Get a full review of your your seo strategy

Author’s Note: The following analysis is based on information revealed in the May 2024 leak of Google’s internal documentation. All conclusions about the function, connection, and impact of these attributes (such as contentEffort) are the author’s expert interpretation. Google has not officially confirmed this information, and its ranking systems are complex and subject to change. The Scooby Doo image is naturally a vastly oversimplified version of things, for fun.
This is an in-depth analysis of the contentEffort attribute and its related ecosystem, based on information revealed in the May 2024 leak of Google’s internal Content Warehouse API documentation.
Here are the top ten insights from my research
contentEffortIs a Core Metric: Google uses an attribute calledcontentEffort, described as a “Large Language Model (LLM)-based effort estimation for article pages,” to directly measure the human labour and resources invested in creating content.- A Direct Response to AI Spam: This system is designed as a direct countermeasure to the growth of low-effort, scaled, and AI-generated content that lacks originality and depth. It moves beyond simple heuristics like word count to a qualitative assessment of intellectual and creative investment.
- Site-Wide Quality Is Paramount: A page’s performance is inextricably linked to the overall quality and focus of its host domain. The analysis confirms numerous site-level quality signals, meaning low-quality content on one part of a site can negatively impact the entire domain’s rankings.
- E-E-A-T Is Not a Single Score: The leak suggests there is no single “eeat_score”. Instead, E-E-A-T is an emergent property of dozens of granular attributes like
contentEffort(Expertise),siteAuthority(Authoritativeness), andscamness(Trust) that are calculated and stored separately. - User Clicks Validate Quality: The NavBoost system uses real user click behavior to re-rank results, acting as a crucial feedback loop. Metrics like
goodClicksandbadClicksserve to validate or challenge the initial algorithmic quality assessment, providing the ultimate verdict on whether an experience was satisfying. siteAuthorityIs Confirmed: The documentation confirms the existence of a site-wide authority metric, a concept Google has publicly downplayed for years. This validates that individual pages inherit qualities from their host domain.- Topical Authority Is Measured Algorithmically: Google uses metrics like
siteFocusScoreto quantify a site’s dedication to a specific topic andsiteRadiusto measure how much a page’s content deviates from that central theme. - The “Sandbox” Theory Is Vindicated: The leak provides strong evidence for a “sandbox” for new websites. An attribute called
hostageis explicitly used “to sandbox fresh spam in serving time,” confirming new sites are treated differently at first. - The Helpful Content System (HCS) Is Codified: The leaked attributes provide the technical underpinnings for the HCS. Public principles of the HCS are directly mapped to specific signals like
contentEffort(demonstrating expertise) andsiteFocusScore(maintaining a primary purpose). - Replicability Is a Key Factor: A key function of the
contentEffortscore appears to be assessing the “ease with which a page could be replicated”. Content rich with original data, expert interviews, and custom visuals is difficult to reproduce and therefore signals a higher level of effort.
But there is a lot more!
![]() Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its
Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its contentEffort and E-E-A-T signals.
An Analysis of Google’s Content Effort and Quality Assessment Systems
The number of connections that had to be made to complete my work of inference is immense. Court docs, leaks, exploits, Googler statements, and really great SEOs drop snippets of information all over the place for you to remember. Sometimes I am reading the leak, thinking “Aha, that’s what so-and-so was on about”. One of those so-and-so’s is Cyrus Shephard.
Cyrus Shephard helped shape the industry narrative on EEAT and quality over the last couple of decades, and he has proven to be a very generous “industry leader” – always using his platform to give back to others. I called him that, by the way. I’d vote for him (and probably Lily Ray) for the titles.
This is an example from a year ago, highlighting the very thing my article makes an argument for (and he’s citing his sources).
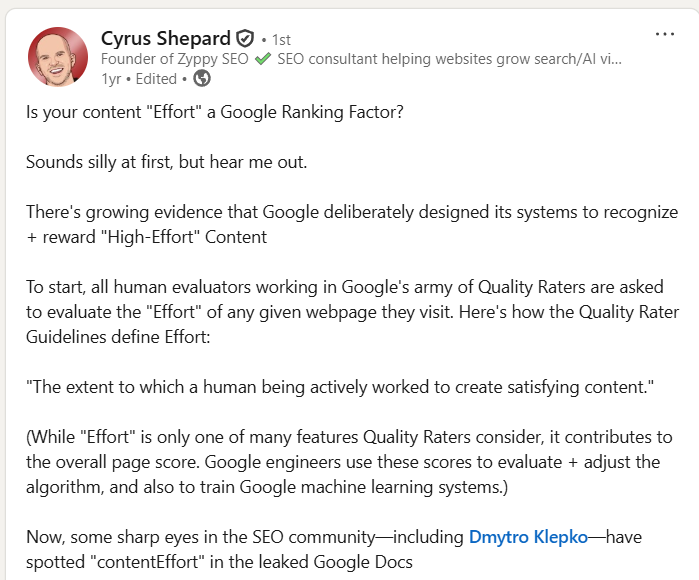
Oh, I don’t think it’s “silly” at all, Cyrus (and Dmytro Klepko).
In fact, the findings indicate a fundamental shift in how Google algorithmically assesses content quality, moving beyond indirect signals to a direct, machine-learning-based estimation of the human labour and resources invested in content creation.
The contentEffort attribute, described as a “Large Language Model (LLM)-based effort estimation for article pages,” emerges as a cornerstone of Google’s modern quality evaluation paradigm.
It might very well perform as a vital technical component of the Helpful Content System (HCS), made famous in Helpful Content Updates, providing a scalable mechanism to operationalise the principles of Experience, Expertise, Authoritativeness, and Trust (E-E-A-T).
This system is designed as a direct countermeasure to the proliferation of low-effort, scaled, and generative AI-produced content that lacks originality and depth.
The analysis reveals that contentEffort does not operate in isolation. It is part of a complex, multi-layered ecosystem of interconnected signals stored across various modules, including PerDocData, CompressedQualitySignals, and QualityNsrNsrData.
These signals create a holistic quality profile for both individual documents and entire domains. Key related attributes include OriginalContentScore, which measures uniqueness; siteAuthority, a site-wide credibility metric; and siteFocusScore, which quantifies topical expertise. This architecture renders page-level optimisation insufficient; a page’s performance is now inextricably linked to the overall quality and topical coherence of its host domain.
