
If you are a web developer, digital marketer, or SEO specialist looking for up-to-date advice on search engine-friendly URLs, you are in the right place. This article examines the significance of search engine-friendly (SEF) URLs in enhancing a website’s ranking on Google. It offers practical advice on creating SEF URLs that boost website usability and enhance search result visibility.
Know that keywords in URLs are a tiny ranking factor and are user-friendly. Keep URLs as simple and user-friendly as you possibly can as longer URLs are truncated in search results listings.
Search engine-friendly URLs are user-friendly, relevant, and easy-to-understand page names on your website and are often visible in a browser address bar.
The SEO checklist is a spreadsheet that is available for you to access for free on Google Sheets, or alternatively, you can subscribe to Hobo SEO Tips and get your checklist as a Microsoft Excel spreadsheet.
Here is an SEO checklist for URLs:
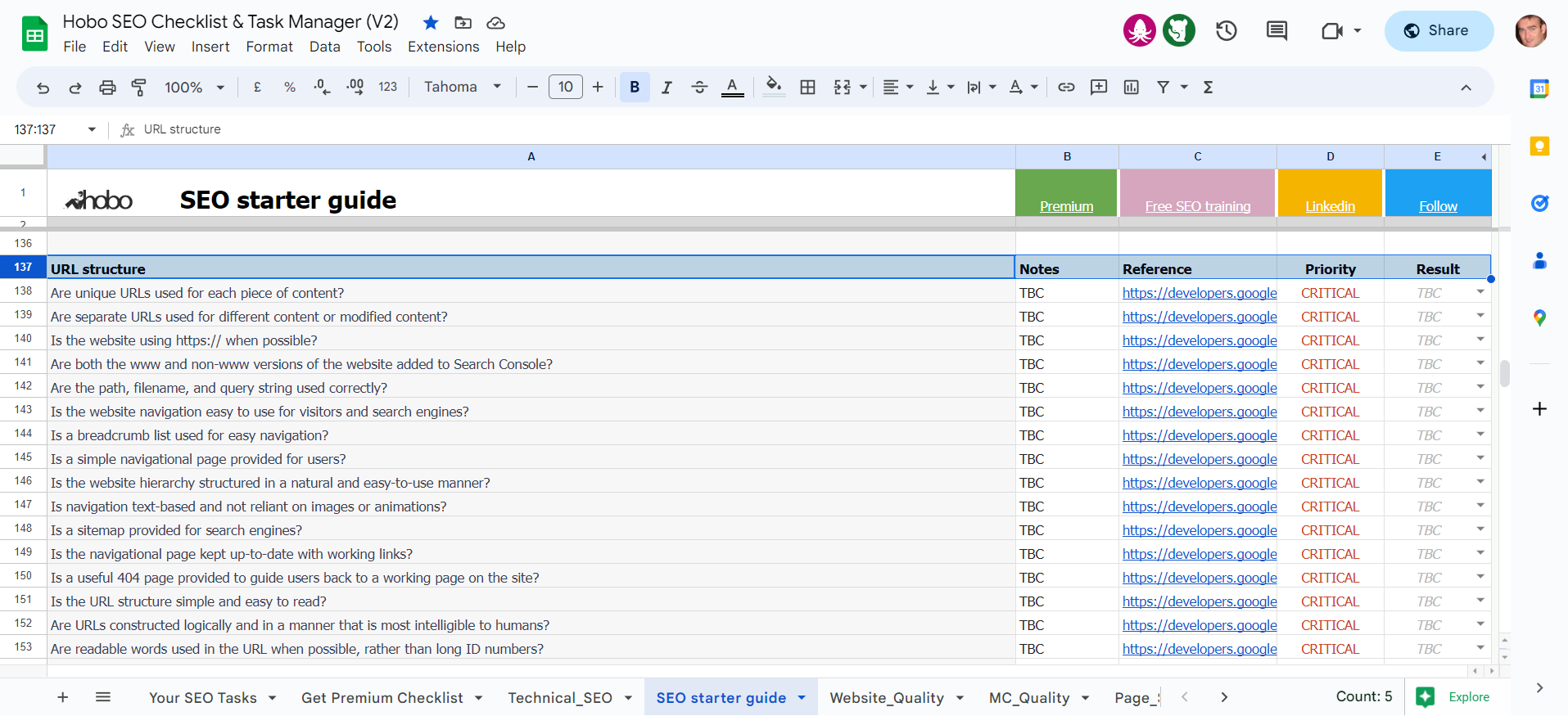
- Are unique URLs used for each piece of content?
- Are separate URLs used for different content or modified content?
- Is the website using https:// when possible?
- Are all versions (e.g. www and non-www) versions of the website added to Search Console?
- Are the path, filename, and query string used correctly?
- Is the website navigation easy to use for visitors and search engines?
- Is a breadcrumb list used for easy navigation?
- Is a simple navigational page provided for users?
