual non-functioning or broken pages on an otherwise maintained site should be rated Low quality. This is true even if other pages on the website are overall High or Highest quality.” Google
Does Google programmatically look at 404 pages?
We are told, NO in a recent hangout – – but – in Quality Raters Guidelines “Users probably care a lot”.
Do 404 Errors in Search Console Hurt My Rankings?
QUOTE: “404 errors on invalid URLs do not harm your site’s indexing or ranking in any way.” John Mueller, Google
It appears this isn’t a once size fits all answer. If you properly deal with mishandled 404 errors that have some link equity, you reconnect equity that was once lost – and this ‘backlink reclamation’ evidently has value.
The issue here is that Google introduces a lot of noise into that Crawl Errors report to make it unwieldy and not very user-friendly.
A lot of broken links Google tells you about can often be totally irrelevant and legacy issues. Google could make it instantly more valuable by telling us which 404s are linked to from only external websites.
Fortunately, you can find your own broken links on-site using the myriad of SEO tools available.
You can also use Analytics to look for broken backlinks on a site with some history of migrations, for instance.
John has clarified some of this before, although he is talking specifically (I think) about errors found by Google Search Console:
- In some cases, crawl errors may come from a legitimate structural issue within your website or CMS. How do you tell? Double-check the origin of the crawl error. If there’s a broken link on your site, in your page’s static HTML, then that’s always worth fixing
- What about the funky URLs that are “clearly broken?” When our algorithms like your site, they may try to find more great content on it, for example by trying to discover new URLs in JavaScript. If we try those “URLs” and find a 404, that’s great and expected. We just don’t want to miss anything important
If you are making websites and want them to rank, the Quality Raters Guidelines document is a great guide for Webmasters to avoid low-quality ratings and potentially avoid punishment algorithms.
Block your internal search function on your site
QUOTE: “Use the robots.txt file on your web server to manage your crawling budget by preventing crawling of infinite spaces such as search result pages. Keep your robots.txt file up to date.” Google, 2017
This will prevent the automatic creation of thin pages and could help prevent against negative SEO attacks, too.
QUOTE: “A robots.txt file is a file on your webserver used to control bots like Googlebot, Google’s web crawler. You can use it to block Google and Bing from crawling parts of your site.” Shaun Anderson, Hobo 2020
CAVEAT: Unless the site is actually built around an extremely well designed architecture. I’ve never came across this, but I see some very well organised big-brands do it. If is not broken do not fix it.
Use canonicals properly
QUOTE: “If your site contains multiple pages with largely identical content, there are a number of ways you can indicate your preferred URL to Google. (This is called “canonicalization”.)” Google, 2007
This will help consolidate signals in the correct pages.
QUOTE: “The canonical link element is extremely powerful and very important to include on your page. Every page on your site should have a canonical link element, even if it is self referencing. It’s an easy way to consolidate ranking signals from multiple versions of the same information. Note: Google will ignore misused canonicals given time.” Shaun Anderson, Hobo 2020
Use proper pagination control on paginated sets of pages
This will help with duplicate content issues.
QUOTE: “Use
rel="next"andrel="prev"links to indicate the relationship between component URLs. This markup provides a strong hint to Google that you would like us to treat these pages as a logical sequence, thus consolidating their linking properties and usually sending searchers to the first page. Google
What you do to handle paginated content will depend on your circumstances.
QUOTE: “Paginated pages are not duplicate content, but often, it would be more beneficial to the user to land on the first page of the sequence. Folding pages in a sequence and presenting a canonical URL for a group of pages has numerous benefits.“ Shaun Anderson, Hobo 2020
Use proper indexation control on pages
Some pages your site may require to have a meta noindex on them.
Identify your primary content assets and improve them instead of optimising low-quality pages (which will get slapped in a future algorithm update).
QUOTE: “Meta tags, when used properly can still be useful in a number of areas outside just ranking pages e.g. to improve click-through rates from the SERP. Abuse them, and you might fall foul of Google’s punitive quality algorithms.“ Shaun Anderson, Hobo 2020
How To Deal With Search Console Indexation Report Errors
How to deal with “Submitted URL marked ‘noindex’” and “Excluded by ‘noindex’ tag” notifications in Search console
Why are you creating pages and asking Google to noindex them? There is always a better way than to noindex pages. Review the pages you are making and check they comply with Google guidelines e.g. are not doorway pages. Check if technically there is a better way to handle noindexed pages.
How to handle “Page with redirect” notifications in Search console
Why do you have URLs in your sitemap that are redirects? This is not ideal. Review and remove the redirects from the sitemap.
What does “ Indexed, not submitted in sitemap” mean in Search Console?
It means Google has crawled your site and found more pages than you have in your sitemap. Depending on the number of pages indicated, this could be a non-issue or a critical issue.
Make sure you know the type of pages you are attempting to get indexed, the page types your CMS produces.
How to deal with “Duplicate page without canonical tag”, “Alternate page with proper canonical tag” and “Submitted URL not selected as canonical” notifications in Search console
Review how you use canonical link elements throughout the site.
How To Deal with “Crawl anomaly” notifications in search console:
QUOTE: “An unspecified anomaly occurred when fetching this URL. This could mean a 4xx- or 5xx-level response code; try fetching the page using Fetch as Google to see if it encounters any fetch issues. The page was not indexed.” Google, 2018
How To Deal With Crawled – currently not indexed:
QUOTE: “The page was crawled by Google, but not indexed. It may or may not be indexed in the future; no need to resubmit this URL for crawling.” Google, 2018
These could be problematic. You should check to see if pages you want indexed are included in this list of URLs. If they are, this could be indicative of a page quality issue.
Read this official article a full list of new features in the Google Search Console Indexation Report,
On-Site; Do I Need A Google XML Sitemap For My Website?
QUOTE: “(The XML Sitemap protocol) has wide adoption, including support from Google, Yahoo!, and Microsoft.“
No. You do NOT, technically, need an XML Sitemap to optimise a site for Google if you have a sensible navigation system that Google can crawl and index easily.
QUOTE: “Some pages we crawl every day. Other pages, every couple of months.” John Mueller, Google
Some pages are more important than others to Googlebot.
HOWEVER you should have a Content Management System that produces one as a best practice – and you should submit that sitemap to Google in Google Search Console. Again – best practice.
Google has said very recently XML and RSS are still a very useful discovery method for them to pick out recently updated content on your site.
QUOTE: “All formats limit a single sitemap to 50MB (uncompressed) and 50,000 URLs. If you have a larger file or more URLs, you will have to break your list into multiple sitemaps.” Google Webmaster Guidelines 2020
An XML Sitemap is a file on your server with which you can help Google easily crawl & index all the pages on your site. This is evidently useful for very large sites that publish lots of new content or updates content regularly.
Your web pages will still get into search results without an XML sitemap if Google can find them by crawling your website if you:
- Make sure all your pages link to at least one other in your site
- Link to your important pages often, with (varying anchor text, in the navigation and in page text content if you want best results)
Remember – Google needs links to find all the pages on your site, and links spread Pagerank, that help pages rank – so an XML sitemap is never a substitute for a great website architecture.
QUOTE: “Sitemaps are an easy way for webmasters to inform search engines about pages on their sites that are available for crawling. In its simplest form, a Sitemap is an XML file that lists URLs for a site along with additional metadata about each URL (when it was last updated, how often it usually changes, and how important it is, relative to other URLs in the site) so that search engines can more intelligently crawl the site.” Sitemaps.org, 2020
Most modern CMS auto-generate XML sitemaps and Google does ask you submit a site-map in Google Search Console, and I do these days.
I prefer to define manually my important pages by links and depth of content, but an XML sitemap is a best practice for most sites.
QUOTE: “We support 50 megabytes for a sitemap file, but not everyone else supports 50 megabytes. Therefore, we currently just recommend sticking to the 10 megabyte limit,” John Mueller, Google
Google wants to know when primary page content is updated, not when supplementary page content is modified – “if the content significantly changes, that’s relevant. If the content, the primary content, doesn’t change,then I wouldn’t update it.
Does Google crawl an XML sitemap and does it crawl the entire sitemap once it starts?
A question was asked in a recent Google Hangout by someone with a website indexation problem:
QUOTE: “How often does Google crawl an XML sitemap and does it crawl the entire sitemap once it starts?”
An XML sitemap is inclusive, not exclusive.
QUOTE: “sitemap files do help us to better understand a website and to better figure out which parts of website need to be recrawled so specifically if you have information in like the last modification date that really helps us to figure out which of these pages are new or have changed that need to be recrawled.” John Mueller Google, 2017
There will be URLs on your site that are not in the XML sitemap that Google will crawl and index. There are URLs in your XML sitemap that Google will probably crawl and not index.
QUOTE: “if you’re looking at the sitemap files in search console you have information on how many URLs are indexed from those sitemap files the important part there is that we look at exactly the URL that you list in the sitemap file so if we index the URL with a different parameter or with different upper or lower case or a slash at the end or not then all of that matters for for that segment file so that that might be an issue to kind of look out there” John Mueller 2017
and
QUOTE: “in the sitemap file we primarily focus on the last modification date so that’s that’s what we’re looking for there that’s where we see that we’ve crawled this page two days ago and today it has changed therefore we should recrawl it today we don’t use priority and we don’t use change frequency in the sitemap file at least at the moment with regards to crawling so I wouldn’t focus too much on priority and change frequency but really on the more factual last modification date information an RSS feed is also a good idea with RSS you can use pubsubhubbub which is a way of getting your updates even faster to Google so using pubsubhubbub is probably the fastest way to to get content where you’re regularly changing things on your site and you want to get that into Google as quickly as possible an RSS feed with pubsubhubbub is is a really fantastic way to get that done.” John Mueller Google 2017
and
QUOTE: “so a [XML] sitemap file helps us to understand which URLs on your website are new or have recently changed so in the second file you can specify a last modification date and with that we can kind of judge as we need to crawl next to make sure that we’re not like behind in keeping up with your website’s indexing so if you have an existing website and you submit a sitemap file and the sitemap file has realistic change dates on there then in an ideal case we would look at that and say oh we know about most of these URLs and here are a handful of URLs that we don’t know about so we’ll go off and crawl those URLs it’s not the case that submitting a sitemap file will replace our normal crawling it essentially just adds to the existing crawling that we do“. John Mueller 2017
Can I put my sitemap file into separate smaller files? Yes.
