Disclaimer: This is not official. Any article (like this) dealing with the Google Content Data Warehouse leak requires a lot of logical inference when putting together the framework for SEOs, as I have done with this article. I urge you to double-check my work and use critical thinking when applying anything for the leaks to your site. My aim with these articles is essentially to confirm that Google does, as it claims, try to identify trusted sites to rank in its index. The aim is to irrefutably confirm white hat SEO has purpose in 2025 – and that purpose is to build high-quality websites. Feedback and corrections welcome. First published on 6 October 2025.
The following matrix serves as a high-level summary of the core findings presented in this article an my core thesis that E-E-A-T is Google’s doctrine codified.
It aims to provide (with a lot of inference on my part) a direct correlation between publicly known Google algorithm updates or internal ranking systems and the specific, named technical attributes revealed in the 2024 Google Content Warehouse API documentation and the U.S. D.O.J. v. Google antitrust trial.
This table acts as a foundational reference, mapping the conceptual purpose of each system to its concrete, architectural implementation within Google’s ranking pipeline. Remember, it is a work of logical inference – this is not official. Google won’t confirm stuff like this.
| System / Framework | Primary Function / Purpose | Key Associated Leaked Attributes |
| Core Authority / Q* | Assesses the overall, site-wide trust, authority, and quality of a domain. Functions as a foundational, query-independent quality score. | siteAuthority, nsrDataProto (Normalised Site Rank), authorityPromotion, homepagePagerankNs, chromeInTotal, unauthoritativeScore |
| Google Panda Update / Content Quality | Demotes sites with prevalent low-quality, thin, or duplicate content. Operates as a site-wide quality signal. | pandaDemotion, babyPandaDemotion, lowQuality, shingleInfo, OriginalContentScore |
| NavBoost / CRAPS | Re-ranks results based on user click behavior and engagement signals observed on the Search Engine Results Page (SERP) and on-site. | navDemotion, serpDemotion, GoodClicks, BadClicks, LastLongestClicks, crapsNewUrlSignals, crapsNewHostSignals |
| Helpful Content System (HCS) | Rewards “people-first” content and demotes low-value, ranking-focused content, with a focus on originality and topical coherence. | contentEffort, ugcScore, ugcDiscussionEffortScore, siteFocusScore, siteRadius |
| E-E-A-T Framework | A quality assessment framework enforced by a suite of signals measuring Experience, Expertise, Authoritativeness, and Trust. | Experience/Expertise: contentEffort, OriginalContentScore, isAuthor Authoritativeness: siteAuthority, authorityPromotion Trust: scamness, badSslCertificate, ymy1NewsV2Score, healthScore |
| Page Experience / Mobile-First | Evaluates and penalises poor user experience, including on-page clutter, intrusive ads/interstitials, and poor mobile usability. | clutterScore, violatesMobileInterstitialPolicy, adsDensityInterstitialViolationStrength, isSmartphoneOptimized, mobileCwv, desktopCwv |
| Product Reviews Update | Applies specialised, more rigorous quality criteria to product review content, rewarding first-hand expertise and in-depth analysis. | productReviewPPromotePage, productReviewPDemoteSite, productReviewPUhqPage (Ultra High Quality) |
| Algorithmic Penalties | ||
| EMD (Exact Match Domain) Update | Neutralises the unfair ranking advantage of low-quality sites that use an exact-match keyword as their domain name. | exactMatchDomainDemotion |
| Google Penguin Update | Penalises manipulative link-building tactics, particularly those involving irrelevant or over-optimised anchor text. | anchorMismatchDemotion, IsAnchorBayesSpam |
| General Spam Detection | Identifies and demotes content that is deceptive, fraudulent, or employs various manipulative tactics. | scamness, KeywordStuffingScore, GibberishScore, spamrank, spambrainData |
