
During the landmark Department of Justice antitrust trial in the fall of 2023 (U.S. v. Google LLC, 1:20-cv-03010-APM), a trove of highly confidential internal presentations was unsealed.
These original PDFs – including a mobile ranking newsletter from August 16, 2014, the crucial “Search All Hands” presentation from December 8, 2016, the “Life of a Click” presentation from May 15, 2017, and subsequent strategy decks dated October 30, 2017, November 16, 2018, September 17, 2019, and May 8, 2020 – exposed candid admissions from senior search engineers about their heavy reliance on user click data to “fake” document understanding. Hat tip to Danny Goodwin for covering these on SEL in 2023 – really helped bring my research to a close in this area.

Just months later, in May 2024, the industry experienced a second massive shockwave: the “Content API Warehouse” leak, where thousands of internal engineering documents detailing Google’s modern, mechanical ranking attributes were accidentally published to GitHub.
Together, these two historic data dumps stripped away the public marketing narrative, providing the first unfiltered, behind-the-scenes look at the actual architecture and evolution of modern search.
The Core Admission: “We Do Not Understand Documents. We Fake It.”

The public is often sold a narrative of omniscient algorithms and flawless artificial intelligence. However, internal documents revealed in the landmark antitrust case 1:20-cv-03010-APM (based on internal documents and slideshows from 2016) offer a starkly different, highly candid look behind the curtain.
Exhibit No. UPX0203 contains an internal presentation by Eric Lehman. Lehman begins by framing Google Search as a grand scientific endeavour:
“Search is a great place to start understanding language… Success has implications far beyond Search.”
“Making machines understand human language is a fundamental scientific problem… I believe Google search may be the best setting in the world to attack that problem. If we succeed, we can potentially transfer that technology to many other applications.”
He then immediately undercuts the grand ambition with humility:
“This is big talk, but I’m going to back it up … with … comic strips … with little … stick figures.”
The most revealing slide delivers the central truth:
“We do not understand documents. We fake it.”
Lehman provides background on daily operations:
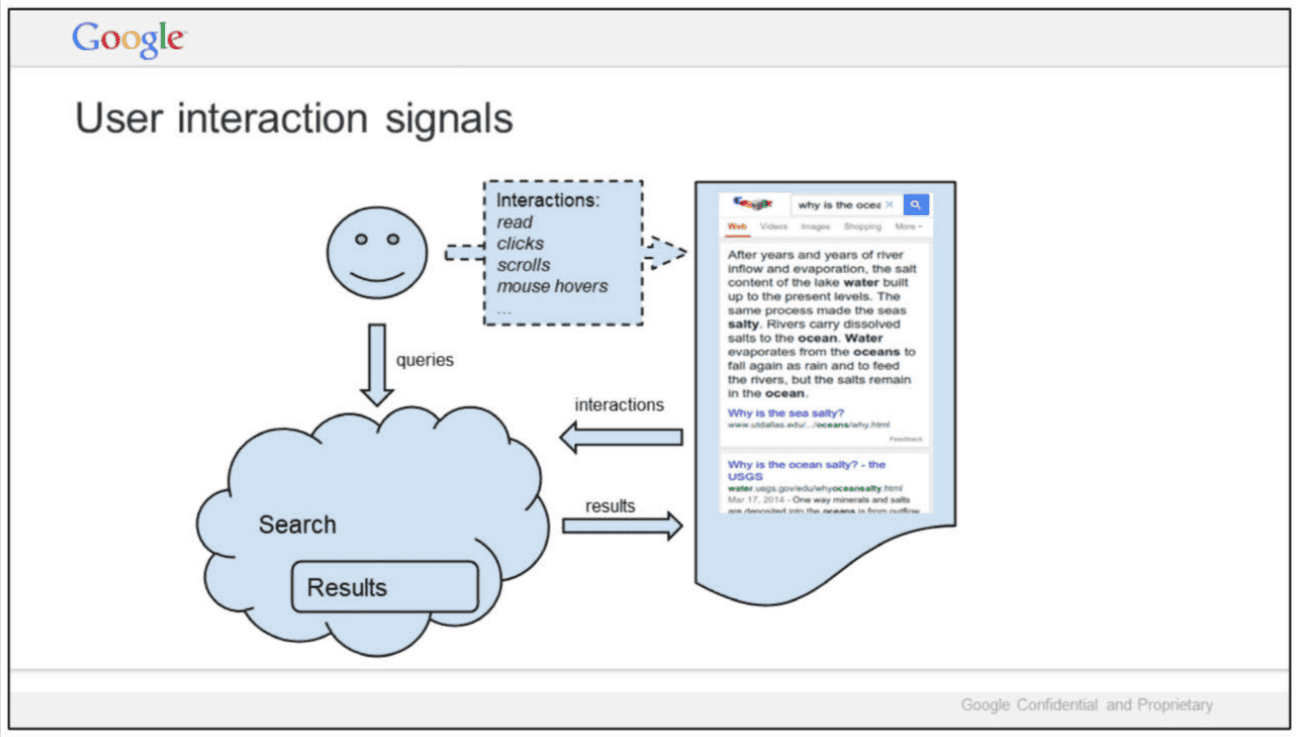
“A billion times a day, people ask us to find documents relevant to a query… What’s crazy is that we don’t actually understand documents. Beyond some basic stuff, we hardly look at documents.”