The primary strategic imperative for search engine optimisation (SEO) professionals is a fundamental reorientation of content strategy. A demonstrable and measurable commitment to content effort and user-centric value must supersede the long-standing focus on content volume and keyword density. Success in this new paradigm requires a shift from producing content at the lowest possible cost to investing in original research, unique multimedia, and deep expertise that is difficult to replicate and algorithmically recognisable as high-effort.
Watch the overview video:
Deconstructing the contentEffort Attribute: Google’s Algorithmic Measure of Labour
The recent disclosure of Google’s internal API documentation has brought to light numerous attributes used in its ranking systems. Among the most significant is contentEffort, a metric that represents a sophisticated attempt to quantify a previously abstract concept: the amount of work invested in creating a piece of content.
This section provides a granular analysis of the attribute’s technical basis, its function, and the specific on-page elements that potentially contribute to its calculation.
Definition and Technical Basis
The contentEffort attribute is defined within the leaked documentation as an “LLM-based effort estimation for article pages”. Several sources corroborate this, describing it as Google’s attempt to determine how much human effort has gone into creating a piece of content. Its placement is identified as a variable within the broader pageQuality framework, specifically located within the QualityNsrPQData module. This positioning places it at the heart of Google’s core systems for evaluating the intrinsic quality of a webpage.
The description of this attribute as “LLM-based” is a critical technical detail. It signifies a departure from simple, quantitative heuristics like word count or the number of images on a page. Instead, Google employs a Large Language Model, a complex form of artificial intelligence, to perform a qualitative assessment.
This model has potentially been trained on a vast corpus of web documents, learning to recognise the nuanced patterns, structural complexities, and semantic features that differentiate high-effort, human-crafted content from low-effort, templated, or purely machine-generated text. This allows the system to move beyond superficial metrics and evaluate the intellectual rigour and creative investment in a document.
This fundamentally alters the economic model of content marketing. Historically, “quality” in SEO has been an abstract concept, often inferred through indirect proxy signals such as the quantity and quality of backlinks or user engagement metrics.
The contentEffort attribute, however, represents a direct attempt to algorithmically quantify the labour and resources invested in a piece of content. Google is no longer just inferring quality; it is measuring a primary input of quality—human effort. Consequently, content strategies built on producing content at the lowest possible cost, such as those relying on scaled AI generation or simple article spinning, are now in direct opposition to a measurable ranking attribute. The return on investment (ROI) calculation for content must now factor in the “demonstrable effort” required to achieve a high score, rewarding investment in substantive content creation.
Key Factors Influencing the contentEffort Score
The mechanism by which the LLM calculates the contentEffort score is not explicitly detailed, but analysis of the leaked documentation and related expert commentary points to several key contributing factors. These factors collectively signal to the algorithm that significant resources and expertise were dedicated to the content’s creation.
- Multimedia Integration: The inclusion of unique images, videos, and embedded tools is explicitly cited as a method to boost the
contentEffortscore. The emphasis on “unique” is paramount. It suggests the system can differentiate between generic stock imagery, which requires little effort to implement, and original photography, custom-designed infographics, or explanatory videos, which represent a substantial investment of time and resources. - Data and Originality: The presence of unique data, in-depth information, and original research are identified as crucial contributors. This directly rewards content that introduces new information to the web corpus, as opposed to merely summarising or rephrasing existing sources. A page that presents the results of a proprietary survey, for instance, would signal a much higher level of effort than one that aggregates statistics from other websites.
- Structure and Complexity: The LLM potentially analyses the structural and linguistic characteristics of the content. Factors such as a logical and hierarchical structure (indicated by the proper use of headings and bullet points), the complexity of the language and vocabulary used, and the inclusion of citations to authoritative sources are also probable inputs. These elements serve as proxies for intellectual rigour and thorough research.
- Replicability Assessment: A key function of the
contentEffortscore appears to be an assessment of the “ease with which a page could be replicated”. Content that is formulaic, generic, or lacks unique insights can be easily reproduced by competitors or AI models. Conversely, content rich with original data, expert interviews, and custom visuals is difficult and costly to replicate. A highcontentEffortscore, therefore, signals that the content is a valuable, non-commoditised asset, making it inherently more worthy of a high ranking.
The contentEffort attribute appears to be the technical lynchpin of Google’s “Helpful Content System” (HCS). The HCS was publicly introduced to reward content that is “created for people” and penalise content created “primarily for search engines”. The official documentation for the HCS uses qualitative, human-centric questions to define its goals. For instance, it asks creators to self-assess: “Does your content clearly demonstrate first-hand expertise and a depth of knowledge (for example, from having actually used a product or service, or visiting a place)?”
This focus on depth and originality is reinforced by further questions, such as, “Does the content provide original information, reporting, research, or analysis?” and “Does the content provide a substantial, complete, or comprehensive description of the topic?” The contentEffort attribute provides the precise technical mechanism to answer these questions algorithmically and at the scale of the entire web. An LLM can assess “depth of knowledge” and “original research” by analysing linguistic complexity and the presence of unique data. It can also identify patterns of “extensive automation”—which the guidelines warn against—by comparing a document’s features against its training data of low-effort text. Therefore, contentEffort is not merely another ranking factor; it is potentially the core classifier for the HCS. A low contentEffort score serves as a strong signal that content is not “people-first” and may trigger the site-wide demotion that is characteristic of the HCS.
The Algorithmic Ecosystem of Content Quality
The contentEffort attribute, while significant, does not operate in a vacuum. The leaked documentation reveals that it is a single component within a vast and interconnected ecosystem of signals that Google uses to form a holistic judgement of content and site quality. This multi-layered system evaluates documents from numerous angles, including originality, trustworthiness, site-level authority, and user validation. Understanding this broader context is critical, as the interplay between these signals determines the ultimate ranking potential of a page.
Document-Level Quality Signals
Alongside contentEffort, Google employs a suite of other attributes at the individual document level to build a granular quality profile. These signals serve to both reward positive attributes and penalise negative ones.
