
Disclosure: Hobo Web uses generative AI when specifically writing about our own experiences, ideas, stories, concepts, tools, tool documentation or research. Our tool of choice for this process is Google Gemini Pro 2.5 Deep Research. This assistance helps ensure our customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was verified as correct. See our AI policy.”
This is a chapter from my new SEO eBook – Hobo Strategic AiSEO – about integrating AI and SEO into your marketing efforts.
This is a forward-looking framework that moves beyond traditional search engine optimisation (SEO) into a new discipline called “Answer Engine Optimisation” (AEO). Not GEO (Generative Answer Optimisation) – which is a marketing gimmick.
Query Fan Out – AKA ‘Multiple Search Autocomplete and Synthesise a Text Answer, negating lots of clicks to websites’.
At the heart of the AISEO evolution – and evolution merging AI, Answer Engine Optimisation and Search Engine Optimisation) lies a powerful technique known as query fan-out, an advanced method employed by artificial intelligence systems to interpret, process, and answer user questions.
This is not a minor update to existing search algorithms but a fundamental reimagining of the relationship between a user’s query and the vast expanse of digital information.
It signals a strategic move by search engines from being directories of information to becoming synthesisers of answers, a shift with profound implications for users, content creators, and businesses alike.
The principle of Query Fan out is not a new “thing” in tech circles, as pointed out by Michael Martinez.

Beyond a Single Search
Query fan-out is a sophisticated information retrieval technique where a single user query is not treated as a standalone request. Instead, an AI system, such as Google’s, effectively “explodes” or “fans out” the initial prompt into a multitude of related, more specific sub-queries.
This process fundamentally alters the traditional search model, which has long been defined by matching a single query to a ranked list of documents.
With query fan-out, the AI system takes on the role of a research assistant, issuing numerous queries simultaneously on the user’s behalf to delve deeper into the web and discover more comprehensive and hyper-relevant content than a single search ever could.
The primary objective of this technique is to move beyond the limitations of simple keyword matching and instead fulfil the user’s underlying, and often unstated, intent with a context-rich, synthesised response.
By anticipating follow-up questions and exploring various facets of a topic, the system aims to create a low-effort, high-value search experience for the user.
This architectural choice directly serves a critical business goal for search providers: to capture more of the user’s information journey by providing a complete answer within the search environment itself, transforming the search engine from a mere waypoint into a final destination.
| Feature | Traditional Search | Query Fan-Out |
| Core Process | Matches a single query to a ranked list of documents based on relevance signals like keywords and links. | Decomposes a single query into multiple sub-queries, retrieves information in parallel, and synthesises a comprehensive answer. |
| User Query | Treats the query as a single, literal request. | Analyses the query for multiple facets, underlying intents, and implicit questions. |
| Data Sources | Primarily relies on the indexed live web. | Queries the live web, knowledge graphs, product feeds, and real-time structured databases (e.g., finance, shopping). |
| Result Format | A ranked list of links (SERP), sometimes with a featured snippet or knowledge panel. | A single, synthesised, conversational answer, often with citations and integrated data from multiple sources. |
| User’s Role | The user is the researcher, required to click through links and synthesise information from multiple sources. | The user is the question-asker; the AI performs the research and synthesis on their behalf. |
| Primary Goal | To provide a list of the most relevant potential sources. | To provide a direct, comprehensive, and contextually rich answer that fulfils the user’s complete intent. |
The Three-Stage Process: A Mechanical Breakdown
The query fan-out mechanism can be understood as a three-stage process that happens behind the scenes in milliseconds. This process transforms an ambiguous or complex user prompt into a precise and comprehensive AI-generated answer.
Stage 1: Query Decomposition and Intent Analysis
The process begins the moment a user submits a query. An AI system, powered by a Large Language Model (LLM) like Google’s Gemini, parses the user’s natural language input.
It goes beyond keywords to analyse the phrasing, identifying the core facets of the topic, the underlying user intents (such as comparing options, exploring a concept, or making a decision), and any implicit needs that were not explicitly stated.
Based on this analysis, the system generates what are known as “synthetic queries” – dozens or even hundreds of distinct sub-queries that target specific aspects of the original prompt.
This decomposition is not random; it is a structured process. Evidence from Google’s patent application US20240289407A1 describes a method called “prompted expansion,” where the LLM is given specific instructions to create a diverse set of queries that exhibit intent diversity (comparing, exploring), lexical variation (synonyms, paraphrasing), and entity-based reformulations (mentioning specific brands or features).
This advanced decomposition is typically reserved for complex, multi-intent, or nuanced prompts; simple factual queries like “capital of Spain” may not trigger an extensive fan-out.
These machine-generated, invisible sub-queries represent a new battleground for content visibility, where success depends not on ranking for the user’s initial query but on being relevant to the hidden queries the AI generates.
Stage 2: Parallel Retrieval from Diverse Sources
Once the sub-queries are generated, they are executed simultaneously – in parallel – across a vast and diverse ecosystem of data sources, extending far beyond the traditional live web index.
This parallel retrieval is a key element of the fan-out’s power, as it allows the system to gather a wide range of information very quickly.
These sources include not only web pages but also highly structured and proprietary databases. For instance, Google’s implementation queries its Knowledge Graph for entity information, its Shopping Graph for real-time product data (which is updated 2 billion times per hour), Google Finance for market data, and other specialised repositories for information like local business listings or flight availability.
This multi-source, parallel execution dramatically expands the pool of information available for constructing the final answer, allowing the system to pull in hyper-relevant data that might reside in specialised databases rather than on a top-ranking webpage.
