When I started in SEO over 20 years ago, getting your pages into Google was simple. Google prided itself on indexing pages fast.
Two months after de-indexing my site after attempting to exasorbate a potential disconnected entity status (with almost 100% pages indexed on a site of about 100 pages), testing how fast Google will re-index de-indexed pages, I can report that key pages are STILL NOT INDEXED.
There are a few reasons for that, and there are a few interesting patterns to ponder for the pages that Google doesn’t seem to want to index.
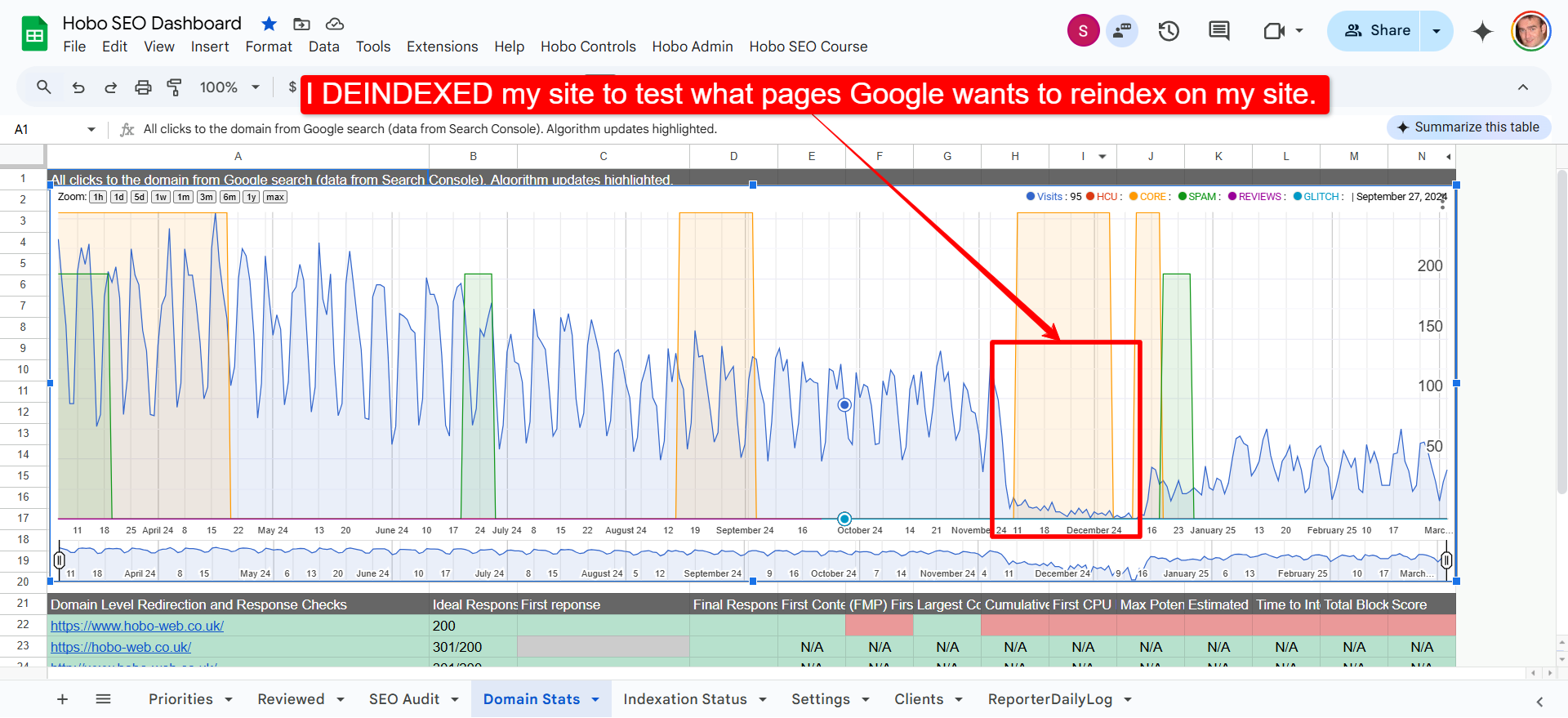
Pages that were once indexed now languish in the Crawled – currently not indexed status, eg not indexed.
I’ve had a look at these pages, and I see some very interesting things to note.