- Originality (
OriginalContentScore): This attribute is designed to score the uniqueness of a page’s content. The documentation specifically notes that this score is present for pages with “little content,” such as product descriptions, category pages, or local business listings. It is stored as a 7-bit integer (a value from 0 to 127) but is decoded to a wider range of 0 to 512, allowing for more granular scoring. This attribute acts as a crucial complement tocontentEffort. WhilecontentEffortassesses the depth and labour invested in long-form content,OriginalContentScoretargets the problem of thin, duplicative, or templated content on pages where extensive text is not the primary goal. It provides a mechanism to reward a uniquely written product description over a manufacturer’s boilerplate text, for example. - URL-Level Content Quality Predictors: The
QualityNsrPQDatamodule, which housescontentEffort, also contains a variety of other URL-level quality scores. These includechard,tofu,keto, andrhubarb. While the exact function of each is not fully detailed, they represent a suite of different machine-learning models designed to analyse various facets of a page’s content. The existence of multiple, distinct URL-level quality predictors indicates that Google’s assessment is not based on a single model but is a composite judgement formed from several specialised classifiers. - Spam and Deception Signals: The system is fortified with numerous attributes designed to identify and penalise low-quality, manipulative, or harmful content. This defensive layer is essential for maintaining the integrity of the search results. Key signals include:
scamness: A metric that measures the probability that a page is a scam or is designed to deceive users.uacSpamScoreandspamtokensContentScore: These attributes specifically measure spam within user-generated content (UGC), indicating that Google evaluates this content type with its own dedicated models.spamMuppetSignals: A set of signals used to identify hacked sites, which are often injected with spammy content or links.GibberishScore: A straightforward classifier that flags content that is nonsensical or algorithmically generated without coherence.copycatScoreandspamScore: Located within theBlogPerDocDatamodule, these attributes potentially signal that a document’s content has been copied from another source or is otherwise spammy, showing a specific focus on the quality of blog and post-style content.
- Page Typology (
commercialScore): Before evaluating quality, the system first classifies a page’s purpose. ThecommercialScoreattribute is a key page typology signal that identifies whether a page’s primary intent is commercial (designed to sell something) or informational. A score greater than 0 indicates a commercial page. This allows Google to assess the page against the user expectations for that specific intent. The strategic implication is that pages with a clear, singular focus are potentially to perform better than pages that attempt to serve both commercial and informational intents simultaneously. - Page-Level Link Metrics: In addition to site-wide link signals, the system also measures link attributes at the individual page level. The
QualityNsrPQDatamodule containslinkIncomingandlinkOutgoing, which track the links pointing to and from a specific URL. This provides a more granular view of a page’s link profile, complementing the broadersiteAuthorityscore.
This sophisticated, multi-pronged approach to identifying negative quality attributes forms the algorithmic foundation for the “Trust” pillar of Google’s E-E-A-T framework, which will be discussed in a later section.
Site-Level Quality Signals
![]() Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its
Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its contentEffort and E-E-A-T signals.
One of the most profound revelations from the leak is the confirmation of numerous site-level quality signals. These metrics codify the long-held SEO principle that the context of the domain is as important as the content of the page. A page’s quality is not assessed in isolation but is heavily influenced by the reputation and focus of the site on which it is published.
- Site Authority (
siteAuthority): The documentation confirms the existence of a site-wide authority metric, a concept Google representatives have publicly downplayed or denied for years. This attribute is located in theCompressedQualitySignalsmodule, alongside other critical quality metrics. This finding is monumental for SEO strategy. It validates the idea that individual pages inherit qualities from their host domain. A page with a highcontentEffortscore published on a domain with a lowsiteAuthorityscore will potentially be suppressed relative to a similar page on a high-authority domain. The documentation also notes that the authority of a site’s homepage has a particularly strong impact on the entire site’s authority, reinforcing the importance of a strong, well-linked homepage. This is further supported by the presence of attributes likesitePr, which potentially refers to the site-level PageRank, as well assiteLinkInandsiteLinkOut, which measure the average incoming and outgoing links for the site. These metrics suggest a comprehensive, link-based evaluation of a domain’s authority. - Topical Authority (
siteFocusScoreandsiteRadius): The system includes two key metrics to algorithmically measure a site’s topical expertise.siteFocusScorequantifies how dedicated a site is to a specific topic, whilesiteRadiusmeasures how much an individual page’s content deviates from that site’s central theme. This provides a mathematical framework for evaluating topical relevance. Creating content that strays too far from a site’s established core expertise (resulting in a highsiteRadius) can be detrimental to its ranking potential. This reinforces the strategic value of developing deep niche expertise and employing content clustering strategies, such as the hub-and-spoke model, to signal a high degree of topical authority. - Overall Site Quality and Type Classifiers: The system also includes metrics to assess the general quality and user-friendliness of a site as a whole. In addition to the previously mentioned signals, the system uses a variety of other classifiers to build a detailed site profile:
-
- The
lowQualityparameter can be used to flag entire sites that are deemed to be of low quality. clutterScoreappears to penalise sites that have a large number of distracting or annoying resources, such as aggressive ads, pop-ups, and interstitials that obscure the main content. This aligns with the Search Quality Rater Guidelines, which instruct human raters to assign a low rating if the main content is “deliberately obstructed or obscured” by ads.siteQualityStddevmeasures the standard deviation of quality signals across an entire site. The existence of this metric implies that Google values consistency; a site with uniformly high-quality pages is potentially to be scored more favourably than a site with a mix of excellent and very poor pages.tofu: A site-level quality predictor based on the site’s content.smallPersonalSite: A specific score designed to promote small personal blogs, indicating that Google can classify and apply unique ranking adjustments to different types of websites. From the leak: smallPersonalSite: QUOTE: – “Score of small personal site promotion go/promoting-personal-blogs-v1″.spambrainLavcScore: A site-level score from Google’s SpamBrain AI system, used to identify spam
- The
- Specialised Authority and Whitelisting: The documentation also reveals that Google applies highly specific, categorical authority signals. This includes boolean flags like
isCovidLocalAuthorityandisElectionAuthority, which were potentially used to whitelist or elevate specific domains during critical events to ensure the visibility of trustworthy information. AlocalityScorealso exists, which forms a component of a site’s local authority signal, demonstrating a granular approach to authority based on geographic relevance. - The “Sandbox” for New Sites: The leak provides strong evidence for the long-debated “sandbox” theory, which posits that new websites are temporarily suppressed in search rankings. The documentation references a
hostAgeattribute that is explicitly used “to sandbox fresh spam in serving time”. This confirms that new sites are treated differently by the algorithm, at least initially, potentially as a measure to evaluate their trustworthiness before allowing them to rank prominently.