Stage 3: Synthesis and Answer Generation
In the final stage, the system aggregates the vast amount of information retrieved from all the parallel sub-queries.
The LLM then performs a complex task of reasoning and synthesis. It evaluates the retrieved content using a variety of quality signals, including measures of experience, expertise, authoritativeness, and trustworthiness (E-E-A-T). It then reasons across the disparate pieces of information, connecting dots, comparing facts, and identifying patterns to construct a single, coherent, and comprehensive response.
The final output is not just a collection of snippets but a well-structured, data-packed, and nuanced summary. This synthesised answer is designed to address the original query in its entirety and often goes a step further by preemptively answering the logical follow-up questions the user might have had, providing a more complete and satisfying information experience.
| Component | Description |
| Initial User Query | “What are the best moisturisers for dry skin?” |
| Inferred Intents | Product discovery, ingredient education, suitability for related conditions (e.g., sensitivity), brand comparisons, and application advice. |
| Generated Sub-Queries (Examples) | “best moisturisers for dry skin 2025”, “moisturisers for sensitive dry skin”, “what is hyaluronic acid in skincare”, “ceramides benefits for skin barrier”, “La Roche-Posay vs CeraVe for dry skin”, “ingredients to avoid for sensitive skin”, “how often to apply moisturiser for severe dryness”. |
| Synthesised Answer Snippet | The AI generates a multi-part answer. It might begin with a curated list of top-rated moisturisers, followed by a section explaining key ingredients like hyaluronic acid and ceramides. It could then include a subsection on what ingredients to avoid for sensitive skin and conclude with practical advice on patch testing and application frequency, citing information pulled from various expert and user-review sources. |
The Core Function of Fan-Out
One of the most critical functions of the query fan-out technique is its role in grounding AI-generated responses. Grounding is the process of connecting an AI’s output to verifiable, real-world information, which is the primary defence against the phenomenon of “hallucination,” where an LLM generates plausible-sounding but factually incorrect statements.
Traditional LLMs generate text based on patterns learned from their training data, but without a direct connection to a live, factual source, their output can become outdated or untethered from reality.
Query fan-out directly addresses this weakness.
By casting a wide net with dozens or hundreds of sub-queries, the system is designed to identify and retrieve specific, semantically rich, and citation-worthy “chunks” of content from a diverse set of authoritative sources.10 These chunks serve as the factual building blocks for the final answer.
This process allows the AI to synthesise a comprehensive response that is firmly rooted in factual, verifiable data.
The final generated text is often accompanied by citations or links back to the source pages from which the information was drawn.
This not only increases the trustworthiness and reliability of the AI’s answer but also provides users with a path to explore the source material for deeper context. In this way, query fan-out is not just a method for finding more information; it is a crucial mechanism for ensuring the information found is accurate and reliable.
Query Fan-Out vs. Related AI Paradigms
The term is often used alongside related concepts like query decomposition, multi-agent systems, and retrieval-augmented generation.
While these concepts are interconnected, they are not interchangeable. Understanding their distinct roles and relationships reveals the specific architectural choices and engineering trade-offs that make query fan-out uniquely suited for large-scale web search.
Query Decomposition vs. Query Fan-Out: A Matter of Scope
The terms “query decomposition” and “query fan-out” are closely related, but one is a component of the other.
- Query Decomposition is the specific action of breaking a complex user question into a set of simpler, more manageable sub-questions. It is the first and foundational stage of the fan-out process. Academic research in areas like multi-hop question answering focuses heavily on developing effective decomposition strategies, as the quality of the sub-questions directly impacts the ability to find the correct answer.
- Query Fan-Out refers to the entire, end-to-end information retrieval system. It encompasses the initial query decomposition, but also includes the subsequent stages of parallel information retrieval for all the generated sub-queries and the final synthesis of that information into a single, comprehensive answer.
The FanOutQA benchmark, a dataset developed by researchers to test the capabilities of LLMs, perfectly illustrates this relationship.
The benchmark consists of complex “fan-out questions” that require multi-hop, multi-document reasoning.
A core part of the dataset is the human-annotated decomposition of each fan-out question into a series of simpler sub-questions.21 This demonstrates that decomposition is the necessary first step required to solve the broader fan-out problem. In essence, decomposition is a tactic, while fan-out is the complete strategy.
Multi-Agent Systems (MAS) – A Comparative Analysis
Query fan-out can be viewed as a specific, highly structured implementation of a multi-agent approach, but it differs significantly from the broader and more dynamic concept of a Multi-Agent System (MAS). A MAS is defined as a system composed of multiple autonomous AI agents that collaborate, communicate, and coordinate to solve problems that are beyond the capability of a single agent.
In a query fan-out architecture, the individual sub-queries can be thought of as simple, parallel “sub-agents,” each tasked with a specific information-gathering mission. However, their operation is highly constrained and centrally orchestrated. These sub-agents do not communicate with each other, negotiate tasks, or share learnings during the retrieval process. They execute their instructions in parallel and report their findings back to a central “orchestrator” or “synthesiser” agent, which then assembles the final response.
True Multi-Agent Systems, by contrast, involve far more sophisticated and decentralised interactions. Agents in a MAS may delegate tasks to one another, negotiate over resources, resolve conflicts, and share learned experiences in real-time to adapt their collective strategy. While this offers immense power and flexibility for solving complex, open-ended problems, it also introduces significant challenges in coordination, reliability, and debugging, with some research highlighting the fragility of these systems in production environments.