QUOTE: “Another thing that sometimes helps is to split the sitemap files up into separate chunks of logical chunks for your website so that you understand more where pages are not being indexed and then you can see are the products not being indexed or the categories not being indexed and then you can drill down more and more and figure out where where there might be problems that said we don’t guarantee indexing so just because a sitemap file has a bunch of URLs and it doesn’t mean that we will index all of them that’s still kind of something to keep in mind but obviously you can try to narrow things down a little bit and see where where you could kind of improve that situation.” John Mueller, 2017
The URL is naturally important in an XML sitemap. The only other XML sitemap you should really be concerned about is the DATE LAST MODIFIED. You can ignore the FREQUENCY attribute:
QUOTE – “we don’t use that at all ….no we only use the date in the [XML] sitemap file “ John Mueller, Google 2017
How many times a week is the index status data in search console updated?
It is updated 2-3 times a week.
Should you use sitemaps with last modified for expired content?
Expired pages can be picked up quickly if you use a last modified date.
Why Doesn’t Google Crawl and Index My Website XML Sitemap Fully?
QUOTE: “So we don’t guarantee indexing. So just because something is in a sitemap file isn’t a guarantee that we will actually index it. It might be completely normal that we don’t actually index all of those pages… that even if you do everything technically correct there’s no guarantee that we will actually index everything.” John Mueller, 2018
I have looked at a lot of sites with such indexation problems. In my experience the most common reasons for poor indexation levels of a sitemap on a site with thousands or millions of pages are:
- doorway pages
- thin pages
Pages that are almost guaranteed to get into Google’s index have one common feature: They have unique content on them.
In short, if you are building doorway type pages without unique content on them, Google won’t index them all properly. If you are sloppy, and also produce thin pages on the site, Google won’t exactly reward that behaviour either.
QUOTE: “with regards to product pages not being indexed in Google again that’s something where maybe that’s essentially just working as intended where we just don’t index everything from them from any website. I think for most websites if you go into the sitemap section or the indexing section you’ll see that we index just a fraction of all of the content on the website. I think for any non-trivial sized website indexing all of the content would be a very big exception and I would be very surprised to see that happen.” John Mueller, Google 2018
Google rewards a smaller site with fat, in-depth pages a lot more than a larger site with millions of thinner pages.
Perhaps Google can work out how much unique text a particular site has on it and weighs that score with the number of pages the site produces. Who knows.
The important takeaway is ‘Why would Google let millions of your auto-generated pages rank, anyway?”
QUOTE: “really create something useful for users in individual locations maybe you do have some something unique that you can add there that makes it more than just a doorway page“. John Mueller, Google 2017
Google Not Indexing URLs In Your Sitemap? Creating New Sitemaps Won’t Help
It is unlikely that modifying your XML sitemaps alone will result in more pages on your site being indexed if the reason the URLs are not indexed in the first place is quality-related:
QUESTION: “I’ve 100 URLs in a xml sitemap. 20 indexed and 80 non-indexed. Then I uploaded another xml sitemap having non-indexed 80 URLs. So same URL’s in multiple sitemap. . . Is it a good practice? Can it be harmful or useful for my site?”
and from Google:
QUOTE: “That wouldn’t change anything. If we’re not indexing 80 URLs from a normal 100 URL site, that sounds like you need to work on the site instead of on sitemap submissions. Make it awesome! Make every page important!” John Mueller, 2018
Most links in your XML Sitemap should be Canonical and not redirects
Google wants final destination URLs and not links that redirect to some other location.
QUOTE: “in general especially, for landing pages…. we do recommend to use the final destination URL in the sitemap file a part of the reason for that is so that we can report explicitly on those URLs in search console …. and you can look at the indexing information just for that sitemap file and that’s based on the exact URLs that you have there. The other reason we recommend doing that is that we use a sitemaps URLs as a part of trying to understand which URL should be the canonical for a piece of content so that is the URL that we should show in the search results and if the sitemap file says one URL and it redirects to a different URL then you’re giving us kind of conflicting information.” John Mueller, Google, 2018
and
QUOTE: “actually the date the last modification date of some of these URLs because with that date we can figure out do we need to recall these URLS to figure out what is new or what is different on these URLs or are these old URLs that basically we might already know about we decided not to index so what I would recommend doing there is creating an XML sitemap file with the dates with the last modification dates just to make sure that Google has all of the information that it can get.” John Mueller, Google, 2018
Read my article on managing redirects properly on a site.
Sometime non-canonical versions of your URLs are indexed instead
QUOTE: “I would recommend doing there is double-checking the URLs themselves and double-checking how they’re actually indexed in Google so it might be that we don’t actually index the URL as you listed in the sitemap file but rather a slightly different version that is perhaps linked in within your website so like I mentioned before the trailing slash is very common or ducked up the non WWW(version) – all of those are technically different URLs and we wouldn’t count that for the sitemap as being indexed if we index it with a slightly different URL.” John Mueller, Google 2018
It is ‘normal’ for Google NOT to index all the pages on your site.
What Is the maximum size limit of an XML Sitemap?
QUOTE: “We support 50 megabytes for a sitemap file, but not everyone else supports 50 megabytes. Therefore, we currently just recommend sticking to the 10 megabyte limit,“ John Mueller, Google 2014
Google wants to know when primary page content is updated, not when supplementary page content is modified – “if the content significantly changes, that’s relevant. If the content, the primary content, doesn’t change,then I wouldn’t update it.“
Why Is The Number Of Indexed URLs in Search Console Dropping?
Google has probably worked out you are creating doorway-type pages with no-added-value.
QUOTE: “The Panda algorithm may continue to show such a site for more specific and highly-relevant queries, but its visibility will be reduced for queries where the site owner’s benefit is disproportionate to the user’s benefit. Google
Page Quality & Site Quality
Google measures quality on a per page basis and also look at the site overall (with site-wide quality being affected by the quality of individual pages.
Do no indexed pages have an impact on site quality?
Only indexable pages have an impact on site quality. You can use a noindex on low-quality pages if page quality cannot be improved.
QUOTE: “If you if you have a website and you realize you have low-quality content on this website somewhere then primarily of course we’d recommend increasing the quality of the content if you really can’t do that if there’s just so much content there that you can’t really adjust yourself if it’s user-generated content all of these things then there there might be reasons where you’d say okay I’ll use a no index for the moment to make sure that this doesn’t affect the bigger picture of my website.” John Mueller, Google 2017
You should only be applying noindex to pages as a temporary measure at best.
Google wants you to improve the content that is indexed to improve your quality scores.
Identifying Which Pages On Your Own Site Hurt Or Help Your Rankings
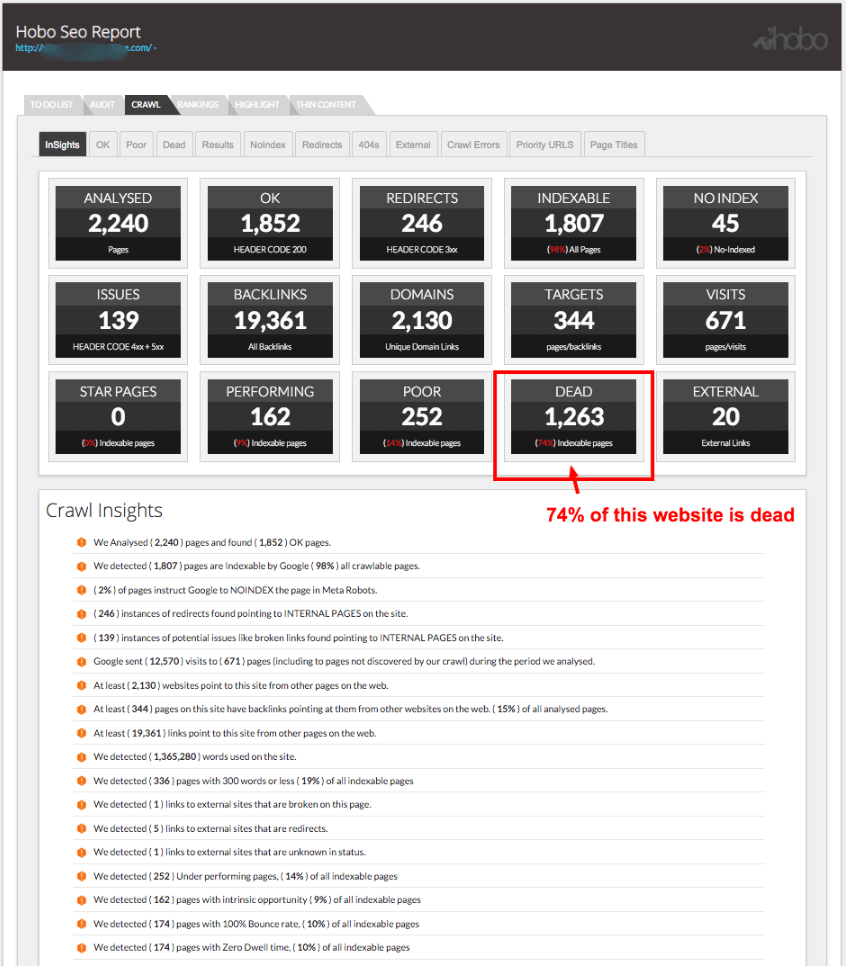
Separating the wheat from the chaff.
Being ‘indexed’ is important. If a page isn’t indexed, the page can’t be returned by Google in Search Engine Results Pages.