Google Algorithm Update & Leaked Attribute Correlation Matrix (1998–2025)
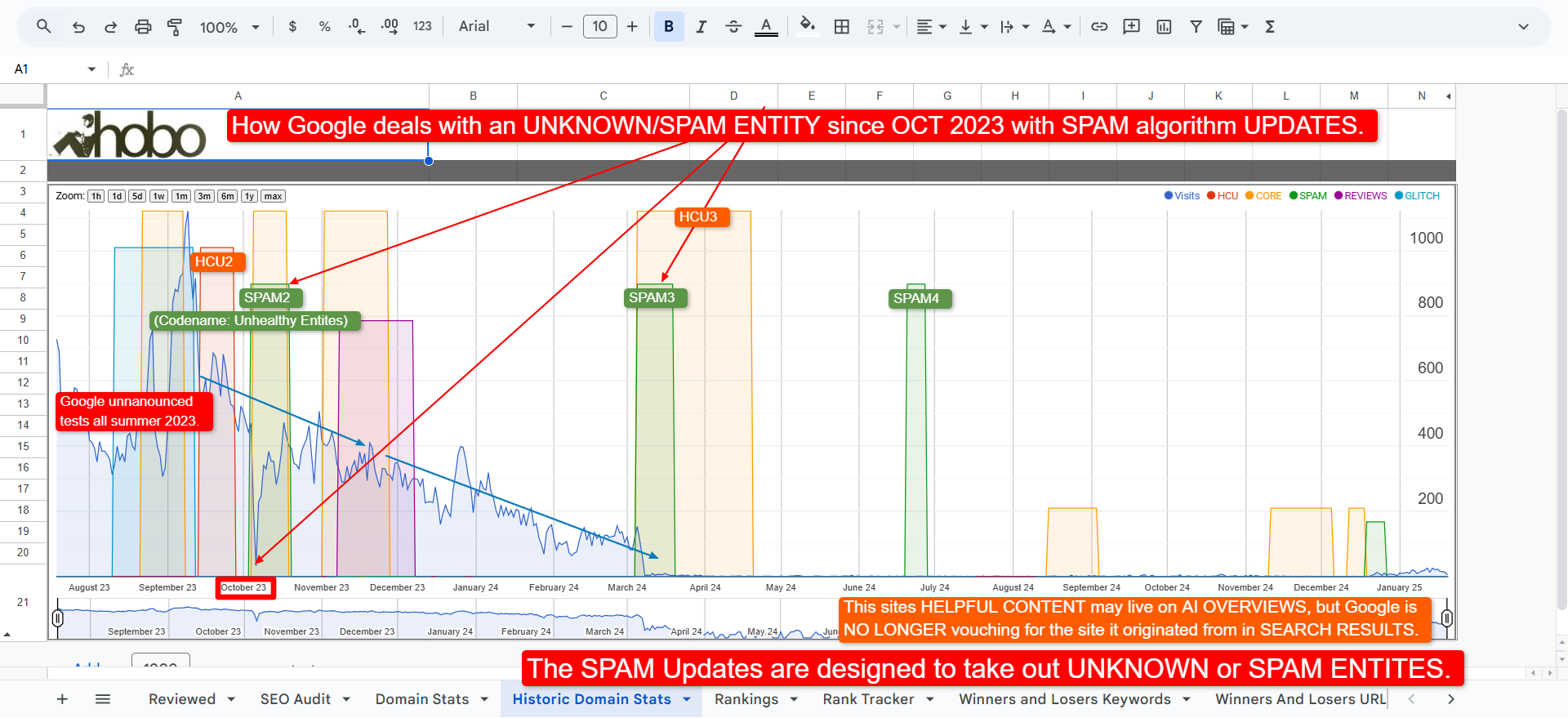
These Google Algorithm Update tables provide a direct mapping from the major named updates throughout Google’s history to the specific internal systems and attributes that likely power them, based on the leaked documentation. Remember! This is not official, and it is a work of educated logical inference by me.
Table 1: The Foundational & Early Spam Era (1998-2010)
This period covers the establishment of Google’s core link-based authority system and its initial efforts to combat manipulative, on-page spam tactics. Remember, it is a work of logical inference – this is not official. Google won’t confirm stuff like this
Table 2: The Content Quality & User Experience Era (2011-2017)
This era was defined by major named updates (Panda, Penguin, Hummingbird) that shifted the focus towards content quality, user experience, mobile-friendliness, and semantic search. Remember, it is a work of logical inference – this is not official. Google won’t confirm stuff like this
Table 3: The AI, E-A-T & Core Systems Era (2018-Present)
The modern era focuses on machine learning, Expertise-Authoritativeness-Trustworthiness (E-A-T), and the consolidation of major signals (like Helpful Content) into broad “Core Updates.” Remember, it is a work of logical inference by Hobo – this is not official. Google won’t confirm stuff like this
![]() Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its
Rate My Page Quality using the Hobo SEO Method: A prompt that uses a 12-criterion methodology to perform a deep audit of a single URL, algorithmically estimating its contentEffort and E-E-A-T signals.
Introduction: From Black Box to Blueprint
For over two decades, the field of Search Engine Optimisation (SEO) has operated under a paradigm of reverse-engineering a black box.
Strategies were built on a foundation of correlation, empirical observation, and the careful interpretation of public guidance.
The 2024 Google Content Warehouse API leak, corroborated by sworn testimony and exhibits from the U.S. D.O.J. v. Google antitrust trial, represents a fundamental paradigm shift.
For the first time, the SEO industry has access to the architectural blueprints, moving the discipline from an art of inference to a science of architectural alignment.
This article provides a forensic analysis of these revelations, mapping the “fossil record” of Google’s public algorithm updates to their specific, documented enforcement mechanisms within the core data structures of Google Search.
Deconstructing the Ranking Pipeline
The analysis confirms that Google’s ranking process is not a single, monolithic algorithm but a sophisticated, multi-stage pipeline. A document’s journey from the index to a top position is a sequence of evaluations, each governed by different systems and signals.
The process begins with an initial retrieval and scoring stage handled by a primary system named Mustang. This system is engineered for immense scale and efficiency, relying on a set of pre-computed, highly compressed quality signals to conduct a first-pass evaluation of a vast set of potentially relevant documents.
This preliminary scoring, fed by a module known as CompressedQualitySignals, acts as a critical gatekeeper, determining which documents are worthy of more computationally expensive analysis.
This module is the essential “cheat sheet” or “rap sheet” containing the pre-computed data points for a document, while a system known as Q* reads this sheet to calculate the final, aggregate quality score.
Following Mustang’s initial pass, the provisional results are subjected to a powerful re-ranking layer known as “Twiddlers.”
These are a series of subsequent re-ranking functions that modify, or “twiddle,” the search results based on more nuanced, often query-dependent factors.
Evidence confirms the existence of numerous Twiddlers, including those that adjust rankings based on user engagement (a system known as NavBoost), content freshness (Freshness Twiddler), and overall quality (QualityBoost).
