
Download Strategic SEO 2025 (V2) – A free ebook in PDF format. Published on: 10 July 2025 at 05:57
This is a guide for professional SEO (Search Engine Optimisation), first published in July 2025.
This book offers an advanced strategic guide for SEO professionals, leveraging primary source evidence like DOJ trial testimony, Google’s patents, and recent data leaks to deconstruct the actual systems defining search ranking in 2025.
It reveals that Google’s ranking system is not a monolithic algorithm but a multi-stage pipeline of distinct, modular systems, including Topicality (T), Navboost, and Quality (Q), which are refined by user behaviour data.
The text highlights a shift in Google’s ranking methodology toward brand authority, user experience, and entity recognition, challenging the previous understanding of SEO.
It also critically examines the impact of zero-click search and AI Overviews, discussing the ongoing legal battles and providing a new framework for SEO success in a post-leak environment, where visibility and influence become more crucial than traditional clicks.
Strategic SEO 2025 FAQ
1. How have the U.S. v. Google antitrust trial and the Content Warehouse leak changed our understanding of Google’s search ranking?
The U.S. v. Google antitrust trial and the Content Warehouse leak (early 2024) have fundamentally rewritten the understanding of Google’s search ranking system. Previously, Google maintained significant secrecy, often publicly dismissing or being evasive about certain ranking factors. However, sworn testimonies from Google’s top engineers and executives during the DOJ trial, along with the accidental leak of internal API documentation, forced unprecedented disclosures.
Key revelations include:
- Confirmation of Core Ranking Systems: The trial revealed a modular, multi-stage ranking pipeline composed of distinct, “hand-crafted” systems like Topicality (T*), Quality Score (Q*), and Navboost, rather than a single, monolithic AI algorithm.
- Centrality of User Interaction Data: Despite previous public evasiveness, it was confirmed that user click data (including dwell time, “good” vs. “bad” clicks, and “last longest clicks”) is a foundational signal for both T* and the powerful Navboost system. The Navboost system specifically analyses 13 months of aggregated user click data to refine rankings.
- Existence of a Site-Level Authority Score: Google’s long-denied “domain authority” equivalent was revealed as Q* (Quality Score), an internal, largely static, query-independent metric assessing a website’s overall trustworthiness and quality. PageRank is a key input to Q*.
- Role of Machine Learning: ML systems like RankBrain and DeepRank are used for specific, complex tasks like query interpretation, not as an all-encompassing “ranking brain.” Google actively strives for transparency and control even over these complex systems, preferring hand-crafted signals for foundational elements.
- New Site “Sandbox”: The concept of a “sandbox” for new websites, previously denied, was validated by the “hostAge” attribute, which is used to “sandbox fresh spam.” This means new sites face an initial probationary period.
- Strategic Obfuscation: The collective evidence demonstrated a deliberate gap between Google’s public narrative and its internal reality, suggesting strategic obfuscation to protect the integrity of search results (e.g., by not openly admitting to click-based ranking to prevent manipulation).
2. What are the core components of Google’s search ranking architecture as revealed by these disclosures?
Google’s search ranking architecture is a sophisticated, multi-stage pipeline, far from a single algorithm. The key components revealed are:
- Topicality (T)*: This hand-crafted system determines a document’s direct relevance to query terms. It’s based on “ABC signals”:
- A (Anchors): Derived from the anchor text of hyperlinks pointing to the document, indicating what other sites say it’s about.
- B (Body): Based on the presence and prominence of query terms within the document’s content.
- C (Clicks): Derived from user behaviour, specifically how long a user dwelled on a clicked page before returning to the SERP.
- Quality Score (Q)*: This is an internal, largely static, query-independent metric that assesses the overall trustworthiness and quality of a website or domain. It’s a hand-crafted score influenced by PageRank (measuring “distance from a known good source” or trusted “seed” sites) and other factors like site reputation. Q* acts as a site-level authority score that can significantly boost or dampen a site’s rankings.