“We look at people… Today, our ability to understand documents directly is minimal. So we watch how people react to documents and memorize their responses.”
“If a document gets a positive reaction, we figure it is good. If the reaction is negative, it is probably bad.”
He summarises the entire system:
“Grossly simplified, this is the source of Google’s magic.”
The Induction Loop: You Are the Algorithm
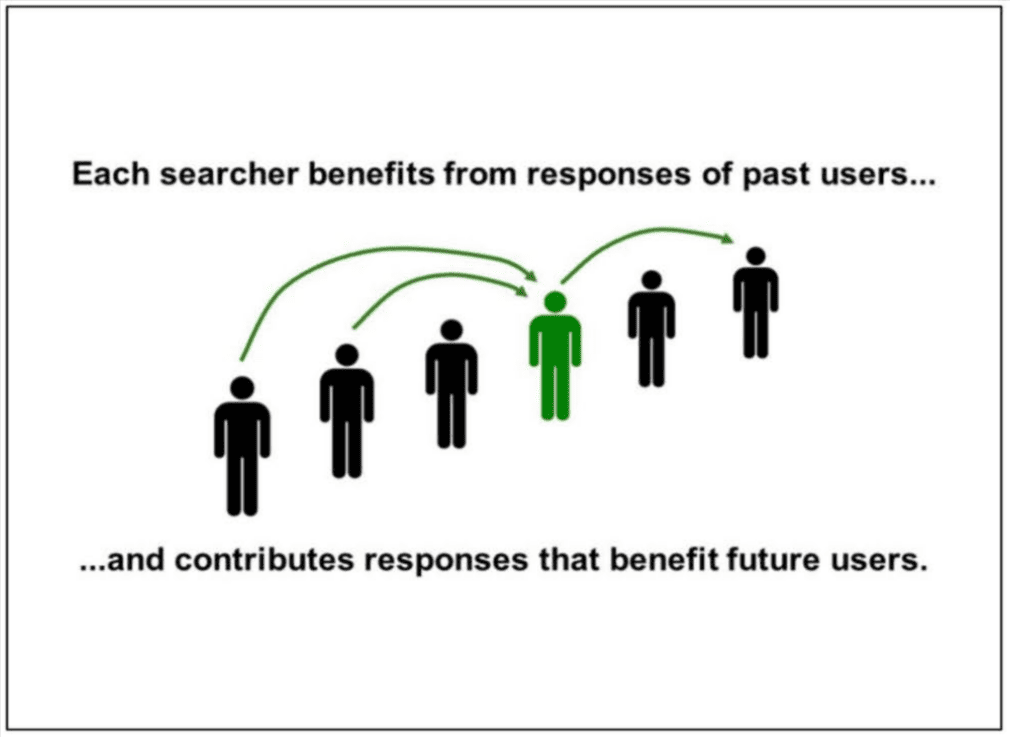
 Google’s Navboost visualised.
Google’s Navboost visualised.
“Each searcher benefits from responses of past users … and contributes responses that benefit future users.”
“SO … if you search right now, you’ll benefit from the billions of past user reactions we’ve recorded. And your responses will benefit people who come after you.”
“Search keeps working by induction.”
Lehman stresses a critical design implication:
“This has an important implication. In designing user experiences, SERVING the user is NOT ENOUGH. We have to design interactions that also allow us to LEARN from users… Because that is how we serve the next person, keep the induction rolling, and sustain the illusion that we understand.”
He remained optimistic about the future:
“Looking to the future, I believe learning from users is also the key to TRULY understanding language.”
When the system fails to gather sufficient behavioural data, the illusion breaks:
“When fake understanding fails, we look stupid… When our fakery fails– maybe because a document is new, recently-changed, or rarely-shown– we look stupid.”