Success in modern SEO requires optimising not just for the initial relevance-based retrieval by Mustang, but also for the subsequent quality- and user-satisfaction-based judgments of the Twiddlers.
The Foundational Data Modules
This entire pipeline operates on a set of foundational data structures that serve as the comprehensive “digital dossier” for every URL Google indexes. Understanding these containers is key to understanding the logic of the system itself.
- The CompositeDoc is the master record, the top-level container that aggregates all known information about a single document. It is the foundational data object within the Content Warehouse.
- Within the CompositeDoc, the PerDocData model serves as the primary container for the vast majority of document-level signals. It is the central repository where on-page factors, quality scores, spam signals, freshness metrics, and user engagement data are stored.
- The QualityNsrPQData module represents the core of Google’s page-level quality assessment. It contains a collection of distinct, yet interconnected, signals that build a holistic quality profile for a URL, including the foundational predictedDefaultNsr score.
- Finally, the CompressedQualitySignals module acts as a highly optimised “rap sheet.” It contains the pre-calculated, compressed versions of the most critical quality judgments—such as authority, Panda demotions, and behavioural penalties—that are used by the Mustang system for its rapid, preliminary scoring.
By deconstructing these modules and the systems that use them, this report provides an evidence-based framework for aligning SEO strategy with the documented architecture of Google Search.
Section 1: The Authority Matrix – Core Quality & Site-Wide Trust
The evidence from the Google leak and the D.O.J. trial confirms that the most foundational layer of Google’s evaluation is a site-level judgment of trust and authority.
This assessment, which operates largely independent of any specific query, establishes a baseline of credibility for a domain, acting as either a powerful amplifier or a persistent suppressor for all content published on that site. This section deconstructs the mechanisms behind this site-wide quality score.
The Site-Wide Quality Score (Q*)
For years, the SEO community has operated with the concept of “Domain Authority,” a third-party metric intended to proxy a site’s overall strength.
The D.O.J. trial has effectively ended this era of proxies by confirming the existence of Google’s internal equivalent: a largely static, query-independent score designated as Q* (pronounced “Q-star”).
Testimony from Google engineers established Q* as a site-wide quality score that influences the ranking potential of all pages on a domain. This is, for all practical purposes, the confirmed domain authority metric that has long been theorised.
The trial also clarified the modern role of Google’s original breakthrough algorithm, PageRank.
While once the dominant factor in rankings, PageRank is now understood to be just one of several inputs into the broader calculation of the Q* signal.
Its function has evolved from a simple measure of link volume to a foundational link equity signal that, when combined with other trust and quality factors, contributes to a site’s overall Q* score.
This reframes PageRank not as the end goal of link building, but as a crucial ingredient in a much more holistic recipe for authority.
Technical Implementation via Leaked Attributes
The leaked API documentation reveals the specific attributes that serve as the technical underpinnings for this abstract concept of site-wide quality. These signals are the quantifiable data points that Google’s systems use to calculate and store a domain’s authoritative standing.
- siteAuthority: This integer value, found within the CompressedQualitySignals module, is the central pillar of the authority assessment. It is described as a persistent, composite score calculated at the site or sub-domain level, converted from quality_nsr.SiteAuthority and applied in Q*. It is not a simple link metric but a multi-vector score that fuses data from link-based authority, user interaction signals, and a site’s topical focus. Its presence in the compressed module underscores its importance as a foundational input for preliminary ranking in the Mustang system.
- nsrDataProto (Normalised Site Rank): The PerDocData and QualityNsrPQData modules both reference NSR, a sophisticated algorithm for assessing a website’s reliability and trustworthiness that appears to be the spiritual successor to the original PageRank. The
predictedDefaultNsr attribute within QualityNsrPQData functions as the baseline quality score for a URL, derived from content quality, user behaviour, and the quality of a site’s link neighbourhood. A high NSR score is a clear indicator that Google’s systems perceive a site as a reliable and authoritative source. - authorityPromotion: This signal, also from the CompressedQualitySignals module, acts as a positive modifier or boost applied to a document’s score based on specific features that signify high authority. Its existence is significant as it demonstrates that Google’s authority system is not purely punitive; it is also designed to actively identify and promote exemplary sites, creating a wider gap between average and truly authoritative domains.
- unauthoritativeScore: This is not merely the absence of authority but an active, calculated penalty. It is a direct negative signal that quantifies a lack of authoritativeness, serving as a powerful demotion factor.
- OriginalContentScore & contentEffort: While these are page-level signals from PerDocData and QualityNsrPQDat,a respectively, they are critical contributing factors to the site-wide quality perception. A domain that consistently publishes content with high originality and demonstrable effort across a large number of pages will, through aggregation, logically contribute to a higher overall Q* and
siteAuthority score. This confirms that site-wide authority is not just about backlinks, but is also built from the ground up through a consistent commitment to high-quality content creation.
The architecture of these signals reveals a dual-speed system for evaluating authority.
The Q* score, described as “largely static,” provides long-term stability and a high barrier to entry, rewarding sustained investment in quality over many years.
In contrast, signals like predictedDefaultNsr are stored as a VersionedFloatSignal, meaning Google’s systems maintain a historical record and can track the trajectory of a site’s quality over time.
This versioning allows the system to be responsive to a site’s recent improvements or degradations without needing to perform a full, computationally expensive recalculation of the more stable Q* score. This balance between stability and responsiveness explains why recovery from a major quality issue is a long and arduous process.