- Navboost: This powerful, data-driven system refines rankings based on 13 months of aggregated historical user satisfaction. It analyses various click metrics like “good clicks” (successful interactions), “bad clicks” (pogo-sticking), and “last longest clicks” (the final, satisfying result in a search session). Navboost dramatically filters down the initial set of relevant documents from tens of thousands to a few hundred.
- RankBrain: An early machine learning (ML) system, its primary function is to interpret novel, ambiguous, and long-tail search queries. It’s trained on historical search data (not live user data) to understand user intent beyond simple keyword matching.
- BERT-based RankEmbed: A more advanced deep learning model, integrated in 2019, that significantly enhances Google’s understanding of language context. It converts queries and documents into mathematical vectors (embeddings) to determine semantic similarity, especially useful for complex and conversational searches.
- Twiddlers: These are re-ranking functions that adjust the order of search results after initial ranking by systems like Mustang. Navboost is a prominent Twiddler, but others like FreshnessTwiddler, QualityBoost, and RealTimeBoost also fine-tune results based on various criteria.
- HostAge: An attribute that validates the “Google Sandbox” theory, indicating that new domains are treated with algorithmic suspicion and “sandboxed” to prevent fresh spam until they establish credibility.
3. What is the “Disconnected Entity Hypothesis” and how does it relate to Google’s E-E-A-T and Helpful Content Updates?
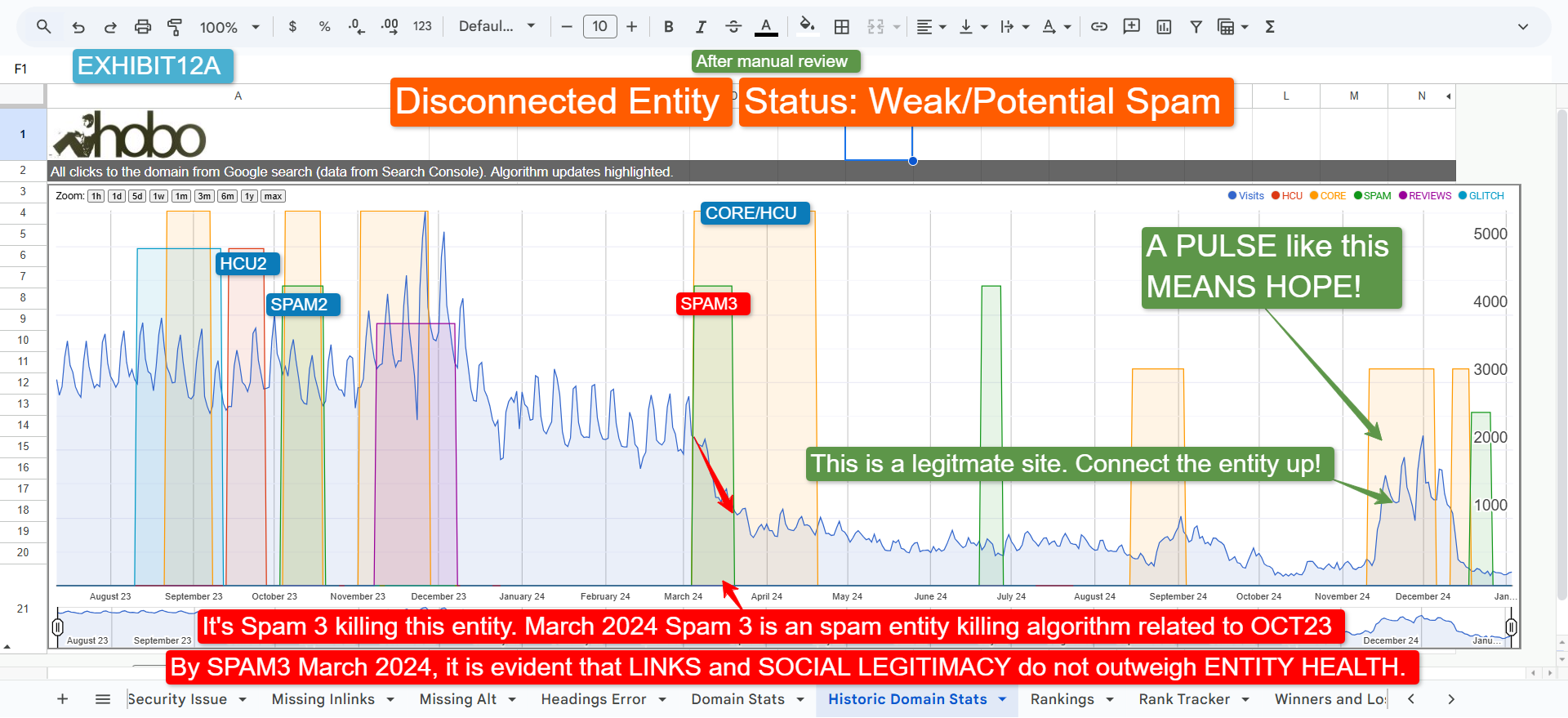
The “Disconnected Entity Hypothesis” (DEH) posits that Google classifies some websites as “unhealthy” or “disconnected” entities when they lack sufficient transparency and trust signals linking them to a credible real-world entity. This leads to ranking declines, even for sites with otherwise good content or links. Such sites are treated as if Google cannot “vouch for” them, limiting their visibility.
This hypothesis directly relates to Google’s E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) framework and the Helpful Content Updates (HCU):
- E-E-A-T and Trust: Google’s Search Quality Rater Guidelines (QRG) explicitly state that “Trust is the most important member of the E-E-A-T family,” as untrustworthy pages are deemed to have low E-E-A-T regardless of other qualities. The QRG emphasises the need to “Find Who is Responsible for the Website and Who Created the Content on the Page” (Section 2.5.2). A site becomes “disconnected” when it fails this fundamental transparency test, lacking clear information about its owner, authors, or purpose.