Let’s not forget:
CRAPS – Google’s internal naming convention for clicks: “Dwell time, CTR, whatever Fishkin’s new theory is, those are generally made up crap. Search is much more simple than people think.” Gary Ilyes 2019 Reddit Thread
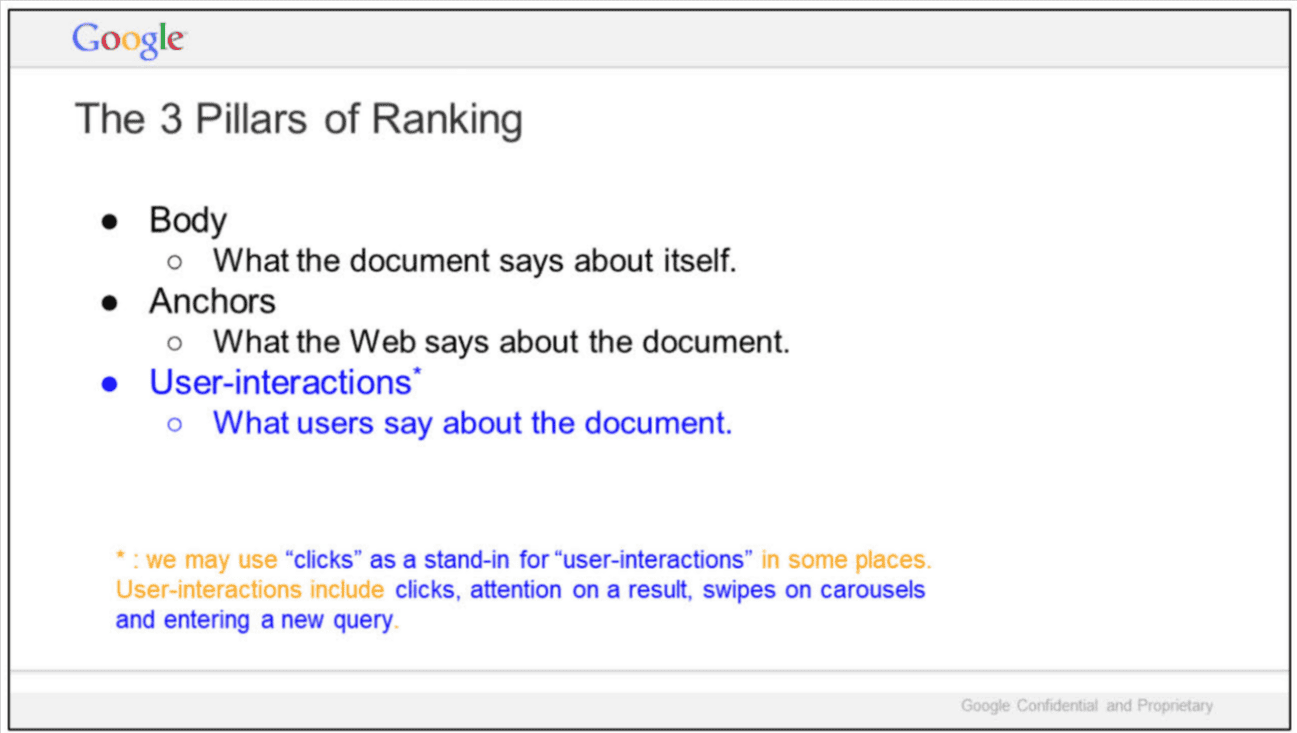
The 3 Pillars of Ranking (Exhibit UPX0004 – “Life of a Click”)
In a related presentation titled “Life of a Click (user-interaction)” (Exhibit No. UPX0004), Eric Lehman outlines the structural foundation of Google’s ranking:
“The 3 Pillars of Ranking
• Body – What the document says about itself.
• Anchors – What the Web says about the document.
• User-interactions* – What users say about the document.”
“* : we may use ‘clicks’ as a stand-in for ‘user-interactions’ in some places.”
“User-interactions include clicks, attention on a result, swipes on carousels and entering a new query.”
How Search Really Works – The Two-Way Dialogue (Exhibit UPX0228)
“Google is magical. Google is sort of magical.”
“This is NOT how search works… We get a query. Various scoring systems emit data, we slap on a UX, and ship it to the user. This is not false, just incomplete… No magic.”
“The key is a second flow of information in the reverse direction. As people interact with search, their actions teach us about the world.”
“This dialogue is the source of magic… With every query, we give some knowledge, and get a little back… These bits add up. After a few hundred billion rounds, we start lookin’ pretty smart!”
“We must unobtrusively turn the tables… Implicitly pose a question to the user. Provide background. Give the user a way to answer.”
Classic 10 blue links example:
“10 blue links – ‘Which result is best?’ … This bland UI made the search results great.”
Logging & Ranking – The Business Reality (Exhibit UPX0219)
“This two-way dialogue is the source of Google’s magic.”
“We have to translate logged events (clicks, swipes, views, scrolls, pauses etc.) to guesses at what parts of the search page were good or bad… A slight improvement in value judgments pays off a billion-fold the very next day!”
“Logs -> Ranking -> $$$ … all major machine learning systems for ranking rely on logs: RankBrain, RankEmbed, DeepRank… I think a huge amount of Google business is tied to the use of logs in ranking.”
Ranking for Research – The Culture of Caution (Exhibit UPX0204)
“Having a big, positive impact on the world is a joy of working on search. But this impact makes our words and actions carry heavy consequences. So we must tread carefully…”
“Do not discuss political bias in search in writing… Do not discuss the use of clicks in search, except on a need-to-know basis… Google has a public position. It is debatable. But please don’t craft your own.”
“Capturing everything in a metric is tough!”
These internal exhibits (UPX0203, UPX0004, UPX0228, UPX0219, and UPX0204) strip away the marketing narrative. Google Search’s dominance is not built on machines that truly understand language or documents. It is built on a vast, continuous behavioural feedback loop in which billions of users unknowingly teach the system through their clicks, scrolls, hovers, dwells, and reactions.
As Eric Lehman candidly stated, “We do not understand documents. We fake it.” The “magic” is the result of an extremely sophisticated induction system that memorises human responses and uses them to simulate understanding.
Every search you perform doesn’t just give you an answer — it also contributes another tiny piece of training data that helps Google fake understanding a little better for the next person.
At least, that was the architecture until recently.
To solve the flaws in this click-based system, Google had to evolve.