A site must not only fix its underlying problems but also build a positive trajectory in its versioned quality scores over a prolonged period to eventually influence its foundational, static reputation.
Section 2: The Ghost of Panda – The Enduring War on Low-Quality Content
The 2011 Google Panda update was a watershed moment in SEO history, marking a definitive shift away from rewarding keyword relevance alone and toward penalising low-quality content at a site-wide level.
The leaked documentation reveals that the principles of Panda are not a historical relic but are “fossilised” within Google’s core ranking architecture. They exist as a family of persistent, automated demotion signals that continue to function as a powerful filter against thin, duplicate, and unhelpful content.
The Panda Algorithm Revisited
The Panda update was Google’s algorithmic response to the proliferation of “content farms” and other low-quality websites that had learned to rank well through scale and keyword optimization rather than genuine value. Its publicly stated purpose was to reduce the visibility of sites characterised by:
- Thin Content: Pages with very little unique or substantive text.
- Duplicate or Near-Duplicate Content: Large-scale repetition of content, both within a single site and across the web.
- Low User Trust: Content that is poorly researched, inaccurate, or lacks authoritative sources.
- High Ad-to-Content Ratio: Pages where the user experience is significantly degraded by an excessive or intrusive ad load.
Crucially, Panda was one of the first major algorithms to apply its judgment at a site-wide or sub-domain level. A site with a significant percentage of low-quality pages would see its overall ranking potential suppressed, affecting even its high-quality content.
Technical Implementation via Leaked Attributes
The CompressedQualitySignals module contains a clear lineage of Panda-related signals, confirming its continued operation and evolution within the ranking pipeline.
- pandaDemotion: This is the primary signal, representing the core, site-wide demotion assessment of the Panda algorithm. It is derived from SiteQualityFeatures, reinforcing its site-wide application. Its presence in the CompressedQualitySignals module confirms that a site’s “Panda score” is a pre-computed factor used in the initial stages of ranking, acting as a foundational penalty before other signals are even considered.
- babyPandaDemotion & babyPandaV2Demotion: These attributes represent subsequent iterations of the algorithm, demonstrating a continuous process of refinement. The documentation notes that babyPandaV2Demotion replaced the original babyPandaDemotion, providing a clear view of the algorithm’s evolutionary path. The connection of babyPandaDemotion to QualityBoost.rendered.boost suggests that later versions may have become more sophisticated, or “softer” as I am sure I remember it being said, targeting quality issues that only become apparent after a page’s JavaScript has been fully rendered.
- lowQuality: This signal, described as an “S2V low quality score” derived from NSR data, likely functions as a more modern, machine-learning-based companion to the original Panda signals. The “S2V” designation likely refers to “site-to-vector,” a technique where an entire site’s content is converted into a numerical vector embedding. By training a model on sites known to be low-quality, Google can programmatically identify other sites that occupy a similar “low-quality” region in the vector space, allowing for more nuanced and scalable detection than the original Panda’s more heuristic-based approach.
- shingleInfo: The underlying mechanism for detecting duplicate content, a primary target of Panda, is also evident in the PerDocData module. The shingleInfo attribute stores data from “shingling,” a technique where a document’s content is broken down into overlapping sequences of words to create a unique fingerprint. By comparing these fingerprints, Google’s systems can efficiently detect near-duplicate content at a massive scale, which is a key input for the pandaDemotion calculation.
The site-wide nature of the pandaDemotion signal means it functions as a form of “algorithmic debt.” Every low-quality, thin, or duplicate page on a domain contributes to this debt. Once a critical threshold is crossed, the entire site’s visibility is suppressed. This architectural reality explains the devastating and often persistent impact of Panda-related quality issues.
The problem is not that individual low-quality pages fail to rank; it is that the entire domain is handicapped by a negative site-level demotion factor that is applied during the preliminary scoring phase. Recovery, therefore, requires a comprehensive and often painful process of “paying down the debt.”
This involves a site-wide content audit to systematically improve, consolidate, or remove the offending low-quality pages until the site’s overall quality profile rises above the demotion threshold.
Section 3: The User as the Ultimate Arbiter – NavBoost and Behavioural Demotions
While site authority and content quality form the foundational pillars of Google’s evaluation, the D.O.J. trial and the API leak have irrefutably confirmed that the ultimate arbiter of ranking success is the user.
The evidence reveals a powerful, closed-loop system that translates raw user clickstream data into direct, quantifiable ranking signals. This system makes user satisfaction not just a conceptual goal of SEO, but a primary, measurable input into the core algorithm.
The NavBoost & CRAPS Systems
The D.O.J. trial provided the first public confirmation of a critical re-ranking system called NavBoost.
Sworn testimony from Google executives described NavBoost as one of the most important ranking signals, a system that uses a rolling 13-month window of aggregated user click data to refine and re-rank search results.
It functions as a massive, data-driven feedback loop, essentially allowing the collective behaviour of users to vote on the quality and relevance of search results.
The leaked documentation provides the technical specifics of this system.
It confirms that NavBoost is the data collection engine, while a separate system named CRAPS (an internal acronym thought to stand for Click and Results Prediction System) is the processing engine that translates the raw click data into actionable demotion scores.
The system captures a nuanced view of user satisfaction by tracking specific metrics:
- GoodClicks: These are clicks that signal a successful user outcome. The most powerful of these is the lastLongestClick, which indicates the final result a user clicked on in a search journey and on which they dwelled for a significant period. This is a strong signal that the query was successfully resolved by that page.