- Helpful Content Updates (HCU): Launched in 2022 and integrated into the core algorithm by March 2024, HCU targets “search engine-first” content – material created primarily for ranking rather than genuinely helping users. The DEH suggests that a lack of trust, stemming from an unclear entity behind the site, causes content to be deemed “unhelpful” by Google’s systems, even if the content itself is well-written. Google’s algorithms struggle to “detect” the helpfulness of content from an untrusted, anonymous source.
- Impact on Small Businesses: Many small publishers impacted by HCU reported having good content but still saw severe traffic drops. The DEH implies that these sites were caught in the crossfire not due to content quality alone, but because they lacked strong, verifiable entity signals. Google prioritises “authoritative, reliable search results,” and without clear entity identification, a site cannot fully demonstrate these qualities.
In essence, DEH argues that Google’s ranking systems might apply an “Entity Health Status” filter before considering other signals like links or content relevance. A site perceived as a “Disconnected Entity” faces an uphill battle to rank, as Google is increasingly prioritising content from identifiable, accountable sources to safeguard user trust and its own reputation.
4. What is “Zero-Click Search” and “Zero-Click Marketing,” and why are they causing a “Digital Cold War” in the industry?
- Zero-Click Search (ZCS): This refers to the user behaviour where a search query is fully answered directly on the search engine results page (SERP), eliminating the need for the user to click through to an external website. This phenomenon is driven by Google’s deliberate design choices, such as Featured Snippets, Knowledge Panels, Direct Answer Boxes, Local Packs, People Also Ask (PAA) features, and most recently, AI Overviews (AIOs).
- Zero-Click Marketing (ZCM): This is the strategic response to ZCS. Popularised by Rand Fishkin, it’s the practice of creating standalone value directly within platforms like Google’s SERP, YouTube, or social media, with the goal of building brand awareness, influence, and community, independent of generating website clicks. It shifts the focus from driving traffic to being the definitive answer or resource where users are.