From “Faking It” to the Algorithmic Glass Ceiling
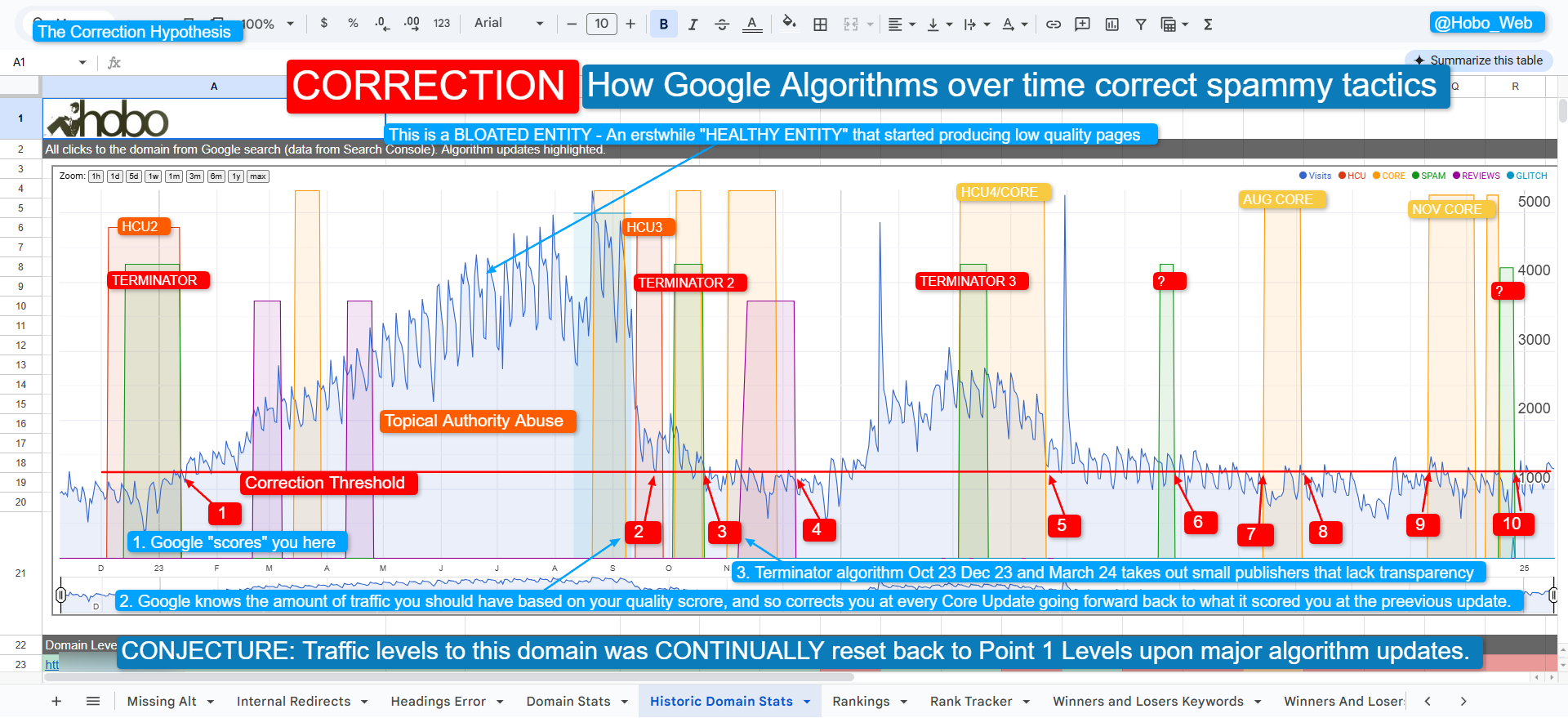
By cross-referencing internal presentations by Google engineers with the leaked API documentation, we finally have a clear picture of how modern search actually works.
It is a story of evolution: how Google went from relying on an “Induction Loop” of user clicks to building a multi-stage, AI-driven gatekeeper system.
Phase 1: The Induction Loop and the Illusion of Understanding
To understand the current algorithm, we must look at how it was originally built. In Exhibit No. UPX0203 from the DOJ trial, Google engineer Eric Lehman made a startling admission about the foundation of Google Search:
“We do not understand documents. We fake it… Beyond some basic stuff, we hardly look at documents. We look at people.”
Google solved the incredibly difficult scientific problem of understanding human language by simply watching human behavior. They created an Induction Loop. When a user searched for a term, Google presented 10 blue links. If a user clicked a link, stayed on the page (a “Good Click”), and didn’t bounce back to the search results (pogo-sticking), the system learned that the document was a good answer.
They used systems like Navboost—fueled by massive amounts of Chrome browser data (chromeInTotal) – to memorise these interactions. They weren’t reading the content; they were crowd-sourcing the evaluation of it.
The fatal flaw of this system was the “cold start” problem. As Lehman noted: “When our fakery fails– maybe because a document is new, recently-changed, or rarely-shown– we look stupid.” If no one had clicked on an article yet, Google didn’t know where to rank it.
Phase 2: Solving the “Cold Start” with Semantic AI
To fix this vulnerability, Google had to evolve from watching users to actually processing language. Over the last few years, through the Transformer revolution (BERT, MUM, and Gemini), Google transitioned to Vector Search.
Instead of just looking for matching keywords or waiting for user clicks to tell them if an article was good, Google’s systems learned to map documents into mathematical spaces to assess semantic context, entity relationships, and sentiment upon indexing.
