If you are an SEO, a website developer, an app developer, or a web designer looking for a Javascript SEO checklist, here is a checklist straight from Google webmaster guidelines. This checklist takes you through the basics of Javascript SEO (search engine optimisation) and how to deploy and test it on your website.
The author has over 20 years of experience in SEO and website development.
To help you track your progress, the Javascript SEO checklist is available as a free Google spreadsheet and also as a free Microsoft Excel spreadsheet.
Read on to find out more about Javascript best practices.
What is Javascript?
JavaScript is one of the most popular programming languages used to develop websites today:
QUOTE: “Alongside HTML and CSS, JavaScript is one of the three core technologies of World Wide Web content production. It is used to make web pages interactive and provide online programs, including video games. The majority of websites employ it, and all modern web browsers support it without the need for plug-ins by means of a built-in JavaScript engine. Each of the many JavaScript engines represents a different implementation of JavaScript, all based on the ECMAScript specification, with some engines not supporting the spec fully, and with many engines supporting additional features beyond ECMA.” Wikipedia, 2018
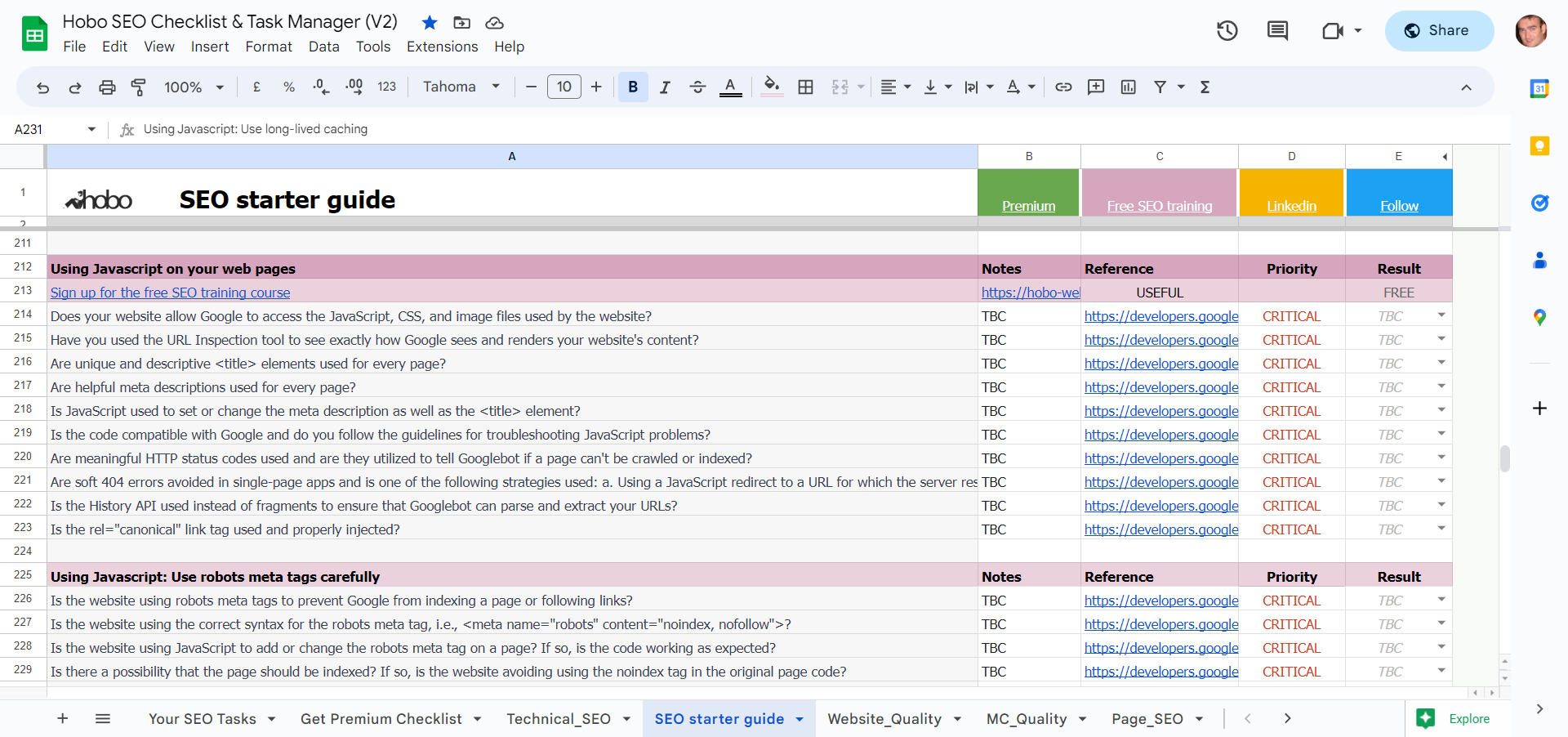
Javascript SEO checklist
Here are some things to check:
- Does your website allow Google to access the JavaScript, CSS, and image files used by the website?