While getting as many pages indexed in Google was historically a priority for an SEO, Google is now rating the quality of pages on your site and the type of pages it is indexing.
So bulk indexation is no guarantee of success – in fact, it’s a risk to index all URLs on your site, especially if you have a large, sprawling site.
If you have a lot of low-quality pages (URLs) indexed on your site compared to high-quality pages (URLs)… Google has told us it is marking certain sites down for that.
Some URLs are just not welcome to be indexed as part of your website content anymore.
Do I need to know which pages are indexed?
No. Knowing is useful, of course, but largely unnecessary. Indexation is never a guarantee of traffic.
Some SEO would tend to scrape Google to get indexation data on a website. I’ve never bothered with that. Most sites I work with have XML sitemap files, so an obvious place to start to look at such issues is Google Search Console.
Google will tell you how many pages you have submitted in a sitemap, and how many pages are indexed. It will not tell you which pages are indexed, but if there is a LARGE discrepancy between SUBMITTED and INDEXED, it’s very much worth digging deeper.
If Google is de-indexing large swaths of your content that you have actually submitted as part of an XML sitemap, then a problem is often afoot.
Unfortunately, with this method, you don’t get to see the pages produced by the CMS out with the XML sitemap – so this is not a full picture of the ‘health’ of your website.
QUOTE: “Make sure Google can crawl your website, index and rank all your primary pages by only serving Googlebot high-quality, user friendly and fast loading pages to index.” Shaun Anderson, Hobo 2020
Identifying Dead Pages
I usually start with a performance analysis that involves merging data from a physical crawl of a website with analytics data and Google Search Console data. A content type analysis will identify the type of pages the cms generates. A content performance analysis will gauge how well each section of the site performs.
If you have 100,000 pages on a site, and only 1,000 pages get organic traffic from Google over a 3-6 month period – you can make the argument 99% of the site is rated as ‘crap’ (at least as far as Google rates pages these days).
I group pages like these together as ‘dead pages‘ for further analysis. Deadweight, ‘dead’ for short.
The thinking is if the pages were high-quality, they would be getting some kind of organic traffic.
Identifying which pages receive no organic visitors over a sensible timeframe is a quick if noisy, way to separate pages that obviously WORK from pages that DONT – and will help you clean up a large portion of redundant URLs on the site.
It helps to see page performance in the context of longer timeframes as some types of content can be seasonal, for instance, and produce false positives over a shorter timescale. It is important to trim content pages carefully – and there are nuances.
False Positives
Experience can educate you when a page is high-quality and yet receives no traffic. If the page is thin, but is not manipulative, is indeed ‘unique’ and delivers on a purpose with little obvious detectable reason to mark it down, then you can say it is a high-quality page – just with very little search demand for it. Ignored content is not the same as ‘toxic’ content.
False positives aside, once you identify the pages receiving no traffic, you very largely isolate the type of pages on your site that Google doesn’t rate – for whatever reason. A strategy for these pages can then be developed.
Identifying Content That Can Potentially Hurt Your Rankings
As you review the pages, you’re probably going to find pages that include:
- out of date, overlapping or irrelevant content
- collections of pages not paginated properly
- indexable pages that shouldn’t be indexed
- stub pages
- indexed search pages
- pages with malformed HTML and broken images
- auto-generated pages with little value
You will probably find ‘dead’ pages you didn’t even know your cms produced (hence why an actual crawl of your site is required, rather than just working from a lit of URLs form an XML sitemap, for instance).
Those pages need to be cleaned up, Google has said. And remaining pages should:
QUOTE: “stand on their own” John Mueller, Google
Google doesn’t approve of most types of auto-generated pages so you don’t want Google indexing these pages in a normal fashion.
Judicious use of ‘noindex,follow‘ directive in robots meta tags, and sensible use of the canonical link element are required implementation on most sites I see these days.
The pages that remain after a URL clear-out, can be reworked and improved.
In fact – they MUST BE improved if you are to win more rankings and get more Google organic traffic in future.
This is time-consuming – just like Google wants it to be. You need to review DEAD pages with a forensic eye and ask:
- Are these pages high-quality and very relevant to a search term?
- Do these pages duplicate content on the pages on the site?
- Are these pages automatically generated, with little or no unique text content on them?
- Is the purpose of this page met WITHOUT sending visitors to another page e.g. doorway pages?
- Will these pages ever pick up natural links?
- Is the intent of these pages to inform first? ( or profit from organic traffic through advertising?)
- Are these pages FAR superior to the competition in Google presently for the search term you want to rank? This is actually very important.
If the answer to any of the above is NO – then it is imperative you take action to minimise the amount of these types of pages on your site.
What about DEAD pages with incoming backlinks or a lot of text content?
Bingo! Use 301 redirects (or use canonical link elements) to redirect any asset you have with some value to Googlebot to equivalent, up to date sections on your site. Do NOT just redirect these pages to your homepage.
Rework available content before you bin it
High-quality content is expensive – so rework content when it is available. Medium quality content can always be made higher quality – in fact – a page is hardly ever finished. EXPECT to come back to your articles every six months to improve them to keep them moving in the right direction.
Sensible grouping of content types across the site can often leave you with substantial text content that can be reused and repackaged in a way that the same content originally spread over multiple pages, now consolidated into one page reworked and shaped around a topic, has a considerably much more successful time of it in Google SERPs.
Well, it does if the page you make is useful and has a purpose other than just to make money.
REMEMBER – DEAD PAGES are only one aspect of a site review. There’s going to be a large percentage of any site that gets a little organic traffic but still severely underperforms, too – tomorrows DEAD pages. I call these POOR pages in my reviews.
Minimise Low-Quality Content & Overlapping Text Content
Specific Advice From Google on Pruning Content From Your Site
If you have very low-quality site from a content point of view, just deleting the content (or noindexing it) is probably not going to have a massive positive impact on your rankings.
Ultimately the recommendation is to focus on “improving content” as “you have the potential to go further down if you remove that content“.
QUOTE: “Ultimately, you just want to have a really great site people love. I know it sounds like a cliché, but almost [all of] what we are looking for is surely what users are looking for. A site with content that users love – let’s say they interact with content in some way – that will help you in ranking in general, not with Panda. Pruning is not a good idea because with Panda, I don’t think it will ever help mainly because you are very likely to get Panda penalized – Pandalized – because of low-quality content…content that’s actually ranking shouldn’t perhaps rank that well. Let’s say you figure out if you put 10,000 times the word “pony” on your page, you rank better for all queries. What Panda does is disregard the advantage you figure out, so you fall back where you started. I don’t think you are removing content from the site with potential to rank – you have the potential to go further down if you remove that content. I would spend resources on improving content, or, if you don’t have the means to save that content, just leave it there. Ultimately people want good sites. They don’t want empty pages and crappy content. Ultimately that’s your goal – it’s created for your users.” Gary Illyes, Google 2017
Specific Advice From Google On Low-Quality Content On Your Site
And remember the following, specific advice from Google on removing low-quality content from a domain:
******” Quote from Google: One other specific piece of guidance we’ve offered is that low-quality content on some parts of a website can impact the whole site’s rankings, and thus removing low-quality pages, merging or improving the content of individual shallow pages into more useful pages, or moving low-quality pages to a different domain could eventually help the rankings of your higher-quality content. GOOGLE ******
Google may well be able to recognise ‘low-quality’ a lot better than it does ‘high-quality’ – so having a lot of ‘low-quality’ pages on your site is potentially what you are actually going to be rated on (if it makes up most of your site) – now, or in the future. NOT your high-quality content.
This is more or less explained by Google spokespeople like John Mueller. He is constantly on about ‘folding’ thin pages together, these days (and I can say that certainly has a positive impact on many sites).
While his advice in this instance might be specifically about UGC (user-generated content like forums) – I am more interested in what he has to say when he talks about the algorithm looking at the site “overall” and how it ‘thinks’ when it finds a mixture of high-quality pages and low-quality pages:
QUOTE: “For instance, we would see a lot of low-quality posts in a forum. We would index those low-quality pages. And we’d also see a lot of really high-quality posts, with good discussions, good information on those pages. And our algorithms would be kind of stuck in a situation with, well, there’s a lot of low-quality content here, but there’s also a lot of high-quality content here. So how should we evaluate the site overall? And usually, what happens is, our algorithms kind of find some middle ground……. what you’d need to do to, kind of, move a step forward, is really try to find a way to analyze the quality of your content, and to make sure that the high-quality content is indexed and that the lower-quality content doesn’t get indexed by default.” John Mueller, Google 2014
And Google has clearly said in print:
QUOTE: “low-quality content on part of a site can impact a site’s ranking as a whole.” Amit Singhal, Google, 2011
Avoid Google’s punitive algorithms
Fortunately, we don’t actually need to know and fully understand the ins-and-outs of Google’s algorithms to know what the best course of action is.
The sensible thing in light of Google’s punitive algorithms is just to not let Google index (or more accurately, rate) low-quality pages on your site. And certainly – stop publishing new ‘thin’ pages. Don’t put your site at risk.
If pages get no organic traffic anyway, are out-of-date for instance, and improving them would take a lot of effort and expense, why let Google index them normally, if by rating them it impacts your overall score? Clearing away the low-quality stuff lets you focus on building better stuff on other pages that Google will rank and beyond.
Ideally, you would have a giant site and every page would be high-quality – but that’s not practical.
A myth is that pages need a lot of text to rank. They don’t, but a lot of people still try to make text bulkier and unique page-to-page.
While that theory is sound (when focused on a single page, when the intent is to deliver utility content to a Google user) using old school SEO techniques on especially a large site spread out across many pages seems to amplify site quality problems, after recent algorithm changes, and so this type of optimisation without keeping an eye on overall site quality is self-defeating in the long run.
Every site is impacted by how highly Google rates it.
There are many reasons a website loses traffic from Google. Server changes, website problems, content changes, downtimes, redesigns, migrations… the list is extensive.