The choice of a structured fan-out architecture over a more dynamic MAS for a public-facing service like Google Search is a clear engineering trade-off. Search engines must serve billions of users with extremely low latency and high reliability.9 The fan-out model provides the key benefit of a “divide-and-conquer” approach without the immense coordination overhead and potential for cascading failures inherent in a true MAS.29 It is, in effect, a “tamed” multi-agent system, optimised for the specific constraints of web search: speed, scale, and predictability.
Retrieval-Augmented Generation (RAG) – The Symbiotic Relationship
Query fan-out is not an alternative to Retrieval-Augmented Generation (RAG); rather, it is a powerful enhancement of the RAG framework.
RAG is a general architectural pattern designed to improve the quality of LLM-generated answers by first retrieving relevant information from an external knowledge base and then providing that information to the LLM as context for generating its response.
This process helps to ground the LLM’s output in factual, up-to-date information, reducing the risk of hallucination.
Within this framework, query fan-out can be understood as a highly advanced and scalable retrieval mechanism. Instead of a single, simple retrieval step where the system looks for documents matching the user’s initial query, the fan-out process performs a multi-pronged, parallel retrieval. It uses decomposition to identify all the different facets of information needed and then gathers a much richer and more diverse set of contextual documents and data points to feed into the generation stage.
By decomposing the query and pulling from multiple, varied sources, fan-out provides the “Generation” part of the RAG system with a pre-processed, multi-faceted context. This dramatically improves the quality, accuracy, and comprehensiveness of the final answer, making the entire RAG pipeline more robust and reliable.
The academic work on the FanOutQA benchmark provides a valuable, non-proprietary window into the cognitive task that commercial fan-out systems are designed to perform. By studying the structure of these benchmark questions and their human-created decompositions, content strategists can effectively reverse-engineer the process. This allows them to structure their own content to explicitly answer the discrete, fact-based sub-questions that an AI is likely to generate, thereby making their content more “citable” and more likely to be included in a synthesised AI answer.
| Feature | Query Decomposition | Query Fan-Out | Multi-Agent System (MAS) |
| Core Function | The act of breaking a complex question into simpler, answerable sub-questions. | An end-to-end system that decomposes a query, retrieves information in parallel, and synthesises a final answer. | A system of multiple autonomous agents that collaborate, communicate, and coordinate to achieve a common goal. |
| Level of Autonomy | N/A (It is a process, not an agent). | Low. “Sub-agents” (queries) are centrally orchestrated and do not act independently. | High. Agents are autonomous, with their own decision-making capabilities. |
| Communication Model | N/A. | Centralized. Sub-queries report back to a central synthesiser; there is no inter-agent communication. | Distributed and Collaborative. Agents can communicate with each other, negotiate, and delegate tasks. |
| Primary Use Case | A necessary step within more complex reasoning and retrieval tasks (e.g., multi-hop QA). | Large-scale, low-latency information retrieval and answer synthesis (e.g., AI-powered web search). | Solving complex, dynamic problems that require emergent, collaborative behaviour (e.g., supply chain optimisation, robotics). |
| Example | Breaking “Best hotels in Paris with a gym and pool” into “best hotels in Paris,” “Paris hotels with a gym,” and “Paris hotels with a pool.” | Taking the decomposed queries, searching hotel databases and review sites for each in parallel, and generating a summary of the top 3 hotels that meet all criteria. | A team of agents, where one agent books flights, another books hotels, and a third plans activities, all coordinating to create a complete travel itinerary. |
Query Fan-Out in Practice – The Google AI Ecosystem
The abstract concepts of query fan-out and answer synthesis are not merely theoretical; they are the practical engine driving the most significant evolution in Google’s search products in a decade.
Google has explicitly confirmed that query fan-out is the core technology underpinning its new suite of generative AI search features, deploying it in a tiered approach that balances computational power with user intent. An examination of these products, along with the company’s own patents, provides a clear picture of this technology in action.
The Engine of AI Mode and AI Overviews
Query fan-out is the foundational technique for both of Google’s flagship generative search experiences: AI Overviews and AI Mode.
- AI Overviews are the AI-generated summaries that appear at the top of a traditional search engine results page (SERP) for certain queries. These overviews use a fan-out process to gather information from multiple sources and synthesise a concise answer, aiming to quickly satisfy the user’s immediate information need without requiring them to click through to multiple websites.
- AI Mode represents a more immersive and extensive application of the technique. When a user opts into AI Mode, the fan-out process is typically more comprehensive, designed to generate a detailed, conversational response that can serve as a complete replacement for the traditional list of blue links.
Interestingly, the results and sources cited can differ significantly between an AI Overview and an AI Mode response for the exact same query.3 This suggests that the depth and breadth of the fan-out process are tunable and can be adjusted based on the specific product interface and the inferred complexity of the user’s intent.
Deep Search – The Next Frontier of Fan-Out
For the most complex and research-intensive queries, Google has introduced a feature called Deep Search, which represents the most powerful application of the fan-out technique to date.
Where a standard AI Mode query might generate dozens of sub-queries, Deep Search takes this to an entirely new level, issuing hundreds of simultaneous background queries to explore a topic from every conceivable angle.
It is engineered to reason across disparate pieces of information and synthesise the findings into what Google describes as an “expert-level fully-cited report”.
This process is computationally intensive and can take several minutes to complete, which is why it is an opt-in feature rather than the default.
Deep Search is designed to save a user hours of manual research on multifaceted topics, showcasing the immense scalability and potential of the underlying fan-out architecture.
This tiered implementation – from the relatively light AI Overviews to the standard AI Mode and the intensive Deep Search – is a deliberate strategy.
It allows the system to manage its vast computational resources effectively, allocating more power (a wider and deeper fan-out) only when it detects a sufficiently complex user query or when the user explicitly requests a more thorough investigation. This approach optimises cost while still delivering advanced capabilities where they are most valuable.