- Have you used the URL Inspection tool to see exactly how Google sees and renders your website’s content?
- Are unique and descriptive title elements used for every page?
- Are helpful meta descriptions used for every page?
- Is JavaScript used to set or change the meta description as well as the title element?
- Is the code compatible with Google and do you follow the guidelines for troubleshooting JavaScript problems?
- Are meaningful HTTP status codes used and are they utilized to tell Googlebot if a page can’t be crawled or indexed?
- Are soft 404 errors avoided in single-page apps and is one of the following strategies used: a. Using a JavaScript redirect to a URL for which the server responds with a 404 HTTP status code b. Adding a <meta name=”robots” content=”noindex”> to error pages using JavaScript.
- Is the History API used instead of fragments to ensure that Googlebot can parse and extract your URLs?
- Is the rel=”canonical” link tag used and properly injected?
Use the robots meta tags carefully
Here are some things to check:
- Does the page use Robots meta tags?
- Is the website using the correct syntax for the robots meta tag, i.e., <meta name=”robots” content=”noindex, nofollow”>?
- Is the website using JavaScript to add or change the robots meta tag on a page? If so, is the code working as expected?
- Is there a possibility that the page should be indexed? If so, is the website avoiding using the noindex tag in the original page code?
Use long-lived caching
- Does the website use Long-lived caching?
- Is the website using content fingerprinting to avoid using outdated JavaScript or CSS resources?
- Has the website followed the long-lived caching strategies outlined in the web.dev guide?
Use structured data
- Does the website use Structured data?
- Is the website using JavaScript to generate the required JSON-LD and inject it into the page?
- Has the website tested its implementation to avoid any issues?
Test with URL Inspection Tool
- Go to Google Search Console.
- Select the property containing the URL you want to inspect.
- Click “URL Inspection” in the left-hand menu.
- Enter the URL you want to inspect in the search bar and hit “Enter”.
- Review the results to see how Google is indexing the URL and identify any crawl or indexing issues related to JavaScript.
Test with Mobile-Friendly Test
- Go to Google’s Mobile-Friendly Test.
- Enter the URL you want to test in the search bar and hit “Test URL”.
- Review the results to see how well the page works on mobile devices, including how it handles JavaScript, and highlight any mobile usability issues.
Test with Google Chrome DevTools
- Open the web page you want to test in Google Chrome.
- Right-click anywhere on the page and select “Inspect” from the context menu.
- In the DevTools window that opens, click the “Console” tab.
- Review the console output for any JavaScript errors or warnings.
- Use the “Elements” and “Network” tabs to inspect and debug the web page, including those that use JavaScript, and test how Googlebot sees your pages.
Understand challenges with Javascript and SEO
The first important challenge to note about Javascript is that not every search engine treats JS the way Google does. The sensible thing is to keep things as simple as possible for maximum effectiveness.