- BadClicks: These are clicks that signal user dissatisfaction. The classic example is “pogo-sticking,” where a user clicks a result and then immediately returns to the SERP to choose a different one. This behaviour is a clear indicator that the initial result failed to satisfy the user’s intent.
Technical Implementation via Leaked Attributes
The outputs of the CRAPS processing engine are stored as direct, pre-computed demotion factors within the CompressedQualitySignals module. The existence of two distinct demotion signals is particularly revealing.
- navDemotion: This is a demotion signal explicitly linked to “poor navigation or user experience issues” on the destination website itself. This signal is generated when a user clicks through to a page but has a negative experience—for example, the site is slow, the navigation is confusing, or the content doesn’t deliver on the promise of the SERP snippet—causing them to leave. It represents the penalty for a poor
on-site experience. - serpDemotion: This demotion is based on negative user behaviour observed directly on the Search Engine Results Page (SERP) itself. This is primarily driven by pogo-sticking behaviour. It represents the penalty for a poor
off-site experience—that is, a failure of the page’s title and snippet to set an accurate expectation for the user, leading to a “bad click” even before the on-page experience is fully evaluated. - crapsNewUrlSignals, crapsNewHostSignals: This family of signals contains complex, encoded data structures that summarise click and impression data at both the URL and host level, serving as the compressed output of the CRAPS system.
The architectural separation of navDemotion and serpDemotion shows that Google’s systems measure user dissatisfaction at two distinct stages of the user journey. This creates a comprehensive feedback loop that penalises both a poor “promise” (the SERP snippet) and a poor “delivery” (the on-page experience). A site can therefore be demoted for two different failures.
The first is a marketing failure: making a bad pitch on the SERP that fails to attract or accurately qualify clicks, leading to serpDemotion. The second is a product failure: failing to deliver a satisfying experience to the user after they have clicked, leading to navDemotion.
A successful SEO strategy must therefore be two-fold: it must first win the click with a compelling and accurate SERP presentation, and then it must satisfy the user’s intent post-click with a technically sound and genuinely helpful page experience.
Section 4: The Page Experience Pillar – Clutter, Interstitials, and Performance
Google’s public-facing emphasis on “page experience” – a holistic measure of a user’s interaction with a web page – is not merely a set of best-practice recommendations.
The leaked documentation confirms that this concept is enforced by a suite of punitive, often site-level, signals that algorithmically penalise on-page clutter, intrusive elements, and poor mobile usability.
These signals represent the technical implementation of a series of well-known algorithm updates, including the Page Layout (“Top Heavy”) update, the Intrusive Interstitial Penalty, and the Page Experience Update (Core Web Vitals).
Technical Implementation via Leaked Attributes
The API documentation reveals a sophisticated system for identifying and penalising user-hostile page layouts, particularly on mobile devices.
- clutterScore: This is a site-level signal found in the CompressedQualitySignals module, explicitly designed to penalise sites with a large number of “distracting/annoying resources”. The documentation reveals a highly sophisticated system for this analysis, which includes detailed geometric analysis of intrusive elements. Crucially, the system can “smear” a negative signal found on a sample of bad URLs to a whole cluster of similar pages, identified by the isSmearedSignal attribute. This means Google does not need to crawl every cluttered page on a site; it can identify a pattern and apply a site-wide penalty, making the clutterScore a powerful enforcement mechanism against aggressive monetisation or poor design.
- violatesMobileInterstitialPolicy: This is a punitive boolean (true/false) flag within the SmartphonePerDocData module. It acts as a direct, non-nuanced demotion signal for pages with intrusive pop-ups that obscure content on mobile devices. Its existence as a simple true/false switch confirms that this is a hard penalty, not a gentle nudge, algorithmically enforcing Google’s public guidelines.
- adsDensityInterstitialViolationStrength: Complementing the boolean flag, this attribute provides a scaled integer from 0 to 1000, indicating not just if a page violates mobile ad density policies, but the strength of that violation. This demonstrates a layered system that can apply penalties with surgical precision, with more egregious violations receiving a stronger demotion factor.
- isSmartphoneOptimized: This tri-state field (true, false, or unset) in the SmartphonePerDocData module confirms that Google’s internal system for mobile-friendliness goes beyond the public pass/fail test, allowing for a more nuanced classification of mobile usability.
- mobileCwv / desktopCwv: These attributes, found within a model whose stated purpose is for “ranking changes,” provide direct evidence that Core Web Vitals field data is ingested, stored per-document, and used to influence rankings.
These page experience signals function as a proactive defence mechanism for the more reactive, click-based NavBoost system. NavBoost requires a statistically significant amount of user interaction data to make a judgment.
A brand new, heavily cluttered page has no click history. Instead of waiting for thousands of users to have a negative experience on such a page, Google’s systems can use architectural analysis to predict a poor outcome.
A page with an intrusive layout can be assigned a high clutterScore or flagged with violatesMobileInterstitialPolicy upon indexing. This allows a pre-emptive demotion to be applied during the initial Mustang ranking pass, before the page has a chance to frustrate a large volume of users.
The reactive data from NavBoost then serves to validate or adjust this initial, proactive judgment over time. This architecture makes a clean, user-friendly page experience a foundational prerequisite for ranking, not a secondary optimisation task.
Section 5: The Specialist Evaluators – Vertical-Specific Quality Systems
The leaked documentation makes it clear that Google’s quality assessment is not a one-size-fits-all process.