The legacy of Google’s Panda algorithm update, which targeted low-quality sites, is evident in these attributes.
The principle that “low quality content on part of a site can impact a site’s ranking as a whole” is now clearly codified in these measurable, site-level metrics. This provides strong evidence for the strategic validity of content pruning and quality audits, where removing or improving low-performing pages can lift the performance of the entire domain.
Mobile-Specific Quality Signals
The system’s focus on user experience is particularly evident in its evaluation of mobile pages. The leak confirms that mobile-friendliness is a critical factor and reveals that Google uses specific modules and signals to evaluate the mobile experience.
- Dedicated Mobile Data (
SmartphonePerDocData): The existence of this module confirms that Google stores specific, additional metadata for pages that are optimised for smartphones. This indicates that the mobile version of a page is analysed with its own set of data points, reinforcing the strategic importance of a mobile-first approach. - Penalties for Intrusive Interstitials: The documentation explicitly mentions penalties for violating mobile interstitial policies. Due to the limited screen space on mobile devices, full-page ads that obscure content are considered a particularly poor user experience. Google’s own developer guidelines recommend using less intrusive formats, such as banners, to avoid frustrating users and potentially harming search performance.
- Hidden Content on Mobile: The documentation also suggests that content “hidden” on mobile devices, for instance within collapsed accordions or tabs, may not be indexed or could be weighed less heavily than content that is fully visible upon loading.
The Role of User Interaction and Freshness Signals
The quality signals derived from content analysis are not the final word. Google’s systems create a crucial feedback loop by incorporating signals from real user behaviour and content timeliness. These signals serve to validate or challenge the initial algorithmic quality assessment.
- Click Signals (NavBoost): The leak provides definitive confirmation of the importance of click data in ranking. The NavBoost system re-ranks results based on user click behaviour, using a variety of metrics stored in a module named
Craps. These include attributes likegoodClicks(potentially indicating a user clicked a result and did not immediately return to the search page, signifying a satisfied search),badClicks(indicating a quick return, or “pogo-sticking”), andlastLongestClicks(identifying the result a user spent the most time on before ending their search session). - Chrome Data: The attribute
chromeInTotalreveals that Google tracks site-level views and visits from its Chrome browser. This gives Google access to a massive stream of user interaction data beyond the search results page itself, potentially influencing signals likesiteAuthority. - Freshness Signals: The system uses multiple attributes to determine the timeliness and relevance of content. These include
bylineDate(the date explicitly stated on the page),syntacticDate(a date found in the URL or title), andsemanticDate(a date inferred from the content itself). The documentation also indicates that irregularly updated content is assigned the lowest storage priority, making it less likely to be served for queries that demand fresh information.
These signals form a critical verification layer. contentEffort and OriginalContentScore represent Google’s prediction of a page’s quality and usefulness. The click data from NavBoost and Chrome represents the real-world validation of that prediction by users. A page that scores highly on effort but fails to satisfy user intent will generate badClicks and will ultimately be demoted. Conversely, a page that strongly satisfies users may see its ranking improve, even if its static quality signals are not perfect.
Key Content Quality Attributes from the Google API Leak
The following table consolidates the most critical content-related attributes revealed in the documentation, translating their technical function into a direct strategic implication for SEO practitioners. This provides a unified reference for understanding the multi-faceted nature of Google’s quality assessment.
| Attribute Name | Associated Module(s) | Likely Function | Strategic Implication for SEO |
contentEffort |
QualityNsrPQData, pageQuality |
LLM-based estimation of human effort in content creation. | Prioritise depth, unique data, multimedia, and original research over content volume. A direct counter to low-effort AI content. |
OriginalContentScore |
PerDocData |
Measures the uniqueness of content, especially for shorter pages. | Ensure product/category/local pages have unique, non-template text. Avoid internal and external duplication. |
siteAuthority |
CompressedQualitySignals |
A site-wide authority score, potentially influenced by links and brand signals. | Acknowledge that domain-level trust is a factor. Page quality is contextualised by site quality. |
siteFocusScore |
QualityNsrNsrData |
Measures the topical focus of the entire site. | Develop deep expertise in a specific niche. Avoid topical dilution. Prune off-topic content. |
siteRadius |
QualityNsrNsrData |
Measures how far a page’s topic deviates from the site’s core focus. | Ensure new content is thematically aligned with the site’s established expertise. |
lowQuality |
CompressedQualitySignals |
A flag for low-quality content/sites. | Regularly audit and prune or improve thin, outdated, or unhelpful content to avoid site-wide suppression. |
scamness |
CompressedQualitySignals |
A score indicating the likelihood a page is deceptive or a scam. | Ensure transparency, avoid deceptive practices, and maintain a trustworthy user experience. |
isAuthor |
(Various) | Boolean function to identify if an entity is the author of a page. | Establish clear authorship for content. Build the author’s entity profile and expertise. |
goodClicks / badClicks |
Craps (related to NavBoost) |
Measures user satisfaction based on click behaviour (dwell time, pogo-sticking). | Optimise for user intent and experience to generate long clicks and reduce bounces back to the SERP. |
chromeInTotal |
QualityNsrNsrData |
Tracks total site views from the Chrome browser. | A strong brand that drives direct and repeat traffic (captured via Chrome) contributes to site authority. |
Deeper Implications of the Quality Ecosystem
The architecture of this quality assessment system reveals several deeper truths about how Google Search operates. The sheer number and diversity of quality signals, spread across multiple modules like PerDocData, CompressedQualitySignals, and QualityNsrNsrData, indicates that the system is designed for holistic, multi-factorial assessment. These signals cover document-level attributes (contentEffort), site-level attributes (siteAuthority), topicality (siteFocusScore), and user validation (goodClicks). This structure implies that no single factor is a “silver bullet.” A page cannot succeed with a high contentEffort score alone if the siteAuthority is low, the topic is off-focus (high siteRadius), and users find it unhelpful (generating badClicks). This makes single-factor optimisation obsolete. SEO strategy must evolve from a checklist of individual optimisations to a comprehensive approach that considers the profound interplay between content quality, site architecture, topical authority, and user experience. The leak confirms that Google’s evaluation is deeply contextual.