QUOTE: “Keep in mind that other search engines and web services accessing your content might not support JavaScript at all” John Mueller, Google 2016
Other search engine guidelines like Bing specifically state in their webmaster guidelines:
QUOTE: “The technology used on your website can sometimes prevent Bingbot from being able to find your content. Rich media (Flash, JavaScript, etc.) can lead to Bing not being able to crawl through navigation, or not see content embedded in a webpage. To avoid any issue, you should consider implementing a down-level experience which includes the same content elements and links as your rich version does. This will allow anyone (Bingbot) without rich media enabled to see and interact with your website.
- Rich media warnings – don’t bury links in Javascript/flash/Silverlight;keep content out of these as well
- Down-level experience enhances discoverability – avoid housing content inside Flash or JavaScript – these block crawlers form finding the content” ” Bing Webmaster Guidelines, 2018
Most other search engines advise webmasters to not block JS and CSS files, much like Google does.
Frequently asked questions
Can Google render JavaScript?
Yes. Google can render pages created with Javascript, as long as you do not block Google from accessing important JS or CSS files:
QUOTE: “As long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers. To reflect this improvement, we recently updated our technical Webmaster Guidelines to recommend against disallowing Googlebot from crawling your site’s CSS or JS files.” Google 2015
and
QUOTE: “If resources like JavaScript or CSS in separate files are blocked (say, with robots.txt) so that Googlebot can’t retrieve them, our indexing systems won’t be able to see your site like an average user. We recommend allowing Googlebot to retrieve JavaScript and CSS so that your content can be indexed better. This is especially important for mobile websites, where external resources like CSS and JavaScript help our algorithms understand that the pages are optimized for mobile.” Google, 2014
and
QUOTE: “Ensure that all required resources (including JavaScript files / frameworks, server responses, 3rd-party APIs, etc) aren’t blocked by robots.txt. The Fetch and Render tool will list blocked resources discovered. If resources are uncontrollably blocked by robots.txt (e.g., 3rd-party APIs) or otherwise temporarily unavailable, ensure that your client-side code fails gracefully.” John Mueller, Google 2016
and
QUOTE: “It’s always a good idea to have your site degrade gracefully. This will help users enjoy your content even if their browser doesn’t have compatible JavaScript implementations. It will also help visitors with JavaScript disabled or off, as well as search engines that can’t execute JavaScript yet.” Google, 2014
and
QUOTE: “The web has moved from plain HTML – as an SEO you can embrace that. Learn from JS devs & share SEO knowledge with them. JS’s not going away.”John Mueller 2017
How does Google treat “titles, description & robots meta tags, structured data, and other meta-data” created With Javascript
You can create page titles and other metadata using Javascript:
QUOTE: “Google supports the use of JavaScript to provide titles, description & robots meta tags, structured data, and other meta-data. When using AMP, the AMP HTML page must be static as required by the spec, but the associated web page can be built using JS/PWA techniques. Remember to use a sitemap file with correct ” lastmod” dates for signaling changes on your website.” John Mueller,Google 2016
and
QUOTE: “Use Chrome’s Inspect Element to check the page’s title and description meta tag, any robots meta tag, and other meta data. Also check that any structured data is available on the rendered page.” Google, 2017
You can read my notes on optimising page titles and meta tags SEO for Google.
How Does Google Handle Navigation Links That Are CREATED Using Javascript?
QUOTE: “we see your content more like modern Web browsers, include the external resources, execute JavaScript and apply CSS.” Google 2014
As long as Google can render it properly, Google will follow any links presented to it including those with nofollow on it.
QUOTE: “A part of following JavaScript the team that implemented crawling JavaScript also implemented the ability to add nofollow attribute on JavaScript links” Matt Cutts, Google 2009
and
QUOTE: “If you’re using javascript to create an <a> element on the page then you can choose to add nofollow or not to that <a> element at the dom and that’s what we will respect when it comes to kind of passing signals.” John Mueller, Google
and
QUOTE: “Avoid the AJAX-Crawling scheme on new sites. Consider migrating old sites that use this scheme soon. Remember to remove “meta fragment” tags when migrating. Don’t use a “meta fragment” tag if the “escaped fragment” URL doesn’t serve fully rendered content.” John Mueller, Google 2016
See my notes on optimising internal links for Google and how to get Google to index my website properly.