This technological leap allowed them to operationalise their famous E-E-A-T (Experience, Expertise, Authoritativeness, and Trust) guidelines.
E-E-A-T is not a singular algorithm; it is the human-centric philosophy that Google’s engineers were tasked with converting into machine-readable proxies.
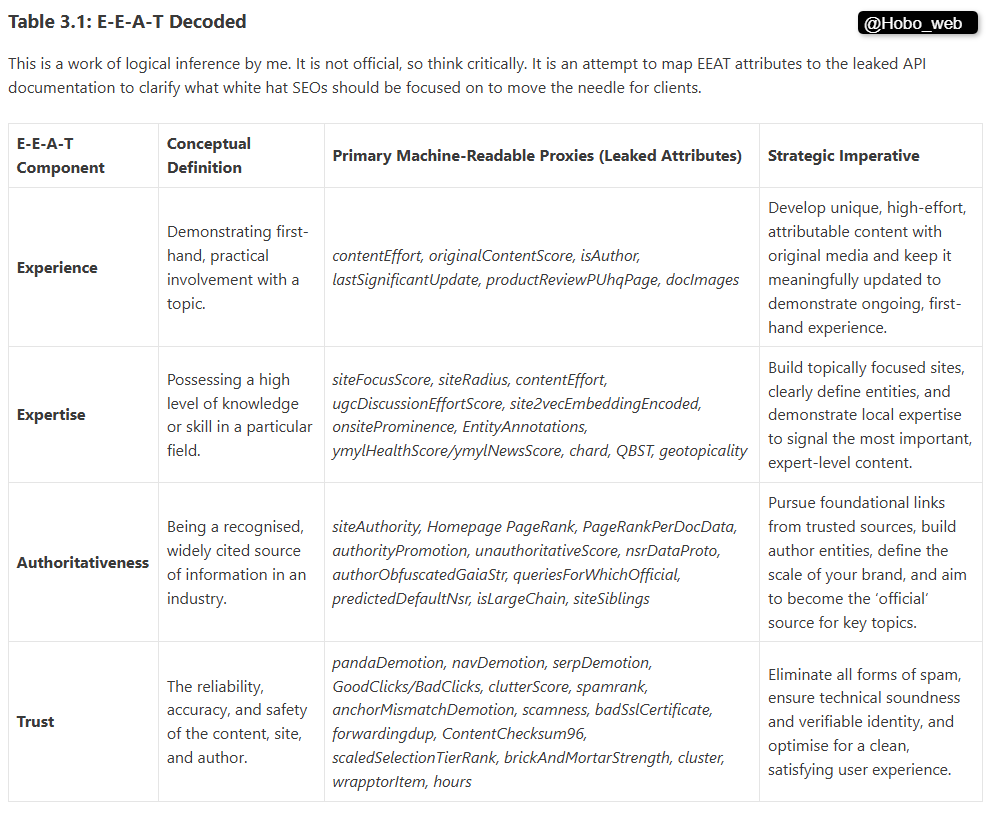
Phase 3: The Modern Pipeline (The 3 Pillars Decoded)
The “Content API Warehouse” leak reveals exactly how Google successfully mechanised E-E-A-T. The algorithm is no longer a single equation; it is a multi-stage gatekeeper system.
The leaked documentation reveals that Google evaluates the classic “3 Pillars of Ranking” (Body, Anchors, and User-Interactions) in a strict, chronological pipeline.

Gatekeeper 1: The Body (Experience & Expertise)
Before a page can rank, it must pass initial retrieval and scoring by a system named Mustang. This system evaluates the “Body” of your document using AI classifiers to determine if you belong in the Base tier (eligible to rank) or the Landfills tier (disqualified).
-
Measuring Experience: Google uses
contentEffort(an LLM-based estimation of the human labour required to create the page) andoriginalContentScoreto penalise mass-produced or purely AI-generated content. If you have original images (docImages) and a history of meaningful updates (lastSignificantUpdate), You pass the Experience check. -
Measuring Expertise: Google calculates your
siteFocusScoreto see if you are a true niche authority or a generalist site. They useEntityAnnotationsto verify if your content semantically covers the expected entities for that topic.
Gatekeeper 2: Anchors (Authoritativeness)
If your content quality is high enough, the system looks at your historical reputation.
-
Algorithmic Momentum: The leak revealed
predictedDefaultNsr, a versioned signal that maintains a historical record of a site’s quality. Combined withsiteAuthority(a holistic metric blending the link graph with overall reliability), this acts as an algorithmic glass ceiling. A brand-new site with a great article will inherently struggle against a domain with years of stored “algorithmic momentum.”
The Final Modifier: User-Interactions (Trust)
If, and only if, your document survives the Mustang gatekeeper and has sufficient site authority, it is passed to the re-ranking layer known as Twiddlers.
-
Navboost and The Chrome Connection: This is where the old “Induction Loop” still lives. Navboost looks at
GoodClicksversusBadClicks(bounces). Even if your content is brilliant, if your title tag is misleading or your site layout triggers a highclutterScorecausing users to bounce, you will suffer anavDemotionorserpDemotion. User behaviour is the final, ultimate validator of Trust.