Sometimes, Google turns up the dial on demands on ‘quality’, and if your site falls short, a website traffic crunch is assured. Some sites invite problems ignoring Google’s ‘rules’ and some sites inadvertently introduce technical problems to their site after the date of a major algorithm update and are then impacted negatively by later refreshes of the algorithm.
Comparing your Google Analytics data side by side with the dates of official algorithm updates is useful in diagnosing a site health issue or traffic drop. In the above example, a new client thought it was a switch to HTTPS and server downtime that caused the drop when it was actually the May 6, 2015, Google Quality Algorithm (originally called Phantom 2 in some circles) that caused the sudden drop in organic traffic – and the problem was probably compounded by unnatural linking practices. (This client did eventually receive a penalty for unnatural links when they ignored our advice to clean up).
Thin Content
A quick check of how the site was laid out soon uncovered a lot of unnecessary pages, or what Google calls thin, overlapping content. This observation would go a long way to confirming that the traffic drop was indeed caused by the May algorithm change.
Another obvious way to gauge the health of a site is to see which pages on the site get zero traffic from Google over a certain period of time. I do this by merging analytics data with crawl data – as analytics doesn’t give you data on pages it sends no traffic to.
Often, this process can highlight low-quality pages on a site.
Google calls a lot of pages ‘thin’ or ‘overlapping’ content these days.
Algorithm Changes
Algorithm changes seem to center on reducing the effectiveness of old-school SEO techniques, with the May 2015 Google ‘Quality’ algorithm update bruisingly familiar. An algorithm change is usually akin to ‘community service’ for the business impacted negatively.
If your pages were designed to get the most out of Google, with commonly known and now outdated SEO techniques chances are Google has identified this and is throttling your rankings in some way. Google will continue to throttle rankings until you clean your pages up.
If Google thinks your links are manipulative, they want them cleaned up, too.
Actually – looking at the backlink profile of this customer, they are going to need a disavow file prepared too.
That is unsurprising in today’s SEO climate.
What could be argued was ‘highly relevant’ or ‘optimised’ on-site SEO for Google just a few years ago is now being treated more like ‘web spam’ by punitive algorithms, rather than just ‘over-optimisation’.
Google went through the SEO playbook and identified old techniques and use them against you today – meaning every SEO job you take on always has a clean up aspect now.
Google has left a very narrow band of opportunity when it comes to SEO – and punishments are designed to take you out of the game for some time while you clean up the infractions.
Technical Issues
Google has a LONG list of technical requirements it advises you meet, on top of all the things it tells you NOT to do to optimise your website. Meeting Google’s technical guidelines is no magic bullet to success – but failing to meet them can impact your rankings in the long run – and the odd technical issue can actually severely impact your entire site if rolled out across multiple pages.
The benefit of adhering to technical guidelines is often a second-order benefit.
You won’t get penalised or filtered when others do. When others fall, you will rise.
Mostly – individual technical issues will not be the reason you have ranking problems, but they still need to be addressed for any second-order benefit they provide.
Google spokespeople say ‘user-experience’ is NOT A RANKING FACTOR but this might be splitting hairs as lots of the rules are designed to guarantee a good a ‘user experience’ as possible for Google’s users.
Most of Google’s technical guidelines can be interpreted in this way. And most need to be followed, whether addressing these issues has an immediate positive impact on the site or not.
Whether or not your site has been impacted in a noticeable way by these algorithms, every SEO project must start with a historical analysis of site performance. Every site has things to clean up and to optimise in a modern way.
The sooner you understand why Google is sending you less traffic than it did last year, the sooner you can clean it up and focus on proactive SEO that starts to impact your rankings in a positive way.
Avoid making doorway pages on your website
Search Engine Land offered this clarification from Google:
QUOTE: “How do you know if your web pages are classified as a “doorway page?” Google said asked yourself these questions:
- Is the purpose to optimise for search engines and funnel visitors into the actual usable or relevant portion of your site, or are they an integral part of your site’s user experience?
- Are the pages intended to rank on generic terms yet the content presented on the page is very specific?
- Do the pages duplicate useful aggregations of items (locations, products, etc.) that already exist on the site for the purpose of capturing more search traffic?
- Are these pages made solely for drawing affiliate traffic and sending users along without creating unique value in content or functionality?
- Do these pages exist as an “island?” Are they difficult or impossible to navigate to from other parts of your site? Are links to such pages from other pages within the site or network of sites created just for search engines?” Barry Schwartz, 2015
Also:
QUOTE: “Well, a doorway page would be if you have a large collection of pages where you’re just like tweaking the keywords on those pages for that.
I think if you focus on like a clear purpose for the page that’s outside of just I want to rank for this specific variation of the keyword then that’s that’s usually something that leads to a reasonable result.
Whereas if you’re just taking a list of keywords and saying I need to make pages for each of these keywords and each of the permutations that might be for like two or three of those keywords then that’s just creating pages for the sake of keywords which is essentially what we look at as a doorway.” Barry Schwartz, 2015
Note:
QUOTE: “focus on like a clear purpose for the page that’s outside of just I want to rank for this specific variation of the keyword.”
That is because sometimes, often, in fact, there is an alternative to doorway pages for location pages that achieve essentially the same thing for webmasters.
Naturally, business owners want to rank for lots of keywords in organic listings with their website. The challenge for webmasters is that Google doesn’t want business owners to rank for lots of keywords using auto-generated content especially when that produces A LOT of pages on a website using (for instance) a list of keyword variations page-to-page.
QUOTE: “7.4.3 Automatically Generated Main Content Entire websites may be created by designing a basic template from which hundreds or thousands of pages are created, sometimes using content from freely available sources (such as an RSS feed or API). These pages are created with no or very little time, effort, or expertise, and also have no editing or manual curation. Pages and websites made up of autogenerated content with no editing or manual curation, and no original content or value added for users, should be rated Lowest.” Google Search Quality Evaluator Guidelines, 2017
The end-result is webmasters create doorway pages without even properly understanding what they represent to Google and without realising Google will not index all these auto-generated pages:
QUOTE: “Doorway pages (bridge pages, portal pages, jump pages, gateway pages or entry pages) are web pages that are created for the deliberate manipulation of search engine indexes (spamdexing).” Wikipedia, 2020
Also:
QUOTE: “In digital marketing and online advertising, spamdexing (web spam)…. is the deliberate manipulation of search engine indexes” Wikipedia, 2020
It is interesting to note that Wikipedia might make clear distinctions between what doorway page is, what spamdexing is and what a landing page is…
QUOTE: “Landing pages are regularly misconstrued to equate to Doorway pages within the literature. The former are content rich pages to which traffic is directed within the context of pay-per-click campaigns…” Wikipedia, 2020
For me, Google blurs that line here.
Google has declared:
QUOTE: “Doorways are sites or pages created to rank highly for specific search queries. They are bad for users because they can lead to multiple similar pages in user search results, where each result ends up taking the user to essentially the same destination. They can also lead users to intermediate pages that are not as useful as the final destination.
Here are some examples of doorways:
- Having multiple domain names or pages targeted at specific regions or cities that funnel users to one page
- Pages generated to funnel visitors into the actual usable or relevant portion of your site(s)
- Substantially similar pages that are closer to search results than a clearly defined, browseable hierarchy”
Google Webmaster Guidelines, 2020
Note:
QUOTE: “Doorways are sites or pages created to rank highly for specific search queries” Google Webmaster Guidelines, 2020
It is not just location pages that are classed as doorway pages:
QUOTE: “For Google, that’s probably overdoing it and ends up in a situation you basically create a doorway site …. with pages of low value…. that target one specific query.” John Mueller 2018
If your website is made up of lower-quality doorway type pages using old techniques (which more and more labelled as spam) then Google will not index all of the pages and your website ‘quality score’ is probably going to be negatively impacted.
Google’s John Mueller advised someone that:
QUOTE: “he should not go ahead and build out 1,300 city based landing pages, with the strategy of trying to rank for your keyword phrase + city name. He said that would be a doorway page and against Google’s guidelines.” Barry Schwartz, 2019
If you are making keyword rich location pages for a single business website, there’s a risk these pages will be classed doorway pages.
If you know you have VERY low-quality doorway pages on your site, you should remove them or rethink your entire strategy if you want to rank high in Google for the long term.
Location-based pages are suitable for some kind of websites, and not others.
What are doorway pages?
A lot of webmasters and business owners do not realise they are building what Google classes as dreaded doorway pages.
Google algorithms consistently target sites with doorway pages in quality algorithm updates. The definition of a “doorway page” can change over time but it is safe to say you do not want an email like this from Google via Search Console:
QUOTE: “Notice of detected doorway pages on xxxxxxxx – Dear site owner or webmaster of xxxxxxxx, We’ve detected that some of your site’s pages may be using techniques that are outside Google’s Webmaster Guidelines. Specifically, your site may have what we consider to be doorway pages – groups of “cookie cutter” or low-quality pages…. We believe that doorway pages typically create a frustrating user experience, and we encourage you to correct or remove any pages that violate our quality guidelines. Once you’ve made these changes, please submit your site for reconsideration in Google’s search results. If you have any questions about how to resolve this issue, please see our Webmaster Help Forum for support.” Google Search Quality Team, 2011
Google classes many types of pages as doorway pages.
Doorway pages can be thought of as lots of pages on a website designed to rank for very specific keywords using minimal original text content e.g. location pages often end up looking like doorway pages.
In the recent past, location-based SERPs were often lower-quality, and so Google historically ranked location-based doorway pages in many instances.
There is some confusion for real businesses who THINK they SHOULD rank for specific locations where they are not geographically based and end up using doorway-type pages to rank for these locations.