This distinction highlights a “Digital Cold War” because these trends are causing a deep schism in the industry:
- The Critics’ View (Zero-Click Searches): Publishers, content creators, and many businesses whose models depend on website traffic view ZCS as an existential threat. They argue that Google is “stealing” their content, “cannibalising website visits,” and “asphyxiating organic traffic” by providing answers directly on the SERP without compensation or referral clicks. This impacts advertising revenue, lead generation, and affiliate sales. They accuse Google of monopolistic abuse, building a “walled garden” to keep users within its ecosystem and hoarding revenue. The lack of a true opt-out (without becoming invisible) is seen as coercive.
- The Proponents’ View (Zero-Click Marketing): Marketers and strategists who embrace ZCM argue that fighting ZCS is futile. They see it as an unavoidable evolution where influence and brand building are more critical than raw clicks. They contend that zero-click features act as a filter, delivering higher-quality, more qualified traffic to websites when clicks do occur, as low-intent users are satisfied on the SERP. Appearing in AI Overviews or Featured Snippets, even without a click, builds brand familiarity and credibility, positioning the brand as an authority for future, higher-intent actions. They advocate for optimising for on-SERP visibility and building direct audience relationships (e.g., email lists) to become click-independent.
The “cold war” reflects these opposing economic models and philosophical outlooks on the future of the open web and how information is discovered and monetised.
5. What are the practical steps webmasters should take to improve their “Site Quality Score” and align with Google’s E-E-A-T principles?
To improve a site’s “Site Quality Score” (Q*) and align with Google’s E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) principles, webmasters should focus on building genuine credibility and transparency:
- Audit and Improve/Remove Low-Quality Content: Identify and prune or significantly enhance “thin,” redundant, or unhelpful pages. Low-quality content across a site can drag down its overall quality score. Focus on creating comprehensive, unique, and valuable resources.
- Focus on E-E-A-T (Especially Trust):
- Clear Identity: Explicitly state who owns and operates the website (e.g., through a detailed “About Us” page with legal/editorial ownership, contact info, and company registration details).
- Author Transparency: For content with a discernible author, include clear bylines linking to dedicated author pages that detail their background, qualifications, and experience. Avoid anonymity or fake personas.
- Contact Info: Provide easily accessible contact information (email, phone, physical address if applicable), particularly for YMYL (Your Money or Your Life) topics or e-commerce sites, to signal accountability.
- Content Accuracy & Transparency: Ensure content is factually correct, well-sourced, and cites evidence. For reviews, disclose testing methods. If AI is used, be transparent where appropriate (e.g., using AI disclaimers).
- User Safety: Implement HTTPS, secure payment systems (for e-commerce), and clear privacy policies to demonstrate site security and professionalism.
- Provide Substantial, Valuable Content: Every page should deliver unique value, offering original research, insightful analysis, and comprehensive descriptions rather than just rehashing existing information. Aim to satisfy the user’s query thoroughly.
- Improve User Experience (UX): Optimise for fast page load times, intuitive navigation, and clean layouts. Avoid excessive or intrusive advertising that detracts from content. Good UX leads to longer dwell times and fewer “bad clicks,” signalling user satisfaction to Navboost.
- Build External Reputation: Encourage positive mentions and reviews on authoritative platforms (Google Business Profile, industry-specific sites). Earn legitimate backlinks from respected sites, not merely for “link juice” but as a signal of third-party endorsement and credibility.
- Implement Structured Data: Use Schema.org markup (e.g., Organization, Person, LocalBusiness) to explicitly define your entity for search engines. Include sameAs links to official profiles (social media, Crunchbase, Wikidata) to help Google corroborate your identity across the web.
- Be Patient and Consistent: Recovering from quality issues or building trust takes time. Continuously implement these best practices, and anticipate that algorithm re-evaluations (often coinciding with core updates) can take weeks or months to reflect improvements.
These steps collectively address the “Disconnected Entity Hypothesis” by making it clear to Google who you are, what your expertise is, and why your content should be trusted.
6. What is “Entity SEO” and why is it becoming increasingly important for businesses, especially small ones?
“Entity SEO” is the practice of optimising your online presence to help Google recognise and understand your business, brand, person, or concept as a distinct, uniquely identifiable “entity” within its Knowledge Graph. An entity is a “thing” with an ID number in Google’s database, allowing Google to connect words to real-world concepts.