Evidence from the Source: Insights from Google’s Patents
The strategic importance of query fan-out to Google is underscored by the technical documentation and patent filings that describe its mechanics.
While patents do not confirm the exact implementation of a live product, they provide powerful evidence of the long-term research and development priorities within the company.
- Patent US20240289407A1, “Prompt-based query generation”: This patent filing is particularly revealing. It details a system that uses large language models to perform “prompted expansion,” generating multiple alternative queries from a user’s initial search. The system is specifically instructed to create queries that reflect different user intents, such as comparative (“A vs. B”), exploratory (“how does X work”), or decision-making (“best X for Y”). The patent also describes filtering mechanisms to ensure the generated queries are diverse. This methodology directly mirrors the described mechanics of query decomposition within the fan-out process.
- Patent US12158907B1, “Thematic Search”: This patent describes a system for organising search results into “themes,” with an AI-generated summary provided for each theme. It outlines how a single user query can trigger the generation of multiple sub-queries based on these inferred themes. For example, a query for “moving to Denver” could be fanned out into thematic sub-queries about “neighbourhoods,” “cost of living,” and “things to do”.2 This aligns perfectly with how query fan-out deconstructs a broad topic into its constituent facets to provide a more structured and comprehensive answer.
The integration of Google’s proprietary, real-time data graphs into this process provides a significant and defensible competitive advantage. The fan-out system does not just query the public web; it has direct access to internal Google tools and databases like the Shopping Graph, Google Finance, and flight data.
These are massive, high-value, and constantly updated datasets that competing systems cannot easily replicate. By making these internal tools first-class citizens in the retrieval process, Google’s AI can provide answers that are not only comprehensive but also timely, commercially relevant, and actionable, transforming the search engine into a powerful planning and transactional tool.
Navigating the New Search Landscape
The ascendance of query fan-out as the dominant architecture for AI-powered search is not merely a technical curiosity; it is a seismic event that necessitates a fundamental rethinking of digital content and search engine optimisation (SEO) strategies.
Professionals who fail to adapt to this new reality risk becoming invisible to the very systems designed to find them. The old rules of ranking are being replaced by new principles of reasoning, relevance, and machine readability.
The Obsolescence of the Keyword – From Ranking to Reasoning
For years, the core of SEO has been centred on the keyword—researching terms with high search volume and optimising pages to rank for those specific queries. Query fan-out renders this model dangerously simplistic and increasingly obsolete.11
The new paradigm shifts the focus from keyword matching to topical relevance and AI-driven reasoning.
In a Query Fan-Out World, success is no longer defined by achieving the number one rank for a single, high-value term. Instead, visibility is earned by being a useful and authoritative source for a multitude of semantically related sub-queries that the AI generates behind the scenes.
Content is now evaluated not just on its own merits, but on how well it fits into a larger “reasoning chain” that the AI constructs to answer a user’s complex prompt.
A website might not rank highly for a broad, initial query but could be surfaced as a key source because it provides the single best answer to a specific, niche sub-query generated by the AI.
Consequently, the goal is no longer to be present for a keyword, but to be comprehensively present across an entire topic cluster.
Content Strategy for an AI-First World
To thrive in this new environment, content strategy must evolve from creating pages for humans to read into building knowledge assets for machines to consume. This requires a deliberate focus on depth, structure, and authority.
- Build Topical Authority & Depth: The most effective strategy is to move away from scattered, keyword-focused articles and toward the creation of comprehensive content hubs or topic clusters. The objective is to build a robust semantic foundation that covers a subject and all its related subtopics exhaustively. This involves anticipating and comprehensively answering all the potential follow-up questions a user – or, more importantly, an AI performing research on their behalf – might have about a topic. This approach signals deep expertise and makes a website a one-stop shop for information on a given subject, increasing the probability that its content will be selected to answer one of the many fan-out queries.
- Optimise for “Chunking”: AI systems do not read web pages from top to bottom; they parse them to extract meaningful, standalone “chunks” of information. Content must be structured to facilitate this process. Each paragraph or section should be semantically complete, capable of providing value and making sense even when extracted from the context of the full page. Practical tactics include using clear, question-based semantic headings (H2S, H3S), writing concise paragraphs, and employing scannable formats like bullet points, numbered lists, and structured data (e.g., Schema.org markup). FAQ sections are particularly effective as they are already formatted in the question-and-answer structure that AI systems are looking for.
- Prioritise E-E-A-T and Semantic Richness: The signals of Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T) become paramount, as AI systems are explicitly designed to prioritise content from credible and reliable sources. This means doubling down on best practices like publishing with author bylines, citing credible research, and showcasing firsthand experience. Furthermore, content should be semantically rich, using specific entities (people, places, organisations, products, concepts) that the AI can recognise and connect to its Knowledge Graph. This helps the system understand the context and relationships within the content more accurately.
The rise of query fan-out creates a dynamic where the “rich get richer,” but the definition of “rich” has changed. While sites with established topical authority are well-positioned to benefit, the system also creates new opportunities.
A smaller, highly specialised website can now gain visibility by providing the definitive answer to a very specific sub-query, potentially being cited alongside much larger, more established domains.5 Authority is thus becoming more granular – less about a generic, site-wide score and more about provable, deep expertise on a specific set of interconnected topics.
This forces a convergence of roles that were often siloed: SEO, content strategy, and information architecture must now work in a deeply integrated fashion to produce not just web pages, but machine-readable knowledge assets.