Google said a few years ago:
QUOTE: “For example, searchers might get a list of results that all go to the same site. So if a user clicks on one result, doesn’t like it, and then tries the next result in the search results page and is taken to that same site that they didn’t like, that’s a really frustrating experience.” Brian White, Google 2015
A question about using content spread across multiple pages and targeting different geographic locations on the same site was asked in the recent Hangout with Google’s John Mueller:
QUOTE: “the content that will be presented in terms of the clinics that will be listed looking fairly similar right and the same I think holds true if you look at it from the location …… we’re conscious that this causes some kind of content duplication so the question is is this type … to worry about? ” Webmaster Question, 2017
Bearing in mind that (while it is not the optimal use of pages) Google does not ‘penalise’ a website for duplicating content across internal pages in a non-malicious way, John’s clarification of location-based pages on a site targeting different regions is worth noting:
QUOTE: “For the most part it should be fine I think the the tricky part that you need to be careful about is more around doorway pages in the sense that if all of these pages end up with the same business then that can look a lot like a doorway page but like just focusing on the content duplication part that’s something that for the most part is fine what will happen there is will index all of these pages separately because from from a kind of holistic point of view these pages are unique they have unique content on them they might have like chunks of text on them which are duplicated but on their own these pages are unique so we’ll index them separately and in the search results when someone is searching for something generic and we don’t know which of these pages are the best ones we’ll pick one of these pages and show that to the user and filter out the other variations of that that page so for example if someone in Ireland is just looking for dental bridges and you have a bunch of different pages for different kind of clinics ….. and probably will pick one of those pages and show those in the search results and filter out the other ones.
But essentially the idea there is that this is a good representative of the the content from your website and that’s all that we would show to users on the other hand if someone is specifically looking for let’s say dental bridges in Dublin then we’d be able to show the appropriate clinic that you have on your website that matches that a little bit better so we’d know dental bridges is something that you have a lot on your website and Dublin is something that’s unique to this specific page so we’d be able to pull that out and to show that to the user like that so from a pure content duplication point of view that’s not really something I totally worry about.
I think it makes sense to have unique content as much as possible on these pages but it’s not not going to like sync the whole website if you don’t do that we don’t penalize a website for having this kind of deep duplicate content and kind of going back to the first thing though with regards to doorway pages that is something I definitely look into to make sure that you’re not running into that so in particular if this is like all going to the same clinic and you’re creating all of these different landing pages that are essentially just funneling everyone to the same clinic then that could be seen as a doorway page or a set of doorway pages on our side and it could happen that the web spam team looks at that and says this is this is not okay you’re just trying to rank for all of these different variations of the keywords and the pages themselves are essentially all the same and they might go there and say we need to take a manual action and remove all these pages from search so that’s kind of one thing to watch out for in the sense that if they are all going to the same clinic then probably it makes sense to create some kind of a summary page instead whereas if these are going to two different businesses then of course that’s kind of a different situation it’s not it’s not a doorway page situation.” John Mueller, Google 2017
The takeaway here is that if you have LOTS of location pages serving ONE SINGLE business in one location, then those are very probably classed as some sort of doorway pages, and probably old-school techniques for these type of pages will see them classed as lower-quality – or even – spammy pages.
Google has long warned webmasters about using Doorway pages but many sites still employ them, because, either:
- their business model depends on it for lead generation
- the alternative is either a lot of work or
- they are not creative enough or
- they are not experienced enough to avoid the pitfalls of having lower-quality doorway pages on a site or
- they are experienced enough to understand what impact they might be having on any kind of site quality score
Google has a doorway page algorithm which no doubt they constantly improve upon. Google warned:
QUOTE: “Over time, we’ve seen sites try to maximize their “search footprint” without adding clear, unique value. These doorway campaigns manifest themselves as pages on a site, as a number of domains, or a combination thereof. To improve the quality of search results for our users, we’ll soon launch a ranking adjustment to better address these types of pages. Sites with large and well-established doorway campaigns might see a broad impact from this change.” Google, 2015
If you have location pages that serve multiple locations or businesses, then those are not doorway pages and should be improved uniquely to rank better, according to John’s advice.
SEO To Avoid
Google has a VERY basic organic search engine optimisation starter guide pdf for webmasters, which they use internally:
QUOTE: “Although this guide won’t tell you any secrets that’ll automatically rank your site first for queries in Google (sorry!), following the best practices outlined below will make it easier for search engines to both crawl and index your content.” Google, 2008
It is still worth a read, even if it is VERY basic, best practices for your site.
No search engine will EVER tell you what actual keywords to put on your site to improve individual rankings or get more converting organic traffic – and in Google – that’s the SINGLE MOST IMPORTANT thing you want to know!
Google specifically mentions something very important in the guide:
QUOTE: “Creating compelling and useful content will likely influence your website more than any of the other factors discussed here.” Google SEO Starter Guide, 2017
This starter guide is still very useful for beginners.
I do not think there is anything in the 2017 guide that is really useful if you have been working online since the last starter guide was first published (2008) and its first update was announced (2010). It still leaves out some of the more complicated technical recommendations for larger sites.
I usually find it useful to keep an eye on what Google tells you to avoid in such documents, which are:
-
AVOID: “Don’t let your internal search result pages be crawled by Google. Users dislike clicking a search engine result only to land on another search result page on your site.”
-
AVOID: “Allowing URLs created as a result of proxy…”
-
AVOID: “Choosing a title that has no relation to the content on the page.”
-
AVOID: “Using default or vague titles like “Untitled” or “New Page 1″.”
-
AVOID: “Using a single title across all of your site’s pages or a large group of pages.”
-
AVOID: “Using extremely lengthy titles that are unhelpful to users.”
-
AVOID: “Stuffing unneeded keywords in your title tags.”
-
AVOID: “Writing a description meta tag that has no relation to the content on the page.”
-
AVOID: “Using generic descriptions like “This is a web page” or “Page about baseball cards”.”
-
AVOID: “Filling the description with only keywords.”
-
AVOID: “Copying and pasting the entire content of the document into the description meta tag.”
-
AVOID: “Using a single description meta tag across all of your site’s pages or a large group of pages.”
-
AVOID: “Placing text in heading tags that wouldn’t be helpful in defining the structure of the page.”
-
AVOID: “Using heading tags where other tags like <em> and <strong> may be more appropriate.”
-
AVOID: “Erratically moving from one heading tag size to another.”
-
AVOID: “Excessive use of heading tags on a page.”
-
AVOID: “Very long headings.”
-
AVOID: “Using heading tags only for styling text and not presenting structure.”
-
AVOID: “Using invalid ‘Structured Data ‘markup.”
-
AVOID: “Changing the source code of your site when you are unsure about implementing markup.”
-
AVOID: “Adding markup data which is not visible to users.”
-
AVOID: “Creating fake reviews or adding irrelevant markups.”
-
AVOID: “Creating complex webs of navigation links, for example, linking every page on your site to every other page.”
-
AVOID: “Going overboard with slicing and dicing your content (so that it takes twenty clicks to reach from the homepage).”
-
AVOID: “Having a navigation based entirely on images, or animations.”
-
AVOID: “Requiring script or plugin-based event-handling for navigation”
-
AVOID: “Letting your navigational page become out of date with broken links.”
-
AVOID: “Creating a navigational page that simply lists pages without organizing them, for example by subject.”
-
AVOID: “Allowing your 404 pages to be indexed in search engines (make sure that your web server is configured to give a 404 HTTP status code or – in the case of JavaScript-based sites – include a noindex robots meta-tag when non-existent pages are requested).”
-
AVOID: “Blocking 404 pages from being crawled through the robots.txt file.”
-
AVOID: “Providing only a vague message like “Not found”, “404”, or no 404 page at all.”
-
AVOID: “Using a design for your 404 pages that isn’t consistent with the rest of your site.”
-
AVOID: “Using lengthy URLs with unnecessary parameters and session IDs.”
-
AVOID: “Choosing generic page names like “page1.html”.”
-
AVOID: “Using excessive keywords like “baseball-cards-baseball-cards-baseballcards.htm”.”
-
AVOID: “Having deep nesting of subdirectories like “…/dir1/dir2/dir3/dir4/dir5/dir6/page.html”.”
-
AVOID: “Using directory names that have no relation to the content in them.”
-
AVOID: “Having pages from subdomains and the root directory access the same content, for example, “domain.com/page.html” and “sub.domain.com/page.html”.”
-
AVOID: “Writing sloppy text with many spelling and grammatical mistakes.”
-
AVOID: “Awkward or poorly written content.”
-
AVOID: “Embedding text in images and videos for textual content: users may want to copy and paste the text and search engines can’t read it.”
-
AVOID: “Dumping large amounts of text on varying topics onto a page without paragraph, subheading, or layout separation.”
-
AVOID: “Rehashing (or even copying) existing content that will bring little extra value to users.”
-
AVOID: “Having duplicate or near-duplicate versions of your content across your site.”
-
AVOID: “Inserting numerous unnecessary keywords aimed at search engines but are annoying or nonsensical to users.”
-
AVOID: “Having blocks of text like “frequent misspellings used to reach this page” that add little value for users.”
-
AVOID: “Deceptively hiding text from users, but displaying it to search engines.”
-
AVOID: “Writing generic anchor text like “page”, “article”, or “click here”.”
-
AVOID: “Using text that is off-topic or has no relation to the content of the page linked to.”
-
AVOID: “Using the page’s URL as the anchor text in most cases, although there are certainly legitimate uses of this, such as promoting or referencing a new website’s address.”
-
AVOID: “Writing long anchor text, such as a lengthy sentence or short paragraph of text.”
-
AVOID: “Using CSS or text styling that make links look just like regular text.”
-
AVOID: “Using excessively keyword-filled or lengthy anchor text just for search engines.”
-
AVOID: “Creating unnecessary links that don’t help with the user’s navigation of the site.”
-
AVOID: “Using generic filenames like “image1.jpg”, “pic.gif”, “1.jpg” when possible—if your site has thousands of images you might want to consider automating the naming of the images.”
-
AVOID: “Writing extremely lengthy filenames.”