Entity SEO is crucial for businesses, especially small ones, for several reasons:
- Building Trust (E-E-A-T): Google’s algorithms (like Q*) and quality raters prioritise content from trustworthy, authoritative entities. If Google cannot confidently identify the real-world entity behind your website (e.g., a person or company with verifiable credentials), it’s less likely to trust and rank your content. Entity SEO provides the signals Google needs to “vouch for” your business, overcoming the “Disconnected Entity Hypothesis.”
- Semantic Understanding: Google has shifted from “strings” (keywords) to “things” (entities). Understanding your content semantically requires recognising the entities discussed within it. By making your business a known entity, Google can better understand your topical authority across your niche.
- Competitive Equaliser: For small businesses, Entity SEO can level the playing field against larger brands with bigger budgets or established domain authority. By clearly defining your identity, expertise, and trustworthiness, you can signal to Google that you are a legitimate, authoritative source in your specific niche, regardless of traditional metrics.
- Improved Visibility: Being recognised as an entity can lead to enhanced visibility in Google’s SERP features, such as Knowledge Panels, Featured Snippets, and AI Overviews, which provide direct answers and influence users even without a click.
- Resilience to Algorithm Updates: Sites with strong, verifiable entity status are often more resilient to broad core updates (like the Helpful Content Updates) that penalise unhelpful or untrustworthy content. Google aims to reward “healthy” entities with a clear “trail of trust.”
Practical steps for Entity SEO include securing presence in authoritative databases (Google Business Profile, Wikidata, industry registries), designating an “Entity Home” on your website with schema markup (Organization, Person, sameAs links), building cohesive topical content structures, optimizing on-page content semantically (covering related entities and user intents), and highlighting authors and E-E-A-T signals.
7. How has the Helpful Content Update (HCU) impacted content strategies and small businesses, and what lessons can be learned?
The Helpful Content Update (HCU), launched in August 2022 and integrated into Google’s core algorithm by March 2024, has had a profound and often devastating impact on content strategies and many small businesses, marking a significant shift in Google’s priorities.
Impact:
- Demotion of “Search Engine-First” Content: HCU explicitly targets content created primarily to rank rather than to genuinely help users. This led to significant drops (20-90% organic traffic loss) for sites churning out generic, low-value, or anonymous SEO-driven articles, including many affiliate blogs and content farms.
- Site-Wide Effect: HCU is a site-wide signal. If a large portion of a website is deemed “unhelpful,” the entire domain’s rankings can be held back, even for its good pages.
- Difficult Recovery: Recovery from HCU is intentionally slow and challenging. Google’s stance is that it requires fundamental changes to a site’s overall content philosophy and approach, not just minor fixes. Many affected publishers have reported little to no recovery even after months or years, leading to immense frustration and even site abandonment.
- Prioritisation of Trust and E-E-A-T: HCU strongly emphasises E-E-A-T, particularly “Trust.” Sites that lack transparency about their ownership, authors, or purpose (i.e., “Disconnected Entities”) are likely to be flagged as unhelpful, regardless of content quality.
- Shift in Ranking Preferences: HCU implicitly favors genuine expert sites, community forums (like Reddit), and content demonstrating first-hand experience over anonymous or generic content.
Lessons Learned:
- “People-First” Content is Paramount: The core lesson is to create content genuinely for users, solving their problems and providing a satisfying experience, rather than for search engines.
- Trust and Entity are Foundational: A site must clearly establish who is behind the content (authors, organisation) and demonstrate verifiable expertise and authority. Lack of identity transparency is a critical “trust killer.”
- Quality Over Quantity: Mass-producing low-value content is a losing strategy. Focus on fewer, high-quality, comprehensive pieces that truly stand out in your niche.
- User Experience is SEO: Beyond content, good UX (fast loading, clear design, low ad density) keeps users engaged, sending positive signals to Google’s Navboost system.