Does A Javascript Link Pass PageRank just like any other link?
QUOTE: “Yes, a link is a link, regardless of how it comes to the page. It wouldn’t really work otherwise.” John Mueller, Google 2017
How Does Google Handle A Link FOUND In Javascript CODE On A Webpage?
Google will follow links found in JS code on a page, but not pass any signals through them like Pagerank, 2020:
QUOTE: “If it’s a URL just in the JavaScript code then we will try to follow that but we don’t pass any PageRank to that so it’s kind of automatically nofollow.” John Mueller, Google
TIP: Use “feature detection” & “progressive enhancement” techniques to make your site accessible to all users
QUOTE: Don’t cloak to Googlebot. Use “feature detection” & “progressive enhancement” techniques to make your content available to all users. Avoid redirecting to an “unsupported browser” page. Consider using a polyfill or other safe fallback where needed. The features Googlebot currently doesn’t support include Service Workers, the Fetch API, Promises, and requestAnimationFrame.” John Mueller, Google 2016
How Does Google Handle Content Which Becomes Visible When Clicking A Button?
This is going to depend on IF the content is actually on the page, or is called from another page using some sort of action the user must perform that calls some JS function.
QUOTE: “Take for example Wikipedia on your mobile phone they’ll have different sections and then if you click they expand those sections and there are good usability reasons for doing that so as long as you’re not trying to stuff something in in a hidden way that’s deceptive or trying to you know distort the rankings as long as you’re just doing that for users I think you’ll be in good shape.” Matt Cutts, Google 2013
How Google Treats Text Hidden But Revealed Using Javascript & CSS e.g. ‘Read More’ Links
As long as the text is available on that page when Google crawls it, Google can see the text and use it in relevance calculations. How Google treats this type of content can be different on mobile sites and desktop sites.
QUOTE: “I think we’ve been doing something similar for quite awhile now, where if we can recognize that the content is actually hidden, then we’ll just try to discount it in a little bit. So that we kind of see that it’s still there, but the user doesn’t see it. Therefore, it’s probably not something that’s critical for this page. So that includes, like, the Click to Expand. That includes the tab UIs, where you have all kinds of content hidden away in tabs, those kind of things. So if you want that content really indexed, I’d make sure it’s visible for the users when they go to that page. From our point of view, it’s always a tricky problem when we send a user to a page where we know this content is actually hidden. Because the user will see perhaps the content in the snippet, they’ll click through the page, and say, well, I don’t see where this information is on this page. I feel kind of almost misled to click on this to actually get in there.” John Mueller, Google 2014
Google has historically assigned more ‘weight’ in terms of relevance to pages where the text is completely visible to the user. Many designers use tabs and “read more” links to effectively hide text from being visible on loading a page.
This is probably not ideal from a Google ranking point of view.
Some independent tests have apparently confirmed this:
QUOTE: “The experiment clearly demonstrates Google’s preference for visible text. The experiment showed Google algorithms clearly gives less weight to text hidden via CSS and JavaScript” RebootOnline 2017
With Google switching to a mobile-first index, where it will use signals it detects on the mobile version of your site, you can expect text hidden in tabs to carry weight from a ranking point of view:
QUOTE: “So with the mobile first indexing will index the the mobile version of the page. And on the mobile version of the page it can be that you have these kind of tabs and folders and things like that, which we will still treat as normal content on the page even. Even if it is hidden on the initial view. So on desktop it’s something where we think if it’s really important content it should be visible. On mobile it’s it’s a bit trickier obviously. I think if it’s a critical contact it should be visible but that’s more kind of between you and your users in the end.” John Mueller, Google 2017
On the subject of “read more” links in general, some Google spokespeople have chimed in thus:
QUOTE: “oh how I hate those. WHY WHY WHY would a site want to hide their content?” John Mueller, Google 2017
and
QUOTE: “I’ve never understood the rationale behind that. Is it generating more money? Or why are people doing that?” Gary Illyes, Google 2017
There are some benefits for some sites to use ‘read more’ links, but I usually shy away from using them on desktop websites.