-
AVOID: “Stuffing keywords into alt text or copying and pasting entire sentences.”
-
AVOID: “Writing excessively long alt text that would be considered spammy.”
-
AVOID: “Using only image links for your site’s navigation”.
-
AVOID: “Attempting to promote each new, small piece of content you create; go for big, interesting items.”
-
AVOID: “Involving your site in schemes where your content is artificially promoted to the top….”
-
AVOID: “Spamming link requests out to all sites related to your topic area.”
-
AVOID: “Purchasing links from another site with the aim of getting PageRank”
This is straightforward stuff but sometimes it’s the simple stuff that often gets overlooked. Of course, you combine the above together with the technical recommendations in Google guidelines for webmasters.
Don’t make these simple but dangerous mistakes…..
- Avoid duplicating content on your site found on other sites. Yes, Google likes content, but it *usually* needs to be well linked to, unique and original to get you to the top!
- Don’t hide text on your website. Google may eventually remove you from the SERPs.
- Don’t buy 1000 links and think “that will get me to the top!”. Google likes natural link growth and often frowns on mass link buying.
- Don’t get everybody to link to you using the same “anchor text” or link phrase. This could flag you as a ‘rank modifier’. You don’t want that.
- Don’t chase Google PR by chasing 100′s of links. Think quality of links….not quantity.
- Don’t buy many keyword rich domains, fill them with similar content and link them to your site. This is lazy and dangerous and could see you ignored or worse banned from Google. It might have worked yesterday but it sure does not work today without some grief from Google.
- Do not constantly change your site pages names or site navigation without remembering to employ redirects. This just screws you up in any search engine.
- Do not build a site with a JavaScript navigation that Google, Yahoo and Bing cannot crawl.
- Do not link to everybody who asks you for reciprocal links. Only link out to quality sites you feel can be trusted.
- Do not spam visitors with ads and pop-ups.
Don’t Flag Your Site With Spam
A primary goal of any ‘rank modification’ is not to flag your site as ‘suspicious’ to Google’s algorithms or their webspam team.
I would recommend you forget about tricks like links in H1 tags etc. or linking to the same page 3 times with different anchor text on one page.
Forget about ‘which is best’ when considering things you shouldn’t be wasting your time with.
Every element on a page is a benefit to you until you spam it.
Put a keyword in every tag and you may flag your site as ‘trying too hard’ if you haven’t got the link trust to cut it – and Google’s algorithms will go to work.
Spamming Google is often counter-productive over the long term.
So:
- Don’t spam your anchor text link titles with the same keyword.
- Don’t spam your ALT Tags or any other tags either.
- Add your keywords intelligently.
- Try and make the site mostly for humans, not just search engines.
On Page is not as simple as a checklist any more of keyword here, keyword there. We are up against lots of smart folk at the Googleplex – and they purposely make this practice difficult.
For those who need a checklist, this is the sort of one that gets me results;
- Do keyword research
- Identify valuable searcher intent opportunities
- Identify the audience & the reason for your page
- Write utilitarian copy – be useful. Use related terms in your content. Use plurals and synonyms. Use words with searcher intent like “buy”, “compare”, “hire” etc. I prefer to get a keyword or related term in almost every paragraph.
- Use emphasis sparingly to emphasise the important points in the page whether they are your keywords are not
- Pick an intelligent Page Title with your keyword in it
- Write an intelligent meta description, repeating it on the page
- Add an image with user-centric ALT attribute text
- Link to related pages on your site within the text
- Link to related pages on other sites
- Your page should have a simple search engine friendly URL
- Keep it simple
- Don’t let ads get in the way
- Share it and pimp it
You can forget about just about everything else.
Subdomains
John Mueller was asked if it is ok to interlink sub-domains, and the answer is yes, usually, because Google will treat subdomains on a website (primarily I think we can presume) as “a single website“:
QUOTE: “So if you have different parts of your website and they’re on different subdomains that’s that’s perfectly fine that’s totally up to you and the way people link across these different subdomains is really up to you I guess one of the tricky aspects there is that we try to figure out what belongs to a website and to treat that more as a single website and sometimes things on separate subdomains are like a single website and sometimes they’re more like separate websites for example on on blogger all of the subdomains are essentially completely separate websites they’re not related to each other on the other hand other websites might have different subdomains and they just use them for different parts of the same thing so maybe for different country versions maybe for different language versions all of that is completely normal.” John Mueller 2017
That is important if Google has a website quality rating score (or multiple scores) for websites.
Subdirectories
Personally I prefer subdirectories rather than subdomains if given the choice, unless it really makes sense to house particular content on a subdomain, rather than the main site (as in the examples John mentions).
Should I Choose a Subfolder or Subdomain?
If you have the choice, I would choose to house content on a subfolder on the main domain. Recent research would still indicate this is the best way to go:
QUOTE: “When you move from Subdomain to Subdirectory, you rank much better, and you get more organic traffic from Google.” Sistrix, 2018
On-Site; Redirect Non-WWW To WWW (or Vice Versa)
QUOTE: “This is a MUST HAVE best practice. Basically, you are redirecting all ranking signals to one canonical version of a URL. It keeps it simple when optimising for Google. Do not mix the two types of www/non-www on-site when linking your internal pages.” Shaun Anderson, Hobo 2020
On-Site; Manage 301 Redirects Accross The Site
QUOTE: “301 Redirects are an incredibly important and often overlooked area of search engine optimisation….. You can use 301 redirects to redirect pages, sub-folders or even entire websites and preserve Google rankings that the old page, sub-folder or website(s) enjoyed. Rather than tell Google via a 404, 410 or some other instruction that a page isn’t here anymore, you can permanently redirect an expired page to a relatively similar page to preserve any link equity that old page might have.” Shaun Anderson, Hobo 2020
On-Site; Have A Useful 404 Error Page
QUOTE: “It is incredibly important to create useful and proper 404 pages. This will help prevent Google recording lots of autogenerated thin pages on your site (both a security risk and a rankings risk).” Shaun Anderson, Hobo 2020
On-Site; Robots.txt File
QUOTE: “A robots.txt file is a file on your webserver used to control bots like Googlebot, Google’s web crawler. You can use it to block Google and Bing from crawling parts of your site.” Shaun Anderson, Hobo 202o
On-Site; Include Enough Satisfying Website Information for the Purpose of the Website
QUOTE: “If a page has one of the following characteristics, the Low rating is usually appropriate…..(if) There is an unsatisfying amount of website information for the purpose of the website.” Google Quality Rater Guide, 2017
Google wants evaluators to find out who owns the website and who is responsible for the content on it.
Your website also needs to meet the legal requirements necessary to comply with laws in your country. It’s easy to just incorporate this required information into your footer.
QUOTE: “Companies…. must include certain regulatory information on their websites and in their email footers before 1st January 2007 or they will breach the Companies Act and risk a fine.” Outlaw, 2006
Here’s what you need to know regarding website and email footers to comply with the Companies Act ;
———————————-
- The Company Name –
Physical geographic address (A PO Box is unlikely to suffice as a geographic address; but a registered office address would – If the business is a company, the registered office address must be included.) - The company’s registration number should be given and, under the Companies Act, the place of registration should be stated
- Email address of the company (It is not sufficient to include a ‘contact us’ form without also providing an email address and geographic address somewhere easily accessible on the site)
- The name of the organisation with which the customer is contracting must be given. This might differ from the trading name. Any such difference should be explained
- If your business has a VAT number, it should be stated even if the website is not being used for e-commerce transactions.
- Prices on the website must be clear and unambiguous. Also, state whether prices are inclusive of tax and delivery costs.
———————————-
The above information does not need to feature on every page, more on a clearly accessible page. However – with Google Quality Raters rating web pages on quality based on Expertise, Authority and Trust (see my recent making high-quality websites post) – ANY signal you can send to an algorithm or human reviewer’s eyes that you are a legitimate business is probably a sensible move at this time (if you have nothing to hide, of course).
Note: If the business is a member of a trade or professional association, membership details, including any registration number, should be provided.
Consider also the Distance Selling Regulations which contain other information requirements for online businesses that sell to consumers (B2C, as opposed to B2B, sales).
On-Page; How To Manage UGC (“User-Generated Content”)
QUOTE – “So it’s not that our systems will look at your site and say oh this was submitted by a user therefore the site owner has like no no control over what’s happening here but rather we look at it and say well this is your website this is what you want to have indexed you kind of stand for the content that you’re providing there so if you’re providing like low quality user-generated content for indexing then we’ll think well this website is about low quality content and spelling errors don’t necessarily mean that it’s low quality but obviously like it can go in all kinds of weird directions with user-generated content…” John Mueller, Google 2019
It’s evident that Google wants forum administrators to work harder on managing user-generated content Googlebot ‘rates’ as part of your page and your site.
In a 2015 hangout John Mueller said to “noindex untrusted post content” and going on says “posts by new posters who haven’t been in the forum before. threads that don’t have any answers. Maybe they’re noindexed by default.“
A very interesting statement was “how much quality content do you have compared to low-quality content“. That indicates google is looking at this ratio. John says to identify “which pages are high-quality, which pages are lower quality so that the pages that do get indexed are really the high-quality ones.“
John mentions looking too at “threads that don’t have any authoritative answers“.
I think that advice is relevant for any site with lots of UGC.
Google wants you to moderate any user-generated content you publish and will rate the page on it. Moderate comments for quality and apply rel=”nofollow” or rel=”ugc” to links in comments.
On-Page; User-Generated Content Is Rated As Part of the Page in Quality Scoring
QUOTE: “when we look at a page, overall, or when a user looks at a page, we see these comments as part of the content design as well. So it is something that kind of all combines to something that users see, that our algorithms see overall as part of the content that you’re publishing.” John Mueller, Google
Bear in mind that:
QUOTE: “As a publisher, you are responsible for ensuring that all user-generated content on your site or app complies with all applicable programme policies.” Google, 2018
Google want user-generated content on your site to be moderated and kept as high quality as the rest of your site.