Furthermore, the documentation makes a clear algorithmic distinction between general “Content”, “User-Generated Content (UGC)”, and “Blog/Microblog Content”. The presence of separate modules and attributes for general content quality (contentEffort, lowQuality), UGC quality (ugcScore, ugcDiscussionEffortScore), and blog-specific quality (docQualityScore, userQualityScore, spamScore in the BlogPerDocData module) indicates that Google evaluates these different content types using distinct models and criteria. This places the onus on website owners to manage the quality of all content types on their site, as each is assessed with its own specialised set of signals.
contentEffort as an Algorithmic Proxy for E-E-A-T

The leaked technical data provides a rare opportunity to bridge the gap between Google’s internal engineering and its public-facing quality framework, known as E-E-A-T (Experience, Expertise, Authoritativeness, and Trust). The analysis demonstrates that specific attributes from the leak serve as quantifiable, scalable proxies for these abstract concepts, which are defined in detail within Google’s Search Quality Rater Guidelines (SQRG).
The Search Quality Rater Guidelines as a Blueprint for Algorithmic Features
The SQRG is a comprehensive manual provided to thousands of human raters who are tasked with evaluating the quality of Google’s search results. The feedback from these raters does not directly alter the ranking of a specific page but is used as a “ground truth” dataset to train, test, and refine Google’s ranking algorithms. Therefore, the principles and criteria laid out in the SQRG represent the desired outcome that Google’s machine learning models are engineered to replicate at scale. The leaked attributes can be seen as the specific features these models use to make their predictions, effectively translating the human-centric guidelines of the SQRG into machine-readable signals. The leak offers a direct view into the engineering interpretation of these philosophical guidelines, transforming E-E-A-T from an abstract ideal into a set of measurable, algorithmic components.
Mapping Leaked Attributes to E-E-A-T Pillars
By cross-referencing the leaked attributes with the principles of the SQRG, it is possible to map the technical signals to the four pillars of E-E-A-T.
- Experience & Expertise (The “E-E” in E-E-A-T): This dimension relates to the skill and first-hand knowledge of the content creator.
contentEffort: This attribute directly maps to the SQRG’s emphasis on content created with “effort, originality, and talent”. A highcontentEffortscore, derived from factors like depth, unique data, and complexity, serves as a strong algorithmic signal of the expertise and research invested in the content.OriginalContentScore: This aligns with the SQRG’s focus on unique, original content that provides value beyond what is already available on the web. Originality is a hallmark of true expertise.- Author and Publisher Entities: The leak confirms that Google’s systems identify authors as distinct entities. The
isAuthorboolean attribute indicates whether an entity is the creator of a page. This corresponds directly with the SQRG’s directive to assess the expertise of the content creator. However, the analysis suggests Google evaluates two separate questions: “Who wrote this?” (the author) and “Who is publishing this?” (the publisher). This creates a two-tiered system of credibility, where both the individual author’s reputation and the publisher’s overall trustworthiness are assessed. This is further substantiated by the existence of separatedocQualityScoreanduserQualityScoreattributes within theBlogPerDocDatamodule, confirming that the system evaluates both the content and the creator’s quality independently. YoutubeCommentsSentimentSentimentEntitySentimentAnnotation: This novel attribute, which analyses the sentiment of YouTube comments related to a specific entity, provides an unconventional but powerful proxy for public perception of expertise. It mirrors the SQRG’s advice for raters to look for external reputation signals, including user reviews and comments.
- Authoritativeness (The “A” in E-E-A-T): This dimension concerns the overall reputation and influence of the website or creator within its field.
siteAuthority: This is the most direct algorithmic proxy for authoritativeness at the domain level. It is potentially a composite score influenced by traditional authority signals such as the site’s backlink profile, specifically its PageRank (sitePr), brand mentions, and the quality of its inbound links.authorityPromotion: This attribute, found within theCompressedQualitySignalsmodule, explicitly suggests that a high authority score can directly lead to a ranking boost, confirming its importance in the ranking process.- Link Quality Signals: The leak reinforces that link quality is determined by the referring site’s authority and the traffic it receives. Furthermore, it indicates that clicks on those links are also measured, adding a user validation component to the concept of link equity. This aligns with the core PageRank concept of authority being transferred through links from reputable sources.
- Trustworthiness (The “T” in E-E-A-T): This dimension focuses on the safety, reliability, and transparency of the content and the site.
scamness,spamMuppetSignals,GibberishScore: These are all powerful negative trust signals. They directly map to the SQRG’s definitions of “Lowest Quality Pages,” which are characterised as deceptive, harmful, or nonsensical.badSslCertificate: The presence of a bad SSL certificate is a clear technical trust signal that is fed into theCompositeDoc, which aggregates information about a document.- YMYL Signals (
ymylNewsV2Score,healthScore): The existence of specific quality scores for “Your Money or Your Life” (YMYL) topics demonstrates that the E-E-A-T criteria are applied with significantly greater weight for sensitive content that can impact a person’s well-being. This is in perfect alignment with the heightened scrutiny for YMYL topics outlined in the SQRG. - Consensus Scoring: Recent analysis has revealed that Google’s systems can count the number of passages in a piece of content that agree with, contradict, or are neutral towards the “general consensus” on a topic. This provides a powerful mechanism for evaluating the trustworthiness of content, particularly for factual queries, and serves as an algorithmic defence against misinformation.
- Page Purpose (
commercialScore): ThecommercialScoreattribute also contributes to Trust. It allows the system to identify a page’s primary purpose. A page that is clearly commercial but presents itself as an unbiased informational resource could be flagged as deceptive, directly violating the principles of trustworthiness outlined in the SQRG.
Deeper Implications for the E-E-A-T Framework
The mapping of these attributes reveals a more nuanced understanding of how E-E-A-T is implemented. The SEO community’s search for a single, unified “E-E-A-T score” appears to be misguided. Nowhere in the leaked documentation is there a single attribute named eeat_score. Instead, the evidence points to dozens of granular attributes distributed across multiple modules (CompressedQualitySignals, PerDocData, QualityNsrNsrData), each measuring a small, discrete component of the broader E-E-A-T framework. contentEffort measures a facet of expertise. siteAuthority measures authoritativeness. scamness measures a lack of trust. These signals are calculated and stored separately. This suggests that E-E-A-T is not a monolithic score but rather an emergent property of a distributed system. Improving a site’s “E-E-A-T” therefore requires a multi-faceted strategy that simultaneously addresses authorship, site reputation, content depth, and technical trust factors, as each is measured and weighted by a different part of the algorithm.