The New Metrics of Success – Beyond the Click
The shift to synthesised AI answers presents a significant measurement challenge. If the AI provides a complete answer directly on the results page, the user may have no reason to click through to the source website, rendering traditional metrics like organic click-through rate (CTR) and page-level traffic less meaningful.
The focus of measurement must therefore shift from page-level performance to topic-level visibility and citation frequency. The new key performance indicator (KPI) is not “did we rank #1 for keyword X?” but “how often is our brand cited as an authoritative source in AI-generated answers across our core topics?”.
This necessitates new analytics approaches and tools.
Marketers and SEOs will need to:
- Monitor AI search platforms directly to see where and how their content is being surfaced.
- Track brand mentions and positive sentiment across the web as indirect signals of authority.6
- Utilise an emerging category of SEO tools designed to simulate the query fan-out process. These tools can analyse a target query, generate likely sub-queries, and assess a website’s content coverage against those queries, identifying gaps and opportunities for improvement.
| Traditional SEO Pillar | The Fan-Out Shift | Actionable Tactics |
| Keyword Research | From single keywords to topic clusters and user journeys. | Map out entire topic ecosystems. Use fan-out simulation tools to identify AI-generated sub-queries. Focus on user intent over search volume. |
| Content Creation | From writing articles to building knowledge assets. | Develop comprehensive content hubs with deep topical coverage. Answer all potential follow-up questions. Prioritise E-E-A-T signals. |
| On-Page Optimization | From keyword density to machine readability (“chunking”). | Use clear semantic HTML (H1, H2, H3). Structure content in scannable, standalone passages. Implement structured data (Schema.org). |
| Link Building/Authority | From link volume to provable topical expertise. | Focus on building a reputation as an authority in a niche. Pursue citations and mentions from other expert sources. Publish original research. |
| Measurement | From keyword rankings and clicks to citation frequency. | Track visibility and mentions within AI-generated answers. Monitor topic-level presence rather than page-level rank. Use content coverage analysis tools. |
Latency, Cost, and Scalability
While query fan-out offers a revolutionary improvement in answer quality, its implementation at a global scale presents formidable engineering challenges.
The decision to break one query into hundreds is not made lightly; it introduces significant complexities related to latency, computational cost, and system stability. Understanding these technical constraints is essential, as they are the primary forces shaping the business strategy and user experience of modern AI search.
The Tail-at-Scale Problem – The Tyranny of the Slowest Task
The single greatest challenge in any large-scale distributed system with high fan-out is managing tail latency. In a system where a single request requires parallel responses from hundreds or thousands of servers, the total response time is not determined by the average response time, but by the response time of the slowest task.
This creates a phenomenon where latency variability is magnified exponentially.
A simple statistical example illustrates the problem: if an individual server has a 99% chance of responding quickly (e.g., under 10ms) and a 1% chance of being slow (e.g., 1 second), a query with a fan-out of just one will be slow only 1% of the time. However, a query with a fan-out of 100 will have a 63.4% chance of being slow (1−0.99100).28 Even one poorly performing server among the hundreds queried is enough to cause a significant delay for the user.
This “tail-at-scale” problem is the core reason why features like Google’s Deep Search, with its fan-out of hundreds of sub-queries, are not the default mode and can take minutes to run.
The trade-off between the comprehensiveness of the answer and the speed of delivery is a direct and unavoidable consequence of this fundamental engineering constraint. The entire tiered product offering – from fast AI Overviews to slow but thorough Deep Search – is a business strategy built around the physical and economic limitations of distributed computing.
The Computational and Financial Costs
Executing a query fan-out is an immensely resource-intensive operation, carrying significant computational and financial costs.
- Computational Cost: Each of the dozens or hundreds of sub-queries consumes CPU cycles, memory, and network bandwidth. When LLM processing is involved in either the decomposition or synthesis stage, the computational load increases dramatically.35 More complex architectures like multi-agent systems, a conceptual cousin of fan-out, are known to be extremely expensive, with some estimates suggesting they use up to 15 times more tokens (and thus, compute) than a standard chat interaction.26
- Financial Cost: This computational burden translates directly into financial expenditure for the service provider. The cost of running the servers, networking equipment, and consuming the electricity required for billions of these complex queries per day is substantial. Cloud services that offer analogous capabilities, such as Amazon Kinesis Data Streams with “enhanced fan-out,” have specific pricing tiers that reflect the high cost of providing dedicated, high-volume throughput to multiple consumers.37 Therefore, the decision of when to trigger a fan-out and how deeply to perform it is not just a technical choice but a critical economic calculation.
Architectural Solutions and Mitigation Strategies
Engineers at companies like Google have developed a sophisticated toolkit of strategies to mitigate the challenges of latency and cost in high fan-out systems. These techniques are designed to make the system “tail-tolerant” without requiring cost-prohibitive over-provisioning of resources.
- Fan-out Aware Resource Allocation: A key principle is to make the system “fan-out aware.” This means the system understands that tasks belonging to a query with a larger fan-out are more critical to the overall latency. It can then dynamically allocate more resources to these tasks to ensure they complete quickly, rather than treating all tasks equally. This is far more efficient than allocating worst-case resources to every single task.28
- Hedged Requests: To combat the problem of a single slow server delaying an entire query, systems can employ “hedged requests.” After sending a request to one server, the client waits for a brief period (e.g., the 95th-percentile expected latency). If a response has not been received, it sends a second, identical request to a replica server. It then uses the result from whichever server responds first and cancels the other request. This simple technique can dramatically shorten the latency tail with only a modest increase in overall system load.36
- Micro-partitioning and Selective Replication: Rather than having one large data partition per machine, systems can break data into thousands of smaller “micro-partitions.” This enables more granular and dynamic load balancing. If a particular piece of data or topic becomes “hot” and is subject to many sub-queries, the system can create additional replicas of just that micro-partition and spread the load across multiple machines without having to rebalance the entire system.