The ranking algorithm contains specialised, context-aware sub-systems that apply more rigorous and nuanced quality criteria to high-stakes or commercially sensitive content verticals.
This is most evident in the sophisticated set of signals dedicated to evaluating product reviews and user-generated content (UGC), which serve as the technical implementation of the Product Reviews Update and the broader Helpful Content System.
Technical Implementation via Leaked Attributes
The CompressedQualitySignals module contains entire suites of signals designed for these specific content types, demonstrating a level of granularity far beyond a generic quality score.
Product Review System
The system for evaluating product reviews is designed not just to demote poor content but to actively identify and promote exceptional examples. The following signals are present:
- productReviewPPromotePage, productReviewPDemotePage, productReviewPPromoteSite, and productReviewPDemoteSite: This suite of signals demonstrates that the system operates at both the page level and the site level. Google assesses the quality of individual reviews while also evaluating the overall trustworthiness of a domain as a source of review content. This directly corresponds to the public guidelines for the Product Reviews Update, which emphasise expertise and first-hand use.
- productReviewPUhqPage: The existence of this signal, likely standing for “Ultra High Quality Page,” is a profound revelation. It indicates a distinct, highest-echelon classification for content that is not just good, but exceptional. This suggests that Google’s quality scale for reviews is not linear, and achieving this “UHQ” status may unlock a disproportionately high level of ranking potential.
User-Generated Content (UGC) System
With Google’s strategic pivot toward surfacing more authentic, conversational content, the ability to distinguish valuable UGC from low-quality spam has become critical. The following signals enable this distinction:
- ugcScore: This is a general score designed to evaluate sites with significant user-generated content, such as forums or Q&A platforms.
- ugcDiscussionEffortScore: This more granular score, also found in CompressedQualitySignals, measures the quality and effort of user-generated discussions and comments. The documentation explicitly notes that for review pages, high-quality user discussion can act as an additional positive quality signal. This directly links community engagement to the core product review quality assessment and is a key component of the Helpful Content System’s focus on authentic, first-hand experience.
The existence of a distinct productReviewPUhqPage signal implies a non-linear reward system for quality.
While a standard “promote” signal might provide an incremental ranking boost, achieving “Ultra High Quality” status may place a piece of content into an entirely different class of results. It might become eligible for prime SERP features, receive a much stronger ranking weight, or be used as a benchmark for quality in its vertical.
This changes the strategic calculus for content creators in these verticals.
The goal should not be to simply be “better than the competition,” but to produce content that is an order of magnitude more detailed, insightful, and evidence-backed, aiming to cross the threshold into this “UHQ” classification where the return on investment is likely to be exponential, not linear.
Section 6: A Taxonomy of Algorithmic Penalties
The leaked documentation confirms that Google has codified the enforcement of its webspam policies by creating a taxonomy of dedicated demotion signals.
These signals, primarily located within the CompressedQualitySignals module, target specific, well-defined manipulative SEO tactics. Their presence as pre-computed values demonstrates a strategic shift from reactive, manual penalties to proactive, scalable, and automated enforcement that is built into the foundational layer of the ranking pipeline.
Technical Implementation via Leaked Attributes
This section details the specific algorithmic penalties designed to combat historical and ongoing spam tactics.
- exactMatchDomainDemotion: This signal is the direct technical implementation of the 2012 EMD (Exact Match Domain) Update. It applies a demotion to low-quality websites that use a keyword-stuffed domain name (e.g., buycheapwidgets.com) as their primary ranking asset, neutralising the unfair advantage such domains once held.
- anchorMismatchDemotion: This signal is a clear legacy of the Google Penguin update, which targeted manipulative link-building schemes. It penalises pages when the anchor text of inbound links is not topically relevant to the content of the destination page. It is designed to combat over-optimisation and the use of irrelevant anchor text to create a false signal of relevance.
- IsAnchorBayesSpam: This boolean flag, found in the PerDocData module, complements the anchorMismatchDemotion signal. It is the output of a classifier that specifically analyses the patterns of inbound anchor text to identify link spam schemes, providing another layer of defence against unnatural link profiles.
- scamness: This attribute provides a numerical score, scaled from 0 to 1023, indicating the likelihood that a page is deceptive or fraudulent. The use of a scaled score rather than a simple Boolean flag demonstrates a probabilistic approach, allowing the system to apply penalties of varying severity based on its confidence level that a page is a scam.
- spamrank: This score, found in PerDocData, measures the likelihood that a document links out to known spam sites. It confirms the long-held SEO principle that a site’s “link neighbourhood” is a measured risk factor, and associating with low-quality or spammy sites by linking to them can negatively impact a page’s own quality assessment.
The placement of these specific demotion factors within the CompressedQualitySignals module is architecturally significant.
In the past, penalties for tactics like unnatural linking were often applied after a manual review or during the slow rollout of a major update like the original Penguin.
By pre-computing these penalties and making them available to the Mustang ranking system, Google has transformed enforcement from a reactive punishment to a proactive disqualification. The system can automatically and programmatically suppress a page that exhibits these well-known manipulative patterns before it ever has a chance to rank and degrade the user experience.
This architecture makes manipulative “black hat” SEO a fundamentally unsustainable strategy, as the system is no longer just trying to catch spam after the fact; it is designed to filter it out at the very first stage of the ranking process.