They explain:
QUOTE: “Since spammy user-generated content can pollute Google search results, we recommend you actively monitor and remove this type of spam from your site.” Google, 2018
and
QUOTE: “One of the difficulties of running a great website that focuses on UGC is keeping the overall quality upright. Without some level of policing and evaluating the content, most sites are overrun by spam and low-quality content. This is less of a technical issue than a general quality one, and in my opinion, not something that’s limited to Google’s algorithms. If you want to create a fantastic experience for everyone who visits, if you focus on content created by users, then you generally need to provide some guidance towards what you consider to be important (and sometimes, strict control when it comes to those who abuse your house rules).”
and
QUOTE: “When I look at the great forums & online communities that I frequent, one thing they have in common is that they (be it the owners or the regulars) have high expectations, and are willing to take action & be vocal when new users don’t meet those expectations.” John Mueller, Google
On-Page; Moderate Comments
Some examples of spammy user-generated content include:
QUOTE: “Comment spam on blogs” Google, 2018
User-generated content (for instance blog comments) are counted as part of the page and these comments are taken into consideration when Google rates the page.
QUOTE: “For this reason there are many ways of securing your application and dis-incentivising spammers.
- Disallow anonymous posting.
- Use CAPTCHAs and other methods to prevent automated comment spamming.
- Turn on comment moderation.
- Use the “nofollow” attribute for links in the comment field.
- Disallow hyperlinks in comments.
- Block comment pages using robots.txt or meta tags.” Google
On-Page; Moderate Forums
QUOTE: “common with forums is low-quality user-generated content. If you have ways of recognizing this kind of content, and blocking it from indexing, it can make it much easier for algorithms to review the overall quality of your website. The same methods can be used to block forum spam from being indexed for your forum. Depending on the forum, there might be different ways of recognizing that automatically, but it’s generally worth finding automated ways to help you keep things clean & high-quality, especially when a site consists of mostly user-generated content.” John Mueller, Google
If you have a forum plugin on your site, moderate:
QUOTE: “Spammy posts on forum threads” Google, 2018
It’s evident that Google wants forum administrators to work harder on managing user-generated content Googlebot ‘rates’ as part of your site.
In a 2015 hangout John Mueller said to “noindex untrusted post content” and going on says “posts by new posters who haven’t been in the forum before. threads that don’t have any answers. Maybe they’re noindexed by default.“
A very interesting statement was “how much quality content do you have compared to low-quality content“. That indicates Google is looking at this ratio. John says to identify “which pages are high-quality, which pages are lower quality so that the pages that do get indexed are really the high-quality ones.“
John mentions looking at “threads that don’t have any authoritative answers“.
I think that advice is relevant for any site with lots of content.
On-Page; Moderate ANY User Generated Content
You are responsible for what you publish.
No matter how you let others post something on your website, you must ensure a high standard:
QUOTE: “One of the difficulties of running a great website that focuses on UGC is keeping the overall quality upright. Without some level of policing and evaluating the content, most sites are overrun by spam and low-quality content. This is less of a technical issue than a general quality one, and in my opinion, not something that’s limited to Google’s algorithms. If you want to create a fantastic experience for everyone who visits, if you focus on content created by users, then you generally need to provide some guidance towards what you consider to be important (and sometimes, strict control when it comes to those who abuse your house rules). When I look at the great forums & online communities that I frequent, one thing they have in common is that they (be it the owners or the regulars) have high expectations, and are willing to take action & be vocal when new users don’t meet those expectations.” John Mueller, Google 2016
and
QUOTE: “… it also includes things like the comments, includes the things like the unique and original content that you’re putting out on your site that is being added through user-generated content, all of that as well. So while I don’t really know exactly what our algorithms are looking at specifically with regards to your website, it’s something where sometimes you go through the articles and say well there is some useful information in this article that you’re sharing here, but there’s just lots of other stuff happening on the bottom of these blog posts. When our algorithms look at these pages, in an aggregated way across the whole page, then that’s something where they might say well, this is a lot of content that is unique to this page, but it’s not really high quality content that we want to promote in a very visible way. That’s something where I could imagine that maybe there’s something you could do, otherwise it’s really tricky I guess to look at specific changes you can do when it comes to our quality algorithms.” John Mueller, Google 2016
and
QUOTE: “Well, I think you need to look at the pages in an overall way, you should look at the pages and say, actually we see this a lot in the forums for example, people will say “my text is unique, you can copy and paste it and it’s unique to my website.” But that doesn’t make this website page a high quality page. So things like the overall design, how it comes across, how it looks like an authority, this information that is in general to webpage, to website, that’s things that all come together. But also things like comments where webmasters might say “this is user generated content, I’m not responsible for what people are posting on my website,” John Mueller, Google 2016
and
QUOTE: “If you have comments on your site, and you just let them run wild, you don’t moderate them, they’re filled with spammers or with people who are kind of just abusing each other for no good reason, then that’s something that might kind of pull down the overall quality of your website where users when they go to those pages might say, well, there’s some good content on top here, but this whole bottom part of the page, this is really trash. I don’t want to be involved with the website that actively encourages this kind of behavior or that actively promotes this kind of content. And that’s something where we might see that on a site level, as well.” John Mueller, Google 2016
and
QUOTE: “When our quality algorithms go to your website, and they see that there’s some good content here on this page, but there’s some really bad or kind of low quality content on the bottom part of the page, then we kind of have to make a judgment call on these pages themselves and say, well, some good, some bad. Is this overwhelmingly bad? Is this overwhelmingly good? Where do we draw the line?” John Mueller, Google 2016
There’s a key insight for many webmasters managing UGC.
Watch out for those who want to use your blog for financial purposes both and terms of adding content to the site and linking to other sites.
QUOTE: “Think about whether or not this is a link that would be on your site if it weren’t for your actions…When it comes to guest blogging it’s a situation where you are placing links on other people’s sites together with this content, so that’s something I kind of shy away from purely from a link building point of view. It can make sense to guest blog on other people’s sites to drive some traffic to your site… but you should use a nofollow.” John Mueller, Google 2013
On-Page; You Must Moderate User-Generated Content If You Display Google Adsense
QUOTE: “Consider where user-generated content might appear on your site or app, and what risks to your site or app’s reputation might occur from malicious user-generated content. Ensure that you mitigate those risks before enabling user-generated content to appear.Set aside some time to regularly review your top pages with user-generated content. Make sure that what you see complies with all our programme policies.” Google Adsense Policies, 2018
and
QUOTE: “If a post hasn’t been reviewed yet and approved, allow it to appear, but disable ad serving on that page. Only enable ad serving when you’re sure that a post complies with our programme policies.” Google Adsense Policies, 2018
and
QUOTE: “And we do that across the whole website to kind of figure out where we see the quality of this website. And that’s something that could definitely be affecting your website overall in the search results. So if you really work to make sure that these comments are really high quality content, that they bring value, engagement into your pages, then that’s fantastic. That’s something that I think you should definitely make it so that search engines can pick that up on.” John Mueller, Google 2016
You can also get a Google manual action penalty for user-generated spam on your site, which can affect parts of the site or the whole site.
QUOTE: “Google has detected user-generated spam on your site. Typically, this kind of spam is found on forum pages, guestbook pages, or in user profiles. As a result, Google has applied a manual spam action to your site.” Google Notice of Manual Action
SEO FAQ
Can you fool Google into ranking your website top?
No.
Google “average rank” principles for your website and commercial keywords associated with it means Google will suppress your rankings (including ignoring keyword stuffing, for instance).
SEO is about ensuring you rank where your website should, first, then work out how to improve its rankings further.
If you are just starting out, don’t think you can fool Google about everything all the time. Google has VERY probably seen your tactics before. So, it’s best to keep your plan simple. GET RELEVANT. GET REPUTABLE. Aim for a healthy, satisfying visitor experience. If you are just starting out – you may as well learn how to do it within Google’s Webmaster Guidelines first. Make a decision, early, if you are going to follow Google’s guidelines, or not, and stick to it. Don’t be caught in the middle with an important project. Do not always follow the herd.
If your aim is to deceive visitors from Google, in any way, Google is not your friend. Google is hardly your friend at any rate – but you don’t want it as your enemy. Google will send you lots of free traffic though if you manage to get to the top of search results, so perhaps they are not all that bad.
Can you ignore Google webmaster guidelines?
No.
A lot of techniques that are in the short term effective at boosting a site’s position in Google are against Google’s guidelines.
For example, many links that may have once promoted you to the top of Google, may, in fact, today be hurting your site and its ability to rank high in Google. Keyword stuffing might be holding your page back. You must be smart, and cautious, when it comes to building links to your site in a manner that Google *hopefully* won’t have too much trouble with, in the FUTURE.
To be listed and rank high in Google and other search engines, you really should consider and mostly abide by search engine rules and official guidelines for inclusion. With experience and a lot of observation, you can learn which rules can be bent, and which tactics are short-term and perhaps, should be avoided.
Because Google will punish you in the future, somehow.
Are rankings guaranteed from SEO?
No.
Don’t expect to rank number 1 in any niche for a competitive keyword phrase without a lot of investment and work. Don’t expect results overnight. Expecting too much too fast might get you in trouble with the Google webspam team.
How much do you pay to get into Google?
You don’t pay anything to get into Google, Yahoo or Bing natural, or free listings. It’s common for the major search engines to find your website pretty quickly by themselves within a few days. This is made so much easier if your cms actually ‘pings’ search engines when you update content (via XML sitemaps or RSS for instance).
Is relevance the primary ranking factor?
Probably, but links matter a lot too.
Google ranks websites (relevancy aside for a moment) by the number and quality of incoming links to a site from other websites (amongst hundreds of other metrics). Generally speaking, a link from a page to another page is viewed in Google “eyes” as a vote for that page the link points to.