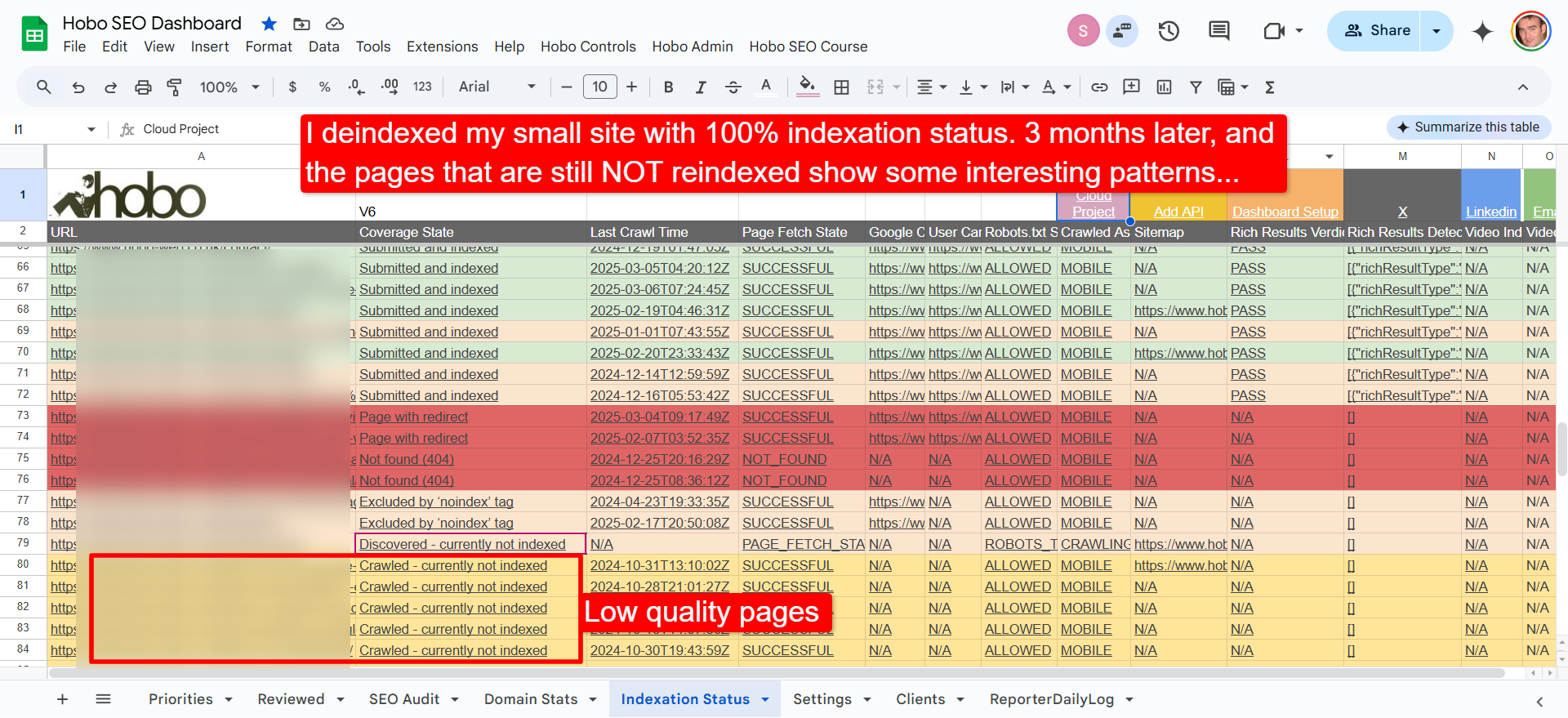
Initial observations from the test
Here are some initial observations:
- Pages with payment gateway links seem to struggle to get re-indexed, especially if the reason for the page to exist is the payment gateway link itself. Anyone paying attention understands this particular aspect goes WAY BACK in Google, though.
- It’s fair to say the pages in Crawled – currently not indexed are lower quality pages, on the whole, in comparison to the rest of the pages on the site, which have more links to them too. I see some AI test pages in there, too.
- Some pages that have minimal text, and a lot of images seem to struggle, regardless of the monetisation of the page.