Furthermore, the system is designed for nuanced adjustments, not just binary judgements. The leak contains attributes like authorityPromotion, productReviewPPromoteSite (for promoting sites with good product reviews), productReviewPDemoteSite (for demoting sites with poor product reviews), and navDemotion. It also refers to “Twiddlers,” which are re-ranking functions that can make final adjustments to scores and rankings just before the search results are served to the user. This indicates a system that is not simply classifying pages as “good” or “bad.” Instead, it applies a spectrum of boosts and demotions based on a complex profile of quality signals. A page is not just “E-E-A-T compliant” or not; it receives a dynamic set of adjustments. For example, a page might have a high contentEffort score (earning a boost) but be on a site with a poor product review profile (triggering a productReviewPDemoteSite demotion), resulting in a net neutral or even negative outcome. This complexity helps explain the often-volatile nature of search rankings, as pages are subject to multiple, and sometimes conflicting, re-ranking functions like the FreshnessTwiddler, which specifically re-ranks documents based on freshness.
Strategic Implications in the Age of AI and the Helpful Content System
The technical findings from the leak must be placed within the broader strategic context of modern SEO, which is currently defined by two dominant forces: the rise of generative artificial intelligence and Google’s response in the form of the Helpful Content System (HCS). The contentEffort attribute and its related signals are not merely technical curiosities; they represent the core architectural components of Google’s strategy for navigating this new information landscape.
contentEffort as the Primary Defence Against Scaled Content Abuse
![]() Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its
Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its contentEffort and E-E-A-T signals.
The proliferation of sophisticated generative AI models has enabled the creation of massive volumes of textually unique but substantively low-value content at a near-zero marginal cost. This presents a fundamental challenge to search engines, as traditional spam detection signals, such as duplicate text analysis, are largely ineffective against this new wave of content.
The contentEffort score, by leveraging an LLM to assess qualitative aspects like depth, the inclusion of unique data, and linguistic complexity, is Google’s direct and robust answer to this challenge. It is an algorithmic tool designed specifically to differentiate between content that merely fills a page with plausible-sounding text and content that provides genuine, hard-to-replicate value derived from human experience and research.
This algorithmic approach aligns perfectly with recent updates to the Search Quality Rater Guidelines. The SQRG now explicitly instructs human raters to assign the “Lowest” quality rating to content created with “little to no effort, little to no originality, and little to no added value,” and it specifically includes AI-generated content as a potential example of this. The contentEffort attribute is the scalable, automated mechanism for enforcing this guideline across the entire web.
How the Leaked Signals Codify the Helpful Content System
The Helpful Content System (HCS) was introduced by Google as a major ranking system designed to elevate “people-first” content and demote content created primarily for search engine manipulation. The leaked signals provide a clear view of the technical underpinnings that power this system, translating its public-facing principles into concrete, measurable attributes.
- HCS Principle: Provide a satisfying user experience.
- Public Guideline: The HCS documentation states the system aims to “better reward content where visitors feel they’ve had a satisfying experience” and encourages creators to ask, “After reading your content, will someone leave feeling they’ve learned enough about a topic to help achieve their goal?”
- Leaked Signal: The entire NavBoost system, with its reliance on metrics like
goodClicksandlastLongestClicks, is the ultimate arbiter of a “satisfying experience.” It directly tracks whether real users found the content helpful enough to end their search journey, providing an unvarnished verdict that codifies this “people-first” principle.
- HCS Principle: Demonstrate expertise, depth, and originality.
- Public Guideline: The guidelines famously ask creators to self-assess: “Does your content clearly demonstrate first-hand expertise and a depth of knowledge…?” This is further supported by related questions, such as, “Does the content provide original information, reporting, research, or analysis?”
- Leaked Signal:
contentEffortis the primary signal for this criterion. A high-effort piece of content, characterised by unique data, expert citations, and complex analysis, algorithmically demonstrates a depth of knowledge and originality that low-effort content cannot replicate.
- HCS Principle: Maintain a primary purpose or focus.
- Public Guideline: The guidelines ask website owners a direct question: “Does your site have a primary purpose or focus?”
- Leaked Signal:
siteFocusScoreandsiteRadiusdirectly and mathematically measure this.siteFocusScorequantifies the site’s topical dedication, whilesiteRadiusmeasures an individual page’s deviation from that core theme, algorithmically enforcing this principle.
- HCS Principle: Avoid creating content for search engines first.
- Public Guideline: The system is designed to penalise content that “seems to have been created primarily for search engines, rather than humans.” The guidelines warn against tactics like “producing lots of content on different topics in hopes that some of it might perform well in search results” or “writing to a particular word count because you’ve heard or read that Google has a preferred word count.”
- Leaked Signal: The combination of
siteFocusScore(penalising topical diffusion) andcontentEffort(which assesses qualitative depth, not just word count) directly targets these manipulative tactics. These attributes are designed to differentiate between content created to provide value and content created to simply “check a box” for an algorithm.
Deeper Implications for SEO Strategy
The relationship between these leaked signals and the HCS has profound implications for SEO strategy. Google has publicly stated that the HCS applies a site-wide signal, meaning that the assessment is not made on a page-by-page basis. The leak reveals numerous site-wide quality metrics, including siteAuthority, siteFocusScore, and siteQualityStddev, which provide the infrastructure for such a system.
It is logical to conclude that the HCS classifier works by aggregating document-level signals like contentEffort, OriginalContentScore, and lowQuality across an entire site.
If a critical mass of pages on a domain falls below a certain quality threshold—for example, if the site has a low average contentEffort score—the entire site is potentially to be flagged by the HCS, and all of its content may be suppressed in the search results. This means that publishing even a single piece of low-effort content is no longer a neutral act; it actively contributes to a negative site-wide quality score that can damage the ranking potential of the entire domain. Consequently, content strategy must now incorporate rigorous quality control and systematic content pruning as a defensive necessity.
This leads to a new competitive landscape for SEO. The introduction of the contentEffort score effectively creates an arms race of quality. To rank, content must demonstrate more algorithmic “effort” than the competition. Generative AI is the primary tool for producing content with minimal effort, making it the main target of this metric. However, this does not mean that AI is to be avoided entirely. Instead, its role must be re-envisioned.