The Strategic Takeaway: Surviving the Algorithmic Glass Ceiling

The most fascinating takeaway is the sheer audacity of the “Induction Loop.” It is incredible to realise that for over a decade, the most powerful information retrieval system in human history wasn’t actually retrieving information based on understanding. It was a massive, crowd-sourced behavioural experiment.
Google built a trillion-dollar empire not by solving natural language processing, but by building a perfect feedback loop that forced billions of users to do the quality assurance for them. The admission that they were completely blind to “cold start” content exposes just how fragile the internet’s infrastructure used to be.
The synthesis of these leaks fundamentally changes how we must approach SEO. You can no longer brute-force your way to the top using just one of the pillars.
-
Stop Optimising Pages; Optimise Entities: The existence of
siteFocusScore,siteAuthority, andauthorObfuscatedGaiaStrproves that Google evaluates the context of the entire domain and the specific author. A single great post on a weak, unfocused domain will hit the glass ceiling. You must build topical hubs and recognisable author entities. -
Pass the “Mustang” Check First: Stop worrying about click-through rates if your content is derivative. You must prove human effort (
contentEffort) and originality (originalContentScore) to avoid being dumped into theLandfillsindexing tier. -
SERP UX is a Direct Ranking Factor: Because Navboost uses a 13-month data window of Chrome user interactions, your title tags, meta descriptions, and initial page load experience are critical. A misleading title that gets a click but results in a fast bounce is now a mathematically confirmed negative ranking factor.
Google is no longer JUST “faking it,” exactly in the same sense, but as my esteemed combatant on X, the renowned SEO Mythbuster David Quaid points out frequently on Reddit and X, can an algorithm really understand content? Even with AI?
Well, no, if you have a handle on fractals, algorithms and what AI actually is (I will avoid even using the word understand here!). What we are dealing with is fundamental and philosophical – no machine can understand content in the way a human can. So don’t use the word “understand”, in this context when talking to David.
“Google is content agnostic…. It always has been.”
What we can infer as I write this in 2026 is that Google is much, much better at “faking” understanding content, using many, many proxies in a system of competing philosophies, on top of more and more historical data. I mean, and not to be facetious, they can fake it real good, when it works. It leaves lots of gaps, though, and we know gaps can persist in years before they are fixed (see Second page navboost“).
Google have built a sophisticated, interdependent system where foundational authority allows your content to be seen, deep semantic quality proves your expertise, and real user satisfaction cements your ranking.
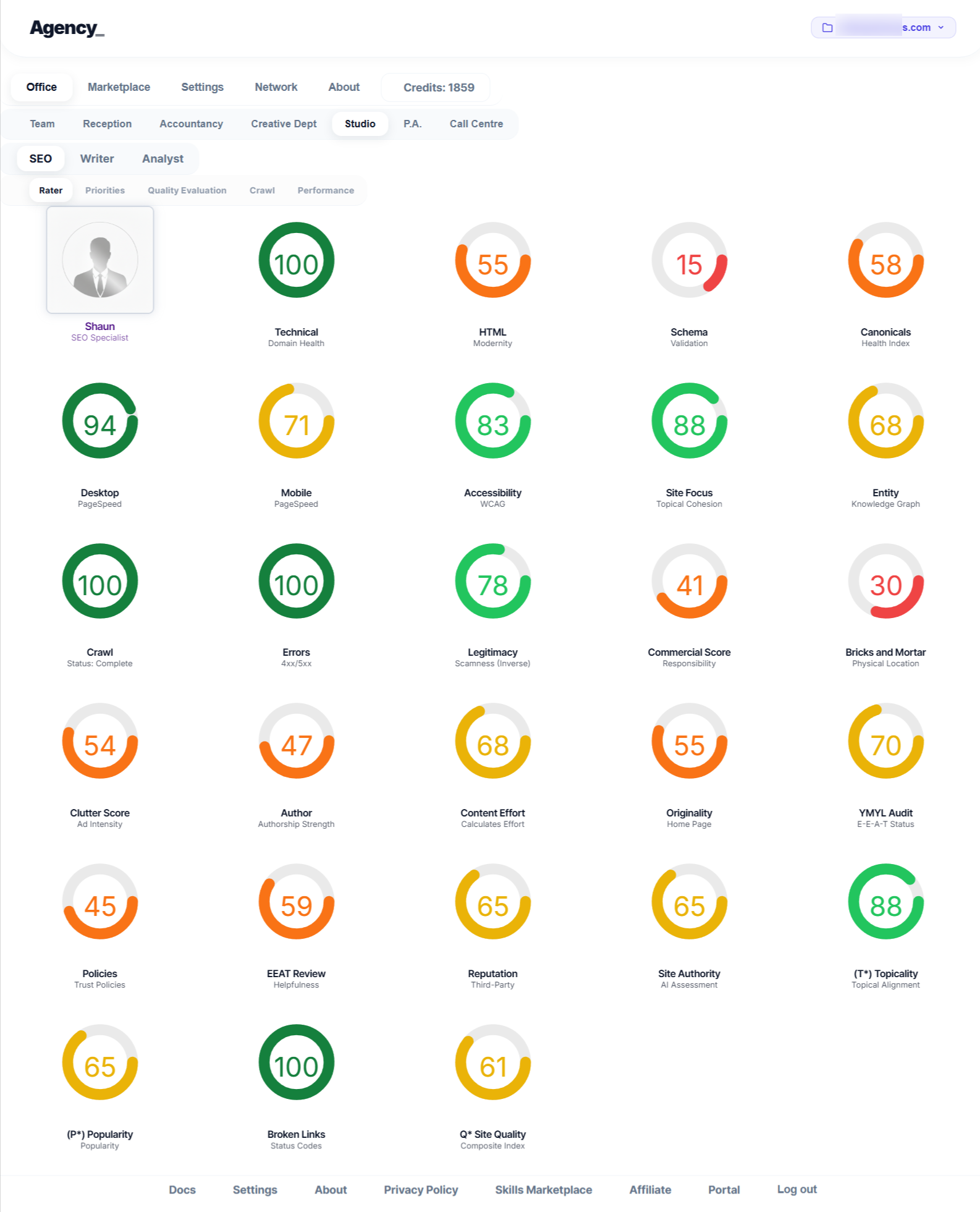
Success in 2026 and beyond requires mastering all three.