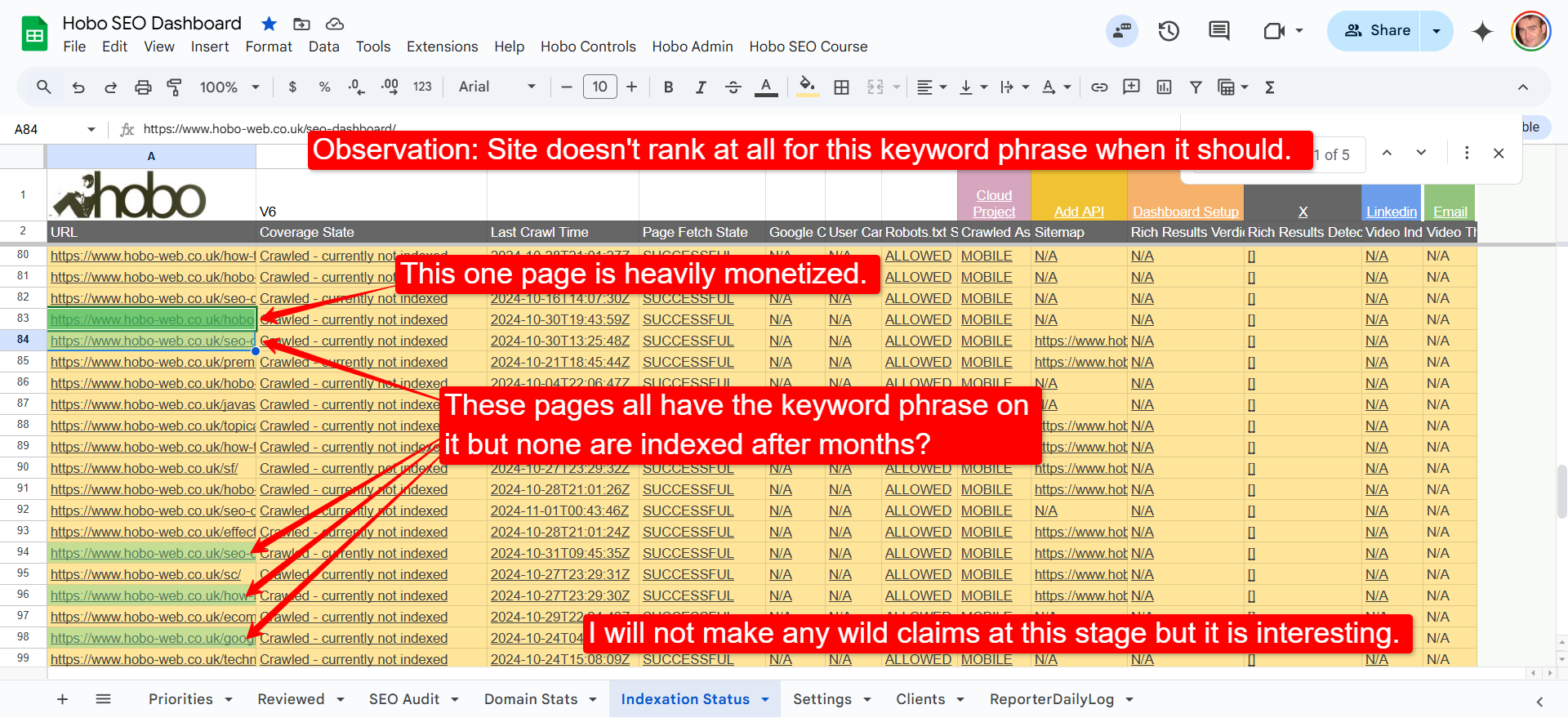
The most interesting thing for me is one particular keyword phrase not ranking.
CONJECTURE: It’s almost as if because one page on the site is heavily optimised for one keyword and monetized, and selected not to be indexed…. its almost as if no other page on the site with that keyword in the title is indexed either…. that WOULD be a wild speculation to make, so I will leave it as pure conjecture at the moment.
It does tie in with an interesting “Disallowed Keywords” theory, although I think what my friend Taleb (and others) are tracking are the effects of being a disconnected entity, or how it manifests, not the cause – which I go into in the Disconnected Entity Hypothesis.
Moz has another interesting theory about HCU – which I haven’t even got to yet after I got distracted by the October Terminator Algorithm but I still lean towards the hypothesis with this one because I think everything in the hypothesis is grounded in Google Quality Rater Guidelines eg there is nothing in The Diconnected Entity Hypothesis that is not in the QRG – and frankly, I would think it takes a lot less processing power to identify weak entities than brand signals for every site on the planet.
I posit that because the site has low Trust (as a disconnected, unknown entity does in the E.E.A.T. framework), it is thus deemed low-quality, which results in a lower quality score for the domain, so particular monetised keywords will not be allowed to rank to protect Google’s users.
I am also seeing weird, keyword-specific ranking glitches in the current unannounced Google Search algorithm update activity.
One things for sure, doon’t deindex your site if you need all your pages indexed.
It can take a long time to get back in.
This has been an interesting test, at least, to see the types of pages not getting back into the index.
More later.
Check out the new EEAT tool I’ve made recently to help you understand what a Disconnected Entity is.