Section 7: The Algorithmic Codification of E-E-A-T & The Helpful Content System
The leaked documentation provides a clear bridge between Google’s public-facing quality frameworks – E-E-A-T (Experience, Expertise, Authoritativeness, and Trust) and the Helpful Content System (HCS) – and their internal, algorithmic enforcement.
The evidence shows that these are not abstract concepts but are operationalised through a suite of specific, measurable signals.
The Central Role of contentEffort
The technical lynchpin of the HCS appears to be the contentEffort attribute, defined as a “Large Language Model (LLM)-based effort estimation for article pages”.
This signal represents a direct attempt to algorithmically quantify the human labour, originality, and resources invested in creating a piece of content. It is a direct countermeasure to low-effort, scaled, and AI-generated content that lacks depth.
A low contentEffort score is a strong indicator that content is not “people-first” and may trigger the site-wide demotion characteristic of the HCS.
The LLM calculates this score based on several factors:
- Multimedia Integration: The inclusion of unique images, videos, and embedded tools, as opposed to generic stock assets.
- Originality and Data: The presence of unique data, in-depth information, and original research that introduces new information to the web.
- Structure and Complexity: A logical structure, complex language, and the inclusion of authoritative citations.
- Difficulty of Replication: An assessment of how easily the content could be reproduced; content with original data and expert interviews is difficult to replicate and thus signals higher effort.
Mapping Attributes to E-E-A-T Pillars
The analysis confirms that E-E-A-T is not a single score but an emergent property of dozens of granular attributes. The leaked signals can be mapped to the four pillars of E-E-A-T 7:
- Experience & Expertise: This is directly measured by contentEffort, which serves as an algorithmic proxy for the expertise and research invested in the content. It is supported by OriginalContentScore (measuring uniqueness) and the system’s ability to identify authors as distinct entities (isAuthor).
- Authoritativeness: This is proxied by the siteAuthority metric, a composite score influenced by a site’s backlink profile (PageRank) and brand mentions. The authorityPromotion attribute confirms that a high authority score can lead to a direct ranking boost.
- Trustworthiness: This is measured through a combination of negative trust signals like scamness and GibberishScore, technical trust factors like a valid SSL certificate (badSslCertificate), and specific quality scores for “Your Money or Your Life” (YMYL) topics (ymy1NewsV2Score, healthScore).
Section 8: Topical Authority – The Mathematics of Niche Expertise
The documentation reveals that Google’s systems go beyond assessing site-wide authority in a general sense; they algorithmically measure a site’s topical expertise with mathematical precision. This provides a data-backed foundation for the long-held SEO strategy of developing deep niche expertise.
Technical Implementation via Leaked Attributes
Two key metrics work in tandem to evaluate a site’s topical relevance:
- siteFocusScore: This attribute quantifies how dedicated a site is to a specific topic. A high score indicates a site that concentrates its content on a well-defined niche, signalling deep expertise to Google’s systems.
- siteRadius: This metric measures how much an individual page’s content deviates from the site’s central theme, as established by the siteFocusScore. A page with a high siteRadius is an outlier, and creating content that strays too far from a site’s core expertise can be detrimental to its ranking potential.
This system reinforces the strategic value of developing deep niche expertise and employing content clustering strategies, such as the hub-and-spoke model. By creating a tightly-knit web of content around a core topic, a site can maximise its siteFocusScore and ensure that new content has a low siteRadius, signalling a high degree of topical authority and coherence to Google.
Section 9: Advanced Concepts – Topicality, Experimentation, and Algorithmic Evolution
The CompressedQualitySignals module not only provides a snapshot of Google’s current ranking priorities but also offers a glimpse into the advanced mechanisms that drive its semantic understanding and its constant, dynamic evolution.
Signals related to topical embeddings reveal how Google moves beyond keywords to a conceptual understanding of content, while a suite of experimental signals lays bare the framework for live, continuous testing of its core algorithms.
Topicality and Semantic Understanding
The topicEmbeddingsVersionedData signal stores versioned data related to topic embeddings.
An embedding is a powerful machine-learning concept where words, sentences, or entire documents are represented as numerical vectors in a multi-dimensional space.
The proximity of these vectors to one another allows a system to mathematically determine semantic similarity. This data allows Google to understand the core topics of a page and, by aggregation, an entire website, fueling crucial parts of the authority calculation.
Live Experimentation and Algorithmic Evolution
A suite of signals, including experimentalQstarDeltaSignal, experimentalQstarSiteSignal, and experimentalQstarSignal are exceptionally revealing. Their purpose is to enable rapid Live Experiments with new components for the Q* quality score system.
Instead of relying on massive, infrequent updates, engineers can inject new experimental signals at serving time, test their impact on a slice of live search traffic, and gather performance data.
This agile framework allows for constant iteration and refinement of the ranking algorithm, fundamentally reframing our understanding of it as a dynamic and living platform for continuous experimentation and self-improvement.
Conclusion: A Unified Model for SEO in the Post-Leak Era
The analysis of Google’s internal ranking documentation provides an unprecedented, evidence-based view into the foundational architecture of its quality systems.
The signals contained within modules like CompressedQualitySignals and QualityNsrPQData are not a random collection of data points; they are a curated, highly optimised set of Google’s most fundamental judgments about a document’s worthiness to rank.
This moves the discipline of SEO beyond public statements and correlation studies into the realm of documented, architectural reality.