AI can be used to enhance human effort rather than replace it. For example, using AI to perform complex data analysis and generate unique visualisations for an article would almost certainly increase its contentEffort score. Conversely, using AI to simply rewrite a competitor’s article would result in a very low score. The winning strategy will not be to shun AI, but to master the art of human-AI collaboration. SEO professionals must become adept at using AI as a force multiplier for human creativity, research, and analysis to produce content that is demonstrably and measurably high-effort.
Actionable Framework for Optimising for Content Effort and Quality Signals
The analysis of the contentEffort attribute and its surrounding ecosystem necessitates a fundamental shift in SEO and content strategy. This section translates the technical findings from the leak into a practical, strategic framework. It provides evidence-based recommendations for content strategists, creators, and SEO professionals to align their work with Google’s evolving quality assessment systems.
Redefining the Content Creation Workflow
The traditional content workflow, often starting with keyword research and aiming for volume, is no longer sufficient. A new, “effort-first” model is required to succeed in an environment where the investment in content creation is algorithmically measured.
- From “Keyword-First” to “Effort-First”: The primary question guiding content planning must evolve. Instead of asking, “What keyword are we targeting?”, the central question should be, “How can we demonstrate maximum, unique, and undeniable effort on this topic?”. Keyword relevance remains essential, but it becomes a component of a larger strategy focused on creating a demonstrably superior resource.
- The Pre-Production Brief: Content briefs must be expanded to include specific requirements that directly map to the factors influencing the
contentEffortscore. Every brief should mandate:- Unique Data/Research: What new information, data, or perspective will this piece contribute to the existing conversation? This forces originality from the outset.
- Expert Sources: Which credible experts will be cited, quoted, or interviewed? This builds in signals of expertise and authoritativeness.
- Custom Multimedia Assets: What original images, custom-designed graphics, explanatory videos, or interactive elements will be created specifically for this piece? This moves beyond using generic stock assets.
- Structural Depth: How will the content be organised with a clear hierarchy of headings and subheadings to demonstrate comprehensive coverage of the topic?
Practical Strategies to Increase contentEffort and Related Scores
To align with the contentEffort metric, content must be imbued with signals of significant labour and expertise. The following strategies are designed to achieve this.
- Invest in Original Research: This is the most defensible method for creating high-effort content. Conducting proprietary surveys, analysing internal data to reveal industry trends, or synthesising public datasets in novel ways creates a resource that cannot be easily replicated.
- Prioritise Custom Multimedia: A strict policy of replacing all stock photos with original photography, custom illustrations, data visualisations, or short explanatory videos should be implemented. Embedding interactive tools, such as calculators or configurators, also signals a high degree of effort and user value.
- Establish and Showcase Authorship: Every piece of content should have a clearly identified author. Create detailed author biography pages that list credentials, experience, and links to their work on other reputable sites and social media profiles. Utilise author schema markup to communicate this information to search engines. Ensure the author is a credible entity with demonstrable expertise in the topic at hand.
- Embrace Content Depth and Structure: Content should be structured with a clear and logical hierarchy of headings (H1, H2, H3, etc.). It should aim to cover a topic and its related subtopics comprehensively, anticipating and answering subsequent user questions. The goal is to go beyond surface-level summarisation and provide deep analysis, actionable advice, and a satisfying user experience.
- Implement Systematic Content Audits: Regularly audit the entire site to identify pages with low
contentEffort, lowOriginalContentScore, or other negative quality signals. Underperforming or outdated content should be systematically pruned (removed and redirected), consolidated with other pages, or substantially rewritten to meet current quality standards. This process is crucial for improving the site-wide average quality score and avoiding penalties from systems like the HCS.
Aligning with Topical and Site-Level Authority
Page-level effort must be supported by domain-level strength. A holistic strategy addresses the site as a whole to maximise the impact of individual content pieces.
- Develop a Core Topical Focus: Clearly define the site’s primary area of expertise. Build content clusters, consisting of comprehensive pillar pages and detailed “spoke” articles, around this core topic. This strategy is designed to maximise the site’s
siteFocusScoreand signal deep expertise to Google. - Engage in Strategic Pruning: Be rigorous in removing or no-indexing content that falls far outside the site’s core topic. Pages with a high
siteRadiusdilute the site’s perceived expertise and can negatively impact the entire domain’s topical authority. - Build Brand and Authority Signals: Focus on earning high-quality, editorially given links from relevant, authoritative sites that drive real referral traffic. Beyond link building, engage in digital PR, thought leadership, and other brand-building activities. The goal is to increase brand-name searches and direct visits, as these are strong signals that potentially contribute to the
siteAuthoritymetric.
Optimising for the User-Validation Feedback Loop
Finally, all algorithmic predictions of quality must be validated by real users. Optimising for the user experience is essential to complete the quality feedback loop and secure long-term rankings.
- Solve User Intent Completely: The primary goal of any high-effort content piece must be to directly and comprehensively answer the user’s query. A satisfying experience that ends the user’s search journey is what generates
goodClicksand long dwell times, which are powerful positive signals for the NavBoost system. - Enhance User Experience (UX): A technically sound website is the foundation of a good user experience. This includes optimising for Core Web Vitals (page speed and stability), ensuring mobile-friendliness, and avoiding intrusive interstitials or excessive advertising that could contribute to a high
clutterScore. A clean, fast, and easy-to-navigate site reduces bounce rates and pogo-sticking. - Utilise Strategic Internal Linking: Employ a logical internal linking structure to guide users from one piece of relevant, high-effort content to another. This increases session duration, exposes users to more of the site’s expertise, and helps search engines understand the topical relationships between pages, reinforcing the site’s overall authority on a subject.

![]() Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its
Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its contentEffort and E-E-A-T signals.