- Reducing Fan-Out Where Possible: Architectural design can also aim to minimise the degree of fan-out required in the first place. For example, maintaining a single, larger, and more efficient index on each replica can be more performant than fanning out a query to many smaller, segmented indices that each need to be queried independently.38
The future evolution of query fan-out will be defined by the tension between the desire for more sophisticated AI reasoning and the need to manage the escalating costs of retrieval.
As LLMs become more capable, they will enable more advanced query decomposition, creating a demand for even wider and deeper fan-outs to gather more nuanced evidence. However, the exponential impact on latency and cost will remain a hard constraint.
Therefore, the next wave of innovation will likely focus on efficiency: developing smarter decomposition models that require fewer sub-queries to achieve the same result, creating more efficient indexing and retrieval technologies, and building more robust tail-tolerant infrastructure.
The future is not just about a wider fan-out, but a smarter one.
Summary
Query fan-out is not merely an incremental improvement in search technology; it represents a fundamental architectural and philosophical shift in how machines mediate our access to information.
By deconstructing a single user prompt into a swarm of parallel, targeted inquiries and synthesising the results into a single, comprehensive answer, AI systems are transitioning from their traditional role as digital librarians to that of autonomous research assistants.
This transformation, driven by the practical application of advanced concepts from multi-agent systems and retrieval-augmented generation, is reshaping the digital landscape.
For users, this shift promises a more intuitive, efficient, and powerful information discovery experience, where complex questions are answered directly and follow-up needs are anticipated and met preemptively. However, this convenience comes at the cost of immense engineering complexity.
The technical challenges of tail latency and computational cost at a global scale are non-trivial, and they are the primary constraints shaping the design and business models of AI-powered search products. The tiered approach seen in the market, from lightweight overviews to intensive deep-dives, is a direct reflection of the necessary trade-offs between answer quality, speed, and economic viability.
For professionals in content creation, marketing, and SEO, the rise of query fan-out is a call to action. The era of optimising for a single keyword is ceding to a new imperative: building deep, authoritative, and machine-readable knowledge bases.
Success in this new paradigm will not be measured by clicks or rankings in a list, but by the frequency with which one’s content is deemed trustworthy and relevant enough to be cited as a source in an AI-synthesised reality.
This requires a strategic convergence of technical SEO, content architecture, and deep subject matter expertise, focused on creating content that is not just engaging for humans but is also structured for consumption by the AI agents that now stand between us and the web. The fan-out revolution is here, and it demands a new way of thinking about what it means to be visible online.
From a traditional SEO point of view, the rise of query fan-out represents a fundamental and disruptive shift away from established practices.
The old model of “Keyword → Content → Ranking” is being replaced by a more complex system where success is determined by reasoning, topical authority, and machine readability.
Here is a breakdown of what this means for a traditional SEO professional:
1. The Obsolescence of the Single Keyword
The core of traditional SEO has been identifying and ranking for specific, high-volume keywords. Query fan-out makes this approach dangerously simplistic.
- From Matching to Reasoning: Search is no longer about matching a user’s query to a page with the right keywords. Instead, an AI deconstructs the query into dozens of hidden sub-queries and reasons across multiple sources to build an answer. Your content is now judged on how well it fits into this larger “reasoning chain”.
- Competing for Hidden Queries: You are no longer competing to rank for one keyword. You are competing to be relevant across an entire constellation of related queries that users never even see. Visibility is now earned by providing the best answer to one of the AI’s many specific, machine-generated sub-queries.
2. A New Content Strategy: From Pages to Knowledge Assets
Content strategy must evolve from creating articles for humans to read into building structured knowledge assets for machines to consume and cite.
- Topical Authority over Keyword Density: The most effective strategy is to build comprehensive topic clusters or content hubs. Instead of scattered articles, the goal is to cover a subject and all its related subtopics so exhaustively that your site becomes a one-stop shop for the AI’s research on that topic.
- Optimise for “Chunking”: AI systems retrieve information in “chunks”—semantically complete passages, paragraphs, or sections—not entire pages. Content must be structured for this:
- Use clear, question-based headings (H2S, H3S).
- Write concise paragraphs that can stand alone and make sense out of context.
- Use scannable formats like bullet points, lists, and especially FAQ sections, which are already in the question-answer format that AI systems look for.
- E-E-A-T is Paramount: Signals of Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T) are more critical than ever. The AI is explicitly designed to prioritise and cite content from credible, authoritative sources.
3. The New Metrics: Citations over Clicks
The shift to AI-synthesised answers directly on the results page means other metrics are on the rise.
- The Decline of the Click: If a user gets a complete answer without leaving Google, metrics like organic click-through rate (CTR) and page rankings become less relevant.
- The Rise of the Citation: The new key performance indicator (KPI) is not whether you rank #1, but how often your brand or content is cited as a source in an AI-generated answer. Success is measured by topic-level visibility and citation frequency. Unlinked brand mentions and positive sentiment across the web also grow in importance as indirect signals of authority.
Actionable Takeaways for SEOs:
- Rethink Research: Move beyond traditional keyword research. Use emerging tools that simulate the fan-out process to identify likely sub-queries and understand the full user journey.
- Build Comprehensively: Focus on building deep topical authority. Map out entire topic ecosystems and create content that anticipates and answers every potential follow-up question.