- Is the website hierarchy structured in a natural and easy-to-use manner?
- Is navigation text-based and not reliant on images or animations?
- Is a sitemap provided for search engines?
- Is the navigational page kept up-to-date with working links?
- Is a useful 404 page provided to guide users back to a working page on the site?
- Is the URL structure simple and easy to read?
- Are URLs constructed logically and in a manner that is most intelligible to humans?
- Are readable words used in the URL when possible, rather than long ID numbers?
- Are localized words used in the URL, if applicable?
- Is UTF-8 encoding used as necessary?
- Are non-ASCII characters avoided in the URL?
- Are unreadable, long ID numbers avoided in the URL?
- If the site is multi-regional, is a URL structure used that makes it easy to geotarget the site?
- Is a country-specific domain or subdirectory used?
- Are hyphens used to separate words in the URL, instead of underscores?
- Are overly complex URLs, especially those containing multiple parameters, avoided?
- Are common causes of unnecessary high numbers of URLs, such as additive filtering of a set of items, dynamic generation of documents, problematic parameters in the URL, sorting parameters, irrelevant parameters in the URL, and calendar issues, avoided?
- Are descriptive categories and filenames used to organize the website’s documents?
- Are URLs on the website easy to understand and use words that are relevant to the site’s content and structure?
- Are URLs on the website simple, avoiding lengthy URLs with unnecessary parameters, and generic page names?
- Is a simple directory structure used to organize the website’s content, making it easy for visitors to navigate the site and know where they’re at?
- Are deep nesting of subdirectories avoided, and are directory names related to the content in them?
- Does the website provide one version of a URL to reach a document to prevent users from linking to different versions and splitting the content’s reputation between URLs?
- If multiple URLs access the same content, does the website use a 301 redirect or the rel=”canonical” link element to refer to the dominant URL?
- Are pages from subdomains and the root directory avoided to access the same content?
These recommendations come directly from Google via their webmaster guidelines.
Search engine-friendly URLs FAQ
Are keywords in URLs a ranking factor in Google?
QUOTE: “I believe that is a very small ranking factor. So it is not something I’d really try to force. And it is not something I’d say it is even worth your effort to restructure your site just so you can get keywords in your URL.” John Mueller, Google 2016
Does Google count a keyword in the URL when ranking a page? Yes, we have been told, and I tested this at the time too.
John Mueller said that keywords in the URL were a ‘small ranking factor’. Having keywords in the URL did affect rankings for individual keyword phrases in test I ran, but its impact could only be witnessed on very long-tail searches and in weird circumstances.
I proceed as if the keyword in a URL was an extremely minor modern relevance signal for Google to use.
It makes sense it carries some weight, soomewhere. It’s the name of an entire document.
Do you need keywords in URLs to rank high in Google?
QUOTE: “MYTH: Dynamic URLs cannot be crawled. FACT: We can crawl dynamic URLs and interpret the different parameters.” Google
No.
You wouldn’t change a site structure on a live, complicated website just to change URLs to search engine-friendly URLs. Unfriendly URLs can be an indication of a poorly managed site. If a complete website overhaul is in the works, then there is reason to consider starting from what is a basic SEO best practice and using search engine-friendly URLs.
How long should a URL Be?
50 characters if you want it to display in full in some areas on Google Search, but this is a limit that does not matter much from an SEO point of view and is impossible to meet with longer domain names.
If the URL (including your full domain name) is longer it will be truncated in Google desktop SERPS.
Keep any URLs as short and concise as possible and you have nothing to worry about.
Do keyword-rich URLs make better links?
Yes, historically this has been the case. Where this benefit is slightly more detectable is when another site links to your site with the URL as the link.
Then it is fair to say you do get a boost because keywords are in the actual anchor text link to your site, and I believe this is the case, but again, that depends on the quality of the page linking to your site and the quality of your page.
Which is best for Google, directories or files?
This doesn’t really matter in modern SEO. As long as the final URL is not over-complicated and is an example of a high-quality page on the website, you have nothing to worry about. Modern CMS like WordPress use directories as default for file names.
Which are the best absolute or relative URLs?
There is no single best answer. The advice to any website developer would be to, above all, keep it consistent and develop for your site and team’s own set-up.
Read more in the internal links SEO checklist.
Should you have a keyword-rich domain name?
Does having a keyword in the URL of your web address improve rankings in Google? An exact match domain name is a web address with the same exact words in it that make up a popular search – like “bingo.com” or “bingo.co.uk”.
The answer is yes it can help if you are promoting it properly, hence why some exact match domains are very expensive to buy. Lower-quality exact match and partial match domains without a history of marketing quality are just nowhere near as powerful as they once were.
Don’t change your website from a brand name to a low-quality exact match domain, but if you are launching a new website and can fit your primary keyword into a short domain name, that is going to help, even today.
You may also be interested in the title tags SEO checklist or the headings SEO checklist.



8,500
followers
2,800
likes
5000+
connections