How Google Treats Content Loaded from Another Page Using JS

If a user needs to click to load content that is pulled from another page, from my own observations, Google will not index that content as a part of the original page IF the content itself is not on the page indexed.
This has been confirmed by Google in a 2016 presentation Google’s John Mueller gave:
QUOTE: “If you have something that’s not even loaded by default that requires an event some kind of interaction with the user then that’s something we know we might not pick up at all because Googlebot isn’t going to go around and click on various parts of your site just to see if anything new happens so if you have something that you have to click on like like this, click to read more and then when someone clicks on this actually there’s an ajax call that pulls in the content and displays it then that’s something we probably won’t be able to use for indexing at all so if this is important content for you again move it to the visible part of the page.” John Mueller, Google 2016
How does Google deal with Javascript Redirects?
QUOTE: “Using JavaScript to redirect users can be a legitimate practice. For example, if you redirect users to an internal page once they’re logged in, you can use JavaScript to do so. When examining JavaScript or other redirect methods to ensure your site adheres to our guidelines, consider the intent. Keep in mind that 301 redirects are best when moving your site, but you could use a JavaScript redirect for this purpose if you don’t have access to your website’s server.” Google Webmaster Guidelines 2018
and
QUOTE: “If you have a hash in the URL or hash-bang in the URL then you need to do that redirect on the client-side with JavaScript and for that it’s really important from our point of view that you do that redirect as quickly as possible that you don’t have interstitials there that you don’t have a timeout that does the redirect after a certain period of time because what might then happen is we don’t recognize that redirect and we might say oh this is actually the content on the page and we will pick up the interstitial for indexing.” John Mueller, Google 2016
and
QUOTE: “JavaScript redirects: If you can’t do a server-side redirect, using JavaScript is a good fall-back. If you’re using a JavaScript framework for your site, this might also be the only option. Caching depends on the server settings, and search engines have to guess at what you’re trying to do.” John Mueller, Google 2016
Using Javascript for common redirects (moving the content on one page to another url) is not the most efficient way of moving content or sites. See my page on using 301 redirects for more on this.
Can I Use Javascript To hide “Affiliate Links”?
Probably not a good idea:
QUOTE: “You’re hiding links from Googlebot. Personally, I wouldn’t recommend doing that as it makes it harder to properly understand the relevance of your website. Ultimately, that’s your choice, just as it would be our choice to review those practices as potential attempts to hide content & links. What’s the advantage for the user?” John Mueller, Google 2010
TIP: Mobile-First Indexing: Ensure your mobile sites and desktop sites are equivalent
When Google renders the page they can crawl links included by JavaScript on mobile pages. However, Google wouldn’t see these links if they exist on desktop pages but cannot be found on mobile pages.
QUOTE: “If we can crawl the JavaScript and render the page with those links from the JavaScript and that’s that’s okay for us on the other hand if the JavaScript doesn’t actually include the links to those other pages when it’s kind of accessed with a mobile device then we wouldn’t have any links to the other pages so that would be kind of a loss” John Mueller, Google 2017
See my notes on the Google mobile-first index.