Findings
This investigation has yielded several critical conclusions that form the basis of a new, unified model for advanced SEO:
- The Primacy of Site-Level Authority: A document’s ranking potential is fundamentally gated by the overall authority of its host domain, a concept quantified by signals like siteAuthority and the Q* score. This establishes a foundational layer of trust that is difficult and time-consuming to build.
- The Persistence of Content Quality Hygiene: The principles of the Panda update are alive and well, codified in the pandaDemotion signal. This “algorithmic debt” means that a site’s weakest content can suppress the performance of its strongest assets, making continuous content auditing and remediation a critical, ongoing task.
- The Dominance of User Behaviour: The NavBoost system, powered by signals like GoodClicks and LastLongestClicks, serves as the ultimate, reactive arbiter of quality and relevance. It creates a direct and powerful feedback loop where demonstrable user satisfaction is translated into ranking boosts, while dissatisfaction leads to demotions (navDemotion, serpDemotion).
- The Automation of Page Experience and Spam Policies: Google’s guidelines are not mere suggestions; they are algorithmically enforced. Punitive signals for on-page clutter (clutterScore), intrusive interstitials (violatesMobileInterstitialPolicy), and specific spam tactics (anchorMismatchDemotion) act as proactive filters, disqualifying low-quality or manipulative content at the earliest stages of the ranking pipeline.
- The Codification of Abstract Quality: Conceptual frameworks like E-E-A-T and the Helpful Content System are not just guidelines but are enforced by specific, measurable attributes. Signals like contentEffort and siteFocusScore translate abstract ideas like “expertise” and “focus” into quantifiable data points that directly influence rankings.
- The Algorithm as a Dynamic System: The ranking system is a platform for continuous live experimentation. This inherent dynamism means that focusing on durable principles of quality is a far more sustainable strategy than chasing specific, transient ranking factors.

The Virtuous Cycle of Quality
These systems do not operate in isolation but are interconnected in a logical, reinforcing cycle. A successful SEO strategy in the post-leak era is one that seeks to create and amplify this virtuous cycle:
- Foundational Authority (siteAuthority, Q*) provides the initial credibility for a page to be seriously considered by the ranking systems.
- High-Quality, People-First Content (contentEffort) that is topically focused (high siteFocusScore) ensures the page avoids foundational quality demotions like pandaDemotion.
- An Excellent Page Experience (low clutterScore, passing CWV) prevents pre-emptive penalties and creates a frictionless environment that encourages positive user engagement.
- This positive engagement generates strong behavioural signals (GoodClicks, LastLongestClicks) that are measured by NavBoost.
- NavBoost then applies a powerful re-ranking boost, increasing the page’s visibility.
- This increased visibility and demonstrated user satisfaction, over time, contribute back to the site’s foundational authority, reinforcing its siteAuthority and Q* score and making it easier for all content on the domain to rank in the future.
This unified model demands a strategic shift away from siloed tactics and toward the holistic practice of building a genuinely high-quality, authoritative, and user-centric digital asset.
The path to sustainable success lies not in attempting to reverse-engineer a static set of rules, but in deeply understanding and aligning with the enduring principles of quality, authority, and user value that are now documented to be hardwired into the very core of Google’s systems.
Disclosure: I use generative AI when specifically writing about my own experiences, ideas, stories, concepts, tools, tool documentation or research. My tool of choice for this process is Google Gemini Pro 2.5 Deep Research. I have over 20 years writing about accessible website development and SEO (search engine optimisation). This assistance helps ensure our customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was conceived ad edited verified as correct by me (and is under constant development). See my AI policy.
Works cited
- Cassandra: Cracking Down on Web Spam | NO BS Marketplace, accessed October 6, 2025, https://nobsmarketplace.com/google-algorithm-updates/cassandra/
- A Complete History of Google Algorithm Updates – eSEOspace, accessed October 6, 2025, https://eseospace.com/blog/a-complete-history-of-google-algorithm-updates/
- Google’s Leaked CompressedQualitySignals: Advanced SEO …, accessed October 6, 2025, https://www.hobo-web.co.uk/compressedqualitysignals/
- The Definitive Guide to Mobile SEO After the Leak: How Google …, accessed October 6, 2025, https://www.hobo-web.co.uk/the-definitive-guide-to-mobile-seo-after-the-leak-how-google-ranks-your-website/
- Google Fred Algorithm Updates: How They Affect Your SEO Strategy, accessed October 6, 2025, https://www.flexwasher.com/google-fred-algorithm-update/
- Google Panda – Wikipedia, accessed October 6, 2025, https://en.wikipedia.org/wiki/Google_Panda
- Hobo_Technical SEO 2025 (3).pdf
- Google’s Big Daddy Update: Algorithm & Infrastructure Improvements, accessed October 6, 2025, https://www.searchenginejournal.com/google-algorithm-history/big-daddy-update/
- The PerDocData: An SEO’s Strategic Analysis of Google’s Leaked …, accessed October 6, 2025, https://www.hobo-web.co.uk/perdocdata/
- The CompositeDoc: Google’s Core Document Data Structure Leaked – Hobo SEO Auditor, accessed October 6, 2025, https://www.hobo-web.co.uk/compositedoc/
- Google’s Leaked QualityNsrPQData: The Core of Page Quality …, accessed October 6, 2025, https://www.hobo-web.co.uk/qualitynsrpqdata/
- Key Strategic SEO Insights from the U.S. D.O.J. v. Google Antitrust …, accessed October 6, 2025, https://www.hobo-web.co.uk/google-vs-doj/