The more votes a page gets, the more trusted a page can become, and the higher Google will rank it – in theory. Rankings are HUGELY affected by how much Google ultimately trusts the DOMAIN the page is on. BACKLINKS (links from other websites – trump every other signal.)
Do you need original content to rank in Google?
Yes.
If you are serious about ranking – do so with ORIGINAL COPY. It’s clear – search engines reward good content it hasn’t found before. It indexes it blisteringly fast, for a start (within a second, if your website isn’t penalised). So – make sure each of your pages has enough text content you have written specifically for that page – and you won’t need to jump through hoops to get it ranking.
Google does not want to rank ‘thin’ pages in results – any page you want to rank – should have all the quality signals Google is looking for.
That’s a lot these days!
Do you need to submit your site to search engines?
No.
If you have original, quality content on a site, you also have a chance of generating inbound quality links (IBL). If your content is found on other websites, you will find it hard to get links, and it probably will not rank very well as Google favours diversity in its results. If you have original content of sufficient quality on your site, you can then let authority websites – those with online business authority – know about it, and they might link to you – this is called a quality backlink.
Search engines need to understand that ‘a link is a link’ that can be trusted. Links can be designed to be ignored by search engines with the rel nofollow attribute.
Search engines can also find your site by other websites linking to it. You can also submit your site to search engines directly, but I haven’t submitted any site to a search engine in the last ten years – you probably don’t need to do that. If you have a new site, I would immediately register it with Google Search Console these days.
Google and Bing use a crawler (Googlebot and Bingbot) that spiders the web looking for new links to find. These bots might find a link to your homepage somewhere on the web and then crawl and index the pages of your site if all your pages are linked together. If your website has an XML sitemap, for instance, Google will use that to include that content in its index. An XML sitemap is INCLUSIVE, not EXCLUSIVE. Google will crawl and index every single page on your site – even pages out with an XML sitemap.
Can a brand new site rank well?
Yes, for hyper-relevant terms.
Many think that Google won’t allow new websites to rank well for competitive terms until the web address “ages” and acquires “trust” in Google – I think this depends on the quality of the incoming links. Sometimes your site will rank high for a while then disappears for months. A “honeymoon period” to give you a taste of Google traffic, perhaps, or a period to better gauge your website quality from an actual user perspective.
Google WILL classify your site when it crawls and indexes your site – and this classification can have a DRASTIC effect on your rankings. It’s important for Google to work out WHAT YOUR ULTIMATE INTENT IS – do you want to be classified as a thin affiliate site made ‘just for Google’, a domain holding page or a small business website with a real purpose? Ensure you don’t confuse Google in any way by being explicit with all the signals you can – to show on your website you are a real business, and your INTENT is genuine – and even more important today – FOCUSED ON SATISFYING A VISITOR.
NOTE – If a page exists only to make money from Google’s free traffic – Google calls this spam.
Do you need to provide business contact details on your site?
Yes.
The transparency you provide on your website in text and links about who you are, what you do, and how you’re rated on the web or as a business is one way that Google could use (algorithmically and manually) to ‘rate’ your website.
Note that Google has a HUGE army of quality raters and at some point, they will be on your site if you get a lot of traffic from Google.
How do you rank top for relevant keywords?
To rank for relevant keyword phrase searches, you usually need to have the keyword phrase or highly relevant words on your page (not necessarily all together, but it helps) or in links pointing to your page/site.
Ultimately what you need to do to compete is largely dependent on what the competition for the term you are targeting is doing. You’ll need to at least mirror how hard they are competing if a better opportunity is hard to spot.
As a result of other quality sites linking to your site, the site now has a certain amount of real PageRank that is shared with all the internal pages that make up your website that will in future help provide a signal to where this page ranks in the future.
Do you need links to rank in Google?
Yes, you need to attract links to your site to acquire more PageRank, or Google ‘juice’ – or what we now call domain authority or trust. Google is a link-based search engine – it does not quite understand ‘good’ or ‘quality’ content – but it does understand ‘popular’ content. It can also usually identify poor, or THIN CONTENT – and it penalises your site for that – or – at least – it takes away the traffic you once had with an algorithm change.
Google doesn’t like calling actions the take a ‘penalty’ – it doesn’t look good.
They blame your ranking drops on their engineers getting better at identifying quality content or links, or the inverse – low-quality content and unnatural links. If they do take action your site for paid links – they call this a ‘Manual Action’ and you will get notified about it in Google Search Console if you sign up.
Do you need a lot of links to rank top in Google?
Yes, usually but not always.
Link building is not JUST a numbers game, though. One link from a “trusted authority” site in Google could be all you need to rank high in your niche. Of course, the more “trusted” links you attract, the more Google will trust your site. It is evident you need MULTIPLE trusted links from MULTIPLE trusted websites to get the most from Google.
Try and get links within page text pointing to your site with relevant, or at least, natural looking, keywords in the text link – not, for instance, in blogrolls or site-wide links. Try to ensure the links are not obviously “machine generated” e.g. site-wide links on forums or directories. Get links from pages, that in turn, have a lot of links to them, and you will soon see benefits.
Are internal links valuable?
Yes.
I think the anchor text links in internal navigation is still valuable – but keep it natural. Google needs links to find and help categorise your pages. Don’t underestimate the value of a clever internal link keyword-rich architecture and be sure to understand for instance how many words Google counts in a link, but don’t overdo it. Too many links on a page could be seen as a poor user experience. Avoid lots of hidden links in your template navigation.
Search engines like Google ‘spider’ or ‘crawl’ your entire site by following all the links on your site to new pages, much as a human would click on the links to your pages. Google will crawl and index your pages, and within a few days usually, begin to return your pages in SERPs.
After a while, Google will know about your pages, and keep the ones it deems ‘useful’ – pages with original content, or pages with a lot of links to them. The rest will be de-indexed. Be careful – too many low-quality pages on your site will impact your overall site performance in Google.
Onsite, consider linking to your other pages by linking to pages within main content text. I usually only do this when it is relevant – often, I’ll link to relevant pages when the keyword is in the title elements of both pages. I don’t go in for auto-generating links at all. Google has penalised sites for using particular auto link plugins, for instance, so I avoid them.
Linking to a page with actual key phrases in the link help a great deal in all search engines when you want to feature for specific key terms. For example; “keyword-phrase” as opposed to a naked url or “click here“. Beware, though that Google is punishing manipulative anchor text very aggressively, so be sensible – and stick to brand mentions and plain URL links that build authority with less risk. I do not optimise for grammatically incorrect terms these days (especially with links).
It is important you spread all that real ‘PageRank’ – or link equity – to your sales keyword/phrase rich sales pages, and as much remains to the rest of the site pages, so Google does not ‘demote’ pages into oblivion – or ‘supplemental results’ as we old timers knew them back in the day. Again – this is slightly old school – but it gets me by, even today.
Consider linking to important pages on your site from your home page, and other important pages on your site.
Google does not want to rank ‘thin’ pages in results – any page you want to rank – should have all the things Google is looking for. That’s a lot these days!
Do you need unique content?
Yes.
Google is on record talking about good and bad ratios of quality content to low-quality content. Original content is king and will attract a “natural link growth” – in Google’s opinion.
Ideally, you will have unique pages, with unique page titles and unique page meta descriptions . Google does not seem to use the meta description when ranking your page for specific keyword searches if not relevant and unless you are careful if you might end up just giving spammers free original text for their site and not yours once they scrape your descriptions and put the text in main content on their site. Don’t worry about meta keywords these days as Google and Bing say they either ignore them or use them as spam signals.
Google will take some time to analyse your entire site, examining text content and links.
This process is taking longer and longer these days but is ultimately determined by your domain reputation and real PageRank.
If you have a lot of duplicate low-quality text already found by Googlebot on other websites it knows about; Google will ignore your pages. If your site or page has spammy signals, Google will penalise it, sooner or later.
If you have lots of these pages on your site – Google will ignore most of your website, eventually.
Do you need to keyword stuff copy?
You don’t need to keyword stuff your text to beat the competition.
You optimise a page for more traffic by increasing the frequency of the desired key phrase, related key terms, co-occurring keywords and synonyms in links, page titles and text content. There is no ideal amount of text – no magic keyword density. Keyword stuffing is a tricky business, too, these days.
Hobo prefers to make sure they have as many UNIQUE relevant words on the page that makeup as many relevant long-tail queries as possible.
Can you link out to unrelated sites?
Yes, but why? Especially when linking out to irrelevant sites may well be a low-quality classifier.
If you link out to irrelevant sites, Google may ignore the page, too – but again, it depends on the site in question. Who you link to, or HOW you link to, REALLY DOES MATTER – I expect Google to use your linking practices as a potential means by which to classify your site.
Affiliate sites, for example, don’t do well in Google these days without some good quality backlinks and higher quality copywriting and value add.
Many search engine marketers think who you link out to (and who links to you) helps determine a topical community of sites in any field or a hub of authority. Quite simply, you want to be in that hub, at the centre if possible (however unlikely), but at least in it. I like to think of this one as a good thing to remember in the future as search engines get even better at determining topical relevancy of pages, but I have never actually seen any granular ranking benefit (for the page in question) from linking out.
Google can devalue whole sites, individual pages, template generated links and individual links if Google deems them “unnecessary” and a ‘poor user experience’.
Google knows who links to you, the “quality” of those links, and whom you link to. These – and other factors – help ultimately determine where a page on your site ranks. To make it more confusing – the page that ranks on your site might not be the page you want to rank, or even the page that determines your rankings for this term.
Once Google has worked out your site quality, it seems that the most relevant page on your site Google HAS NO ISSUE with will rank HIGHEST.
Google decides which pages on your site are important or most relevant. You can help Google by linking to your important pages and ensuring at least one page is well optimised amongst the rest of your pages for your desired key phrase.
Focus on RELEVANCE first. Then, focus your marketing efforts and get REPUTABLE. This is the key to ranking ‘legitimately’ in Google.