WARNING: Some Javascript-Based Sites Can be “Slow and inefficient”
“QUOTE: Sometimes things don’t go perfectly during rendering, which may negatively impact search results for your site.” Google
and
QUOTE: “What should be a relatively simple process, where the crawler finds your site’s pages and the indexer then evaluates them, becomes a cumbersome endeavour. On JavaScript sites where most or all internal links are not part of the HTML source code, in the first instance the crawler finds only a limited set of URLs. It then has to wait for the indexer to render these pages and extract new URLs, which the crawler then looks at and sends to the indexer. And so on, and so forth. With such JavaScript-based websites, crawling and indexing becomes slow and inefficient.” Barry Adams stateofdigital, 2017
and
QUOTE: “Limit the number of embedded resources, in particular the number of JavaScript files and server responses required to render your page. A high number of required URLs can result in timeouts & rendering without these resources being available (e.g., some JavaScript files might not be loaded). Use reasonable HTTP caching directives.” Google
and
QUOTE: “If your web server is unable to handle the volume of crawl requests for resources, it may have a negative impact on our capability to render your pages. If you’d like to ensure that your pages can be rendered by Google, make sure your servers are able to handle crawl requests for resources. Sometimes the JavaScript may be too complex or arcane for us to execute, in which case we can’t render the page fully and accurately. Some JavaScript removes content from the page rather than adding, which prevents us from indexing the content.” Google
How To Test If Google Can Render Your Pages Properly
QUOTE: “Use Search Console’s Fetch and Render tool to test how Googlebot sees your pages. Note that this tool doesn’t support “#!” or “#” URLs. Avoid using “#” in URLs (outside of “#!”). Googlebot rarely indexes URLs with “#” in them. Use “normal” URLs with path/filename/query-parameters instead, consider using the History API for navigation.” John Mueller,Google 2016
Google can crawl and execute some types and configurations of javascript:
QUOTE: “Rendering on Google Search: http://bit.ly/2wffmpL – web rendering is based on Chrome 41; use feature detection, polyfills, and log errors!” Ilya Grigorik 2017
and
QUOTE: “Googlebot uses a web rendering service (WRS) that is based on Chrome 41 (M41). Generally, WRS supports the same web platform features and capabilities that the Chrome version it uses — for a full list refer to chromestatus.com, or use the compare function on caniuse.com.” Google, 2020
Will Google Properly Render Single Page Application and Execute Ajax Calls?
Yes. Google will properly render Single Page Applications (SPA):
QUOTE: “Googlebot run the Javascript on the page and the Ajax calls are properly executed.” Lucamug test 2017
Will Google Properly Render Hash-Bang URLs (#!)?
Yes, Google can render hash-bang URLs (#!) and crawl the content generated by JavaScript served through these URLs, also known as AJAX crawling. However, it’s now recommended to use server-side or dynamic rendering instead of hash-bang URLs for better indexing and crawling of JavaScript-based web pages.
JavaScript SEO FAQ
What is JavaScript SEO?
JavaScript SEO refers to the practice of optimising websites that use JavaScript frameworks, libraries, and technologies for search engine visibility. This involves addressing issues related to how search engines crawl, index, and rank JavaScript-based web content, as well as optimising the performance and user experience of JavaScript-based web pages.
What are some common JavaScript SEO issues?
Common JavaScript SEO issues may include:
- Search engine crawlers may not be able to access or render JavaScript content.
- JavaScript-based content may be dynamically loaded or changed, making it difficult for search engines to accurately index and rank the content.
- JavaScript-based web pages may load slowly or have poor performance, which can negatively impact user experience and search engine rankings.
- JavaScript-based web pages may not be properly structured or optimised for on-page SEO factors, such as meta tags and content structure.
How can I optimise my website for JavaScript SEO?
Here are some tips for optimising your website for JavaScript SEO:
- Ensure that search engine crawlers can access and render your JavaScript content.
- Use server-side rendering or dynamic rendering to provide search engines with static HTML versions of your JavaScript-based web pages.
- Implement lazy loading or other techniques to optimise the performance and speed of your JavaScript-based web pages.
- Structure your JavaScript-based web pages to follow best practices for on-page SEO, such as using descriptive meta tags and optimising content structure.
- Use tools such as Google Search Console and Lighthouse to identify and address JavaScript SEO issues on your website.
What are the benefits of optimising for JavaScript SEO?
Optimising your website for JavaScript SEO can help improve your website’s search engine visibility and rankings. By addressing JavaScript SEO issues and following best practices for JavaScript-based web development, you can ensure that your website is accessible to all, including search engines.