References
- Google API Content Warehouse Leak – Analysis – Mojo Dojo, accessed on September 21, 2025, https://mojodojo.io/blog/googleapi-content-warehouse-leak-an-ongoing-analysis/
- Confirmed Ranking Factors based on Google Search API Leak – Growfusely, accessed on September 21, 2025, https://growfusely.com/blog/google-api-leak/
- Google Search Leaks: What’s in the document? – Techmagnate, accessed on September 21, 2025, https://www.techmagnate.com/blog/know-about-the-google-search-leak-documents/
- The Google API Leak and E-E-A-T – Keywords People Use, accessed on September 21, 2025, https://keywordspeopleuse.com/seo/guides/google-api-leak/e-e-a-t
- Google Algo Leak: Summary of the Most Interesting Aspects – In Marketing We Trust, accessed on September 21, 2025, https://inmarketingwetrust.com.au/google-algo-leak-summary-of-the-most-interesting-aspects/
- 10 Actionable Insights from the Google Algorithm Leak | Universal Creative Solutions, accessed on September 21, 2025, https://www.universalcreativesolutions.com/insights/post/actionable-insights-from-the-google-algorithm-leak
- What creators should know about Google’s August 2022 helpful content update, accessed on September 21, 2025, https://developers.google.com/search/blog/2022/08/helpful-content-update
- Google API Leak & SEO: How Can It Improve your Search Engine Optimisation – Curious, accessed on September 21, 2025, https://www.iamcurious.co.uk/google-api-leak-what-does-it-mean-for-search-engine-optimisation/
- Secrets from the Algorithm: Google Search’s Internal … – iPullRank, accessed on September 21, 2025, https://ipullrank.com/google-algo-leak
- Google API Leak: Ranking factors and systems, accessed on September 21, 2025, https://www.kopp-online-marketing.com/google-api-leak-ranking-relevant-systems-and-metrics
- Local Search Implications of the Google API Leak – Near Media, accessed on September 21, 2025, https://www.nearmedia.co/googles-api-leak-and-local-search/
- Google Search API Leak: Top 5 Key Findings for Marketers (2024) – Resolution Digital, accessed on September 21, 2025, https://www.resolutiondigital.com.au/services/digital-media/insights/google-api-leak-top-seo-recommendations/
- Google Algorithm Leak: What Content Creators Need to Know | by Jairo Rodriguez Garza, accessed on September 21, 2025, https://medium.com/@jairorodriguezgarza/google-algorithm-leak-what-content-creators-need-to-know-95638cbdae23
- 22 Things We Might Have Learned From The Google Search Leak, accessed on September 21, 2025, https://www.searchlogistics.com/learn/seo/algorithm/google-search-leak/
- The Biggest Takeaways From the Google Search Algorithm Leak – VELOX, accessed on September 21, 2025, https://www.veloxmedia.com/blog/google-search-algorithm-leak-takeaways
- Google Search Data Leak: Four Key Takeaways – Innovaxis Marketing, accessed on September 21, 2025, https://www.innovaxisinc.com/b2b-marketing-strategy-blog/four-takeaways-from-the-google-search-algorithm-leak
- My take away from the Google algorithm leak : r/SEO – Reddit, accessed on September 21, 2025, https://www.reddit.com/r/SEO/comments/1d350h5/my_take_away_from_the_google_algorithm_leak/
- Everything we know about the massive Google algorithm leak – Embryo, accessed on September 21, 2025, https://embryo.com/blog/everything-we-know-about-the-massive-google-algorithm-leak/
- HUGE Google Search document leak reveals inner workings of ranking algorithm, accessed on September 21, 2025, https://searchengineland.com/google-search-document-leak-ranking-442617
- Google API Leak: A Look Inside the Algorithm – Optimal, accessed on September 21, 2025, https://www.winwithoptimal.com/insights/google-api-leak/
- Google API Leak: Comprehensive Review and Guidance – Marketing Aid, accessed on September 21, 2025, https://www.marketingaid.io/google-api-leak-comprehensive-review-and-guidance/
- Google quality rater guidelines: comprehensive and updated guide – SEOZoom, accessed on September 21, 2025, https://www.seozoom.com/google-search-quality-rater-guidelines/
- What are Google’s Quality Rater Guidelines? – Ryte Wiki, accessed on September 21, 2025, https://en.ryte.com/wiki/Quality_Rater_Guidelines/
- Google updates search quality raters guidelines adding AI Overview examples & YMYL definitions – Search Engine Land, accessed on September 21, 2025, https://searchengineland.com/google-updates-search-quality-raters-guidelines-adding-ai-overview-examples-ymyl-definitions-461908
- Google quality raters now assess whether content is AI-generated – Search Engine Land, accessed on September 21, 2025, https://searchengineland.com/google-quality-raters-content-ai-generated-454161
- How the Google leak confirms the significance of author and publisher entities in SEO, accessed on September 21, 2025, https://searchengineland.com/google-leak-author-publisher-entities-seo-442963
- Google Search Quality Rater Guidelines: Key Insights About AI Use – Originality.ai, accessed on September 21, 2025, https://originality.ai/blog/google-search-quality-rater-guidelines-ai
- The Helpful Content Update Was Not What You Think – Moz, accessed on September 21, 2025, https://moz.com/blog/helpful-content-update-not-what-you-think
- SEO Starter Guide: The Basics | Google Search Central | Documentation, accessed on September 21, 2025, https://developers.google.com/search/docs/fundamentals/seo-starter-guide
- Six Ways to Improve Your Site’s Ranking (SEO) – Michigan Technological University, accessed on September 21, 2025, https://www.mtu.edu/umc/services/websites/seo/
- Content Score – What It Is and How To Use It for SEO and Content Marketing – Surfer SEO, accessed on September 21, 2025, https://surferseo.com/blog/content-score-product-update/
- The Three Pillars Of SEO: Authority, Relevance, And Experience – Search Engine Journal, accessed on September 21, 2025, https://www.searchenginejournal.com/seo/search-authority/
- Ranking Factors in 2025: Insights from 1 Million SERPs – Surfer SEO, accessed on September 21, 2025, https://surferseo.com/blog/ranking-factors-study/
- SEO Analysis: How to Conduct 4 Types of Analyses Effectively, accessed on September 21, 2025, https://www.singlegrain.com/seo/seo-analysis/
- SEO Ranking Factors – What Are The Important Ones? – Supple Digital, accessed on September 21, 2025, https://supple.com.au/guides/seo-ranking-factors/
- 6 Simple Steps to Improve Your SEO Content Score and Why You Should Care, accessed on September 21, 2025, https://trendemon.com/blog/6-simple-steps-to-improve-your-seo-content-score-and-why-you-should-care/
Disclosure: Hobo Web uses generative AI when specifically writing about our own experiences, ideas, stories, concepts, tools, tool documentation or research. Our tools of choice for this process is Google Gemini Pro 2.5 Deep Research. This assistance helps ensure our customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was verified as correct by Shaun Anderson. See our AI policy.