- Diversification is Key: Relying solely on Google organic traffic is risky. Small businesses need to diversify their traffic sources (e.g., email lists, social media, other platforms) to build a resilient online presence.
- Patience and Persistence: For sites impacted by HCU, recovery is a long-term commitment requiring consistent effort to align with Google’s updated quality expectations.
Ultimately, HCU signals Google’s commitment to surfacing content from authentic, accountable, and helpful sources, fundamentally reshaping the expectations for web publishers.
8. What is Google’s stance on using copyrighted material for AI training, and why is this a significant legal battle?
Google’s stance on using copyrighted material to train its AI models, particularly for features like AI Overviews, is rooted in the legal doctrine of “fair use.”
Google’s Position:
- “Not Stealing”: Google unequivocally argues that “Using publicly available information to learn is not stealing. Nor is it an invasion of privacy, conversion, negligence, unfair competition, or copyright infringement.”
- “Transformative Use”: They contend that training an AI model on copyrighted material constitutes a “transformative” use. Under U.S. copyright law, a transformative use is one that changes the original work in a way that creates new expression, meaning, or purpose, making it eligible for the fair use defence. Google asserts that it is not simply re-publishing the original work but using it as raw material to create something fundamentally new – an AI model capable of generating novel responses.
- Existing Controls: Google also points to existing technical tools like robots.txt files and snippet control meta tags (nosnippet, max-snippet) as mechanisms by which publishers can control how their content is made available to Google.
Why it’s a Significant Legal Battle:
This is a high-stakes legal conflict with monumental, far-reaching implications for the digital economy and the future of creative industries:
- Uncompensated Ingestion: Publishers and content creators (including news organisations and education tech companies like Chegg) are filing lawsuits, alleging that Google’s unauthorised scraping of their work for AI training constitutes mass copyright infringement and “unjust enrichment.” They argue that Google is profiting from their content without providing compensation or meaningful attribution.
- “No Choice” Dilemma: Critics highlight that Google explicitly considered offering publishers a true opt-out for AI training but decided against it, creating a “hard red line.” This leaves publishers with a Hobson’s choice: allow their content to be used to train Google’s AI (and potentially appear in zero-click AI Overviews, reducing direct traffic) or block Google’s crawlers, effectively becoming invisible on the world’s largest search platform. This is seen as an anticompetitive tying arrangement imposed by a monopolist.
- Economic Impact: If courts side with Google, it would legally validate a business model for the entire AI industry based on the uncompensated use of public data. This could accelerate AI development but potentially devastate the creative industries (news, publishing, content creation) whose economic models rely on traffic and monetisation of their content. If publishers cannot monetise their work, the quality and quantity of publicly available content on the web could decline.
- Future of Property Rights: The outcome of these “fair use” cases will define fundamental property rights for the digital age, determining who benefits from the vast repository of human knowledge on the internet. It could compel AI companies to enter into widespread licensing agreements, creating new revenue streams for creators but also potentially slowing down AI innovation.
In essence, this legal battle is about establishing precedents for compensation, control, and the very viability of content creation in an AI-driven digital landscape.
Sneak peek:
- Read Chapter 1 – How Google Works.
- Read Chapter 2 – The ABCs of Relevance.
- Read Chapter 3 – Google Quality Score.
- Read Chapter 4 – Google Panda.
- Read Chapter 5 – Navboost.
- Read Chapter 6 – Entity SEO.
Hobo first published a guide to SEO in 2009, with the latest version for beginners being 2018. You can read about the history of SEO using Hobo SEO Books here. Read a round-up of the best SEO books.
The follow-up and companion book to Hobo SEO Strategy 2025 (published in July 2025) is Hobo AISEO Strategy 2025, which was published in August 2025.
Disclosure: Hobo Web uses generative AI when specifically writing about our own experiences, ideas, stories, concepts, tools, tool documentation or research. Our tool of choice for this process is Google Gemini Pro 2.5. This assistance helps ensure Hobo customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was edited and verified as correct by Shaun Anderson (creator of the Hobo SEO Dashboard). All external links were editorially approved by Shaun Anderson. See our AI policy.