- Structure for Machines: Audit and restructure existing content to be easily “chunked” by AI systems. Ensure every passage is semantically rich and can provide value on its own.
- Track What Matters: Shift analytics focus from page-level rankings to topic-level presence and citation frequency within AI answers.
Google has been fanning out queries since 2004
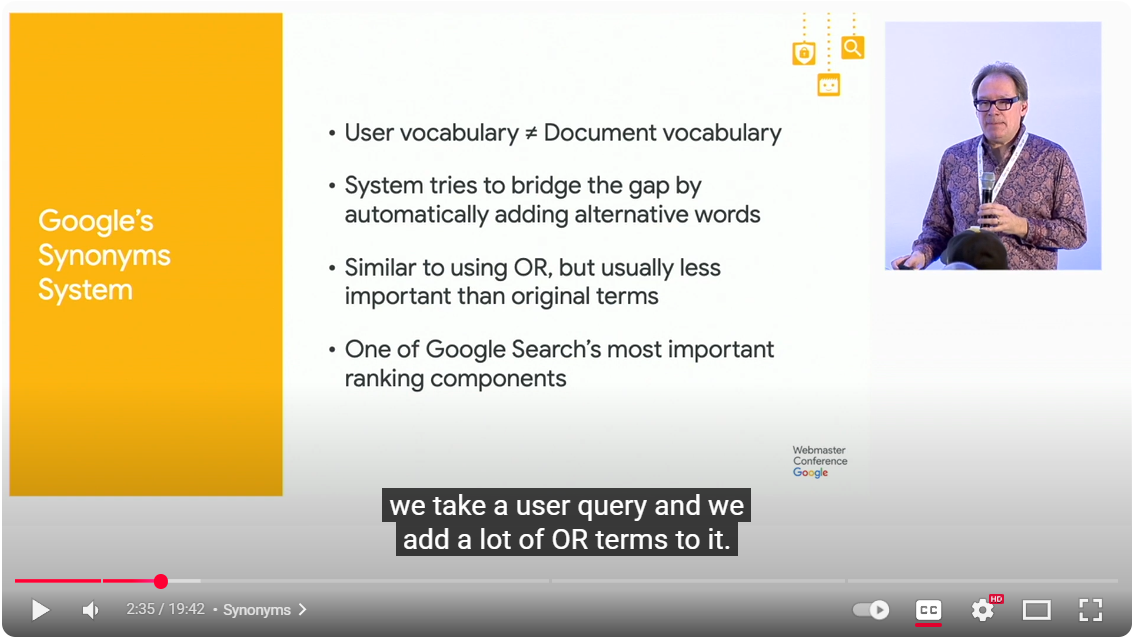
I thought this was worth adding. And also, the following about Google’s Synonym Systems, in a talk from 2019, that sounds a lot like Google Search connected to some type of query fan out. Was this why we needed to add all those synonyms? At first, we had to do it on a page. Now we have to do it on a site (and perhaps even beyond)?
In the video “Improving Search Over the Years (WMConf MTV ’19),” the speaker Paul Haahr, Distinguished Engineer for the Google Search Team, discusses the synonym system [01:39], which he describes as effectively adding “or” terms to a user’s query [02:07]. He explains that this system bridges the gap between user vocabulary and document vocabulary [01:50].
He provides the example of the query “cycling tours in Italy” [02:51], which the system expands to search for “cycling or cycle or bicycle or bike or biking” for “cycling,” and “tour or holidays or vacation” for “tours,” and “Italy or Italian” for “Italy” [02:51]. He emphasises that the synonym system is one of Google’s “most important ranking components”, launched over 15 years prior to the talk [02:36] which makes it 2004
The speaker also clarifies that synonyms are not straightforward rewrites and are done in the context of the full query [03:31]. For instance, “GM” can turn into “General Motors” in the context of trucks, but “general manager” in the context of baseball [03:43].
You can watch the full video here: https://www.youtube.com/watch?v=DeW-9fhvkLM

Want to see how query fan out works in practice? – Use AI to check your visibility in AI answer engines and chatbots.
References:
- www.kopp-online-marketing.com, accessed August 7, 2025, https://www.kopp-online-marketing.com/from-query-refinement-to-query-fan-out-search-in-times-of-generative-ai-and-ai-agents#:~:text=Query%20fan%2Dout%20is%20an,queries%20simultaneously%20on%20their%20behalf.