| Document Title | Date | Link Text / Reference |
| Life of a Click (user-interaction) | May 15, 2017 | Google presentation: Life of a Click (user-interaction) (May 15, 2017) (PDF) |
| Q4 Search All Hands: Ranking | Dec. 8, 2016 | Google presentation: Q4 Search All Hands (Dec. 8, 2016) (PDF) |
| Ranking for Research | November 16, 2018 | Google presentation: Ranking for Research (November 16, 2018) (PDF) |
| Google is magical. | October 30, 2017 | Google presentation: Google is magical. (October 30, 2017) (PDF) |
| Logging & Ranking | May 8, 2020 | Google presentation: Logging & Ranking (May 8, 2020) (PDF) |
| Ranking Newsletter (Mobile vs. desktop ranking) | August 16, 2014 | Email from Google’s Web Ranking Team to Pandu Nayak – Subject: [Web Ranking Team] Aug 11 –Aug 15, 2014 was updated — Ranking Newsletter (August 16, 2014) (PDF) |
| Bullet points for presentation to Sundar | Sept. 17, 2019 | Google document: Bullet points for presentation to Sundar (Sept. 17, 2019) (PDF) |
Addendum: The E-E-A-T & Systems Master Index
To further explore the concepts of E-E-A-T, Content Effort, and system-level SEO discussed in this review, below is a complete, curated index of my foundational research, frameworks, and practical guides.
Watch: EEAT Explained: What Google Actually Uses to Judge Trust & Quality
Part 1: Hobo Web – Applied Quality & E-E-A-T

This section focuses on the practical application of E-E-A-T, content audits, and site-level quality signals.
1. Contextual SEO: The “It Depends” Edition
In this article, I explain why SEO – including E-E-A-T – is always contextual. There is no universal checklist that works for every site. What Google expects depends on the topic, YMYL status, site history, intent, and the risk profile of getting the information wrong. This article frames everything else I’ve written on quality and trust.
2. E-E-A-T Decoded: Experience, Expertise, Authority & Trust
This is my foundational Hobo article on E-E-A-T. I strip away SEO mythology and focus on what raters are actually trained to look for, breaking down Experience, Expertise, Authoritativeness, and Trust. I also mapped the leak to public algorithm updates, demonstrating that E-E-A-T is Google’s codified doctrine.
3. E-E-A-T Is the Goal, Q-Star Is the System, Site_Quality Is the Score
My mental model for Google quality systems. E-E-A-T is the goal, but behind it are the machine-level systems that attempt to measure it. This piece connects abstract quality ideas to enforceable, scalable scoring systems.
4. The ContentEffort Attribute, the Helpful Content System, and E-E-A-T
My argument here is simple: Google is not just judging what you say; it is judging how much real human work went into saying it. This explains why low-effort, templated content fails and why effort is the hidden spine of E-E-A-T.
5. What Is Google’s Content Effort Signal?
Going deeper into the content effort concept as a ranking reality. I explain how effort manifests through original research, first-hand experience, depth, editorial care, and maintenance. E-E-A-T does not exist without effort.
6. E-E-A-T Checklist
The practical implementation layer. This turns E-E-A-T theory into auditable signals, page-level checks, and site-level responsibilities. It is intentionally conservative, reflecting what I’ve seen actually work when sites are under quality pressure.
7. Hobo E-E-A-T Review & Task Prioritisation
This page documents how I evaluate E-E-A-T professionally. It covers how I assess risk, distinguish cosmetic changes from meaningful improvements, and intelligently prioritise fixes.
8. The Definitive Guide to SEO Audits (Post-Leak)
This article embeds E-E-A-T into a full audit methodology. I explain how quality, effort, intent, and trust are now inseparable from technical SEO, content audits, and recovery work. E-E-A-T is no longer optional in audits—it is structural.
9. Prompt: Rate My Page Quality Using the Hobo SEO Method
An applied framework for quality self-assessment. It forces honest answers about purpose, audience, experience, effort, and trust to prevent webmasters from lying to themselves about their content quality.
10. Thanks to AI, Websites Will Never Die
Why AI does not replace E-E-A-T, but rather amplifies its importance. AI increases supply; Trust controls demand. E-E-A-T is how real websites survive an era of digital abundance.