- Query fan-out in Google AI mode – Hall, accessed August 7, 2025, https://usehall.com/guides/query-fan-out-ai-mode
- Understanding Query Fan-Out in Google’s AI Mode – Marie Haynes Consulting, accessed August 7, 2025, https://www.mariehaynes.com/ai-mode-query-fan-out/
- Google’s Query Fan-Out Technique and What SEOs Should Know About It – Ethan Lazuk, accessed August 7, 2025, https://ethanlazuk.com/blog/googles-query-fan-out/
- How Google’s AI Mode ‘query fan-out’ affects your SEO – ContentGrip, accessed August 7, 2025, https://www.contentgrip.com/google-ai-mode-query-fan-out/
- Google AI Mode’s Query Fan-Out Technique: What is it & How Does it Mean for SEO?, accessed August 7, 2025, https://www.aleydasolis.com/en/ai-search/google-query-fan-out/
- Query Fan Out in Google AI Mode: Optimize with Niara’s New Free Tool, accessed August 7, 2025, https://niara.ai/en/blog/google-query-fan-out/
- WTF is “query fan-out” in Google’s AI mode? – Digiday, accessed August 7, 2025, https://digiday.com/media/wtf-is-query-fan-out-in-googles-ai-mode/
- Query Fan-Out Technique in AI Mode: New Details From Google – Search Engine Journal, accessed August 7, 2025, https://www.searchenginejournal.com/query-fan-out-technique-in-ai-mode-new-details-from-google/552532/
- From Query Refinement to Query Fan-Out: Search in times of …, accessed August 7, 2025, https://www.kopp-online-marketing.com/from-query-refinement-to-query-fan-out-search-in-times-of-generative-ai-and-ai-agents
- AI Mode & Fan-out Query Explained — Concept, Impact & Tactics – Link Building HQ, accessed August 7, 2025, https://www.linkbuildinghq.com/blog/ai-mode-fan-out-query-explained-concept-impact-tactics/
- AI Mode Query Fan Out: How to Optimize Content for Google’s AI – Writesonic, accessed August 7, 2025, https://writesonic.com/blog/ai-mode-query-fan-out
- The Rise of Multi-Agent Systems in Complex Data Environments | by Claudionor Coelho, accessed August 7, 2025, https://medium.com/@nunescoelho/the-rise-of-multi-agent-systems-in-complex-data-environments-5458430dc2d0
- Retrieval-Augmented Generation for Large Language Models: A Survey – arXiv, accessed August 7, 2025, https://arxiv.org/pdf/2312.10997
- Query Fan-Out: A Data-Driven Approach to AI Search Visibility – WordLift Blog, accessed August 7, 2025, https://wordlift.io/blog/en/query-fan-out-ai-search/
- SEO for AI Search: Introducing the Query Fan-Out Tool, accessed August 7, 2025, https://locomotive.agency/blog/rethinking-seo-for-ai-search-introducing-locomotives-query-fan-out-tool/
- How the user search journey has gone from query stacking to query fanning – Oncrawl, accessed August 7, 2025, https://www.oncrawl.com/general-seo/how-user-search-journey-gone-from-query-stacking-query-fanning/
- [2506.13380] Decompositional Reasoning for Graph Retrieval with Large Language Models, accessed August 7, 2025, https://arxiv.org/abs/2506.13380
- POQD: Performance-Oriented Query Decomposer for Multi-vector retrieval – arXiv, accessed August 7, 2025, https://arxiv.org/html/2505.19189v1
- Why LLM Query Fanout is Breaking Traditional SEO – Priority Pixels, accessed August 7, 2025, https://prioritypixels.co.uk/blog/why-llm-query-fanout-is-breaking-traditional-seo/
- [2402.14116] FanOutQA: A Multi-Hop, Multi-Document Question Answering Benchmark for Large Language Models – arXiv, accessed August 7, 2025, https://arxiv.org/abs/2402.14116
- FanOutQA: Multi-Hop, Multi-Document Question Answering for Large Language Models, accessed August 7, 2025, https://arxiv.org/html/2402.14116v1
- FanOutQA: A Multi-Hop, Multi-Document Question … – ACL Anthology, accessed August 7, 2025, https://aclanthology.org/2024.acl-short.2.pdf
- What is a Multi-Agent System? | IBM, accessed August 7, 2025, https://www.ibm.com/think/topics/multiagent-system
- How Multi-Agent Systems Solve Complex Problems – Creaitor, accessed August 7, 2025, https://www.creaitor.ai/blog/multi-agent-systems
- How we built our multi-agent research system \ Anthropic, accessed August 7, 2025, https://www.anthropic.com/engineering/built-multi-agent-research-system
- Don’t Build Multi-Agents – Cognition, accessed August 7, 2025, https://cognition.ai/blog/dont-build-multi-agents
- A Tail Latency SLO Guaranteed Task Scheduling … – CSE SERVICES, accessed August 7, 2025, https://ranger.uta.edu/~jiang/publication/Journals/2025/IEEE-TPDS(TailGuard).pdf
- AgentGroupChat-V2 : Divide-and-Conquer Is What LLM-Based Multi-Agent System Need, accessed August 7, 2025, https://arxiv.org/html/2506.15451v1
- AI in Search: Going beyond information to intelligence – Google Blog, accessed August 7, 2025, https://blog.google/products/search/google-search-ai-mode-update/
- AI Features and Your Website | Google Search Central | Documentation, accessed August 7, 2025, https://developers.google.com/search/docs/appearance/ai-features
- How AI Search REALLY WORKS (Free Query Fan-Out AI Coverage Tool by Tyler Gargula), accessed August 7, 2025, https://www.youtube.com/watch?v=-eEoIW_COog
- AI Is Taking Over Your Search Engine. Here’s What It’s Doing and …, accessed August 7, 2025, https://www.cnet.com/tech/services-and-software/ai-is-taking-over-your-search-engine-heres-what-its-doing-and-why-it-matters/
- AI Search Study: Understanding Keyword Query Fan-out – Surfer SEO, accessed August 7, 2025, https://surferseo.com/blog/keyword-query-fan-out-research/
- Moolle: Fan-out Control for Scalable Distributed Data Stores – LinkedIn, accessed August 7, 2025, https://content.linkedin.com/content/dam/engineering/site-assets/pdfs/ICDE16_industry_571.pdf
- The Tail at Scale – Communications of the ACM, accessed August 7, 2025, https://cacm.acm.org/research/the-tail-at-scale/
- Cost optimization in analytics services – Cost Modeling Data Lakes for Beginners, accessed August 7, 2025, https://docs.aws.amazon.com/whitepapers/latest/cost-modeling-data-lakes/cost-optimization-in-analytics-services.html
- Cost-Effective, Low Latency Vector Search with Azure Cosmos DB – arXiv, accessed August 7, 2025, https://arxiv.org/html/2505.05885v2