Part 2: Searchable.com — Systems, Signals, and the Open Web
In my series on Searchable.com, I continued my analysis, aligning Google’s known internal systems with their public-facing documentation and guidelines:

I am a special advisor to Searchable.com, where I focus on systems thinking, algorithm interpretation, and the future of search.
11. E-E-A-T: The Only Answer for the Open Web
My core thesis: E-E-A-T is the survival mechanism of the open web. AI content is not the threat; low-effort content is. Trust is the final uncompressible asset.
12. Decoded: Google Quality Rater Guidelines – Content Quality
Here, I map rater concepts to real scoring logic, explaining how human judgements regarding effort, originality, expertise, and purpose are likely translated into machine-readable features.
13. Decoded: Google Helpful Content Guidelines
An exploration of how Helpful Content and E-E-A-T overlap. “Who, how, and why” are not slogans—they are algorithmic filters. This piece shows how Google evaluates intent and motivation, not just text.
14. Content Effort Score Guide
This guide formalises effort as a measurable concept. It explains what effort looks like, how it compounds, and why it resists automation.
15. The Marketing Cyborg
How to use AI without destroying trust. This approach is about augmentation, not replacement, ensuring that E-E-A-T survives because humans stay accountable. See also: The Marketing Cyborg Technique..
16. What Is Searchable.com? The Operating System for the Agentic Web
Providing context for my broader work, this article explains why E-E-A-T, effort, and trust are foundational to how modern search systems must function in an AI-driven world.
Part 3: Documented Evidence & Ranking Systems Analysis

This section catalogs my direct analysis of the internal Google ranking systems, providing the evidence-based foundation for my SEO frameworks.
17. How Google Works in 2025: Q* and P* Revealed
Based on the DOJ disclosures, I explain the core architecture of modern Google Search: Quality (Q*) and Popularity (P*), and how modular systems like Navboost operate within them.
18. The Google Content Warehouse Leak Analysis
My deep dive into the 2024 API leak. This article confirms the existence of the Mustang indexing engine, the Twiddler re-ranking functions, and the “sandbox” mechanic for new sites.
19. Topicality (T*) and the ABCs of Relevance
An analysis of the Topicality (T*) system. I explain how Google computes document relevance based on “ABC signals”: Anchors, Body content, and Clicks (user dwell time).
20. The Q* Metric: Google’s Site-Level Quality Score
A detailed breakdown of Q* (“Q-star”), the largely static, query-independent measure of a website’s overall trustworthiness and foundational authority.
21. The Popularity Signal (P*)
An exploration of P*, the top-level Google ranking signal that uses Chrome browsing data and anchor links to measure how “well-linked” and widely visited a domain is.
22. Google Panda: The Origin of Site-Wide Quality
This piece traces the history of the Panda algorithm, explaining how it established the precedent for “overall site quality” as a permanent ranking factor and its evolution into the modern Q* score.
23. The Evolution of PageRank
A history of PageRank, clarifying that while the public toolbar is dead, the internal metric remains a critical input for higher-level quality scores like Q*.
24. How Human Quality Raters Train the AI
Evidence from the DOJ trial showing that human quality rater scores are a direct training input for core ranking models like RankEmbed, directly shaping machine understanding.
Part 4: The Disconnected Entity Hypothesis
My theoretical framework explaining the devastating impact of recent Google algorithm updates on independent publishers.
25. The Disconnected Entity Hypothesis (Core Concept)
My central thesis: Google’s recent updates (HCU, SPAM, CORE) actively demote “Unhealthy Entities”—sites that fail to meet Google’s baseline requirements for transparency, accountability, and real-world connection.
26. The Compliance Domino Effect (Section 2.5.2)
Why identifying “who is responsible for a website” is the most critical SEO task today. I argue that complying with Section 2.5.2 triggers a domino effect that inherently satisfies a dozen other trust guidelines.
27. Analysis: The March 2024 Core Update
An analysis of “Judgement Day for independent publishers,” reinforcing how the update specifically targeted sites with poor Entity Health.
28. Analysis: The December 2024 Spam Update
Further validation of the Disconnected Entity Hypothesis, analyzing how this update targeted “unknown entities” lacking verifiable real-world presence.
Part 5: Strategy for the AI Era
Strategic frameworks for adapting to AI Overviews and the shifting search landscape.
29. Optimising for the Synthetic Content Data Layer
A strategy for influencing how AI systems represent your brand by proactively publishing an exhaustive, fact-checked knowledge base on your own website.
30. Entity SEO Explained
Why optimizing to be recognized as a distinct “thing” in Google’s Knowledge Graph is crucial for demonstrating E-E-A-T and earning algorithmic trust.
31. The New Link Economy: Brand Mentions
My argument that in the era of AI Overviews, authoritative brand mentions are replacing traditional links as a primary signal for E-E-A-T consensus.
32. Navigating Zero-Click Search
An exploration of how to adapt marketing strategies when user queries are answered directly on the SERP via AI features.
33. Query Fan-Out & Answer Engine Optimisation
An explanation of how AI breaks single queries into multiple sub-queries, requiring a shift toward deep topical authority and machine readability.